 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Inferring Local Structure from Pairwise Correlations
May 07, 2023

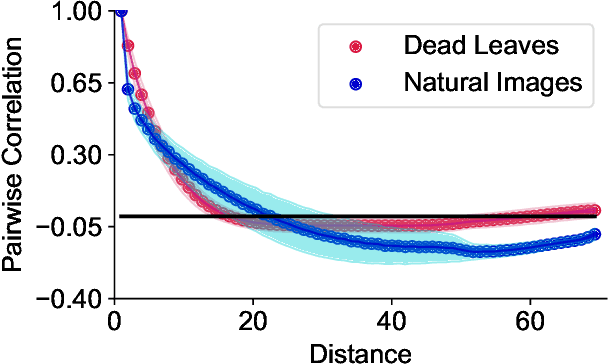
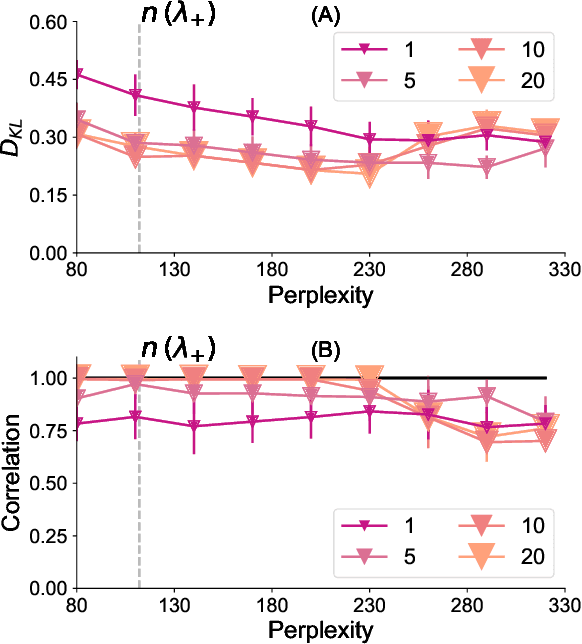
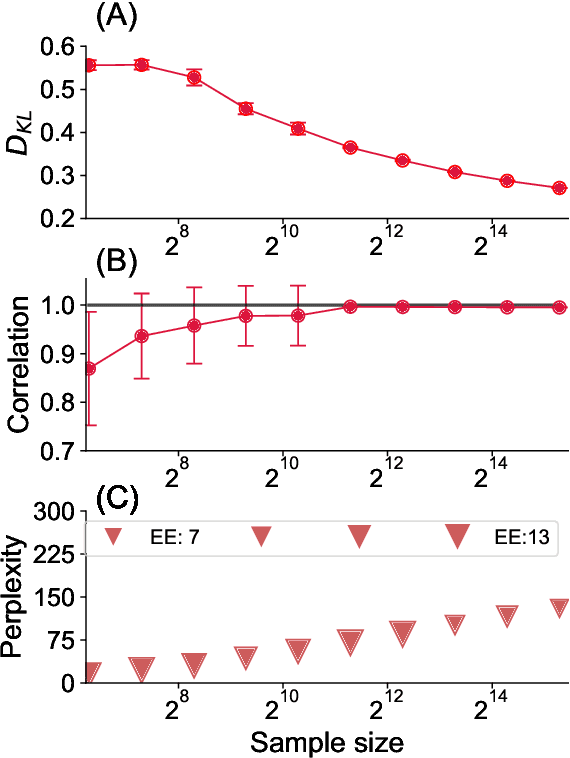
To construct models of large, multivariate complex systems, such as those in biology, one needs to constrain which variables are allowed to interact. This can be viewed as detecting ``local'' structures among the variables. In the context of a simple toy model of 2D natural and synthetic images, we show that pairwise correlations between the variables -- even when severely undersampled -- provide enough information to recover local relations, including the dimensionality of the data, and to reconstruct arrangement of pixels in fully scrambled images. This proves to be successful even though higher order interaction structures are present in our data. We build intuition behind the success, which we hope might contribute to modeling complex, multivariate systems and to explaining the success of modern attention-based machine learning approaches.
Materials Informatics: An Algorithmic Design Rule
May 05, 2023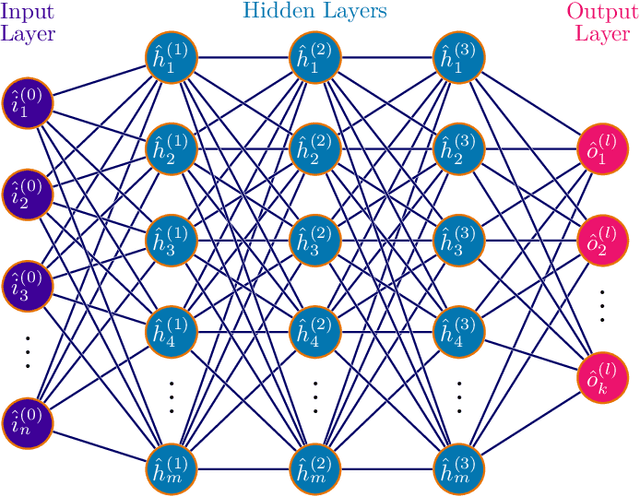
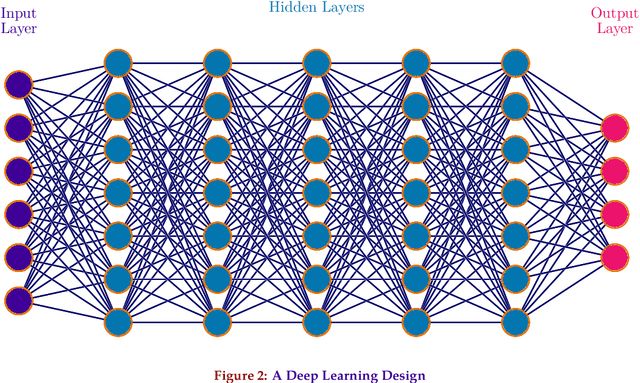
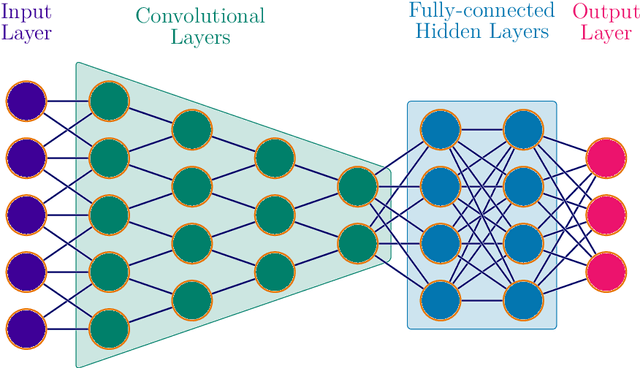
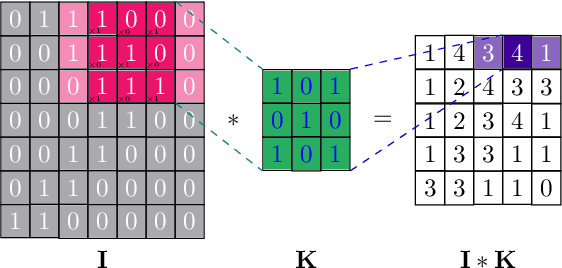
Materials informatics, data-enabled investigation, is a "fourth paradigm" in materials science research after the conventional empirical approach, theoretical science, and computational research. Materials informatics has two essential ingredients: fingerprinting materials proprieties and the theory of statistical inference and learning. We have researched the organic semiconductor's enigmas through the materials informatics approach. By applying diverse neural network topologies, logical axiom, and inferencing information science, we have developed data-driven procedures for novel organic semiconductor discovery for the semiconductor industry and knowledge extraction for the materials science community. We have reviewed and corresponded with various algorithms for the neural network design topology for the materials informatics dataset.
Controllable Mixed-Initiative Dialogue Generation through Prompting
May 06, 2023
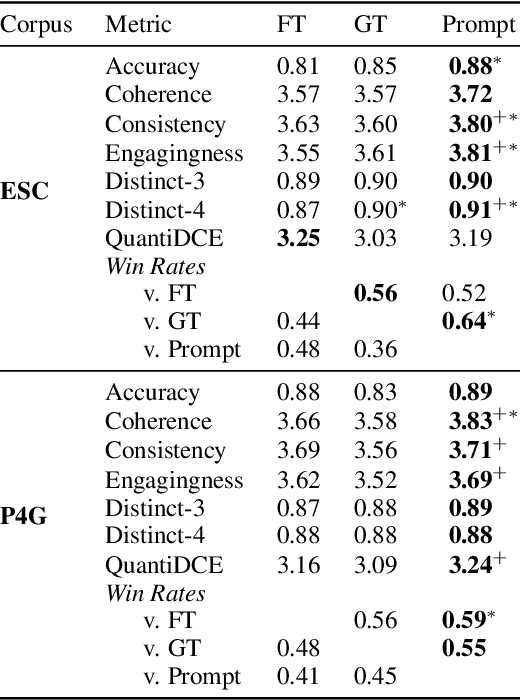

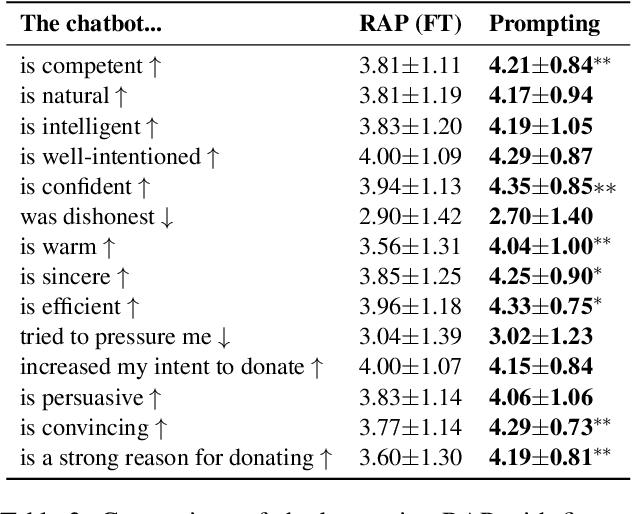
Mixed-initiative dialogue tasks involve repeated exchanges of information and conversational control. Conversational agents gain control by generating responses that follow particular dialogue intents or strategies, prescribed by a policy planner. The standard approach has been fine-tuning pre-trained language models to perform generation conditioned on these intents. However, these supervised generation models are limited by the cost and quality of data annotation. We instead prompt large language models as a drop-in replacement to fine-tuning on conditional generation. We formalize prompt construction for controllable mixed-initiative dialogue. Our findings show improvements over fine-tuning and ground truth responses according to human evaluation and automatic metrics for two tasks: PersuasionForGood and Emotional Support Conversations.
Multi-Modality Deep Network for Extreme Learned Image Compression
Apr 26, 2023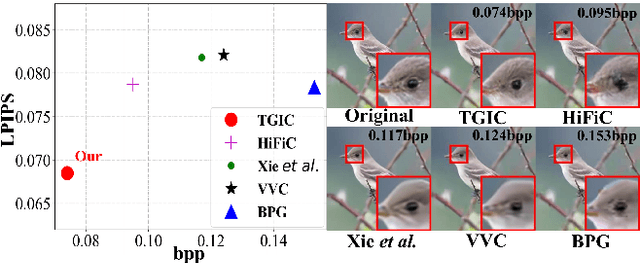

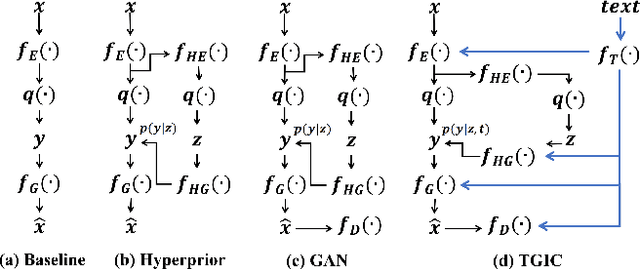
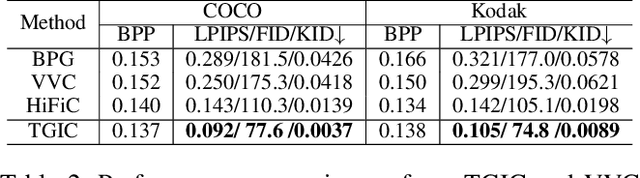
Image-based single-modality compression learning approaches have demonstrated exceptionally powerful encoding and decoding capabilities in the past few years , but suffer from blur and severe semantics loss at extremely low bitrates. To address this issue, we propose a multimodal machine learning method for text-guided image compression, in which the semantic information of text is used as prior information to guide image compression for better compression performance. We fully study the role of text description in different components of the codec, and demonstrate its effectiveness. In addition, we adopt the image-text attention module and image-request complement module to better fuse image and text features, and propose an improved multimodal semantic-consistent loss to produce semantically complete reconstructions. Extensive experiments, including a user study, prove that our method can obtain visually pleasing results at extremely low bitrates, and achieves a comparable or even better performance than state-of-the-art methods, even though these methods are at 2x to 4x bitrates of ours.
Identity-Guided Collaborative Learning for Cloth-Changing Person Reidentification
Apr 10, 2023

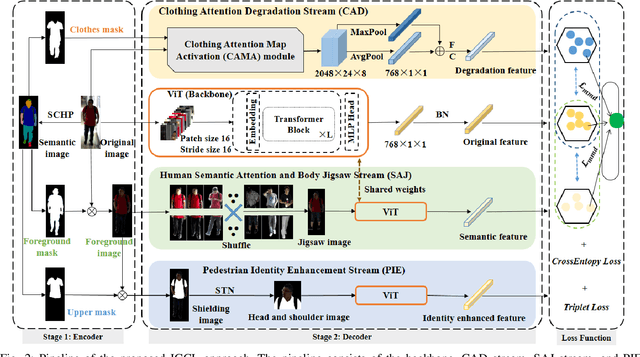

Cloth-changing person reidentification (ReID) is a newly emerging research topic that is aimed at addressing the issues of large feature variations due to cloth-changing and pedestrian view/pose changes. Although significant progress has been achieved by introducing extra information (e.g., human contour sketching information, human body keypoints, and 3D human information), cloth-changing person ReID is still challenging due to impressionable pedestrian representations. Moreover, human semantic information and pedestrian identity information are not fully explored. To solve these issues, we propose a novel identity-guided collaborative learning scheme (IGCL) for cloth-changing person ReID, where the human semantic is fully utilized and the identity is unchangeable to guide collaborative learning. First, we design a novel clothing attention degradation stream to reasonably reduce the interference caused by clothing information where clothing attention and mid-level collaborative learning are employed. Second, we propose a human semantic attention and body jigsaw stream to highlight the human semantic information and simulate different poses of the same identity. In this way, the extraction features not only focus on human semantic information that is unrelated to the background but also are suitable for pedestrian pose variations. Moreover, a pedestrian identity enhancement stream is further proposed to enhance the identity importance and extract more favorable identity robust features. Most importantly, all these streams are jointly explored in an end-to-end unified framework, and the identity is utilized to guide the optimization. Extensive experiments on five public clothing person ReID datasets demonstrate that the proposed IGCL significantly outperforms SOTA methods and that the extracted feature is more robust, discriminative, and clothing-irrelevant.
Mask to reconstruct: Cooperative Semantics Completion for Video-text Retrieval
May 13, 2023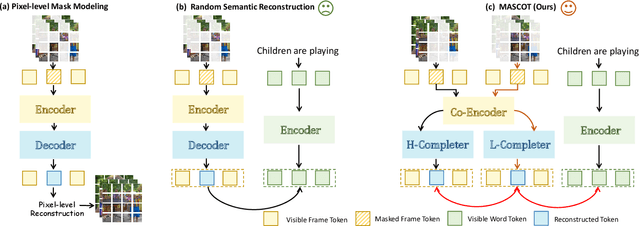
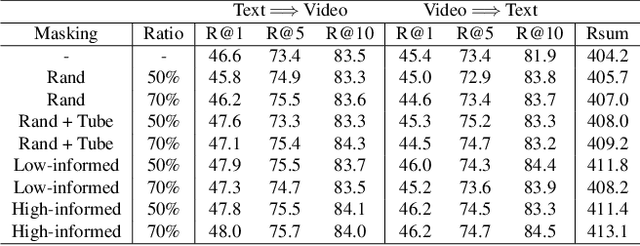
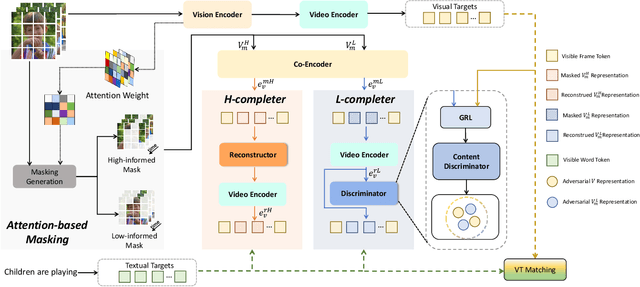
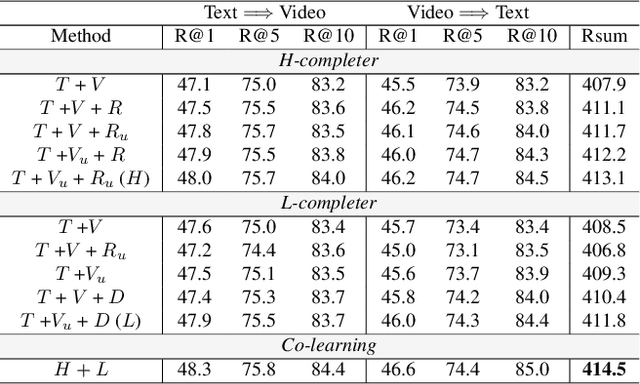
Recently, masked video modeling has been widely explored and significantly improved the model's understanding ability of visual regions at a local level. However, existing methods usually adopt random masking and follow the same reconstruction paradigm to complete the masked regions, which do not leverage the correlations between cross-modal content. In this paper, we present Mask for Semantics Completion (MASCOT) based on semantic-based masked modeling. Specifically, after applying attention-based video masking to generate high-informed and low-informed masks, we propose Informed Semantics Completion to recover masked semantics information. The recovery mechanism is achieved by aligning the masked content with the unmasked visual regions and corresponding textual context, which makes the model capture more text-related details at a patch level. Additionally, we shift the emphasis of reconstruction from irrelevant backgrounds to discriminative parts to ignore regions with low-informed masks. Furthermore, we design dual-mask co-learning to incorporate video cues under different masks and learn more aligned video representation. Our MASCOT performs state-of-the-art performance on four major text-video retrieval benchmarks, including MSR-VTT, LSMDC, ActivityNet, and DiDeMo. Extensive ablation studies demonstrate the effectiveness of the proposed schemes.
Revisit the Algorithm Selection Problem for TSP with Spatial Information Enhanced Graph Neural Networks
Feb 08, 2023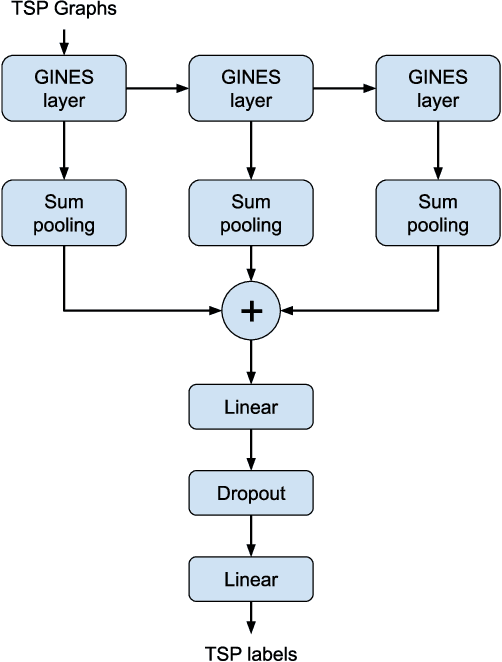
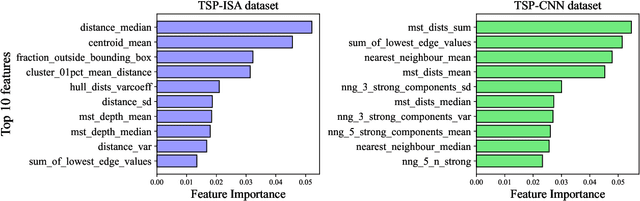
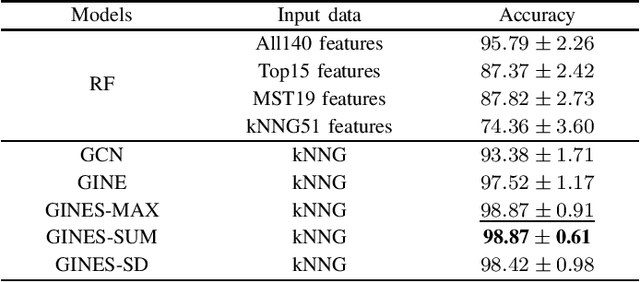
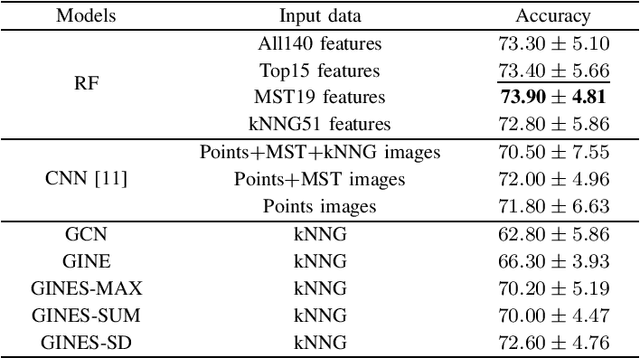
Algorithm selection is a well-known problem where researchers investigate how to construct useful features representing the problem instances and then apply feature-based machine learning models to predict which algorithm works best with the given instance. However, even for simple optimization problems such as Euclidean Traveling Salesman Problem (TSP), there lacks a general and effective feature representation for problem instances. The important features of TSP are relatively well understood in the literature, based on extensive domain knowledge and post-analysis of the solutions. In recent years, Convolutional Neural Network (CNN) has become a popular approach to select algorithms for TSP. Compared to traditional feature-based machine learning models, CNN has an automatic feature-learning ability and demands less domain expertise. However, it is still required to generate intermediate representations, i.e., multiple images to represent TSP instances first. In this paper, we revisit the algorithm selection problem for TSP, and propose a novel Graph Neural Network (GNN), called GINES. GINES takes the coordinates of cities and distances between cities as input. It is composed of a new message-passing mechanism and a local neighborhood feature extractor to learn spatial information of TSP instances. We evaluate GINES on two benchmark datasets. The results show that GINES outperforms CNN and the original GINE models. It is better than the traditional handcrafted feature-based approach on one dataset. The code and dataset will be released in the final version of this paper.
Interpretable Multimodal Misinformation Detection with Logic Reasoning
May 10, 2023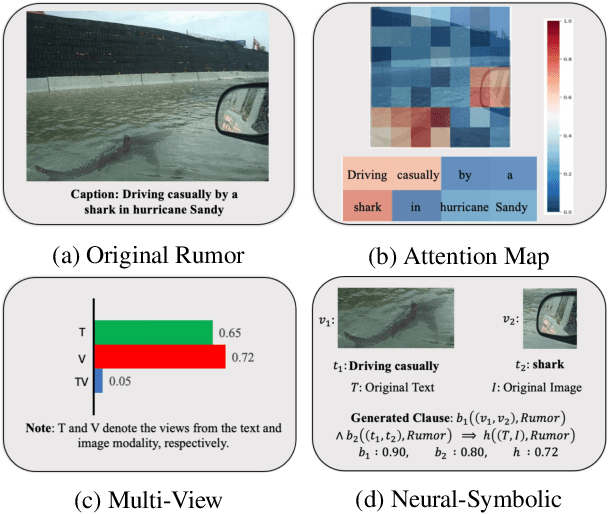

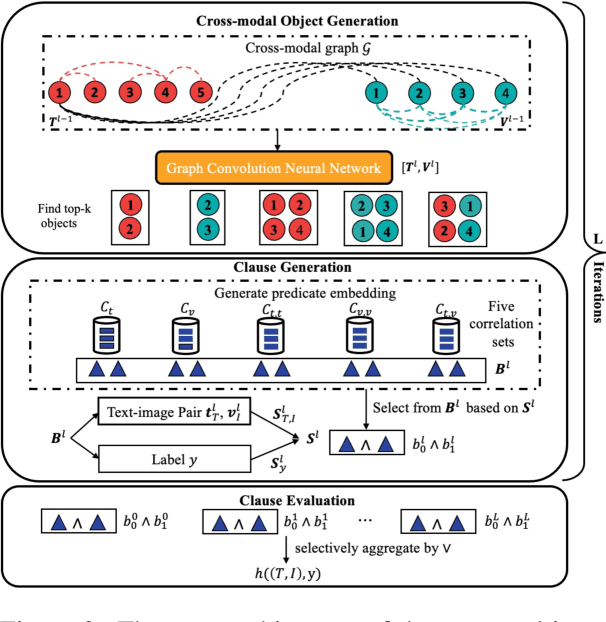
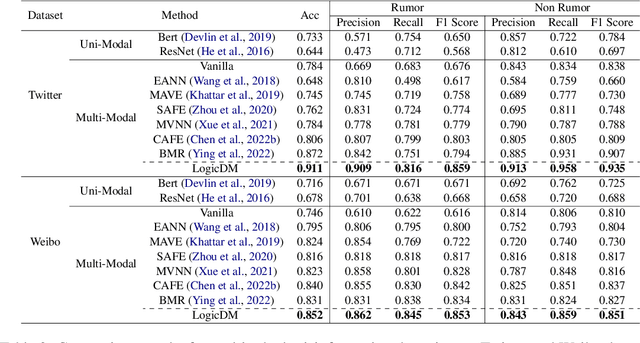
Multimodal misinformation on online social platforms is becoming a critical concern due to increasing credibility and easier dissemination brought by multimedia content, compared to traditional text-only information. While existing multimodal detection approaches have achieved high performance, the lack of interpretability hinders these systems' reliability and practical deployment. Inspired by NeuralSymbolic AI which combines the learning ability of neural networks with the explainability of symbolic learning, we propose a novel logic-based neural model for multimodal misinformation detection which integrates interpretable logic clauses to express the reasoning process of the target task. To make learning effective, we parameterize symbolic logical elements using neural representations, which facilitate the automatic generation and evaluation of meaningful logic clauses. Additionally, to make our framework generalizable across diverse misinformation sources, we introduce five meta-predicates that can be instantiated with different correlations. Results on three public datasets (Twitter, Weibo, and Sarcasm) demonstrate the feasibility and versatility of our model.
Low-Light Image Enhancement via Structure Modeling and Guidance
May 10, 2023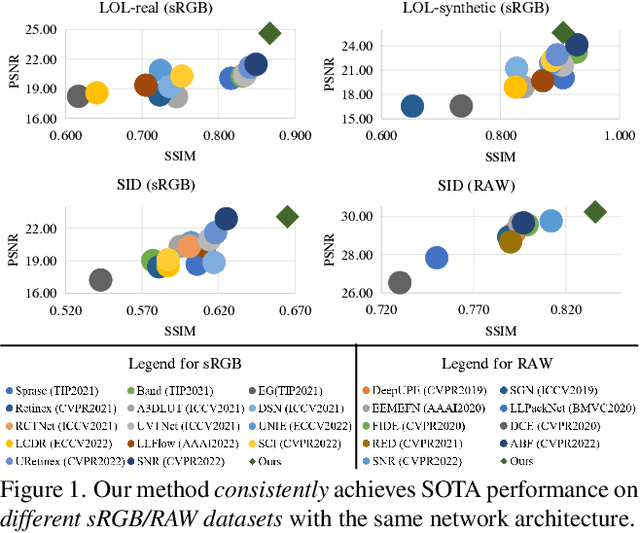
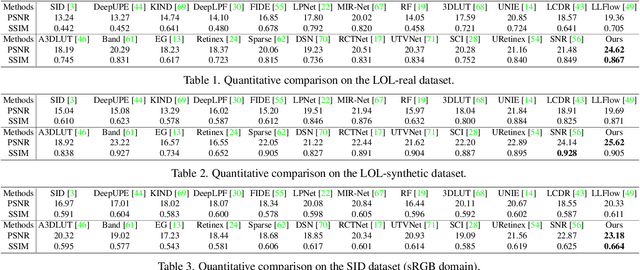

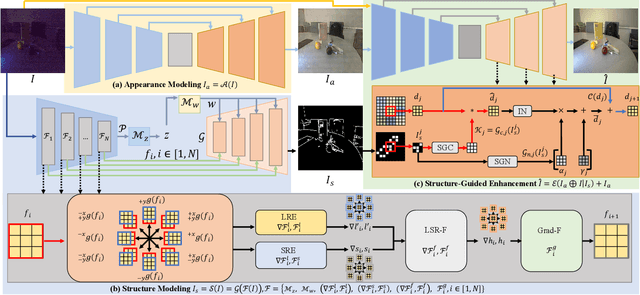
This paper proposes a new framework for low-light image enhancement by simultaneously conducting the appearance as well as structure modeling. It employs the structural feature to guide the appearance enhancement, leading to sharp and realistic results. The structure modeling in our framework is implemented as the edge detection in low-light images. It is achieved with a modified generative model via designing a structure-aware feature extractor and generator. The detected edge maps can accurately emphasize the essential structural information, and the edge prediction is robust towards the noises in dark areas. Moreover, to improve the appearance modeling, which is implemented with a simple U-Net, a novel structure-guided enhancement module is proposed with structure-guided feature synthesis layers. The appearance modeling, edge detector, and enhancement module can be trained end-to-end. The experiments are conducted on representative datasets (sRGB and RAW domains), showing that our model consistently achieves SOTA performance on all datasets with the same architecture.
Best-Effort Adaptation
May 10, 2023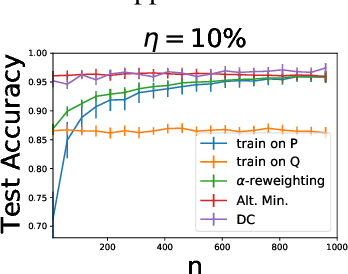
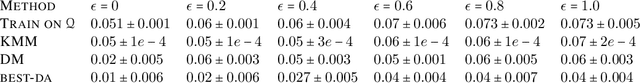
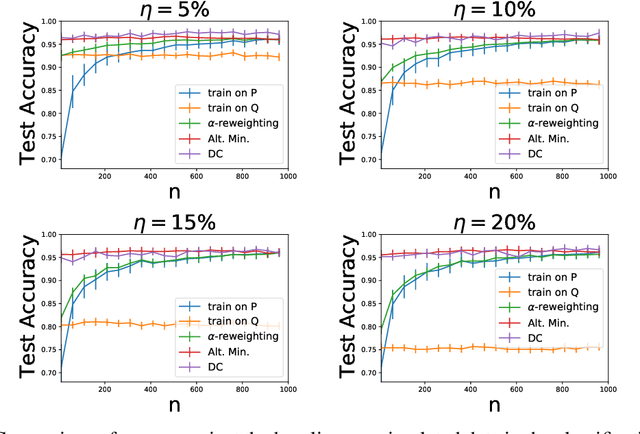
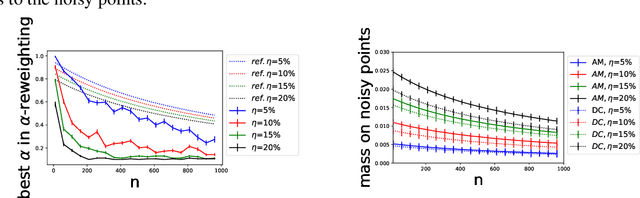
We study a problem of best-effort adaptation motivated by several applications and considerations, which consists of determining an accurate predictor for a target domain, for which a moderate amount of labeled samples are available, while leveraging information from another domain for which substantially more labeled samples are at one's disposal. We present a new and general discrepancy-based theoretical analysis of sample reweighting methods, including bounds holding uniformly over the weights. We show how these bounds can guide the design of learning algorithms that we discuss in detail. We further show that our learning guarantees and algorithms provide improved solutions for standard domain adaptation problems, for which few labeled data or none are available from the target domain. We finally report the results of a series of experiments demonstrating the effectiveness of our best-effort adaptation and domain adaptation algorithms, as well as comparisons with several baselines. We also discuss how our analysis can benefit the design of principled solutions for fine-tuning.