 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge†DAGGER: Distractor-Aware Graph Generation for Executable Reasoning in Math Problems
Jan 11, 2026Chain-of-Thought (CoT) prompting is widely adopted for mathematical problem solving, including in low-resource languages, yet its behavior under irrelevant context remains underexplored. To systematically study this challenge, we introduce DISTRACTMATH-BN, a Bangla benchmark that augments MGSM and MSVAMP with semantically coherent but computationally irrelevant information. Evaluating seven models ranging from 3B to 12B parameters, we observe substantial performance degradation under distractors: standard models drop by up to 41 points, while reasoning-specialized models decline by 14 to 20 points despite consuming five times more tokens. We propose †DAGGER, which reformulates mathematical problem solving as executable computational graph generation with explicit modeling of distractor nodes. Fine-tuning Gemma-3 models using supervised fine-tuning followed by Group Relative Policy Optimization achieves comparable weighted accuracy on augmented benchmarks while using 89 percent fewer tokens than reasoning models. Importantly, this robustness emerges without explicit training on distractor-augmented examples. Our results suggest that enforcing structured intermediate representations improves robustness and inference efficiency in mathematical reasoning compared to free-form approaches, particularly in noisy, low-resource settings.
Chain-of-Instructions: Compositional Instruction Tuning on Large Language Models
Feb 18, 2024



Fine-tuning large language models (LLMs) with a collection of large and diverse instructions has improved the model's generalization to different tasks, even for unseen tasks. However, most existing instruction datasets include only single instructions, and they struggle to follow complex instructions composed of multiple subtasks (Wang et al., 2023a). In this work, we propose a novel concept of compositional instructions called chain-of-instructions (CoI), where the output of one instruction becomes an input for the next like a chain. Unlike the conventional practice of solving single instruction tasks, our proposed method encourages a model to solve each subtask step by step until the final answer is reached. CoI-tuning (i.e., fine-tuning with CoI instructions) improves the model's ability to handle instructions composed of multiple subtasks. CoI-tuned models also outperformed baseline models on multilingual summarization, demonstrating the generalizability of CoI models on unseen composite downstream tasks.
Integrating Summarization and Retrieval for Enhanced Personalization via Large Language Models
Oct 30, 2023



Personalization, the ability to tailor a system to individual users, is an essential factor in user experience with natural language processing (NLP) systems. With the emergence of Large Language Models (LLMs), a key question is how to leverage these models to better personalize user experiences. To personalize a language model's output, a straightforward approach is to incorporate past user data into the language model prompt, but this approach can result in lengthy inputs exceeding limitations on input length and incurring latency and cost issues. Existing approaches tackle such challenges by selectively extracting relevant user data (i.e. selective retrieval) to construct a prompt for downstream tasks. However, retrieval-based methods are limited by potential information loss, lack of more profound user understanding, and cold-start challenges. To overcome these limitations, we propose a novel summary-augmented approach by extending retrieval-augmented personalization with task-aware user summaries generated by LLMs. The summaries can be generated and stored offline, enabling real-world systems with runtime constraints like voice assistants to leverage the power of LLMs. Experiments show our method with 75% less of retrieved user data is on-par or outperforms retrieval augmentation on most tasks in the LaMP personalization benchmark. We demonstrate that offline summarization via LLMs and runtime retrieval enables better performance for personalization on a range of tasks under practical constraints.
MultiCoNER v2: a Large Multilingual dataset for Fine-grained and Noisy Named Entity Recognition
Oct 20, 2023



We present MULTICONER V2, a dataset for fine-grained Named Entity Recognition covering 33 entity classes across 12 languages, in both monolingual and multilingual settings. This dataset aims to tackle the following practical challenges in NER: (i) effective handling of fine-grained classes that include complex entities like movie titles, and (ii) performance degradation due to noise generated from typing mistakes or OCR errors. The dataset is compiled from open resources like Wikipedia and Wikidata, and is publicly available. Evaluation based on the XLM-RoBERTa baseline highlights the unique challenges posed by MULTICONER V2: (i) the fine-grained taxonomy is challenging, where the scores are low with macro-F1=0.63 (across all languages), and (ii) the corruption strategy significantly impairs performance, with entity corruption resulting in 9% lower performance relative to non-entity corruptions across all languages. This highlights the greater impact of entity noise in contrast to context noise.
SemEval-2023 Task 2: Fine-grained Multilingual Named Entity Recognition
May 25, 2023We present the findings of SemEval-2023 Task 2 on Fine-grained Multilingual Named Entity Recognition (MultiCoNER 2). Divided into 13 tracks, the task focused on methods to identify complex fine-grained named entities (like WRITTENWORK, VEHICLE, MUSICALGRP) across 12 languages, in both monolingual and multilingual scenarios, as well as noisy settings. The task used the MultiCoNER V2 dataset, composed of 2.2 million instances in Bangla, Chinese, English, Farsi, French, German, Hindi, Italian., Portuguese, Spanish, Swedish, and Ukrainian. MultiCoNER 2 was one of the most popular tasks of SemEval-2023. It attracted 842 submissions from 47 teams, and 34 teams submitted system papers. Results showed that complex entity types such as media titles and product names were the most challenging. Methods fusing external knowledge into transformer models achieved the best performance, and the largest gains were on the Creative Work and Group classes, which are still challenging even with external knowledge. Some fine-grained classes proved to be more challenging than others, such as SCIENTIST, ARTWORK, and PRIVATECORP. We also observed that noisy data has a significant impact on model performance, with an average drop of 10% on the noisy subset. The task highlights the need for future research on improving NER robustness on noisy data containing complex entities.
Preventing Catastrophic Forgetting in Continual Learning of New Natural Language Tasks
Feb 22, 2023



Multi-Task Learning (MTL) is widely-accepted in Natural Language Processing as a standard technique for learning multiple related tasks in one model. Training an MTL model requires having the training data for all tasks available at the same time. As systems usually evolve over time, (e.g., to support new functionalities), adding a new task to an existing MTL model usually requires retraining the model from scratch on all the tasks and this can be time-consuming and computationally expensive. Moreover, in some scenarios, the data used to train the original training may be no longer available, for example, due to storage or privacy concerns. In this paper, we approach the problem of incrementally expanding MTL models' capability to solve new tasks over time by distilling the knowledge of an already trained model on n tasks into a new one for solving n+1 tasks. To avoid catastrophic forgetting, we propose to exploit unlabeled data from the same distributions of the old tasks. Our experiments on publicly available benchmarks show that such a technique dramatically benefits the distillation by preserving the already acquired knowledge (i.e., preventing up to 20% performance drops on old tasks) while obtaining good performance on the incrementally added tasks. Further, we also show that our approach is beneficial in practical settings by using data from a leading voice assistant.
Learning to Retrieve Engaging Follow-Up Queries
Feb 21, 2023



Open domain conversational agents can answer a broad range of targeted queries. However, the sequential nature of interaction with these systems makes knowledge exploration a lengthy task which burdens the user with asking a chain of well phrased questions. In this paper, we present a retrieval based system and associated dataset for predicting the next questions that the user might have. Such a system can proactively assist users in knowledge exploration leading to a more engaging dialog. The retrieval system is trained on a dataset which contains ~14K multi-turn information-seeking conversations with a valid follow-up question and a set of invalid candidates. The invalid candidates are generated to simulate various syntactic and semantic confounders such as paraphrases, partial entity match, irrelevant entity, and ASR errors. We use confounder specific techniques to simulate these negative examples on the OR-QuAC dataset and develop a dataset called the Follow-up Query Bank (FQ-Bank). Then, we train ranking models on FQ-Bank and present results comparing supervised and unsupervised approaches. The results suggest that we can retrieve the valid follow-ups by ranking them in higher positions compared to confounders, but further knowledge grounding can improve ranking performance.
MultiCoNER: A Large-scale Multilingual dataset for Complex Named Entity Recognition
Aug 30, 2022


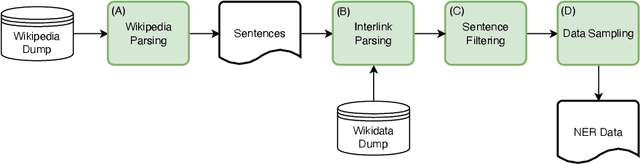
We present MultiCoNER, a large multilingual dataset for Named Entity Recognition that covers 3 domains (Wiki sentences, questions, and search queries) across 11 languages, as well as multilingual and code-mixing subsets. This dataset is designed to represent contemporary challenges in NER, including low-context scenarios (short and uncased text), syntactically complex entities like movie titles, and long-tail entity distributions. The 26M token dataset is compiled from public resources using techniques such as heuristic-based sentence sampling, template extraction and slotting, and machine translation. We applied two NER models on our dataset: a baseline XLM-RoBERTa model, and a state-of-the-art GEMNET model that leverages gazetteers. The baseline achieves moderate performance (macro-F1=54%), highlighting the difficulty of our data. GEMNET, which uses gazetteers, improvement significantly (average improvement of macro-F1=+30%). MultiCoNER poses challenges even for large pre-trained language models, and we believe that it can help further research in building robust NER systems. MultiCoNER is publicly available at https://registry.opendata.aws/multiconer/ and we hope that this resource will help advance research in various aspects of NER.
SemEval-2020 Task 9: Overview of Sentiment Analysis of Code-Mixed Tweets
Aug 10, 2020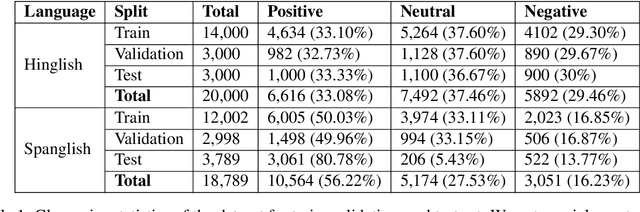

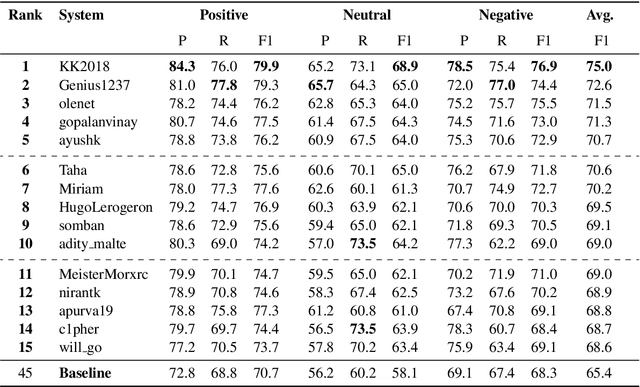
In this paper, we present the results of the SemEval-2020 Task 9 on Sentiment Analysis of Code-Mixed Tweets (SentiMix 2020). We also release and describe our Hinglish (Hindi-English) and Spanglish (Spanish-English) corpora annotated with word-level language identification and sentence-level sentiment labels. These corpora are comprised of 20K and 19K examples, respectively. The sentiment labels are - Positive, Negative, and Neutral. SentiMix attracted 89 submissions in total including 61 teams that participated in the Hinglish contest and 28 submitted systems to the Spanglish competition. The best performance achieved was 75.0% F1 score for Hinglish and 80.6% F1 for Spanglish. We observe that BERT-like models and ensemble methods are the most common and successful approaches among the participants.
LinCE: A Centralized Benchmark for Linguistic Code-switching Evaluation
May 09, 2020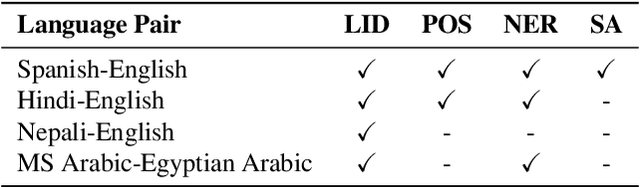
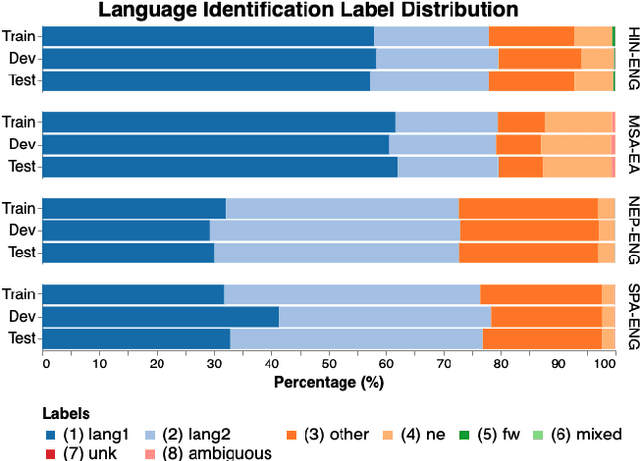
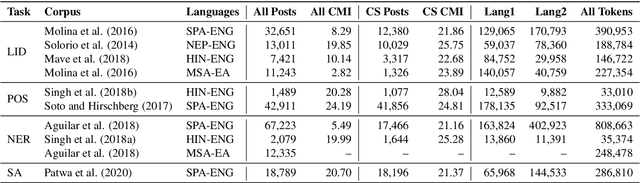
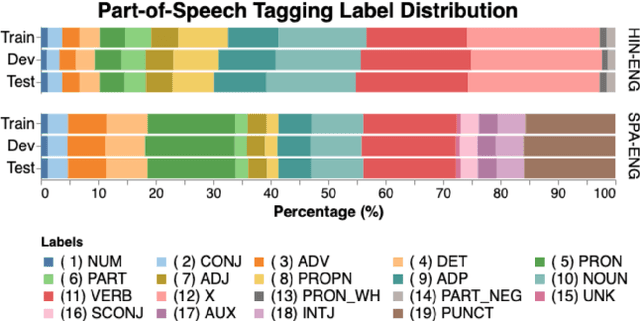
Recent trends in NLP research have raised an interest in linguistic code-switching (CS); modern approaches have been proposed to solve a wide range of NLP tasks on multiple language pairs. Unfortunately, these proposed methods are hardly generalizable to different code-switched languages. In addition, it is unclear whether a model architecture is applicable for a different task while still being compatible with the code-switching setting. This is mainly because of the lack of a centralized benchmark and the sparse corpora that researchers employ based on their specific needs and interests. To facilitate research in this direction, we propose a centralized benchmark for Linguistic Code-switching Evaluation (LinCE) that combines ten corpora covering four different code-switched language pairs (i.e., Spanish-English, Nepali-English, Hindi-English, and Modern Standard Arabic-Egyptian Arabic) and four tasks (i.e., language identification, named entity recognition, part-of-speech tagging, and sentiment analysis). As part of the benchmark centralization effort, we provide an online platform at ritual.uh.edu/lince, where researchers can submit their results while comparing with others in real-time. In addition, we provide the scores of different popular models, including LSTM, ELMo, and multilingual BERT so that the NLP community can compare against state-of-the-art systems. LinCE is a continuous effort, and we will expand it with more low-resource languages and tasks.