 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semi-decentralized Federated Ego Graph Learning for Recommendation
Feb 10, 2023
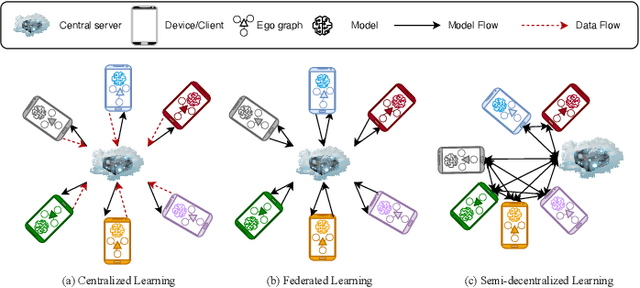
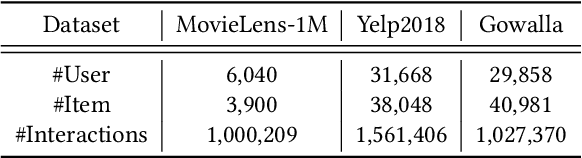
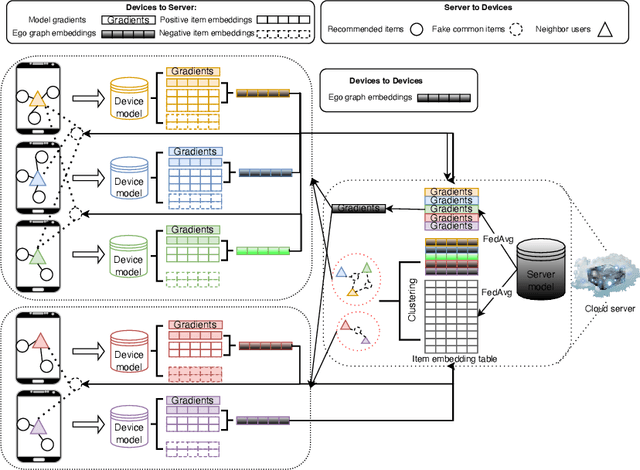
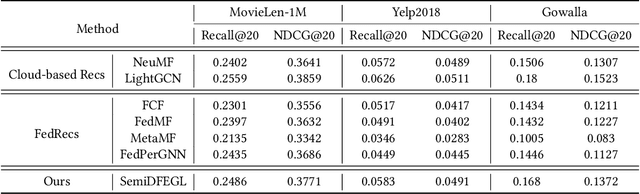
Collaborative filtering (CF) based recommender systems are typically trained based on personal interaction data (e.g., clicks and purchases) that could be naturally represented as ego graphs. However, most existing recommendation methods collect these ego graphs from all users to compose a global graph to obtain high-order collaborative information between users and items, and these centralized CF recommendation methods inevitably lead to a high risk of user privacy leakage. Although recently proposed federated recommendation systems can mitigate the privacy problem, they either restrict the on-device local training to an isolated ego graph or rely on an additional third-party server to access other ego graphs resulting in a cumbersome pipeline, which is hard to work in practice. In addition, existing federated recommendation systems require resource-limited devices to maintain the entire embedding tables resulting in high communication costs. In light of this, we propose a semi-decentralized federated ego graph learning framework for on-device recommendations, named SemiDFEGL, which introduces new device-to-device collaborations to improve scalability and reduce communication costs and innovatively utilizes predicted interacted item nodes to connect isolated ego graphs to augment local subgraphs such that the high-order user-item collaborative information could be used in a privacy-preserving manner. Furthermore, the proposed framework is model-agnostic, meaning that it could be seamlessly integrated with existing graph neural network-based recommendation methods and privacy protection techniques. To validate the effectiveness of the proposed SemiDFEGL, extensive experiments are conducted on three public datasets, and the results demonstrate the superiority of the proposed SemiDFEGL compared to other federated recommendation methods.
DOR: A Novel Dual-Observation-Based Approach for News Recommendation Systems
Feb 02, 2023
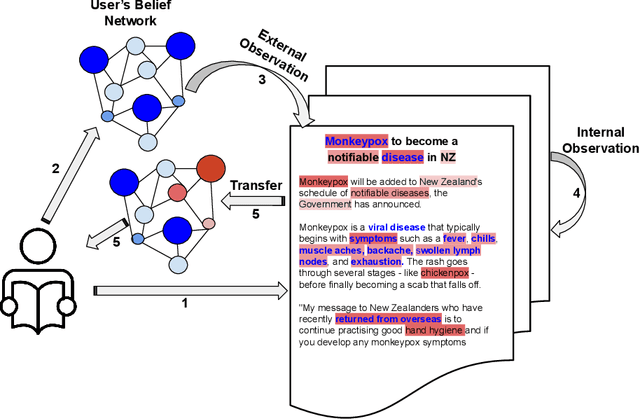
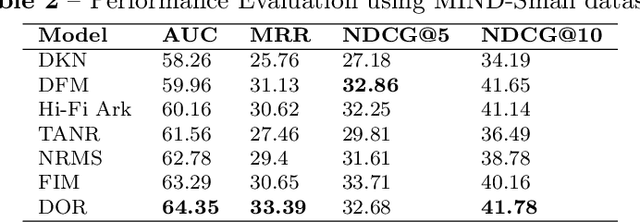
Online social media platforms offer access to a vast amount of information, but sifting through the abundance of news can be overwhelming and tiring for readers. personalised recommendation algorithms can help users find information that interests them. However, most existing models rely solely on observations of user behaviour, such as viewing history, ignoring the connections between the news and a user's prior knowledge. This can result in a lack of diverse recommendations for individuals. In this paper, we propose a novel method to address the complex problem of news recommendation. Our approach is based on the idea of dual observation, which involves using a deep neural network with observation mechanisms to identify the main focus of a news article as well as the focus of the user on the article. This is achieved by taking into account the user's belief network, which reflects their personal interests and biases. By considering both the content of the news and the user's perspective, our approach is able to provide more personalised and accurate recommendations. We evaluate the performance of our model on real-world datasets and show that our proposed method outperforms several popular baselines.
Beyond KNN: Deep Neighborhood Learning for WiFi-based Indoor Positioning Systems
Feb 02, 2023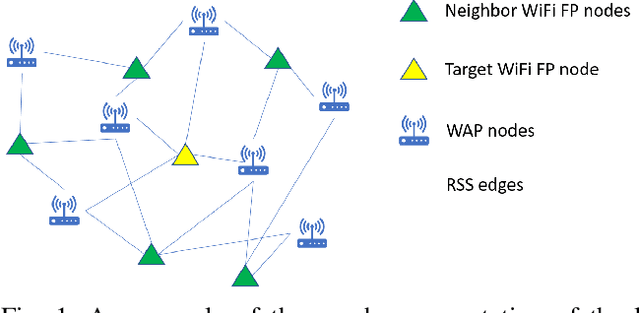
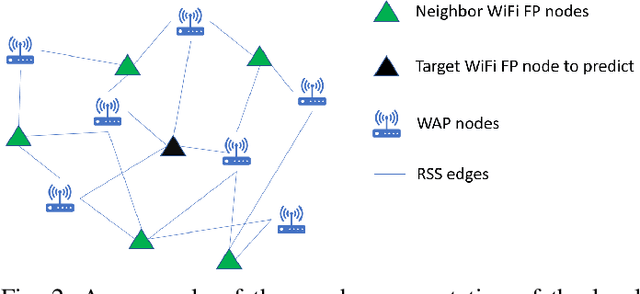
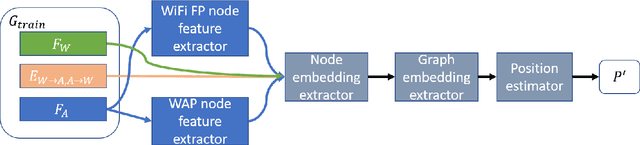
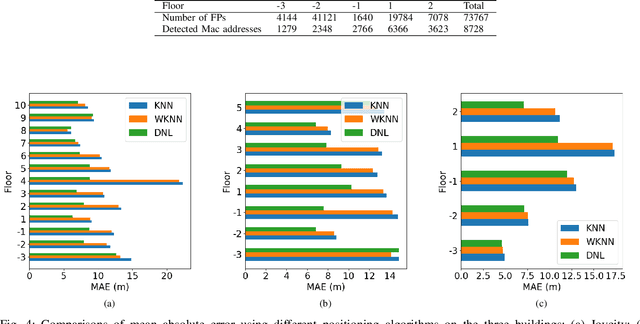
K-Neares Neighbors (KNN) and its variant weighted KNN (WKNN) have been explored for years in both academy and industry to provide stable and reliable performance in WiFi-based indoor positioning systems. Such algorithms estimate the location of a given point based on the locality information from the selected nearest WiFi neighbors according to some distance metrics calculated from the combination of WiFi received signal strength (RSS). However, such a process does not consider the relational information among the given point, WiFi neighbors, and the WiFi access points (WAPs). Therefore, this study proposes a novel Deep Neighborhood Learning (DNL). The proposed DNL approach converts the WiFi neighborhood to heterogeneous graphs, and utilizes deep graph learning to extract better representation of the WiFi neighborhood to improve the positioning accuracy. Experiments on 3 real industrial datasets collected from 3 mega shopping malls on 26 floors have shown that the proposed approach can reduce the mean absolute positioning error by 10% to 50% in most of the cases. Specially, the proposed approach sharply reduces the root mean squared positioning error and 95\% percentile positioning error, being more robust to the outliers than conventional KNN and WKNN.
Capturing Global Structural Information in Long Document Question Answering with Compressive Graph Selector Network
Oct 11, 2022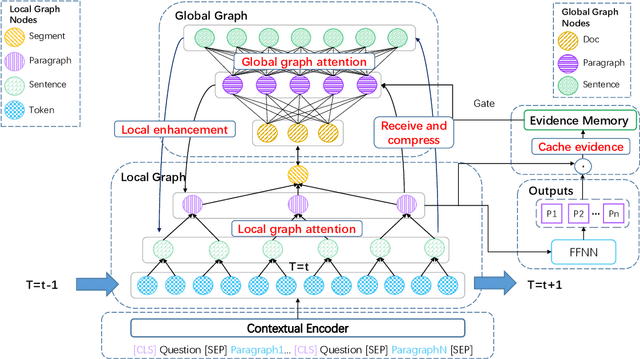
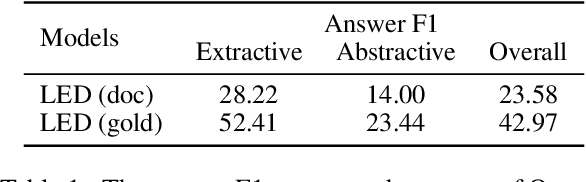
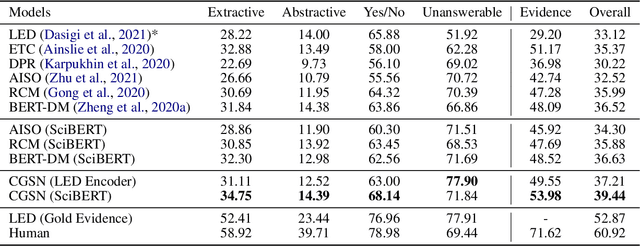
Long document question answering is a challenging task due to its demands for complex reasoning over long text. Previous works usually take long documents as non-structured flat texts or only consider the local structure in long documents. However, these methods usually ignore the global structure of the long document, which is essential for long-range understanding. To tackle this problem, we propose Compressive Graph Selector Network (CGSN) to capture the global structure in a compressive and iterative manner. Specifically, the proposed model consists of three modules: local graph network, global graph network and evidence memory network. Firstly, the local graph network builds the graph structure of the chunked segment in token, sentence, paragraph and segment levels to capture the short-term dependency of the text. Secondly, the global graph network selectively receives the information of each level from the local graph, compresses them into the global graph nodes and applies graph attention into the global graph nodes to build the long-range reasoning over the entire text in an iterative way. Thirdly, the evidence memory network is designed to alleviate the redundancy problem in the evidence selection via saving the selected result in the previous steps. Extensive experiments show that the proposed model outperforms previous methods on two datasets.
Edge-weighted pFISTA-Net for MRI Reconstruction
Feb 15, 2023
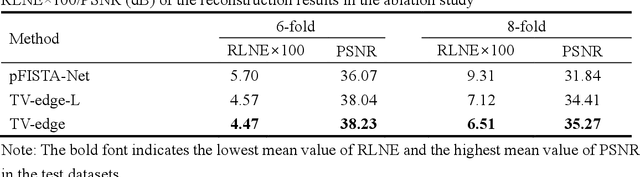
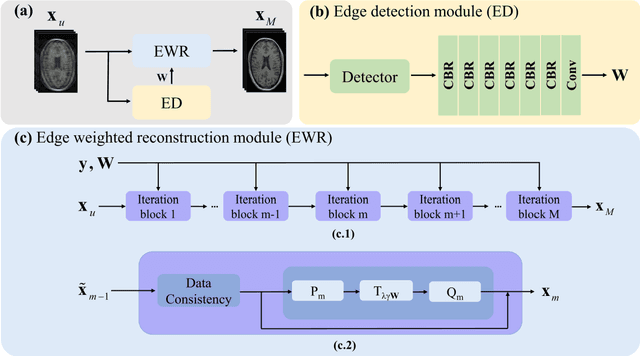
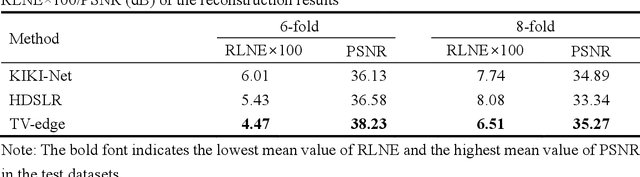
Deep learning based on unrolled algorithm has served as an effective method for accelerated magnetic resonance imaging (MRI). However, many methods ignore the direct use of edge information to assist MRI reconstruction. In this work, we present the edge-weighted pFISTA-Net that directly applies the detected edge map to the soft-thresholding part of pFISTA-Net. The soft-thresholding value of different regions will be adjusted according to the edge map. Experimental results of a public brain dataset show that the proposed yields reconstructions with lower error and better artifact suppression compared with the state-of-the-art deep learning-based methods. The edge-weighted pFISTA-Net also shows robustness for different undersampling masks and edge detection operators. In addition, we extend the edge weighted structure to joint reconstruction and segmentation network and obtain improved reconstruction performance and more accurate segmentation results.
A Dynamic Temporal Self-attention Graph Convolutional Network for Traffic Prediction
Feb 21, 2023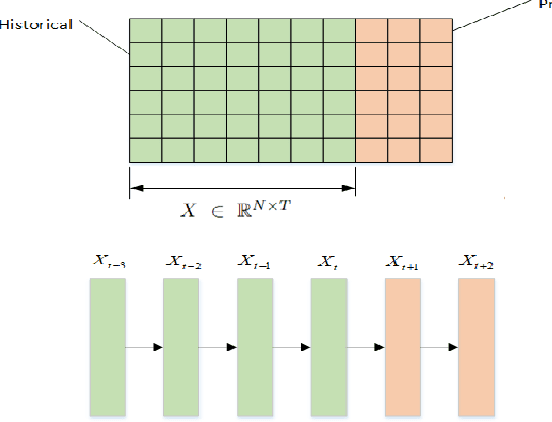
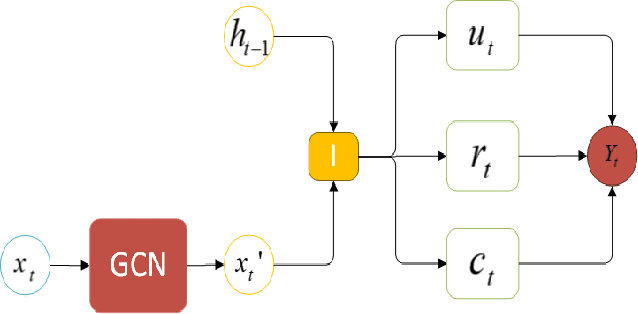
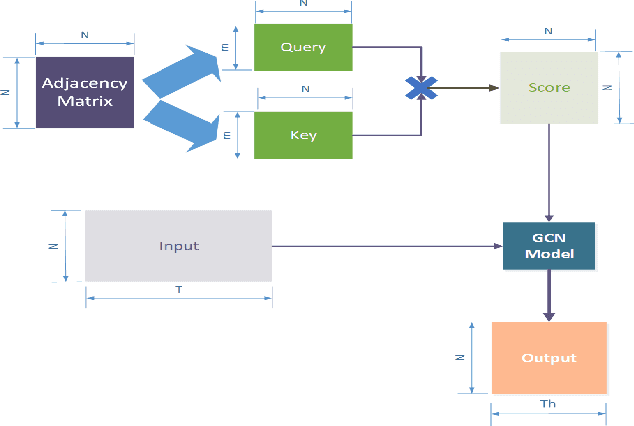
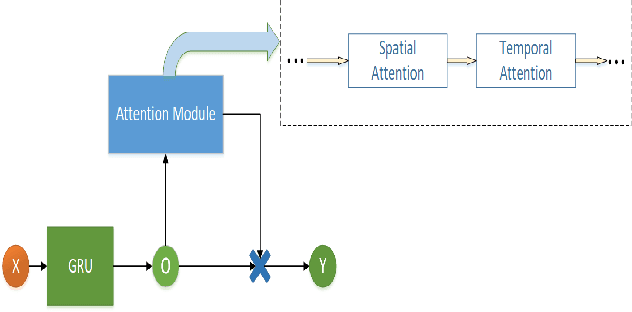
Accurate traffic prediction in real time plays an important role in Intelligent Transportation System (ITS) and travel navigation guidance. There have been many attempts to predict short-term traffic status which consider the spatial and temporal dependencies of traffic information such as temporal graph convolutional network (T-GCN) model and convolutional long short-term memory (Conv-LSTM) model. However, most existing methods use simple adjacent matrix consisting of 0 and 1 to capture the spatial dependence which can not meticulously describe the urban road network topological structure and the law of dynamic change with time. In order to tackle the problem, this paper proposes a dynamic temporal self-attention graph convolutional network (DT-SGN) model which considers the adjacent matrix as a trainable attention score matrix and adapts network parameters to different inputs. Specially, self-attention graph convolutional network (SGN) is chosen to capture the spatial dependence and the dynamic gated recurrent unit (Dynamic-GRU) is chosen to capture temporal dependence and learn dynamic changes of input data. Experiments demonstrate the superiority of our method over state-of-art model-driven model and data-driven models on real-world traffic datasets.
Learning to Retrieve Engaging Follow-Up Queries
Feb 21, 2023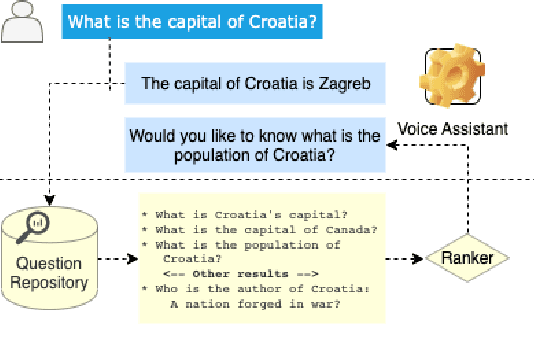

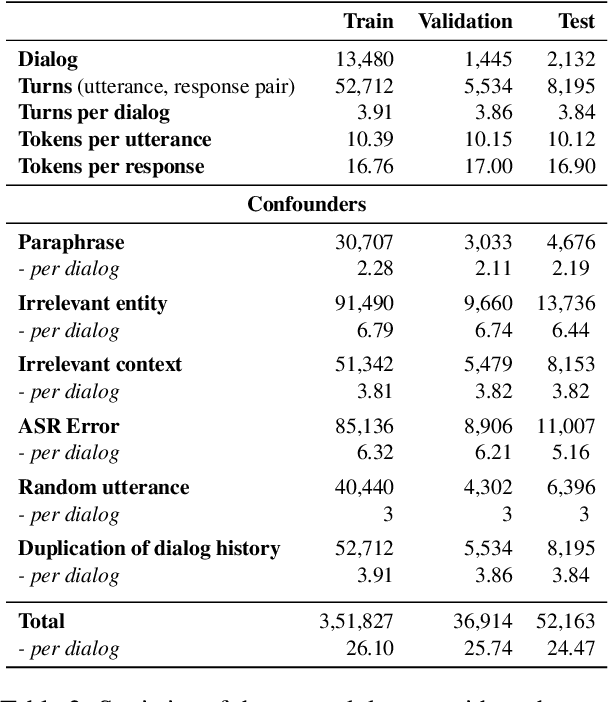
Open domain conversational agents can answer a broad range of targeted queries. However, the sequential nature of interaction with these systems makes knowledge exploration a lengthy task which burdens the user with asking a chain of well phrased questions. In this paper, we present a retrieval based system and associated dataset for predicting the next questions that the user might have. Such a system can proactively assist users in knowledge exploration leading to a more engaging dialog. The retrieval system is trained on a dataset which contains ~14K multi-turn information-seeking conversations with a valid follow-up question and a set of invalid candidates. The invalid candidates are generated to simulate various syntactic and semantic confounders such as paraphrases, partial entity match, irrelevant entity, and ASR errors. We use confounder specific techniques to simulate these negative examples on the OR-QuAC dataset and develop a dataset called the Follow-up Query Bank (FQ-Bank). Then, we train ranking models on FQ-Bank and present results comparing supervised and unsupervised approaches. The results suggest that we can retrieve the valid follow-ups by ranking them in higher positions compared to confounders, but further knowledge grounding can improve ranking performance.
Que2Engage: Embedding-based Retrieval for Relevant and Engaging Products at Facebook Marketplace
Feb 21, 2023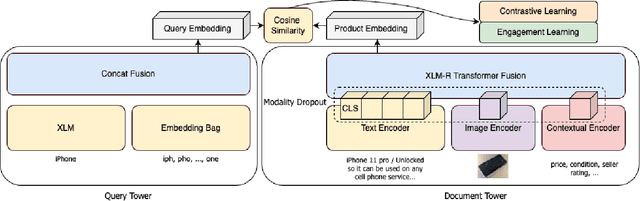
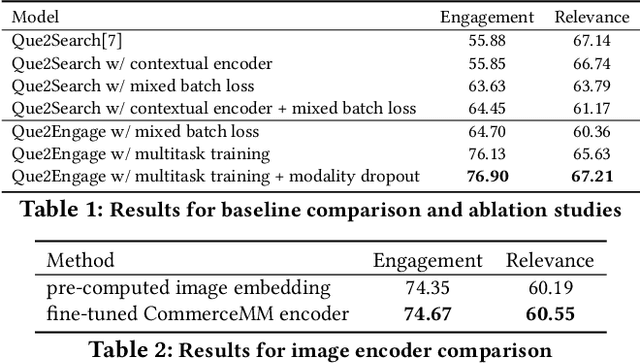
Embedding-based Retrieval (EBR) in e-commerce search is a powerful search retrieval technique to address semantic matches between search queries and products. However, commercial search engines like Facebook Marketplace Search are complex multi-stage systems optimized for multiple business objectives. At Facebook Marketplace, search retrieval focuses on matching search queries with relevant products, while search ranking puts more emphasis on contextual signals to up-rank the more engaging products. As a result, the end-to-end searcher experience is a function of both relevance and engagement, and the interaction between different stages of the system. This presents challenges to EBR systems in order to optimize for better searcher experiences. In this paper we presents Que2Engage, a search EBR system built towards bridging the gap between retrieval and ranking for end-to-end optimizations. Que2Engage takes a multimodal & multitask approach to infuse contextual information into the retrieval stage and to balance different business objectives. We show the effectiveness of our approach via a multitask evaluation framework and thorough baseline comparisons and ablation studies. Que2Engage is deployed on Facebook Marketplace Search and shows significant improvements in searcher engagement in two weeks of A/B testing.
Learning the Effects of Physical Actions in a Multi-modal Environment
Jan 27, 2023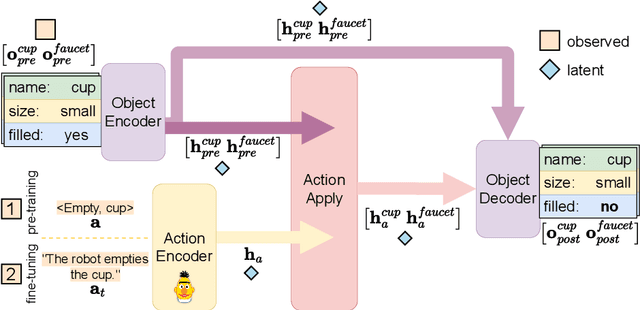
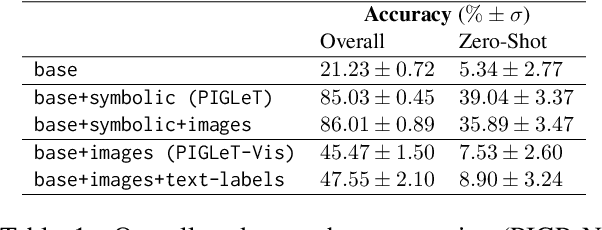
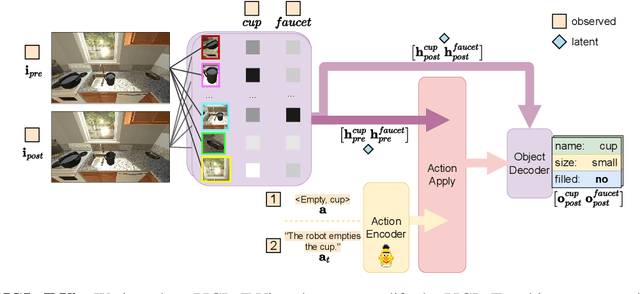
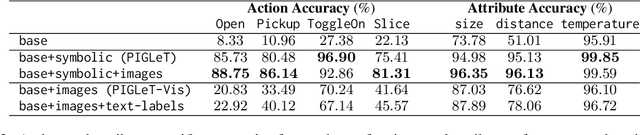
Large Language Models (LLMs) handle physical commonsense information inadequately. As a result of being trained in a disembodied setting, LLMs often fail to predict an action's outcome in a given environment. However, predicting the effects of an action before it is executed is crucial in planning, where coherent sequences of actions are often needed to achieve a goal. Therefore, we introduce the multi-modal task of predicting the outcomes of actions solely from realistic sensory inputs (images and text). Next, we extend an LLM to model latent representations of objects to better predict action outcomes in an environment. We show that multi-modal models can capture physical commonsense when augmented with visual information. Finally, we evaluate our model's performance on novel actions and objects and find that combining modalities help models to generalize and learn physical commonsense reasoning better.
Machine Translation Impact in E-commerce Multilingual Search
Jan 31, 2023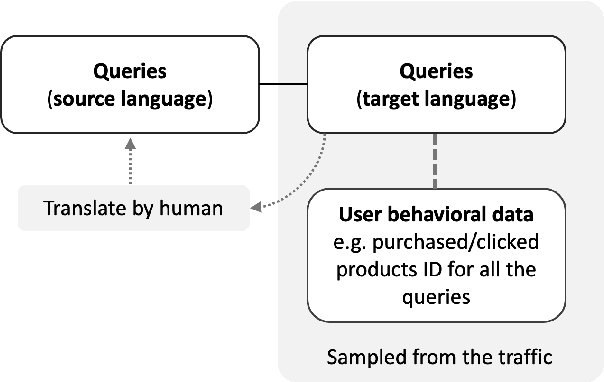
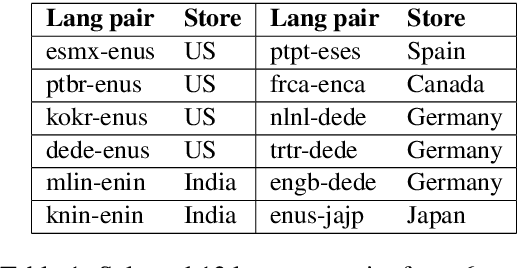
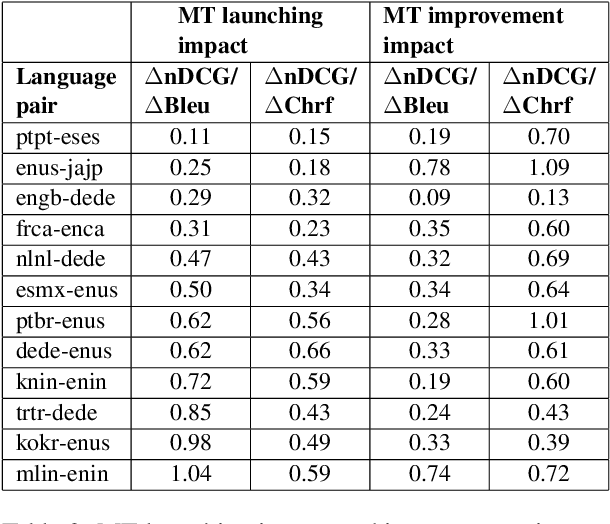
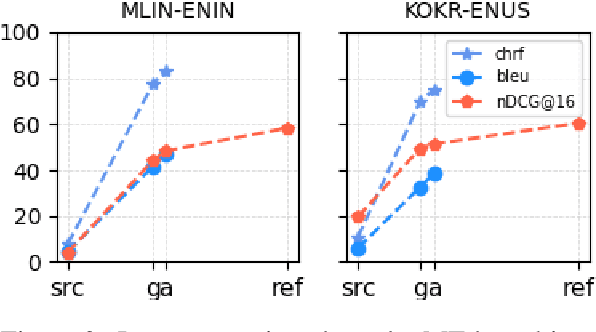
Previous work suggests that performance of cross-lingual information retrieval correlates highly with the quality of Machine Translation. However, there may be a threshold beyond which improving query translation quality yields little or no benefit to further improve the retrieval performance. This threshold may depend upon multiple factors including the source and target languages, the existing MT system quality and the search pipeline. In order to identify the benefit of improving an MT system for a given search pipeline, we investigate the sensitivity of retrieval quality to the presence of different levels of MT quality using experimental datasets collected from actual traffic. We systematically improve the performance of our MT systems quality on language pairs as measured by MT evaluation metrics including Bleu and Chrf to determine their impact on search precision metrics and extract signals that help to guide the improvement strategies. Using this information we develop techniques to compare query translations for multiple language pairs and identify the most promising language pairs to invest and improve.