 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CFLIT: Coexisting Federated Learning and Information Transfer
Jul 26, 2022
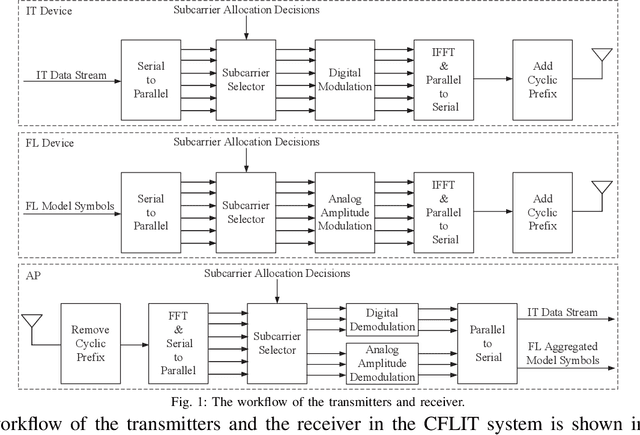
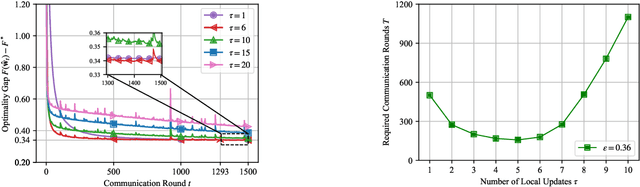
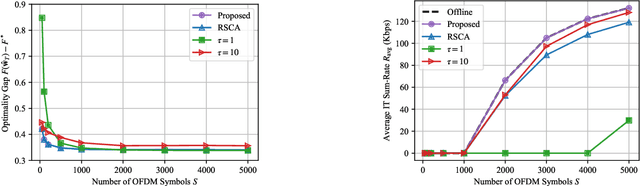
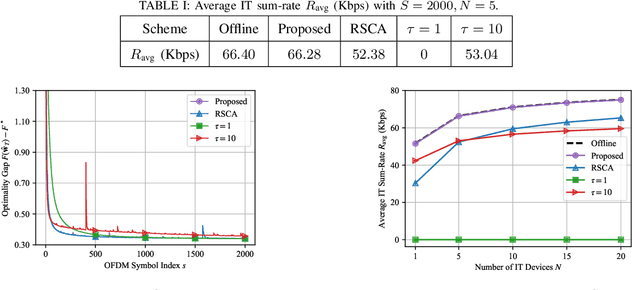
Future wireless networks are expected to support diverse mobile services, including artificial intelligence (AI) services and ubiquitous data transmissions. Federated learning (FL), as a revolutionary learning approach, enables collaborative AI model training across distributed mobile edge devices. By exploiting the superposition property of multiple-access channels, over-the-air computation allows concurrent model uploading from massive devices over the same radio resources, and thus significantly reduces the communication cost of FL. In this paper, we study the coexistence of over-the-air FL and traditional information transfer (IT) in a mobile edge network. We propose a coexisting federated learning and information transfer (CFLIT) communication framework, where the FL and IT devices share the wireless spectrum in an OFDM system. Under this framework, we aim to maximize the IT data rate and guarantee a given FL convergence performance by optimizing the long-term radio resource allocation. A key challenge that limits the spectrum efficiency of the coexisting system lies in the large overhead incurred by frequent communication between the server and edge devices for FL model aggregation. To address the challenge, we rigorously analyze the impact of the computation-to-communication ratio on the convergence of over-the-air FL in wireless fading channels. The analysis reveals the existence of an optimal computation-to-communication ratio that minimizes the amount of radio resources needed for over-the-air FL to converge to a given error tolerance. Based on the analysis, we propose a low-complexity online algorithm to jointly optimize the radio resource allocation for both the FL devices and IT devices. Extensive numerical simulations verify the superior performance of the proposed design for the coexistence of FL and IT devices in wireless cellular systems.
Cybersecurity Challenges of Power Transformers
Feb 25, 2023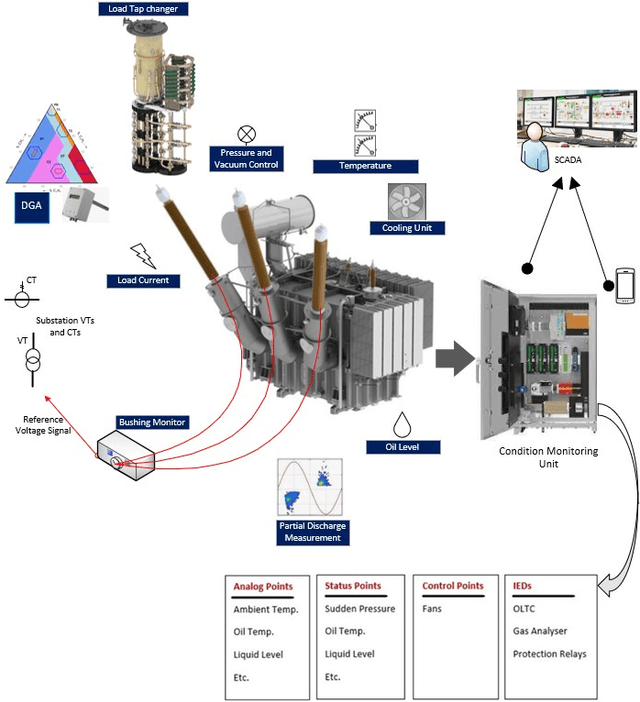
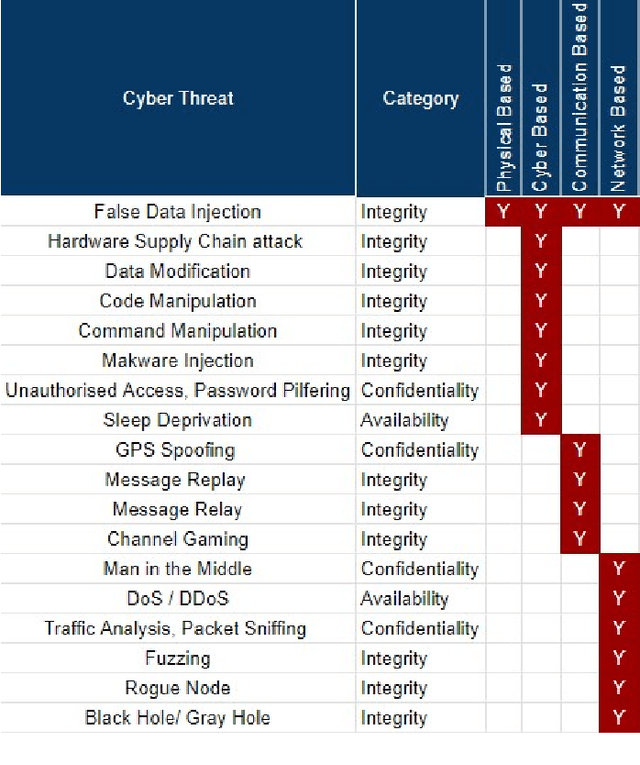
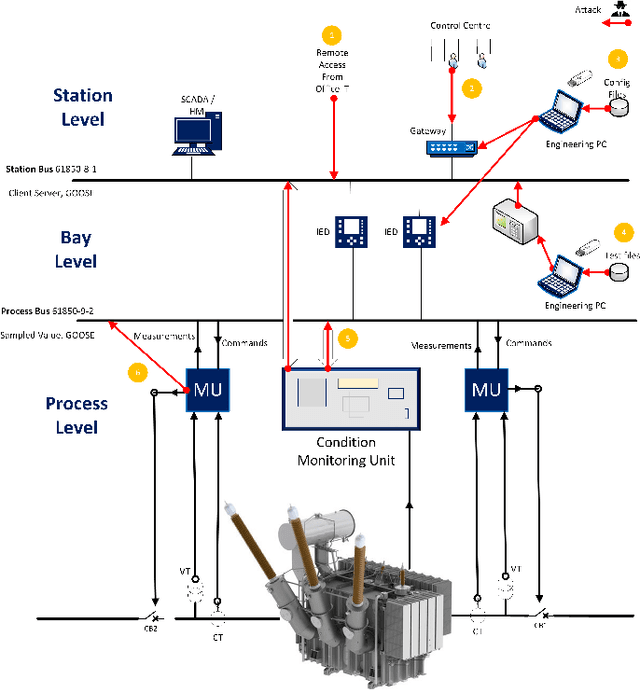
The rise of cyber threats on critical infrastructure and its potential for devastating consequences, has significantly increased. The dependency of new power grid technology on information, data analytic and communication systems make the entire electricity network vulnerable to cyber threats. Power transformers play a critical role within the power grid and are now commonly enhanced through factory add-ons or intelligent monitoring systems added later to improve the condition monitoring of critical and long lead time assets such as transformers. However, the increased connectivity of those power transformers opens the door to more cyber attacks. Therefore, the need to detect and prevent cyber threats is becoming critical. The first step towards that would be a deeper understanding of the potential cyber-attacks landscape against power transformers. Much of the existing literature pays attention to smart equipment within electricity distribution networks, and most methods proposed are based on model-based detection algorithms. Moreover, only a few of these works address the security vulnerabilities of power elements, especially transformers within the transmission network. To the best of our knowledge, there is no study in the literature that systematically investigate the cybersecurity challenges against the newly emerged smart transformers. This paper addresses this shortcoming by exploring the vulnerabilities and the attack vectors of power transformers within electricity networks, the possible attack scenarios and the risks associated with these attacks.
TimeMAE: Self-Supervised Representations of Time Series with Decoupled Masked Autoencoders
Mar 01, 2023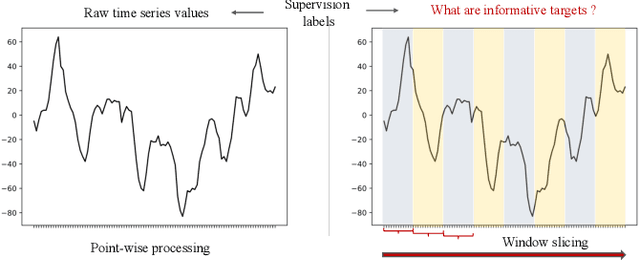

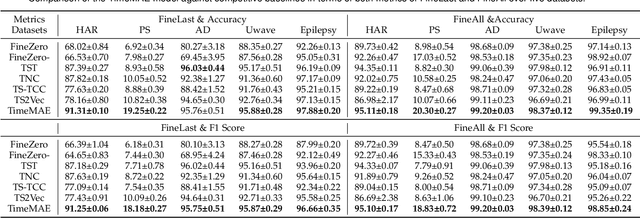
Enhancing the expressive capacity of deep learning-based time series models with self-supervised pre-training has become ever-increasingly prevalent in time series classification. Even though numerous efforts have been devoted to developing self-supervised models for time series data, we argue that the current methods are not sufficient to learn optimal time series representations due to solely unidirectional encoding over sparse point-wise input units. In this work, we propose TimeMAE, a novel self-supervised paradigm for learning transferrable time series representations based on transformer networks. The distinct characteristics of the TimeMAE lie in processing each time series into a sequence of non-overlapping sub-series via window-slicing partitioning, followed by random masking strategies over the semantic units of localized sub-series. Such a simple yet effective setting can help us achieve the goal of killing three birds with one stone, i.e., (1) learning enriched contextual representations of time series with a bidirectional encoding scheme; (2) increasing the information density of basic semantic units; (3) efficiently encoding representations of time series using transformer networks. Nevertheless, it is a non-trivial to perform reconstructing task over such a novel formulated modeling paradigm. To solve the discrepancy issue incurred by newly injected masked embeddings, we design a decoupled autoencoder architecture, which learns the representations of visible (unmasked) positions and masked ones with two different encoder modules, respectively. Furthermore, we construct two types of informative targets to accomplish the corresponding pretext tasks. One is to create a tokenizer module that assigns a codeword to each masked region, allowing the masked codeword classification (MCC) task to be completed effectively...
TAU: A Framework for Video-Based Traffic Analytics Leveraging Artificial Intelligence and Unmanned Aerial Systems
Mar 01, 2023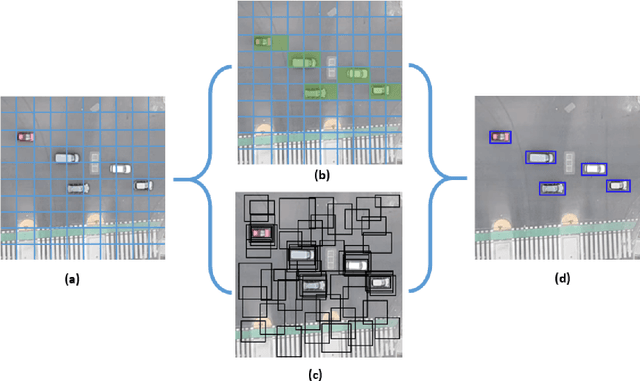

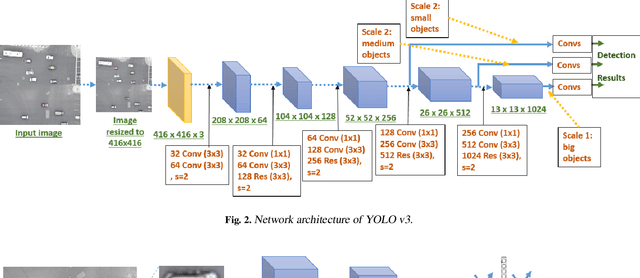

Smart traffic engineering and intelligent transportation services are in increasing demand from governmental authorities to optimize traffic performance and thus reduce energy costs, increase the drivers' safety and comfort, ensure traffic laws enforcement, and detect traffic violations. In this paper, we address this challenge, and we leverage the use of Artificial Intelligence (AI) and Unmanned Aerial Vehicles (UAVs) to develop an AI-integrated video analytics framework, called TAU (Traffic Analysis from UAVs), for automated traffic analytics and understanding. Unlike previous works on traffic video analytics, we propose an automated object detection and tracking pipeline from video processing to advanced traffic understanding using high-resolution UAV images. TAU combines six main contributions. First, it proposes a pre-processing algorithm to adapt the high-resolution UAV image as input to the object detector without lowering the resolution. This ensures an excellent detection accuracy from high-quality features, particularly the small size of detected objects from UAV images. Second, it introduces an algorithm for recalibrating the vehicle coordinates to ensure that vehicles are uniquely identified and tracked across the multiple crops of the same frame. Third, it presents a speed calculation algorithm based on accumulating information from successive frames. Fourth, TAU counts the number of vehicles per traffic zone based on the Ray Tracing algorithm. Fifth, TAU has a fully independent algorithm for crossroad arbitration based on the data gathered from the different zones surrounding it. Sixth, TAU introduces a set of algorithms for extracting twenty-four types of insights from the raw data collected. The code is shared here: https://github.com/bilel-bj/TAU. Video demonstrations are provided here: https://youtu.be/wXJV0H7LviU and here: https://youtu.be/kGv0gmtVEbI.
* This is the final proofread version submitted to Elsevier EAAI: please see the published version at: https://doi.org/10.1016/j.engappai.2022.105095
DTW-SiameseNet: Dynamic Time Warped Siamese Network for Mispronunciation Detection and Correction
Mar 01, 2023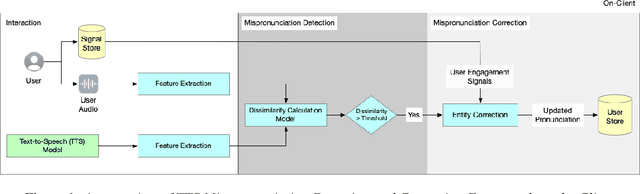
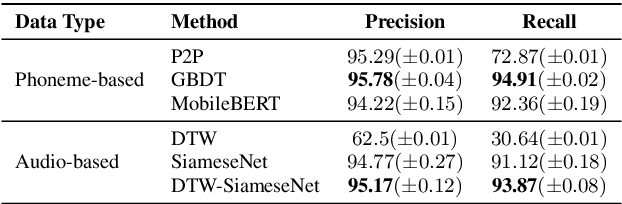

Personal Digital Assistants (PDAs) - such as Siri, Alexa and Google Assistant, to name a few - play an increasingly important role to access information and complete tasks spanning multiple domains, and by diverse groups of users. A text-to-speech (TTS) module allows PDAs to interact in a natural, human-like manner, and play a vital role when the interaction involves people with visual impairments or other disabilities. To cater to the needs of a diverse set of users, inclusive TTS is important to recognize and pronounce correctly text in different languages and dialects. Despite great progress in speech synthesis, the pronunciation accuracy of named entities in a multi-lingual setting still has a large room for improvement. Existing approaches to correct named entity (NE) mispronunciations, like retraining Grapheme-to-Phoneme (G2P) models, or maintaining a TTS pronunciation dictionary, require expensive annotation of the ground truth pronunciation, which is also time consuming. In this work, we present a highly-precise, PDA-compatible pronunciation learning framework for the task of TTS mispronunciation detection and correction. In addition, we also propose a novel mispronunciation detection model called DTW-SiameseNet, which employs metric learning with a Siamese architecture for Dynamic Time Warping (DTW) with triplet loss. We demonstrate that a locale-agnostic, privacy-preserving solution to the problem of TTS mispronunciation detection is feasible. We evaluate our approach on a real-world dataset, and a corpus of NE pronunciations of an anonymized audio dataset of person names recorded by participants from 10 different locales. Human evaluation shows our proposed approach improves pronunciation accuracy on average by ~6% compared to strong phoneme-based and audio-based baselines.
Neural Document Unwarping using Coupled Grids
Feb 06, 2023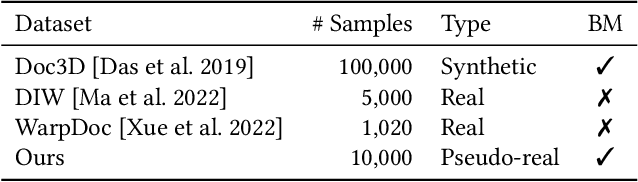
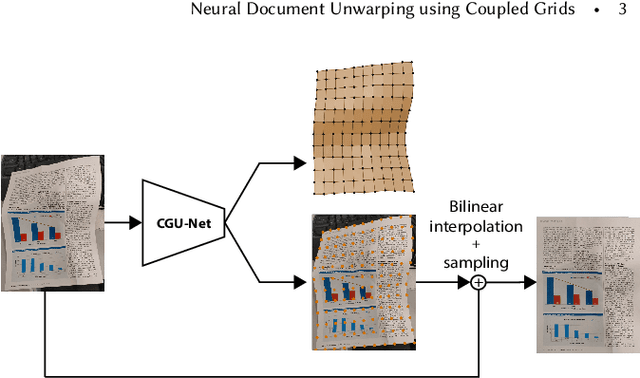
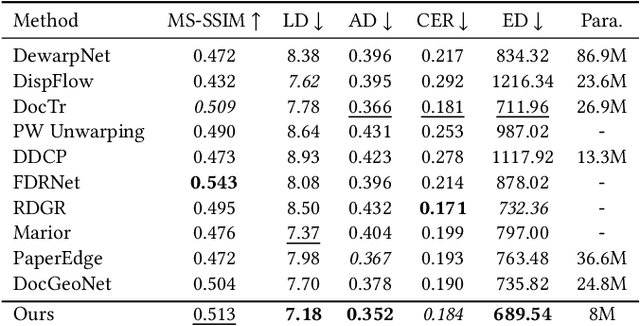

Restoring the original, flat appearance of a printed document from casual photographs of bent and wrinkled pages is a common everyday problem. In this paper we propose a novel method for grid-based single-image document unwarping. Our method performs geometric distortion correction via a deep fully convolutional neural network that learns to predict the 3D grid mesh of the document and the corresponding 2D unwarping grid in a multi-task fashion, implicitly encoding the coupling between the shape of a 3D object and its 2D image. We additionally create and publish our own dataset, called UVDoc, which combines pseudo-photorealistic document images with ground truth grid-based physical 3D and unwarping information, allowing unwarping models to train on data that is more realistic in appearance than the commonly used synthetic Doc3D dataset, whilst also being more physically accurate. Our dataset is labeled with all the information necessary to train our unwarping network, without having to engineer separate loss functions that can deal with the lack of ground-truth typically found in document in the wild datasets. We include a thorough evaluation that demonstrates that our dual-task unwarping network trained on a mix of synthetic and pseudo-photorealistic images achieves state-of-the-art performance on the DocUNet benchmark dataset. Our code, results and UVDoc dataset will be made publicly available upon publication.
How to DP-fy ML: A Practical Guide to Machine Learning with Differential Privacy
Mar 02, 2023
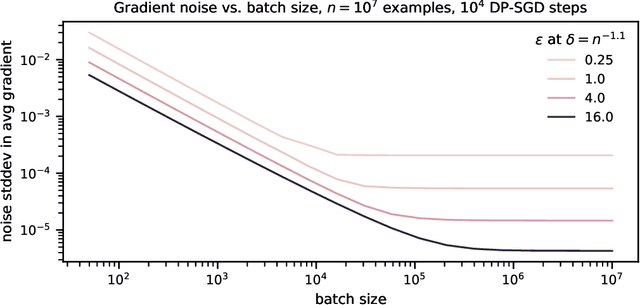

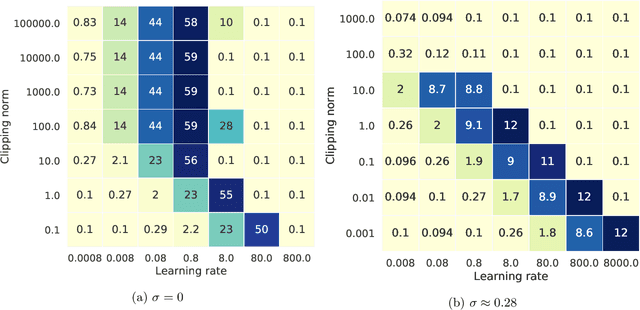
ML models are ubiquitous in real world applications and are a constant focus of research. At the same time, the community has started to realize the importance of protecting the privacy of ML training data. Differential Privacy (DP) has become a gold standard for making formal statements about data anonymization. However, while some adoption of DP has happened in industry, attempts to apply DP to real world complex ML models are still few and far between. The adoption of DP is hindered by limited practical guidance of what DP protection entails, what privacy guarantees to aim for, and the difficulty of achieving good privacy-utility-computation trade-offs for ML models. Tricks for tuning and maximizing performance are scattered among papers or stored in the heads of practitioners. Furthermore, the literature seems to present conflicting evidence on how and whether to apply architectural adjustments and which components are "safe" to use with DP. This work is a self-contained guide that gives an in-depth overview of the field of DP ML and presents information about achieving the best possible DP ML model with rigorous privacy guarantees. Our target audience is both researchers and practitioners. Researchers interested in DP for ML will benefit from a clear overview of current advances and areas for improvement. We include theory-focused sections that highlight important topics such as privacy accounting and its assumptions, and convergence. For a practitioner, we provide a background in DP theory and a clear step-by-step guide for choosing an appropriate privacy definition and approach, implementing DP training, potentially updating the model architecture, and tuning hyperparameters. For both researchers and practitioners, consistently and fully reporting privacy guarantees is critical, and so we propose a set of specific best practices for stating guarantees.
Breaking the Curse of Multiagents in a Large State Space: RL in Markov Games with Independent Linear Function Approximation
Mar 02, 2023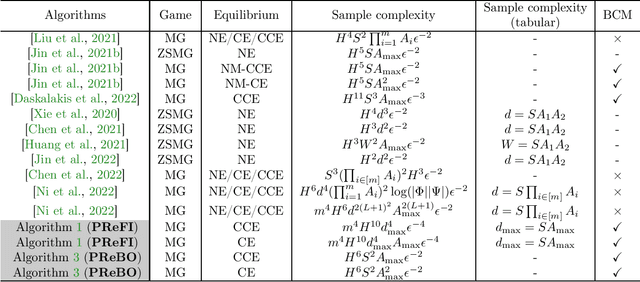
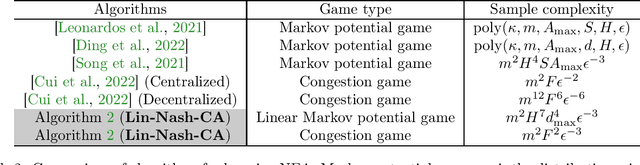
We propose a new model, independent linear Markov game, for multi-agent reinforcement learning with a large state space and a large number of agents. This is a class of Markov games with independent linear function approximation, where each agent has its own function approximation for the state-action value functions that are marginalized by other players' policies. We design new algorithms for learning the Markov coarse correlated equilibria (CCE) and Markov correlated equilibria (CE) with sample complexity bounds that only scale polynomially with each agent's own function class complexity, thus breaking the curse of multiagents. In contrast, existing works for Markov games with function approximation have sample complexity bounds scale with the size of the \emph{joint action space} when specialized to the canonical tabular Markov game setting, which is exponentially large in the number of agents. Our algorithms rely on two key technical innovations: (1) utilizing policy replay to tackle non-stationarity incurred by multiple agents and the use of function approximation; (2) separating learning Markov equilibria and exploration in the Markov games, which allows us to use the full-information no-regret learning oracle instead of the stronger bandit-feedback no-regret learning oracle used in the tabular setting. Furthermore, we propose an iterative-best-response type algorithm that can learn pure Markov Nash equilibria in independent linear Markov potential games. In the tabular case, by adapting the policy replay mechanism for independent linear Markov games, we propose an algorithm with $\widetilde{O}(\epsilon^{-2})$ sample complexity to learn Markov CCE, which improves the state-of-the-art result $\widetilde{O}(\epsilon^{-3})$ in Daskalakis et al. 2022, where $\epsilon$ is the desired accuracy, and also significantly improves other problem parameters.
MLANet: Multi-Level Attention Network with Sub-instruction for Continuous Vision-and-Language Navigation
Mar 02, 2023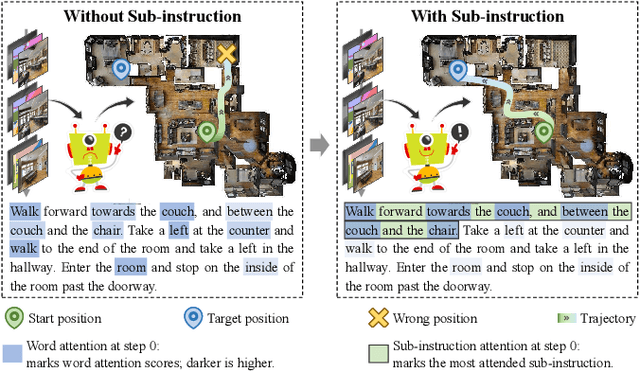
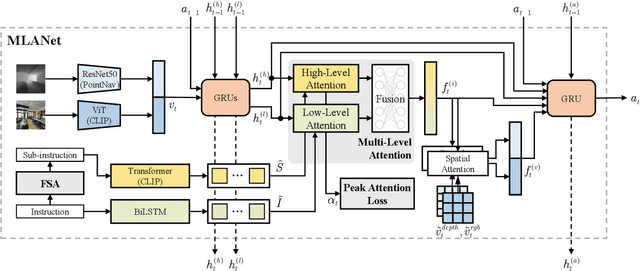
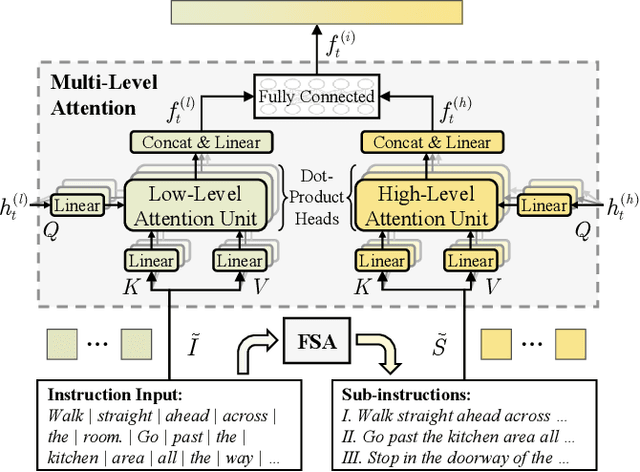
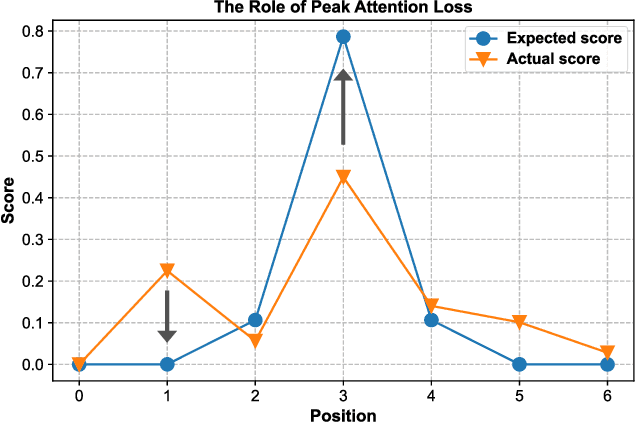
Vision-and-Language Navigation (VLN) aims to develop intelligent agents to navigate in unseen environments only through language and vision supervision. In the recently proposed continuous settings (continuous VLN), the agent must act in a free 3D space and faces tougher challenges like real-time execution, complex instruction understanding, and long action sequence prediction. For a better performance in continuous VLN, we design a multi-level instruction understanding procedure and propose a novel model, Multi-Level Attention Network (MLANet). The first step of MLANet is to generate sub-instructions efficiently. We design a Fast Sub-instruction Algorithm (FSA) to segment the raw instruction into sub-instructions and generate a new sub-instruction dataset named ``FSASub". FSA is annotation-free and faster than the current method by 70 times, thus fitting the real-time requirement in continuous VLN. To solve the complex instruction understanding problem, MLANet needs a global perception of the instruction and observations. We propose a Multi-Level Attention (MLA) module to fuse vision, low-level semantics, and high-level semantics, which produce features containing a dynamic and global comprehension of the task. MLA also mitigates the adverse effects of noise words, thus ensuring a robust understanding of the instruction. To correctly predict actions in long trajectories, MLANet needs to focus on what sub-instruction is being executed every step. We propose a Peak Attention Loss (PAL) to improve the flexible and adaptive selection of the current sub-instruction. PAL benefits the navigation agent by concentrating its attention on the local information, thus helping the agent predict the most appropriate actions. We train and test MLANet in the standard benchmark. Experiment results show MLANet outperforms baselines by a significant margin.
Autonomous particles
Jan 24, 2023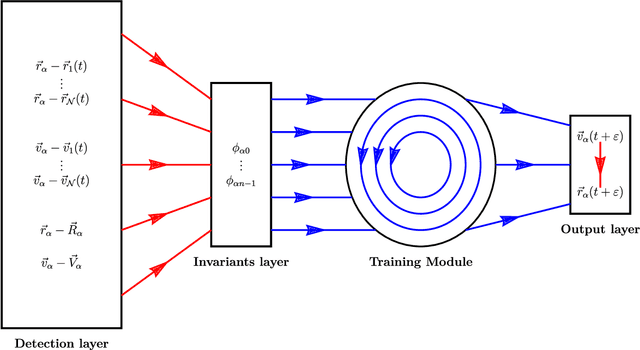
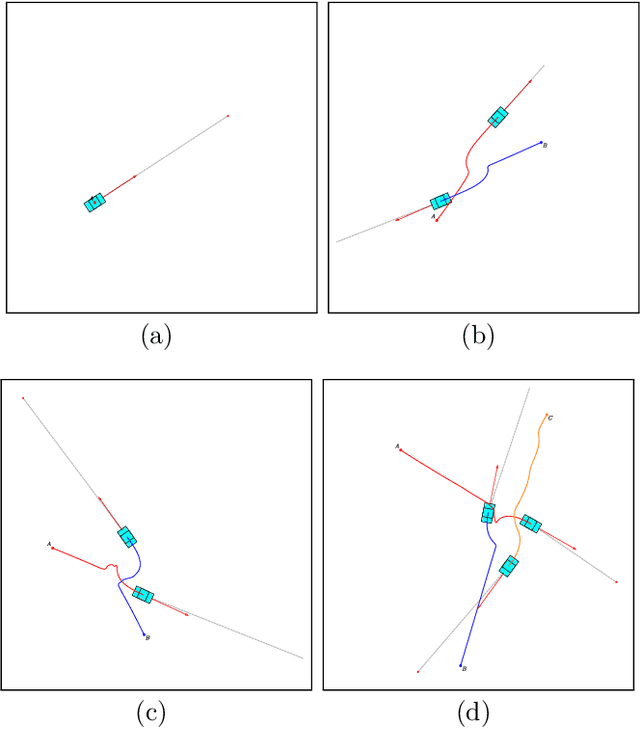
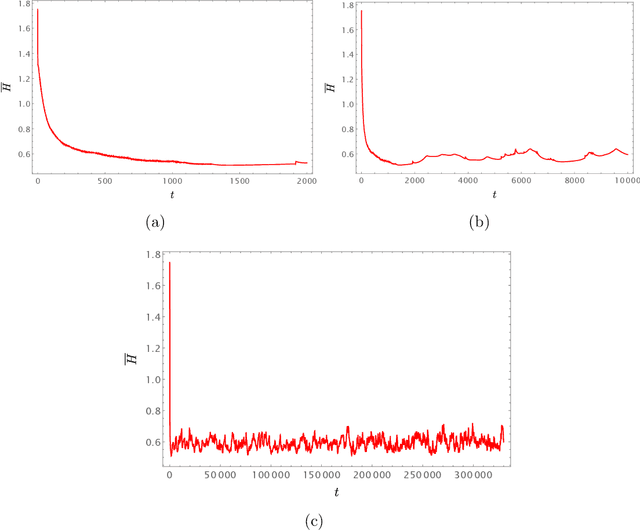
Consider a reinforcement learning problem where an agent has access to a very large amount of information about the environment, but it can only take very few actions to accomplish its task and to maximize its reward. Evidently, the main problem for the agent is to learn a map from a very high-dimensional space (which represents its environment) to a very low-dimensional space (which represents its actions). The high-to-low dimensional map implies that most of the information about the environment is irrelevant for the actions to be taken, and only a small fraction of information is relevant. In this paper we argue that the relevant information need not be learned by brute force (which is the standard approach), but can be identified from the intrinsic symmetries of the system. We analyze in details a reinforcement learning problem of autonomous driving, where the corresponding symmetry is the Galilean symmetry, and argue that the learning task can be accomplished with very few relevant parameters, or, more precisely, invariants. For a numerical demonstration, we show that the autonomous vehicles (which we call autonomous particles since they describe very primitive vehicles) need only four relevant invariants to learn how to drive very well without colliding with other particles. The simple model can be easily generalized to include different types of particles (e.g. for cars, for pedestrians, for buildings, for road signs, etc.) with different types of relevant invariants describing interactions between them. We also argue that there must exist a field theory description of the learning system where autonomous particles would be described by fermionic degrees of freedom and interactions mediated by the relevant invariants would be described by bosonic degrees of freedom.