 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sources of Richness and Ineffability for Phenomenally Conscious States
Mar 01, 2023
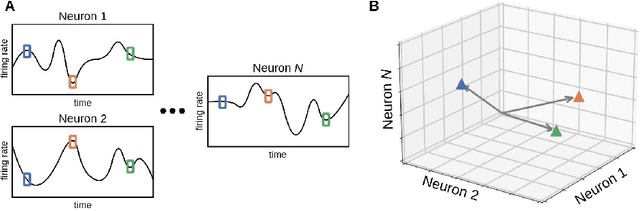
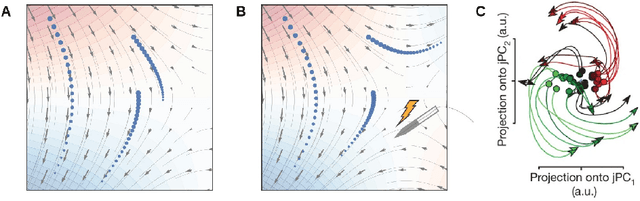
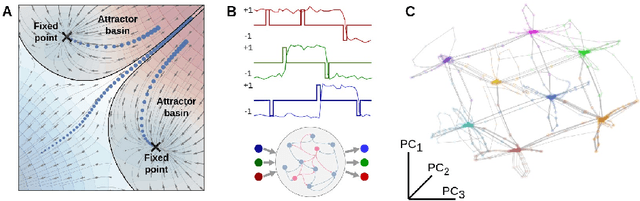
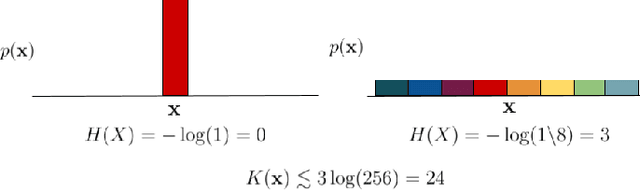
Conscious states (states that there is something it is like to be in) seem both rich or full of detail, and ineffable or hard to fully describe or recall. The problem of ineffability, in particular, is a longstanding issue in philosophy that partly motivates the explanatory gap: the belief that consciousness cannot be reduced to underlying physical processes. Here, we provide an information theoretic dynamical systems perspective on the richness and ineffability of consciousness. In our framework, the richness of conscious experience corresponds to the amount of information in a conscious state and ineffability corresponds to the amount of information lost at different stages of processing. We describe how attractor dynamics in working memory would induce impoverished recollections of our original experiences, how the discrete symbolic nature of language is insufficient for describing the rich and high-dimensional structure of experiences, and how similarity in the cognitive function of two individuals relates to improved communicability of their experiences to each other. While our model may not settle all questions relating to the explanatory gap, it makes progress toward a fully physicalist explanation of the richness and ineffability of conscious experience: two important aspects that seem to be part of what makes qualitative character so puzzling.
Enhancing Vital Sign Estimation Performance of FMCW MIMO Radar by Prior Human Shape Recognition
Mar 16, 2023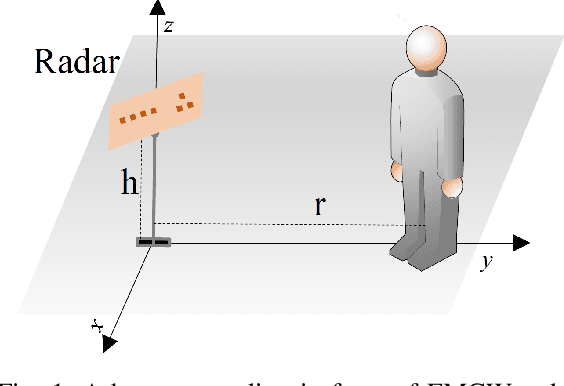
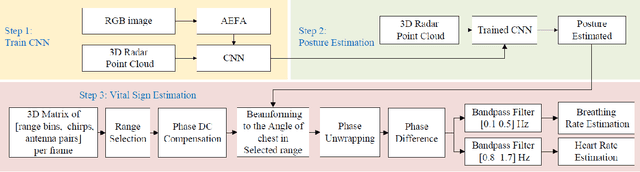
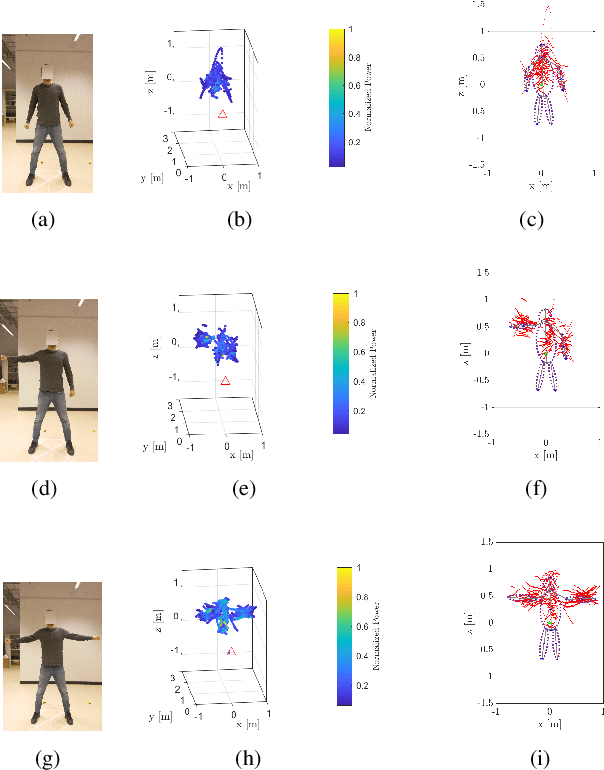
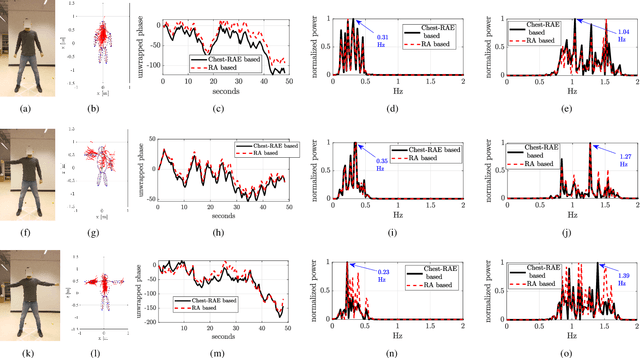
Radio technology enabled contact-free human posture and vital sign estimation is promising for health monitoring. Radio systems at millimeter-wave (mmWave) frequencies advantageously bring large bandwidth, multi-antenna array and beam steering capability. \textit{However}, the human point cloud obtained by mmWave radar and utilized for posture estimation is likely to be sparse and incomplete. Additionally, human's random body movements deteriorate the estimation of breathing and heart rates, therefore the information of the chest location and a narrow radar beam toward the chest are demanded for more accurate vital sign estimation. In this paper, we propose a pipeline aiming to enhance the vital sign estimation performance of mmWave FMCW MIMO radar. The first step is to recognize human body part and posture, where we exploit a trained Convolutional Neural Networks (CNN) to efficiently process the imperfect human form point cloud. The CNN framework outputs the key point of different body parts, and was trained by using RGB image reference and Augmentative Ellipse Fitting Algorithm (AEFA). The next step is to utilize the chest information of the prior estimated human posture for vital sign estimation. While CNN is initially trained based on the frame-by-frame point clouds of human for posture estimation, the vital signs are extracted through beamforming toward the human chest. The numerical results show that this spatial filtering improves the estimation of the vital signs in regard to lowering the level of side harmonics and detecting the harmonics of vital signs efficiently, i.e., peak-to-average power ratio in the harmonics of vital signal is improved up to 0.02 and 0.07dB for the studied cases.
Decentralized Multi-Agent Reinforcement Learning for Continuous-Space Stochastic Games
Mar 16, 2023
Stochastic games are a popular framework for studying multi-agent reinforcement learning (MARL). Recent advances in MARL have focused primarily on games with finitely many states. In this work, we study multi-agent learning in stochastic games with general state spaces and an information structure in which agents do not observe each other's actions. In this context, we propose a decentralized MARL algorithm and we prove the near-optimality of its policy updates. Furthermore, we study the global policy-updating dynamics for a general class of best-reply based algorithms and derive a closed-form characterization of convergence probabilities over the joint policy space.
A Simple Temporal Information Matching Mechanism for Entity Alignment Between Temporal Knowledge Graphs
Sep 20, 2022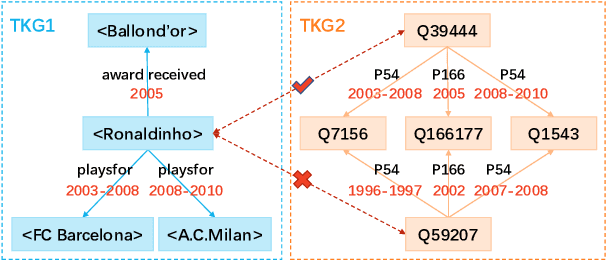

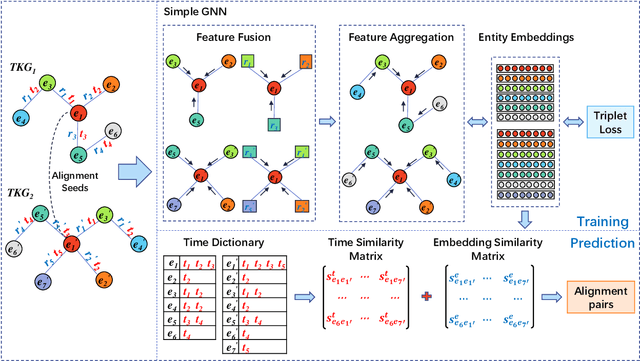
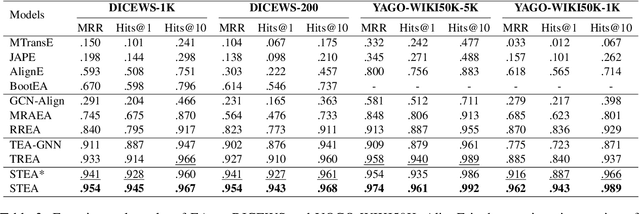
Entity alignment (EA) aims to find entities in different knowledge graphs (KGs) that refer to the same object in the real world. Recent studies incorporate temporal information to augment the representations of KGs. The existing methods for EA between temporal KGs (TKGs) utilize a time-aware attention mechanism to incorporate relational and temporal information into entity embeddings. The approaches outperform the previous methods by using temporal information. However, we believe that it is not necessary to learn the embeddings of temporal information in KGs since most TKGs have uniform temporal representations. Therefore, we propose a simple graph neural network (GNN) model combined with a temporal information matching mechanism, which achieves better performance with less time and fewer parameters. Furthermore, since alignment seeds are difficult to label in real-world applications, we also propose a method to generate unsupervised alignment seeds via the temporal information of TKG. Extensive experiments on public datasets indicate that our supervised method significantly outperforms the previous methods and the unsupervised one has competitive performance.
DejaVu: Conditional Regenerative Learning to Enhance Dense Prediction
Mar 02, 2023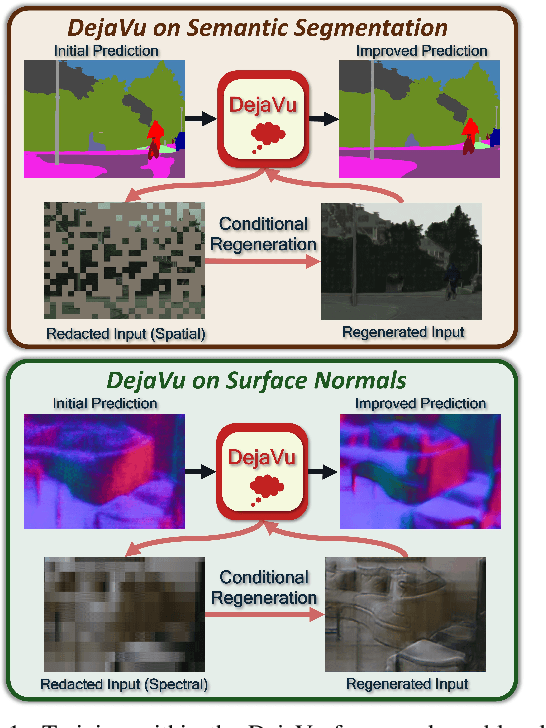
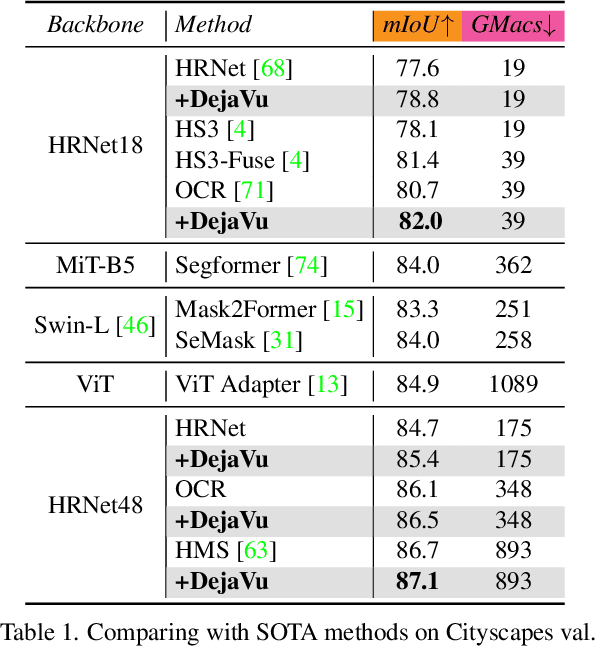
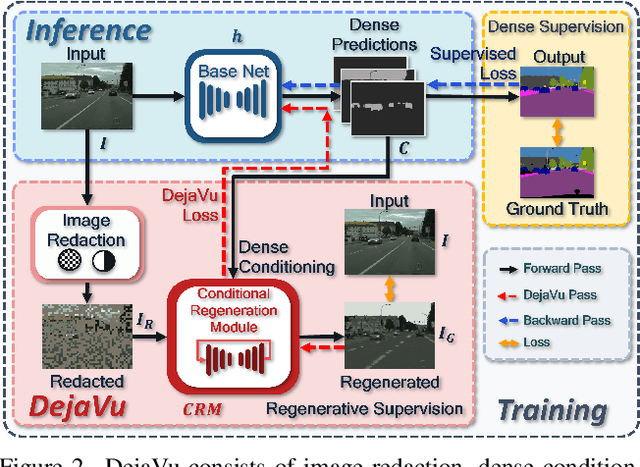
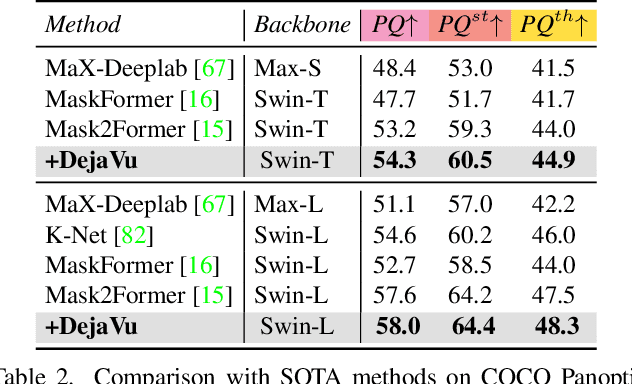
We present DejaVu, a novel framework which leverages conditional image regeneration as additional supervision during training to improve deep networks for dense prediction tasks such as segmentation, depth estimation, and surface normal prediction. First, we apply redaction to the input image, which removes certain structural information by sparse sampling or selective frequency removal. Next, we use a conditional regenerator, which takes the redacted image and the dense predictions as inputs, and reconstructs the original image by filling in the missing structural information. In the redacted image, structural attributes like boundaries are broken while semantic context is largely preserved. In order to make the regeneration feasible, the conditional generator will then require the structure information from the other input source, i.e., the dense predictions. As such, by including this conditional regeneration objective during training, DejaVu encourages the base network to learn to embed accurate scene structure in its dense prediction. This leads to more accurate predictions with clearer boundaries and better spatial consistency. When it is feasible to leverage additional computation, DejaVu can be extended to incorporate an attention-based regeneration module within the dense prediction network, which further improves accuracy. Through extensive experiments on multiple dense prediction benchmarks such as Cityscapes, COCO, ADE20K, NYUD-v2, and KITTI, we demonstrate the efficacy of employing DejaVu during training, as it outperforms SOTA methods at no added computation cost.
Machine Psychology: Investigating Emergent Capabilities and Behavior in Large Language Models Using Psychological Methods
Mar 24, 2023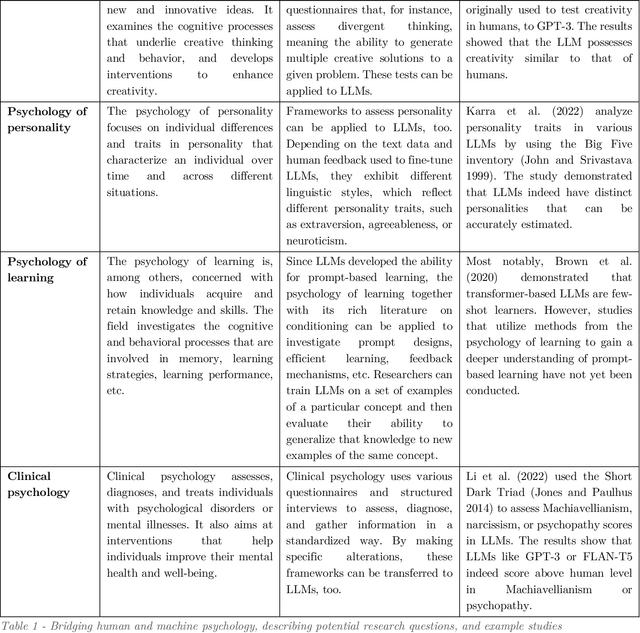

Large language models (LLMs) are currently at the forefront of intertwining AI systems with human communication and everyday life. Due to rapid technological advances and their extreme versatility, LLMs nowadays have millions of users and are at the cusp of being the main go-to technology for information retrieval, content generation, problem-solving, etc. Therefore, it is of great importance to thoroughly assess and scrutinize their capabilities. Due to increasingly complex and novel behavioral patterns in current LLMs, this can be done by treating them as participants in psychology experiments that were originally designed to test humans. For this purpose, the paper introduces a new field of research called "machine psychology". The paper outlines how different subfields of psychology can inform behavioral tests for LLMs. It defines methodological standards for machine psychology research, especially by focusing on policies for prompt designs. Additionally, it describes how behavioral patterns discovered in LLMs are to be interpreted. In sum, machine psychology aims to discover emergent abilities in LLMs that cannot be detected by most traditional natural language processing benchmarks.
PIAT: Parameter Interpolation based Adversarial Training for Image Classification
Mar 24, 2023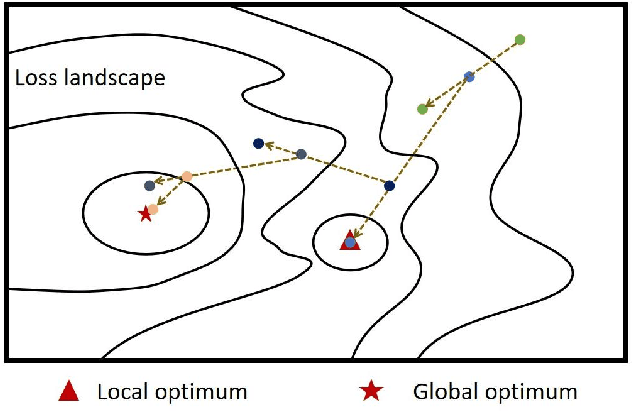
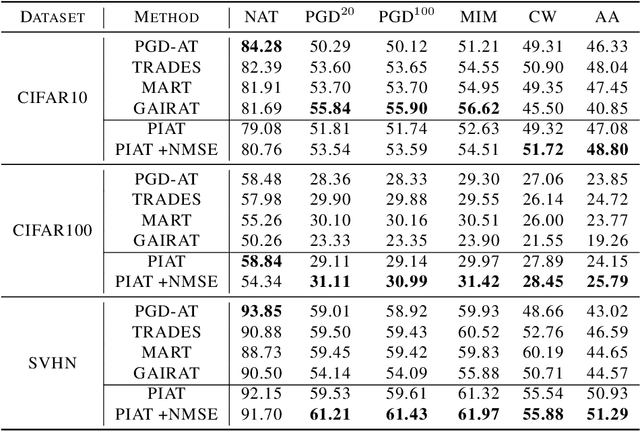
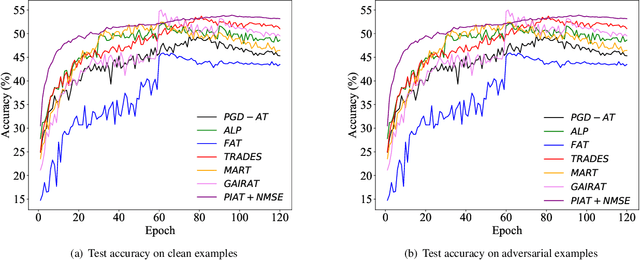
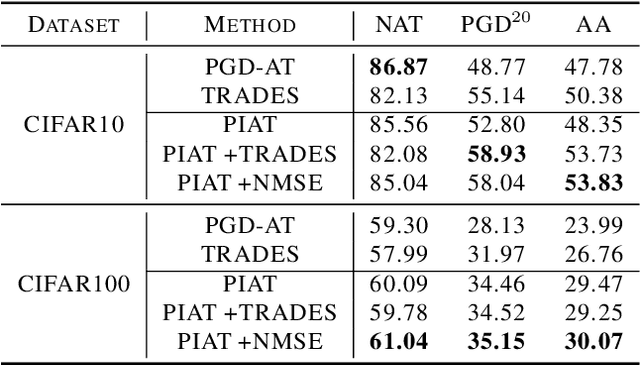
Adversarial training has been demonstrated to be the most effective approach to defend against adversarial attacks. However, existing adversarial training methods show apparent oscillations and overfitting issue in the training process, degrading the defense efficacy. In this work, we propose a novel framework, termed Parameter Interpolation based Adversarial Training (PIAT), that makes full use of the historical information during training. Specifically, at the end of each epoch, PIAT tunes the model parameters as the interpolation of the parameters of the previous and current epochs. Besides, we suggest to use the Normalized Mean Square Error (NMSE) to further improve the robustness by aligning the clean and adversarial examples. Compared with other regularization methods, NMSE focuses more on the relative magnitude of the logits rather than the absolute magnitude. Extensive experiments on several benchmark datasets and various networks show that our method could prominently improve the model robustness and reduce the generalization error. Moreover, our framework is general and could further boost the robust accuracy when combined with other adversarial training methods.
Dynamic Spatial-temporal Hypergraph Convolutional Network for Skeleton-based Action Recognition
Feb 17, 2023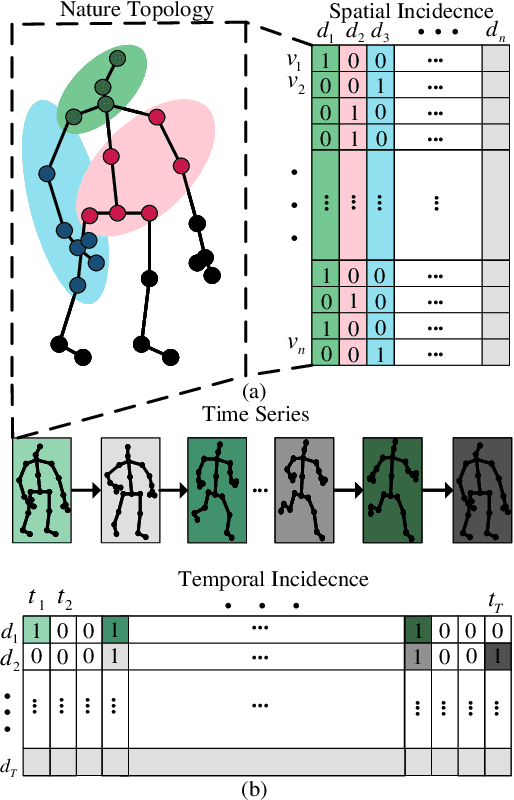
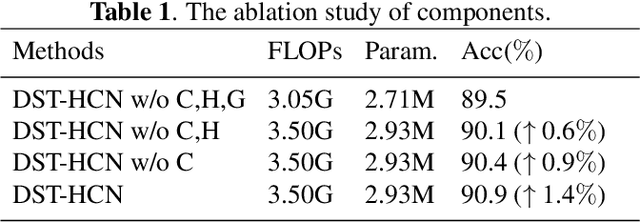
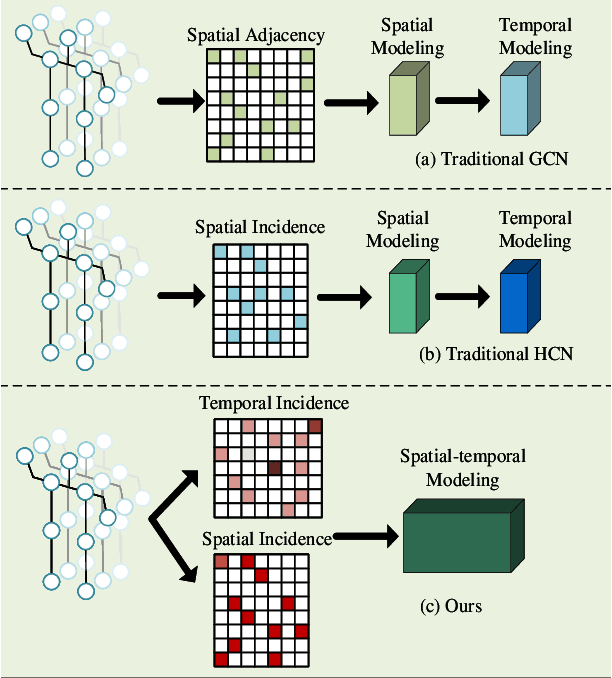

Skeleton-based action recognition relies on the extraction of spatial-temporal topological information. Hypergraphs can establish prior unnatural dependencies for the skeleton. However, the existing methods only focus on the construction of spatial topology and ignore the time-point dependence. This paper proposes a dynamic spatial-temporal hypergraph convolutional network (DST-HCN) to capture spatial-temporal information for skeleton-based action recognition. DST-HCN introduces a time-point hypergraph (TPH) to learn relationships at time points. With multiple spatial static hypergraphs and dynamic TPH, our network can learn more complete spatial-temporal features. In addition, we use the high-order information fusion module (HIF) to fuse spatial-temporal information synchronously. Extensive experiments on NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets show that our model achieves state-of-the-art, especially compared with hypergraph methods.
Improving Scene Text Recognition for Character-Level Long-Tailed Distribution
Mar 31, 2023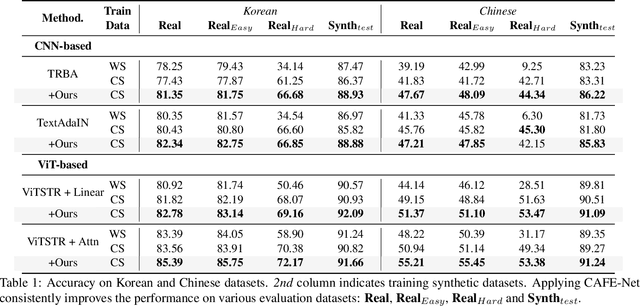
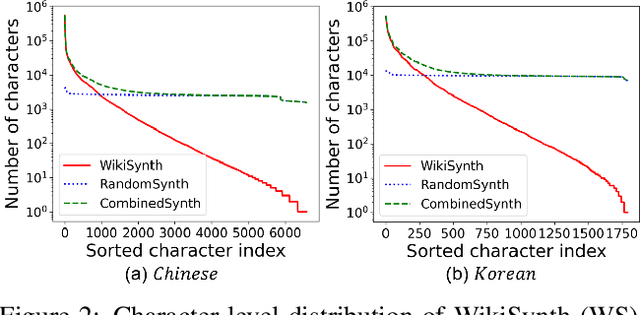
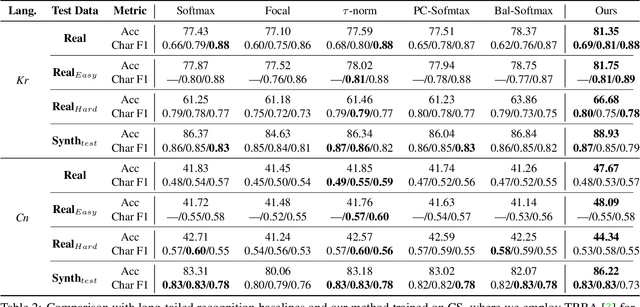
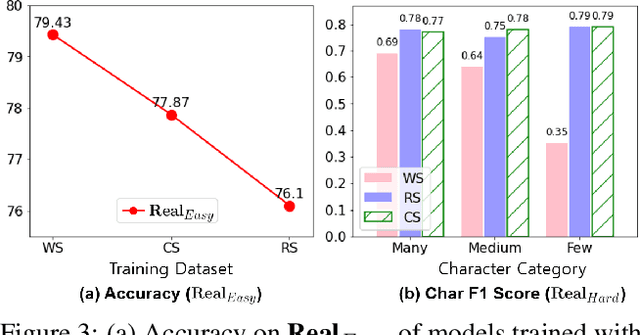
Despite the recent remarkable improvements in scene text recognition (STR), the majority of the studies focused mainly on the English language, which only includes few number of characters. However, STR models show a large performance degradation on languages with a numerous number of characters (e.g., Chinese and Korean), especially on characters that rarely appear due to the long-tailed distribution of characters in such languages. To address such an issue, we conducted an empirical analysis using synthetic datasets with different character-level distributions (e.g., balanced and long-tailed distributions). While increasing a substantial number of tail classes without considering the context helps the model to correctly recognize characters individually, training with such a synthetic dataset interferes the model with learning the contextual information (i.e., relation among characters), which is also important for predicting the whole word. Based on this motivation, we propose a novel Context-Aware and Free Experts Network (CAFE-Net) using two experts: 1) context-aware expert learns the contextual representation trained with a long-tailed dataset composed of common words used in everyday life and 2) context-free expert focuses on correctly predicting individual characters by utilizing a dataset with a balanced number of characters. By training two experts to focus on learning contextual and visual representations, respectively, we propose a novel confidence ensemble method to compensate the limitation of each expert. Through the experiments, we demonstrate that CAFE-Net improves the STR performance on languages containing numerous number of characters. Moreover, we show that CAFE-Net is easily applicable to various STR models.
Predictive Context-Awareness for Full-Immersive Multiuser Virtual Reality with Redirected Walking
Mar 31, 2023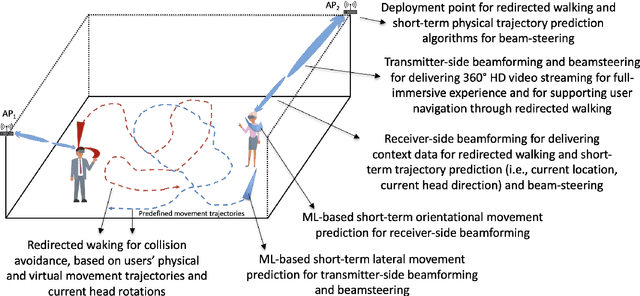
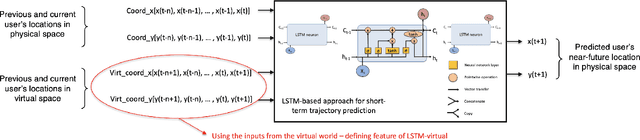
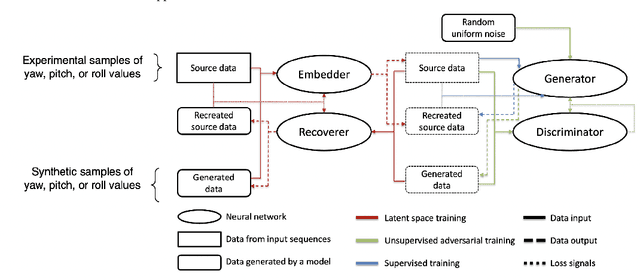
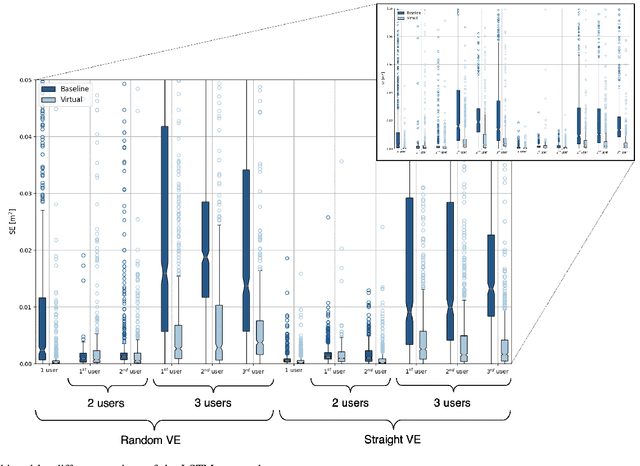
Virtual Reality (VR) technology is being advanced along the lines of enhancing its immersiveness, enabling multiuser Virtual Experiences (VEs), and supporting unconstrained mobility of the users in their VEs, while constraining them within specialized VR setups through Redirected Walking (RDW). For meeting the extreme data-rate and latency requirements of future VR systems, supporting wireless networking infrastructures will operate in millimeter Wave (mmWave) frequencies and leverage highly directional communication in both transmission and reception through beamforming and beamsteering. We propose to leverage predictive context-awareness for optimizing transmitter and receiver-side beamforming and beamsteering. In particular, we argue that short-term prediction of users' lateral movements in multiuser VR setups with RDW can be utilized for optimizing transmitter-side beamforming and beamsteering through Line-of-Sight (LoS) "tracking" in the users' directions. At the same time, short-term prediction of orientational movements can be used for receiver-side beamforming for coverage flexibility enhancements. We target two open problems in predicting these two context information instances: i) lateral movement prediction in multiuser VR settings with RDW and ii) generation of synthetic head rotation datasets to be utilized in the training of existing orientational movements predictors. We follow by experimentally showing that Long Short-Term Memory (LSTM) networks feature promising accuracy in predicting lateral movements, as well as that context-awareness stemming from VEs further benefits this accuracy. Second, we show that a TimeGAN-based approach for orientational data generation can generate synthetic samples closely matching the experimentally obtained ones.