 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SDVRF: Sparse-to-Dense Voxel Region Fusion for Multi-modal 3D Object Detection
May 02, 2023
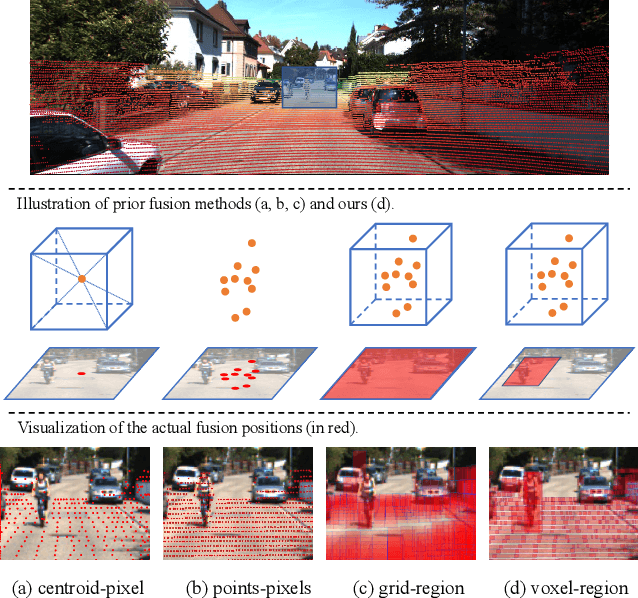
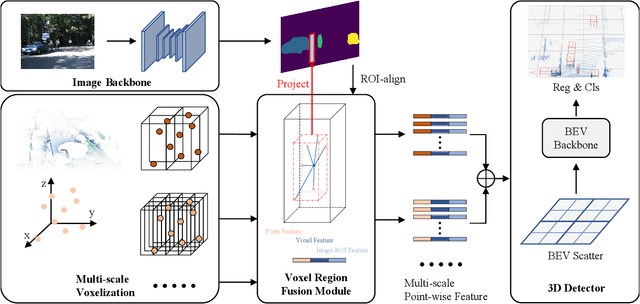
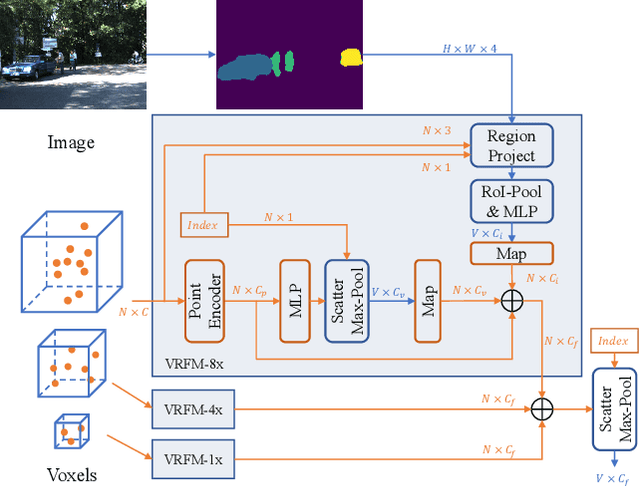

In the perception task of autonomous driving, multi-modal methods have become a trend due to the complementary characteristics of LiDAR point clouds and image data. However, the performance of previous methods is usually limited by the sparsity of the point cloud or the noise problem caused by the misalignment between LiDAR and the camera. To solve these two problems, we present a new concept, Voxel Region (VR), which is obtained by projecting the sparse local point clouds in each voxel dynamically. And we propose a novel fusion method, named Sparse-to-Dense Voxel Region Fusion (SDVRF). Specifically, more pixels of the image feature map inside the VR are gathered to supplement the voxel feature extracted from sparse points and achieve denser fusion. Meanwhile, different from prior methods, which project the size-fixed grids, our strategy of generating dynamic regions achieves better alignment and avoids introducing too much background noise. Furthermore, we propose a multi-scale fusion framework to extract more contextual information and capture the features of objects of different sizes. Experiments on the KITTI dataset show that our method improves the performance of different baselines, especially on classes of small size, including Pedestrian and Cyclist.
Multimodal Neural Databases
May 02, 2023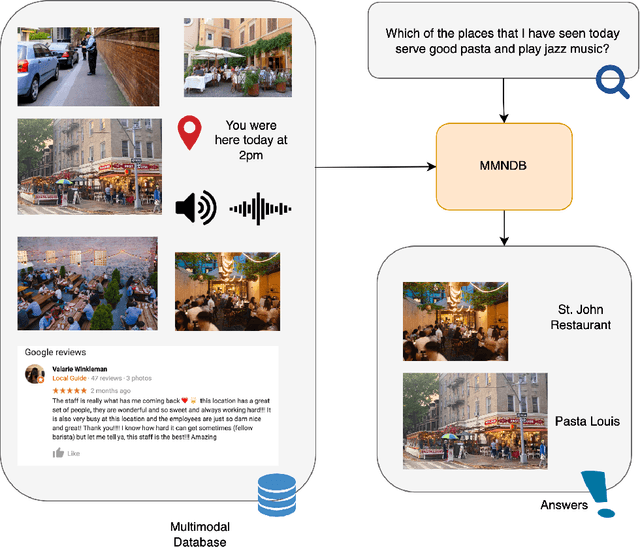
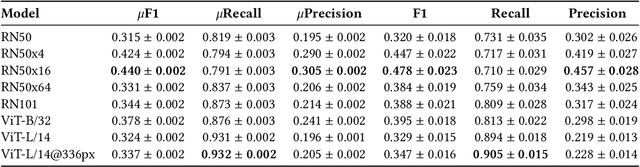
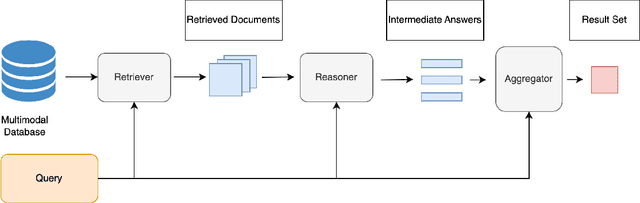
The rise in loosely-structured data available through text, images, and other modalities has called for new ways of querying them. Multimedia Information Retrieval has filled this gap and has witnessed exciting progress in recent years. Tasks such as search and retrieval of extensive multimedia archives have undergone massive performance improvements, driven to a large extent by recent developments in multimodal deep learning. However, methods in this field remain limited in the kinds of queries they support and, in particular, their inability to answer database-like queries. For this reason, inspired by recent work on neural databases, we propose a new framework, which we name Multimodal Neural Databases (MMNDBs). MMNDBs can answer complex database-like queries that involve reasoning over different input modalities, such as text and images, at scale. In this paper, we present the first architecture able to fulfill this set of requirements and test it with several baselines, showing the limitations of currently available models. The results show the potential of these new techniques to process unstructured data coming from different modalities, paving the way for future research in the area. Code to replicate the experiments will be released at https://github.com/GiovanniTRA/MultimodalNeuralDatabases
Physics-Informed Learning Using Hamiltonian Neural Networks with Output Error Noise Models
May 02, 2023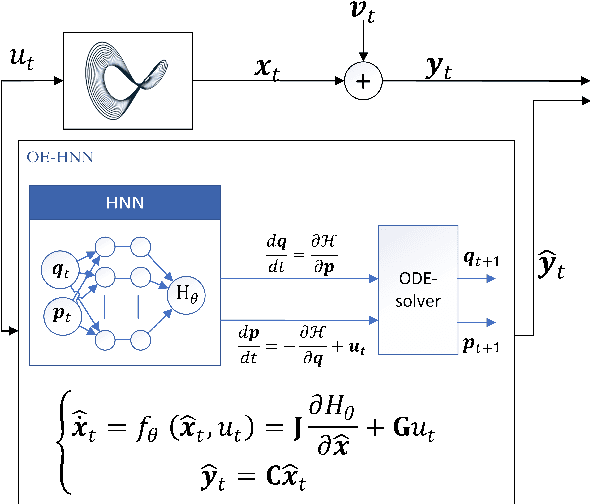

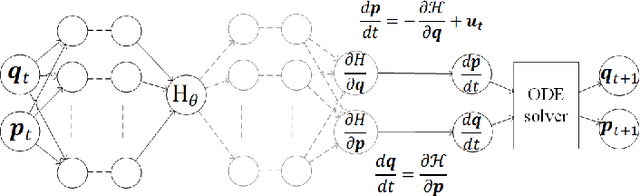
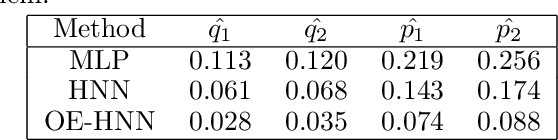
In order to make data-driven models of physical systems interpretable and reliable, it is essential to include prior physical knowledge in the modeling framework. Hamiltonian Neural Networks (HNNs) implement Hamiltonian theory in deep learning and form a comprehensive framework for modeling autonomous energy-conservative systems. Despite being suitable to estimate a wide range of physical system behavior from data, classical HNNs are restricted to systems without inputs and require noiseless state measurements and information on the derivative of the state to be available. To address these challenges, this paper introduces an Output Error Hamiltonian Neural Network (OE-HNN) modeling approach to address the modeling of physical systems with inputs and noisy state measurements. Furthermore, it does not require the state derivatives to be known. Instead, the OE-HNN utilizes an ODE-solver embedded in the training process, which enables the OE-HNN to learn the dynamics from noisy state measurements. In addition, extending HNNs based on the generalized Hamiltonian theory enables to include external inputs into the framework which are important for engineering applications. We demonstrate via simulation examples that the proposed OE-HNNs results in superior modeling performance compared to classical HNNs.
Mitigating Approximate Memorization in Language Models via Dissimilarity Learned Policy
May 02, 2023Large Language models (LLMs) are trained on large amounts of data, which can include sensitive information that may compromise personal privacy. LLMs showed to memorize parts of the training data and emit those data verbatim when an adversary prompts appropriately. Previous research has primarily focused on data preprocessing and differential privacy techniques to address memorization or prevent verbatim memorization exclusively, which can give a false sense of privacy. However, these methods rely on explicit and implicit assumptions about the structure of the data to be protected, which often results in an incomplete solution to the problem. To address this, we propose a novel framework that utilizes a reinforcement learning approach (PPO) to fine-tune LLMs to mitigate approximate memorization. Our approach utilizes a negative similarity score, such as BERTScore or SacreBLEU, as a reward signal to learn a dissimilarity policy. Our results demonstrate that this framework effectively mitigates approximate memorization while maintaining high levels of coherence and fluency in the generated samples. Furthermore, our framework is robust in mitigating approximate memorization across various circumstances, including longer context, which is known to increase memorization in LLMs.
ContactArt: Learning 3D Interaction Priors for Category-level Articulated Object and Hand Poses Estimation
May 02, 2023
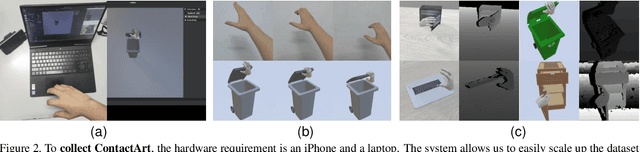
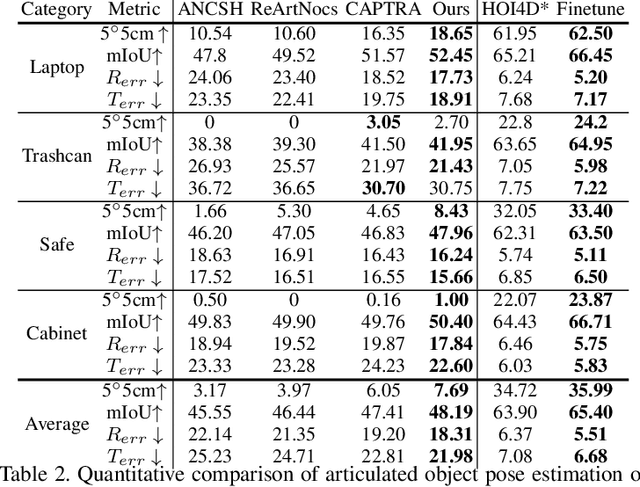
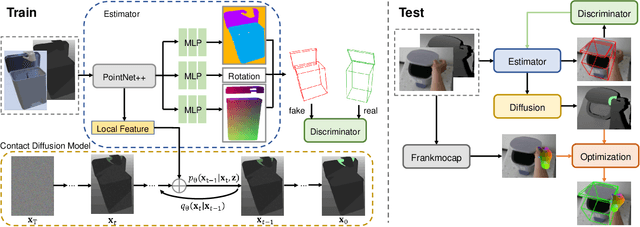
We propose a new dataset and a novel approach to learning hand-object interaction priors for hand and articulated object pose estimation. We first collect a dataset using visual teleoperation, where the human operator can directly play within a physical simulator to manipulate the articulated objects. We record the data and obtain free and accurate annotations on object poses and contact information from the simulator. Our system only requires an iPhone to record human hand motion, which can be easily scaled up and largely lower the costs of data and annotation collection. With this data, we learn 3D interaction priors including a discriminator (in a GAN) capturing the distribution of how object parts are arranged, and a diffusion model which generates the contact regions on articulated objects, guiding the hand pose estimation. Such structural and contact priors can easily transfer to real-world data with barely any domain gap. By using our data and learned priors, our method significantly improves the performance on joint hand and articulated object poses estimation over the existing state-of-the-art methods. The project is available at https://zehaozhu.github.io/ContactArt/ .
An Evidential Real-Time Multi-Mode Fault Diagnosis Approach Based on Broad Learning System
Apr 29, 2023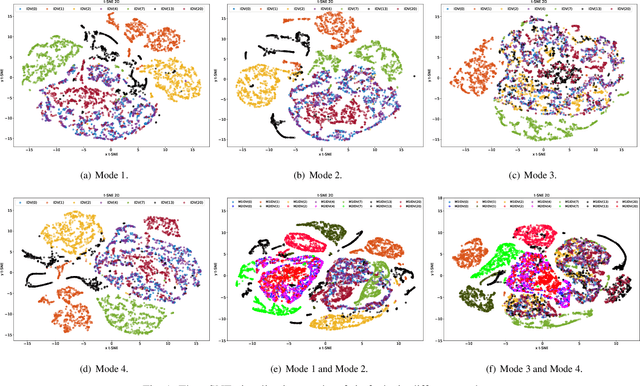
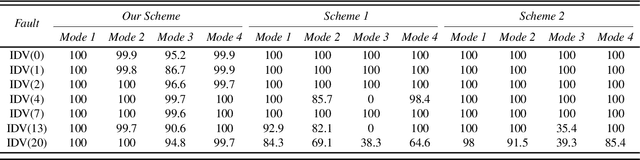
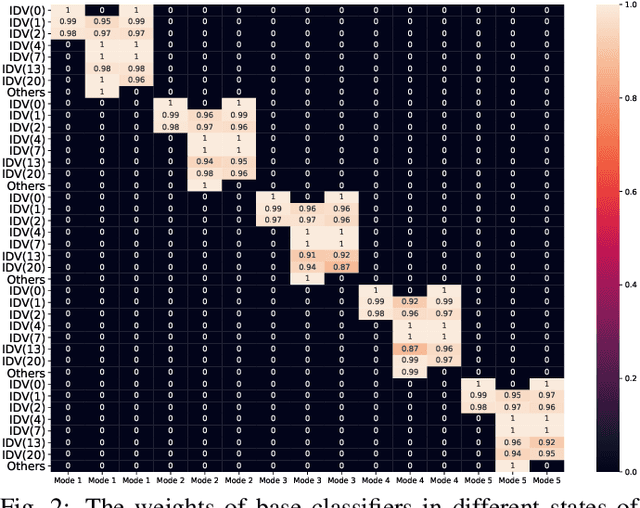
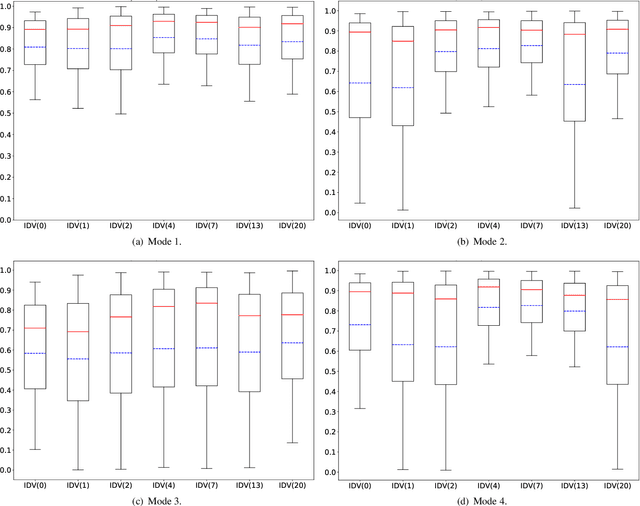
Fault diagnosis is a crucial area of research in the industry due to diverse operating conditions that exhibit non-Gaussian, multi-mode, and center-drift characteristics. Currently, data-driven approaches are the main focus in the field, but they pose challenges for continuous fault classification and parameter updates of fault classifiers, particularly in multiple operating modes and real-time settings. Therefore, a pressing issue is to achieve real-time multi-mode fault diagnosis for industrial systems. To address this problem, this paper proposes a novel approach that utilizes an evidence reasoning (ER) algorithm to fuse information and merge outputs from different base classifiers. These base classifiers are developed using a broad learning system (BLS) to improve good fault diagnosis performance. Moreover, in this approach, the pseudo-label learning method is employed to update model parameters in real-time. To demonstrate the effectiveness of the proposed approach, we perform experiments using the multi-mode Tennessee Eastman process dataset.
Leveraging Label Non-Uniformity for Node Classification in Graph Neural Networks
Apr 29, 2023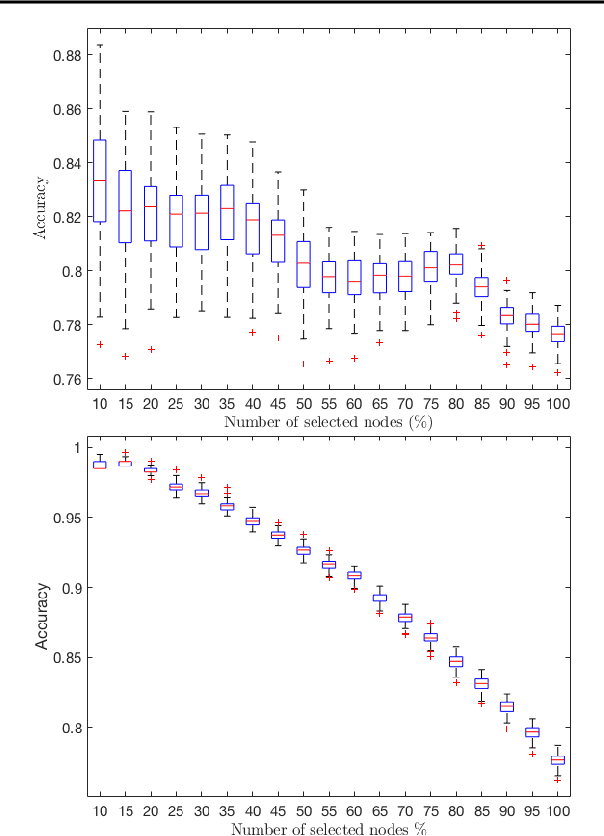

In node classification using graph neural networks (GNNs), a typical model generates logits for different class labels at each node. A softmax layer often outputs a label prediction based on the largest logit. We demonstrate that it is possible to infer hidden graph structural information from the dataset using these logits. We introduce the key notion of label non-uniformity, which is derived from the Wasserstein distance between the softmax distribution of the logits and the uniform distribution. We demonstrate that nodes with small label non-uniformity are harder to classify correctly. We theoretically analyze how the label non-uniformity varies across the graph, which provides insights into boosting the model performance: increasing training samples with high non-uniformity or dropping edges to reduce the maximal cut size of the node set of small non-uniformity. These mechanisms can be easily added to a base GNN model. Experimental results demonstrate that our approach improves the performance of many benchmark base models.
ViewFormer: View Set Attention for Multi-view 3D Shape Understanding
Apr 29, 2023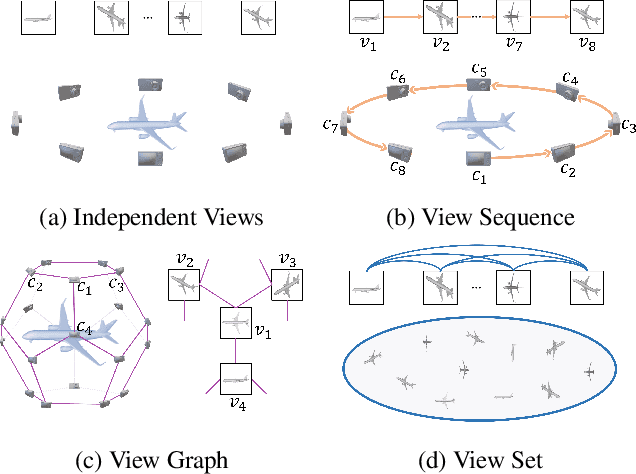
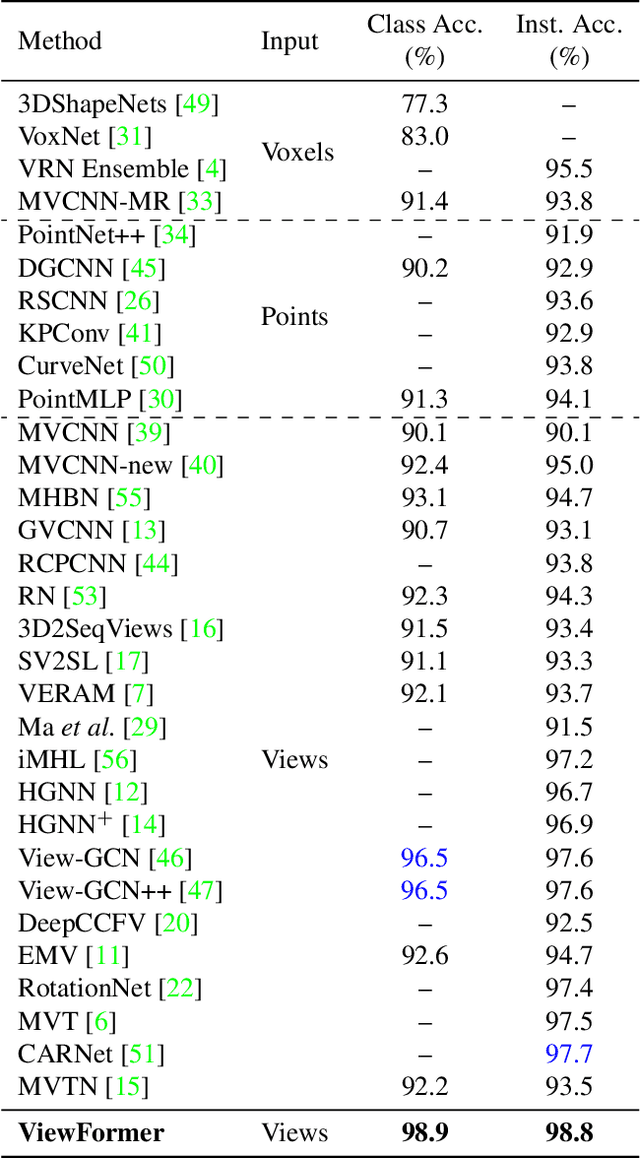

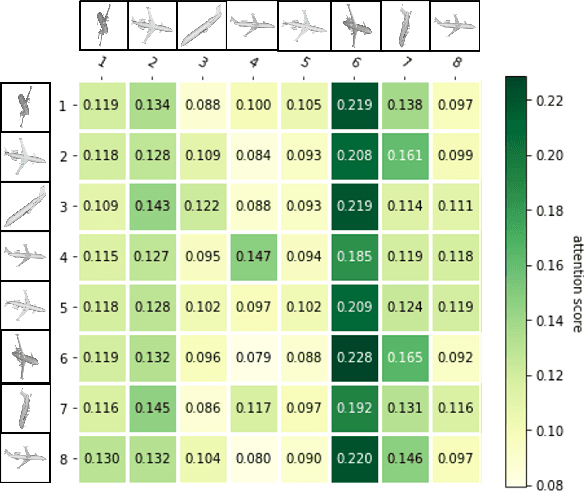
This paper presents ViewFormer, a simple yet effective model for multi-view 3d shape recognition and retrieval. We systematically investigate the existing methods for aggregating multi-view information and propose a novel ``view set" perspective, which minimizes the relation assumption about the views and releases the representation flexibility. We devise an adaptive attention model to capture pairwise and higher-order correlations of the elements in the view set. The learned multi-view correlations are aggregated into an expressive view set descriptor for recognition and retrieval. Experiments show the proposed method unleashes surprising capabilities across different tasks and datasets. For instance, with only 2 attention blocks and 4.8M learnable parameters, ViewFormer reaches 98.8% recognition accuracy on ModelNet40 for the first time, exceeding previous best method by 1.1% . On the challenging RGBD dataset, our method achieves 98.4% recognition accuracy, which is a 4.1% absolute improvement over the strongest baseline. ViewFormer also sets new records in several evaluation dimensions of 3D shape retrieval defined on the SHREC'17 benchmark.
Limits of Model Selection under Transfer Learning
Apr 29, 2023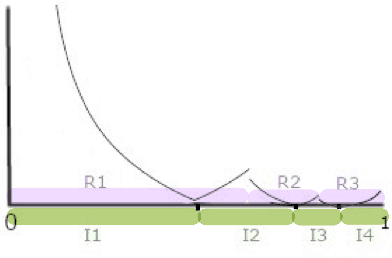
Theoretical studies on transfer learning or domain adaptation have so far focused on situations with a known hypothesis class or model; however in practice, some amount of model selection is usually involved, often appearing under the umbrella term of hyperparameter-tuning: for example, one may think of the problem of tuning for the right neural network architecture towards a target task, while leveraging data from a related source task. Now, in addition to the usual tradeoffs on approximation vs estimation errors involved in model selection, this problem brings in a new complexity term, namely, the transfer distance between source and target distributions, which is known to vary with the choice of hypothesis class. We present a first study of this problem, focusing on classification; in particular, the analysis reveals some remarkable phenomena: adaptive rates, i.e., those achievable with no distributional information, can be arbitrarily slower than oracle rates, i.e., when given knowledge on distances.
Channel State Information Based User Censoring in Irregular Repetition Slotted Aloha
Feb 24, 2023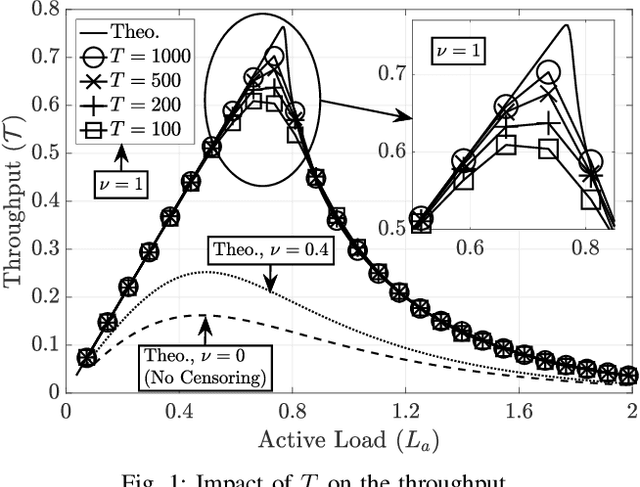
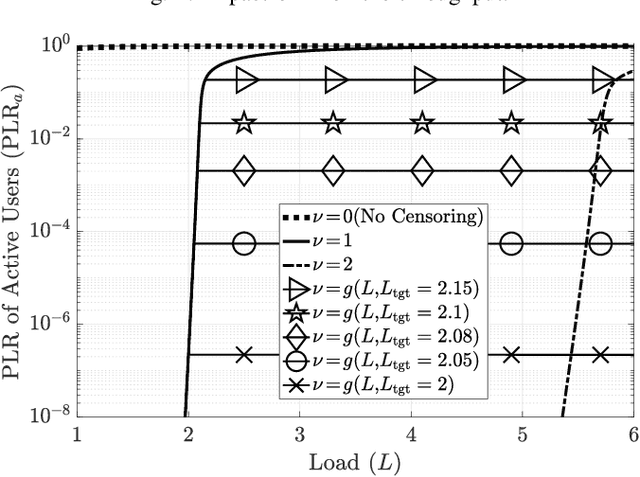
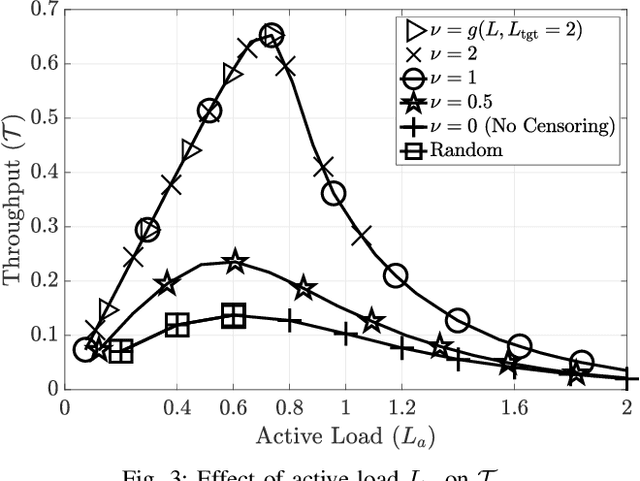
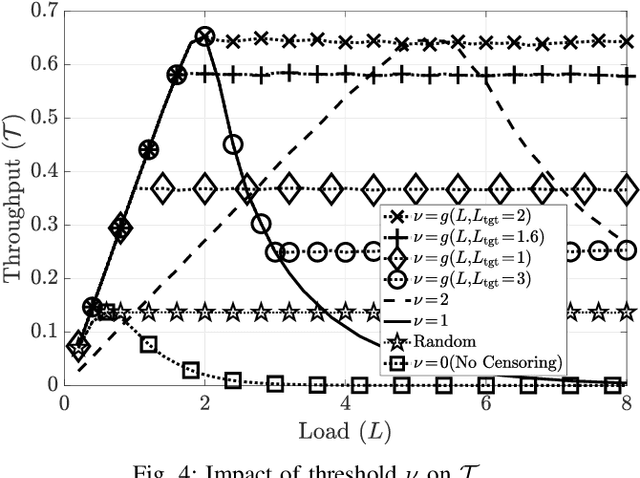
Irregular repetition slotted aloha (IRSA) is a massive random access protocol which can be used to serve a large number of users while achieving a packet loss rate (PLR) close to zero. However, if the number of users is too high, then the system is interference limited and the PLR is close to one. In this paper, we propose a variant of IRSA in the interference limited regime, namely Censored-IRSA (C-IRSA), wherein users with poor channel states censor themselves from transmitting their packets. We theoretically analyze the throughput performance of C-IRSA via density evolution. Using this, we derive closed-form expressions for the optimal choice of the censor threshold which maximizes the throughput while achieving zero PLR among uncensored users. Through extensive numerical simulations, we show that C-IRSA can achieve a 4$\times$ improvement in the peak throughput compared to conventional IRSA.