 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Topological Pooling on Graphs
Mar 25, 2023
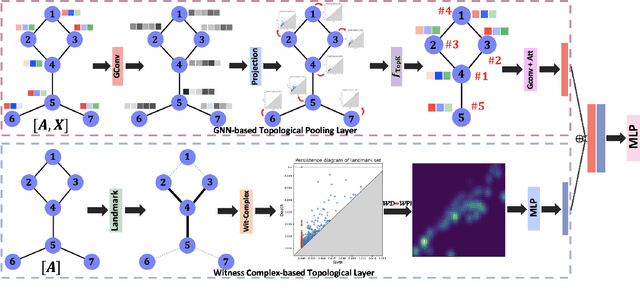
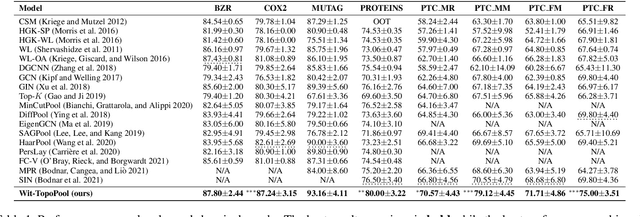
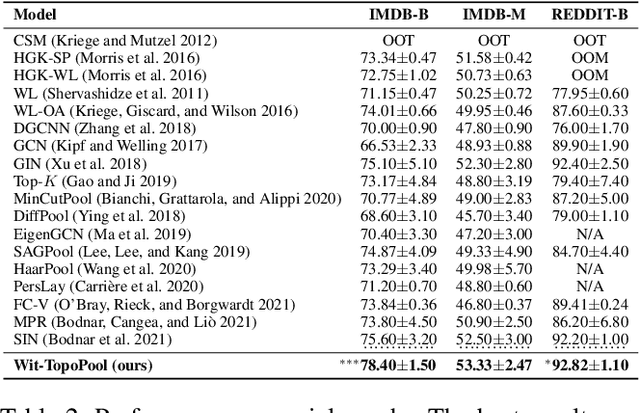
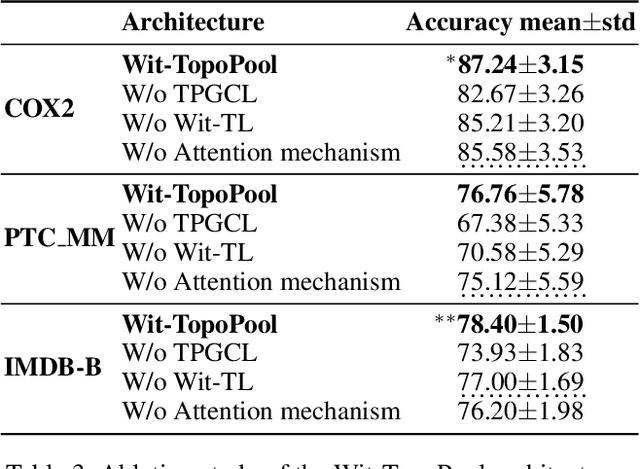
Graph neural networks (GNNs) have demonstrated a significant success in various graph learning tasks, from graph classification to anomaly detection. There recently has emerged a number of approaches adopting a graph pooling operation within GNNs, with a goal to preserve graph attributive and structural features during the graph representation learning. However, most existing graph pooling operations suffer from the limitations of relying on node-wise neighbor weighting and embedding, which leads to insufficient encoding of rich topological structures and node attributes exhibited by real-world networks. By invoking the machinery of persistent homology and the concept of landmarks, we propose a novel topological pooling layer and witness complex-based topological embedding mechanism that allow us to systematically integrate hidden topological information at both local and global levels. Specifically, we design new learnable local and global topological representations Wit-TopoPool which allow us to simultaneously extract rich discriminative topological information from graphs. Experiments on 11 diverse benchmark datasets against 18 baseline models in conjunction with graph classification tasks indicate that Wit-TopoPool significantly outperforms all competitors across all datasets.
Learning with Explanation Constraints
Mar 25, 2023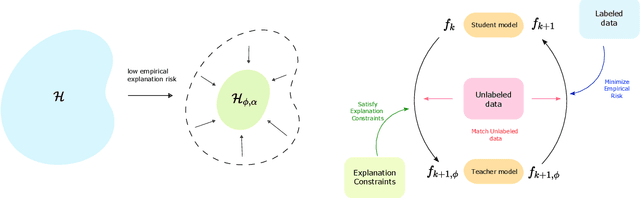
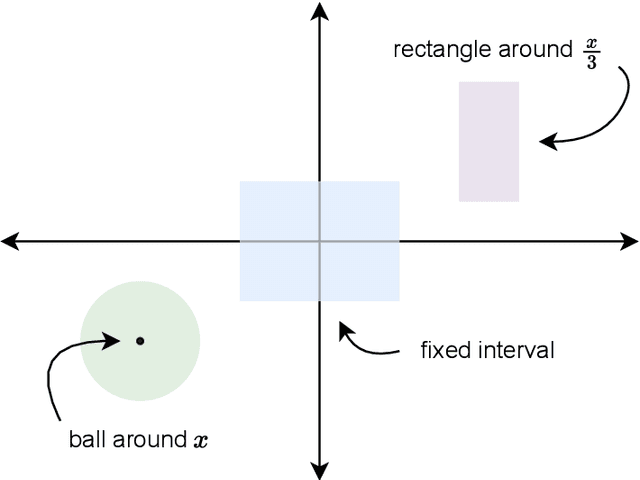
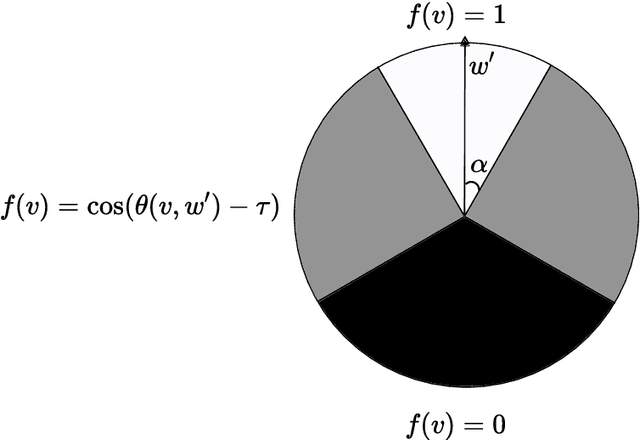
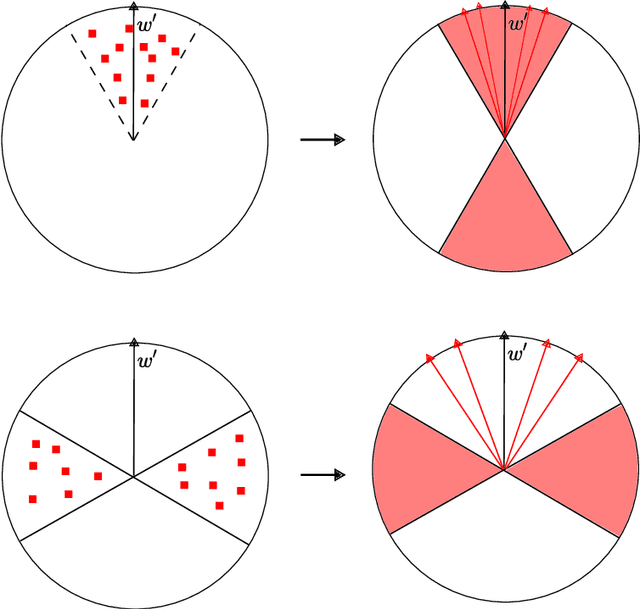
While supervised learning assumes the presence of labeled data, we may have prior information about how models should behave. In this paper, we formalize this notion as learning from explanation constraints and provide a learning theoretic framework to analyze how such explanations can improve the learning of our models. For what models would explanations be helpful? Our first key contribution addresses this question via the definition of what we call EPAC models (models that satisfy these constraints in expectation over new data), and we analyze this class of models using standard learning theoretic tools. Our second key contribution is to characterize these restrictions (in terms of their Rademacher complexities) for a canonical class of explanations given by gradient information for linear models and two layer neural networks. Finally, we provide an algorithmic solution for our framework, via a variational approximation that achieves better performance and satisfies these constraints more frequently, when compared to simpler augmented Lagrangian methods to incorporate these explanations. We demonstrate the benefits of our approach over a large array of synthetic and real-world experiments.
Multi-Object Tracking by Iteratively Associating Detections with Uniform Appearance for Trawl-Based Fishing Bycatch Monitoring
Apr 10, 2023
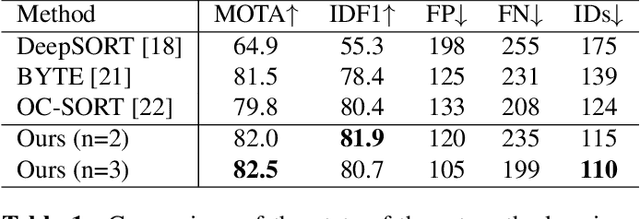

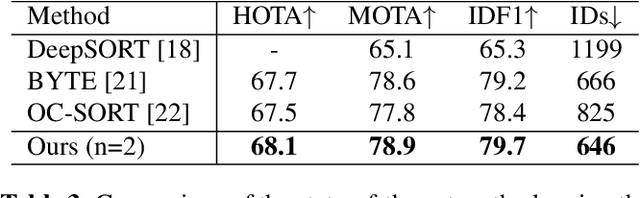
The aim of in-trawl catch monitoring for use in fishing operations is to detect, track and classify fish targets in real-time from video footage. Information gathered could be used to release unwanted bycatch in real-time. However, traditional multi-object tracking (MOT) methods have limitations, as they are developed for tracking vehicles or pedestrians with linear motions and diverse appearances, which are different from the scenarios such as livestock monitoring. Therefore, we propose a novel MOT method, built upon an existing observation-centric tracking algorithm, by adopting a new iterative association step to significantly boost the performance of tracking targets with a uniform appearance. The iterative association module is designed as an extendable component that can be merged into most existing tracking methods. Our method offers improved performance in tracking targets with uniform appearance and outperforms state-of-the-art techniques on our underwater fish datasets as well as the MOT17 dataset, without increasing latency nor sacrificing accuracy as measured by HOTA, MOTA, and IDF1 performance metrics.
coExplore: Combining multiple rankings for multi-robot exploration
Apr 10, 2023

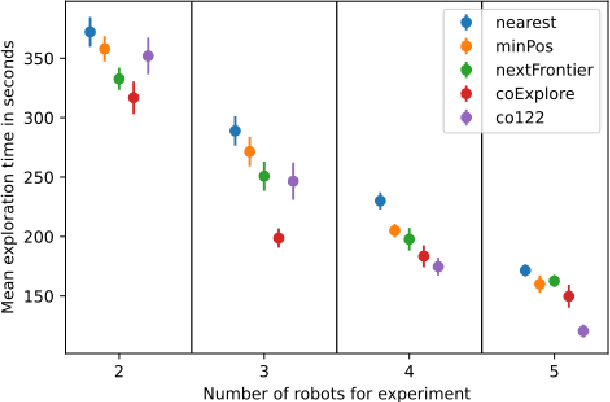
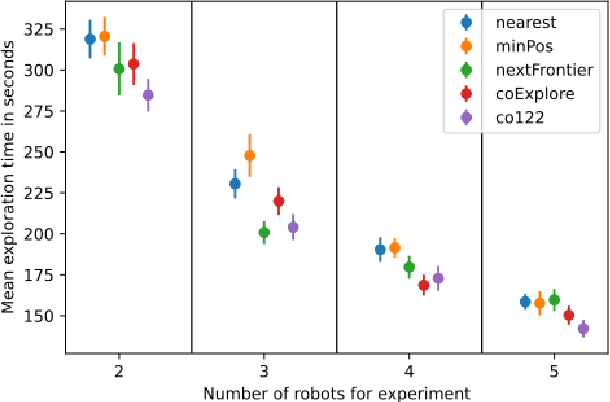
Multi-robot exploration is a field which tackles the challenge of exploring a previously unknown environment with a number of robots. This is especially relevant for search and rescue operations where time is essential. Current state of the art approaches are able to explore a given environment with a large number of robots by assigning them to frontiers. However, this assignment generally favors large frontiers and hence omits potentially valuable medium-sized frontiers. In this paper we showcase a novel multi-robot exploration algorithm, which improves and adapts the existing approaches. Through the addition of information gain based ranking we improve the exploration time for closed urban environments while maintaining similar exploration performance compared to the state-of-the-art for open environments. Accompanying this paper, we further publish our research code in order to lower the barrier to entry for further multi-robot exploration research. We evaluate the performance in three simulated scenarios, two urban and one open scenario, where our algorithm outperforms the state of the art by 5% overall.
Recover Triggered States: Protect Model Against Backdoor Attack in Reinforcement Learning
Apr 10, 2023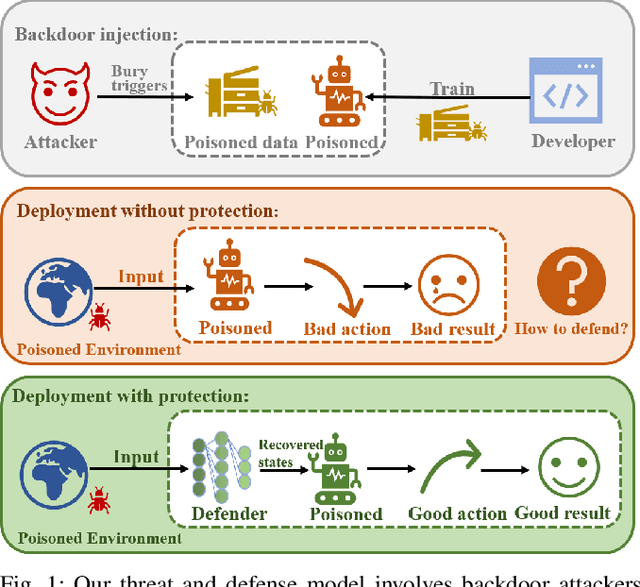
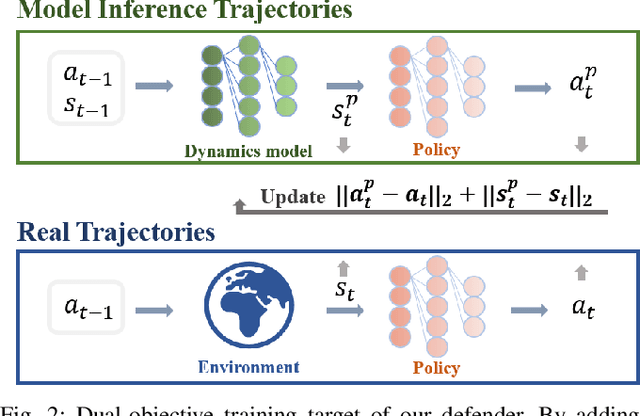
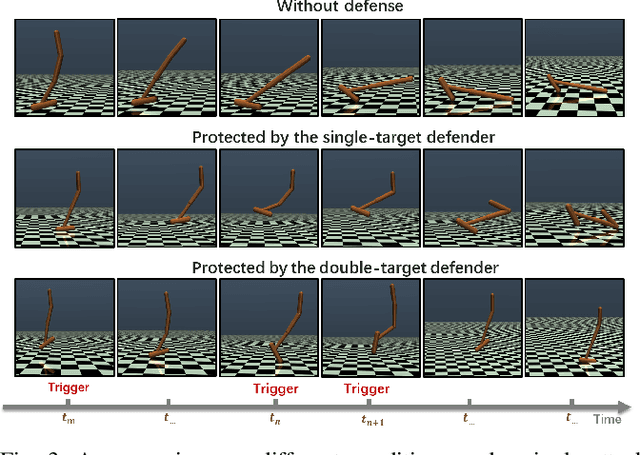
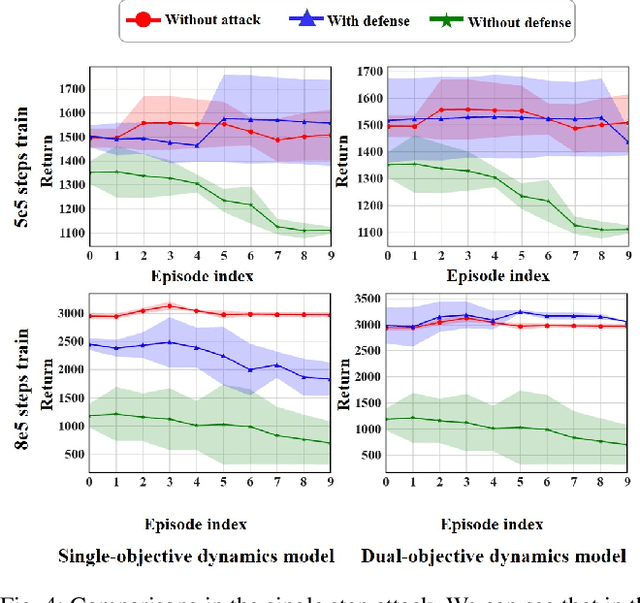
A backdoor attack allows a malicious user to manipulate the environment or corrupt the training data, thus inserting a backdoor into the trained agent. Such attacks compromise the RL system's reliability, leading to potentially catastrophic results in various key fields. In contrast, relatively limited research has investigated effective defenses against backdoor attacks in RL. This paper proposes the Recovery Triggered States (RTS) method, a novel approach that effectively protects the victim agents from backdoor attacks. RTS involves building a surrogate network to approximate the dynamics model. Developers can then recover the environment from the triggered state to a clean state, thereby preventing attackers from activating backdoors hidden in the agent by presenting the trigger. When training the surrogate to predict states, we incorporate agent action information to reduce the discrepancy between the actions taken by the agent on predicted states and the actions taken on real states. RTS is the first approach to defend against backdoor attacks in a single-agent setting. Our results show that using RTS, the cumulative reward only decreased by 1.41% under the backdoor attack.
KERM: Knowledge Enhanced Reasoning for Vision-and-Language Navigation
Mar 28, 2023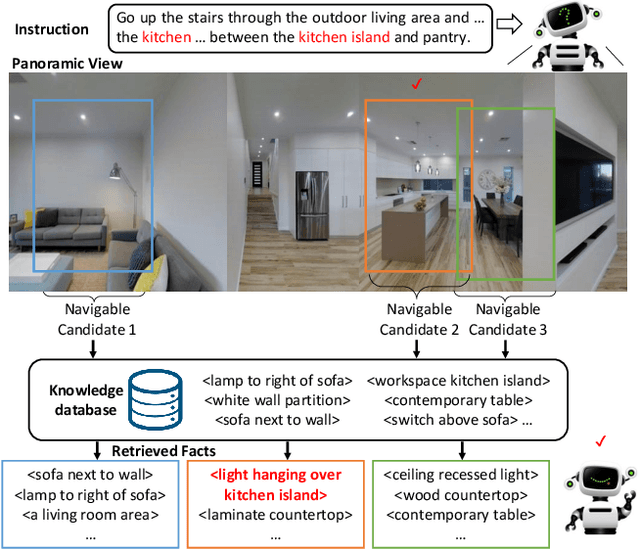
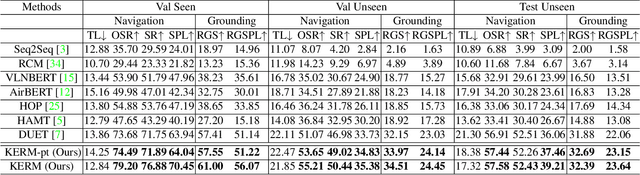
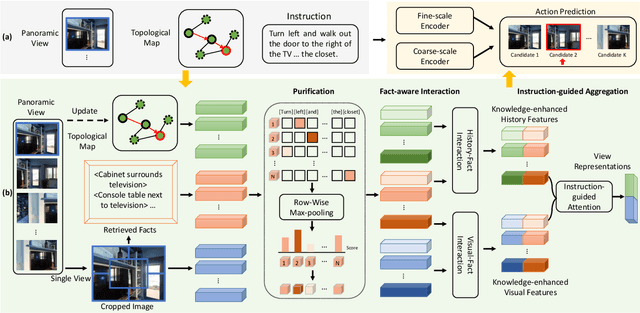
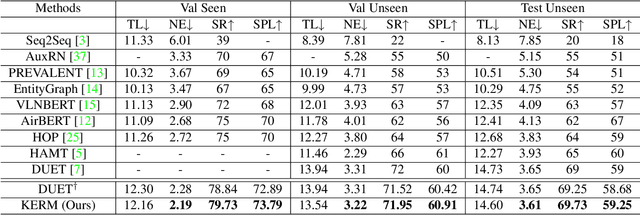
Vision-and-language navigation (VLN) is the task to enable an embodied agent to navigate to a remote location following the natural language instruction in real scenes. Most of the previous approaches utilize the entire features or object-centric features to represent navigable candidates. However, these representations are not efficient enough for an agent to perform actions to arrive the target location. As knowledge provides crucial information which is complementary to visible content, in this paper, we propose a Knowledge Enhanced Reasoning Model (KERM) to leverage knowledge to improve agent navigation ability. Specifically, we first retrieve facts (i.e., knowledge described by language descriptions) for the navigation views based on local regions from the constructed knowledge base. The retrieved facts range from properties of a single object (e.g., color, shape) to relationships between objects (e.g., action, spatial position), providing crucial information for VLN. We further present the KERM which contains the purification, fact-aware interaction, and instruction-guided aggregation modules to integrate visual, history, instruction, and fact features. The proposed KERM can automatically select and gather crucial and relevant cues, obtaining more accurate action prediction. Experimental results on the REVERIE, R2R, and SOON datasets demonstrate the effectiveness of the proposed method.
On Codex Prompt Engineering for OCL Generation: An Empirical Study
Mar 28, 2023
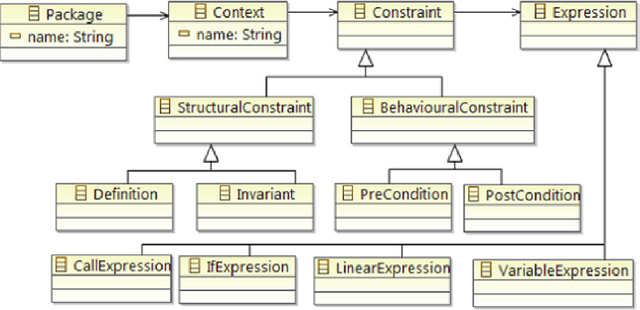
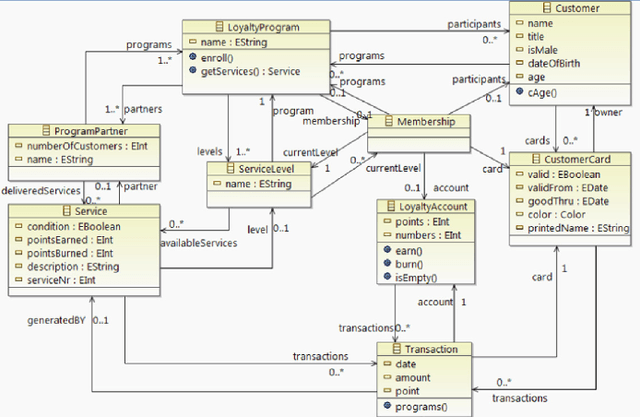
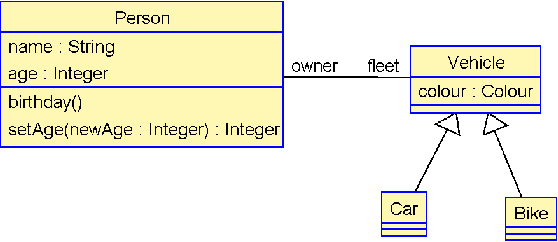
The Object Constraint Language (OCL) is a declarative language that adds constraints and object query expressions to MOF models. Despite its potential to provide precision and conciseness to UML models, the unfamiliar syntax of OCL has hindered its adoption. Recent advancements in LLMs, such as GPT-3, have shown their capability in many NLP tasks, including semantic parsing and text generation. Codex, a GPT-3 descendant, has been fine-tuned on publicly available code from GitHub and can generate code in many programming languages. We investigate the reliability of OCL constraints generated by Codex from natural language specifications. To achieve this, we compiled a dataset of 15 UML models and 168 specifications and crafted a prompt template with slots to populate with UML information and the target task, using both zero- and few-shot learning methods. By measuring the syntactic validity and execution accuracy metrics of the generated OCL constraints, we found that enriching the prompts with UML information and enabling few-shot learning increases the reliability of the generated OCL constraints. Furthermore, the results reveal a close similarity based on sentence embedding between the generated OCL constraints and the human-written ones in the ground truth, implying a level of clarity and understandability in the generated OCL constraints by Codex.
Mask Reference Image Quality Assessment
Mar 19, 2023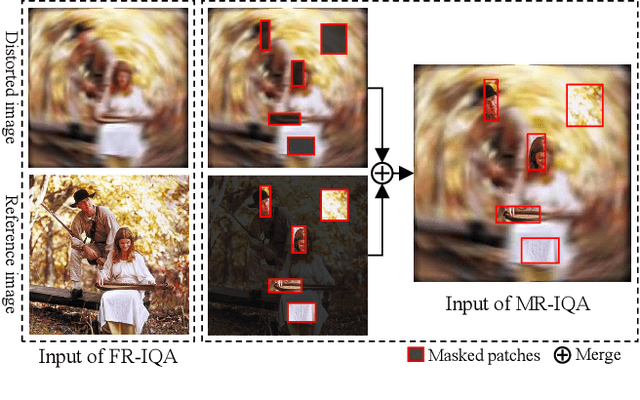

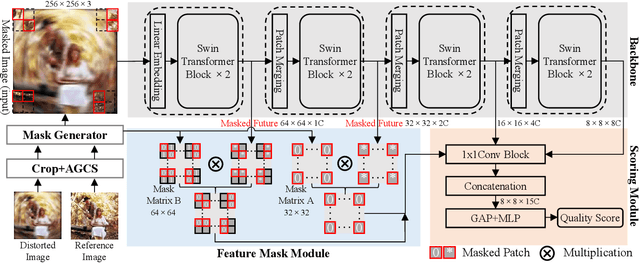
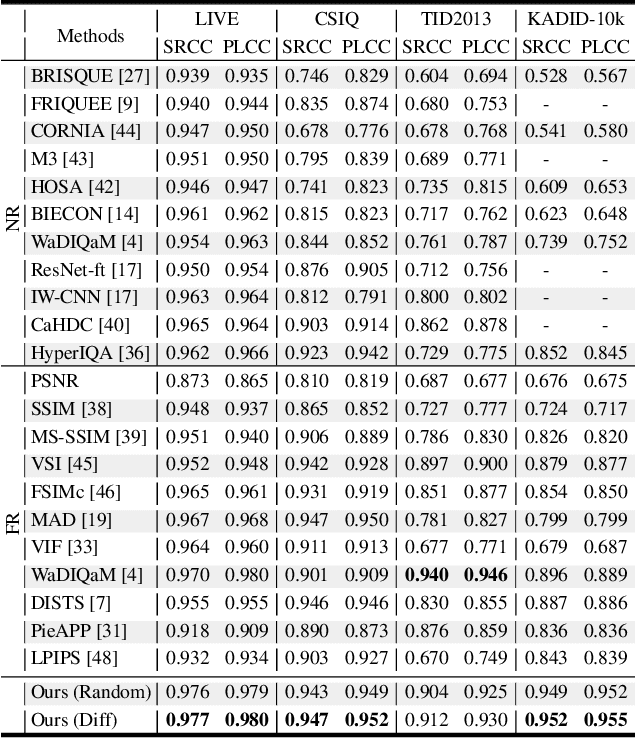
Understanding semantic information is an essential step in knowing what is being learned in both full-reference (FR) and no-reference (NR) image quality assessment (IQA) methods. However, especially for many severely distorted images, even if there is an undistorted image as a reference (FR-IQA), it is difficult to perceive the lost semantic and texture information of distorted images directly. In this paper, we propose a Mask Reference IQA (MR-IQA) method that masks specific patches of a distorted image and supplements missing patches with the reference image patches. In this way, our model only needs to input the reconstructed image for quality assessment. First, we design a mask generator to select the best candidate patches from reference images and supplement the lost semantic information in distorted images, thus providing more reference for quality assessment; in addition, the different masked patches imply different data augmentations, which favors model training and reduces overfitting. Second, we provide a Mask Reference Network (MRNet): the dedicated modules can prevent disturbances due to masked patches and help eliminate the patch discontinuity in the reconstructed image. Our method achieves state-of-the-art performances on the benchmark KADID-10k, LIVE and CSIQ datasets and has better generalization performance across datasets. The code and results are available in the supplementary material.
Crowdsourcing on Sensitive Data with Privacy-Preserving Text Rewriting
Mar 06, 2023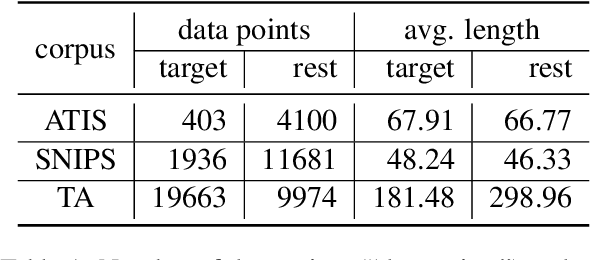
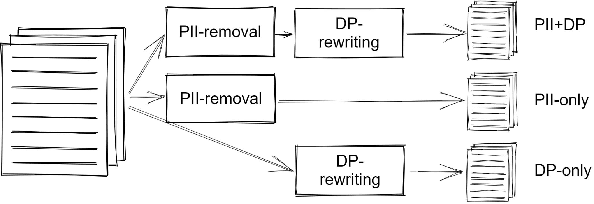
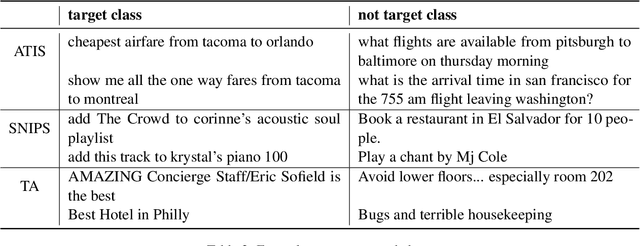
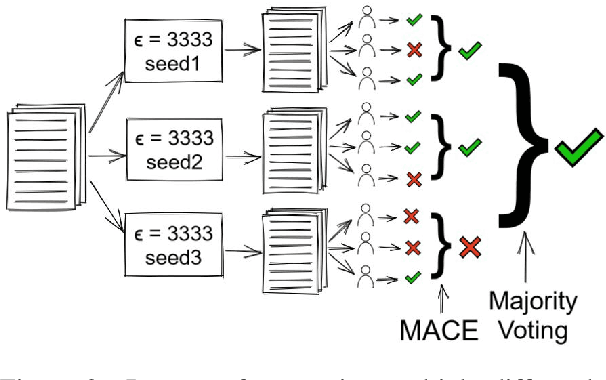
Most tasks in NLP require labeled data. Data labeling is often done on crowdsourcing platforms due to scalability reasons. However, publishing data on public platforms can only be done if no privacy-relevant information is included. Textual data often contains sensitive information like person names or locations. In this work, we investigate how removing personally identifiable information (PII) as well as applying differential privacy (DP) rewriting can enable text with privacy-relevant information to be used for crowdsourcing. We find that DP-rewriting before crowdsourcing can preserve privacy while still leading to good label quality for certain tasks and data. PII-removal led to good label quality in all examined tasks, however, there are no privacy guarantees given.
Dynamic Crowd Vetting: Collaborative Detection of Malicious Robots in Dynamic Communication Networks
Apr 02, 2023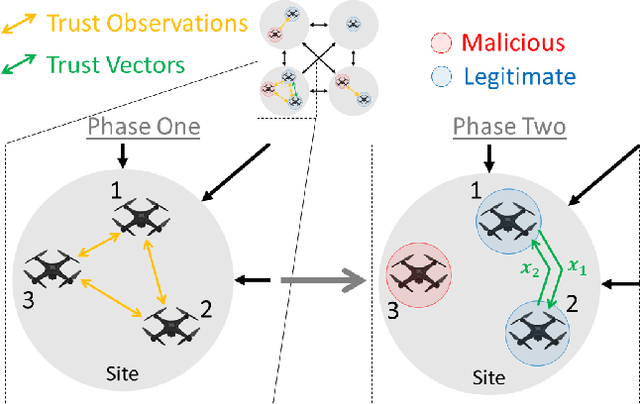
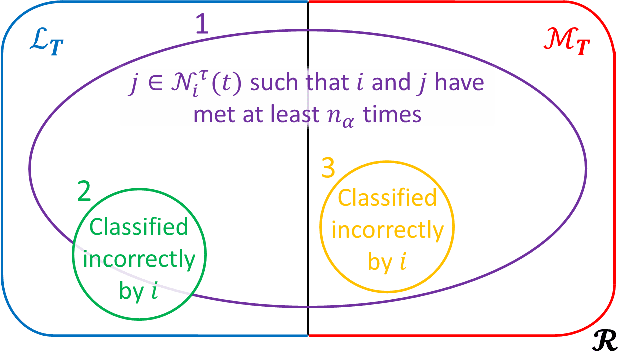
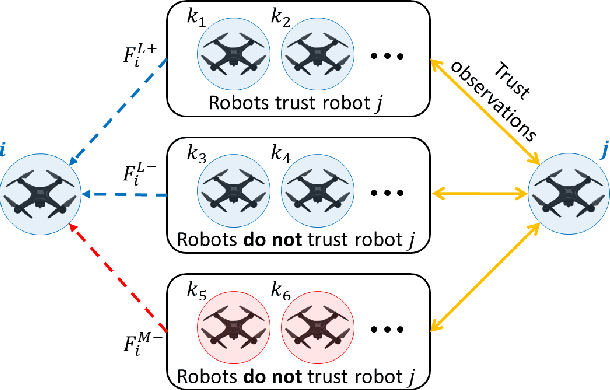
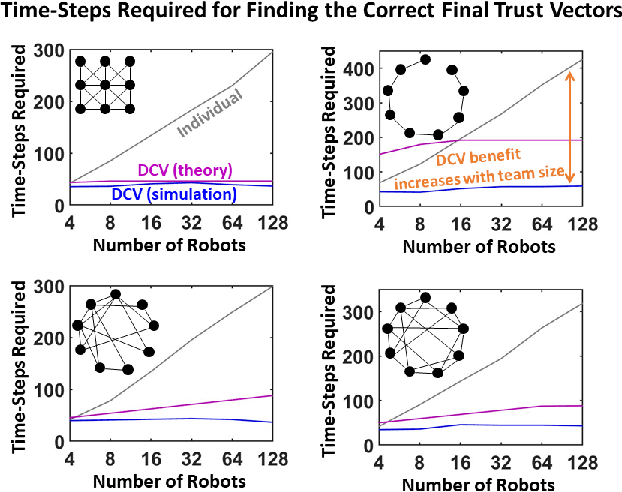
Coordination in a large number of networked robots is a challenging task, especially when robots are constantly moving around the environment and there are malicious attacks within the network. Various approaches in the literature exist for detecting malicious robots, such as message sampling or suspicious behavior analysis. However, these approaches require every robot to sample every other robot in the network, leading to a slow detection process that degrades team performance. This paper introduces a method that significantly decreases the detection time for legitimate robots to identify malicious robots in a scenario where legitimate robots are randomly moving around the environment. Our method leverages the concept of ``Dynamic Crowd Vetting" by utilizing observations from random encounters and trusted neighboring robots' opinions to quickly improve the accuracy of detecting malicious robots. The key intuition is that as long as each legitimate robot accurately estimates the legitimacy of at least some fixed subset of the team, the second-hand information they receive from trusted neighbors is enough to correct any misclassifications and provide accurate trust estimations of the rest of the team. We show that the size of this fixed subset can be characterized as a function of fundamental graph and random walk properties. Furthermore, we formally show that as the number of robots in the team increases the detection time remains constant. We develop a closed form expression for the critical number of time-steps required for our algorithm to successfully identify the true legitimacy of each robot to within a specified failure probability. Our theoretical results are validated through simulations demonstrating significant reductions in detection time when compared to previous works that do not leverage trusted neighbor information.