 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Context-Aware Semantic Similarity Measurement for Unsupervised Word Sense Disambiguation
May 05, 2023
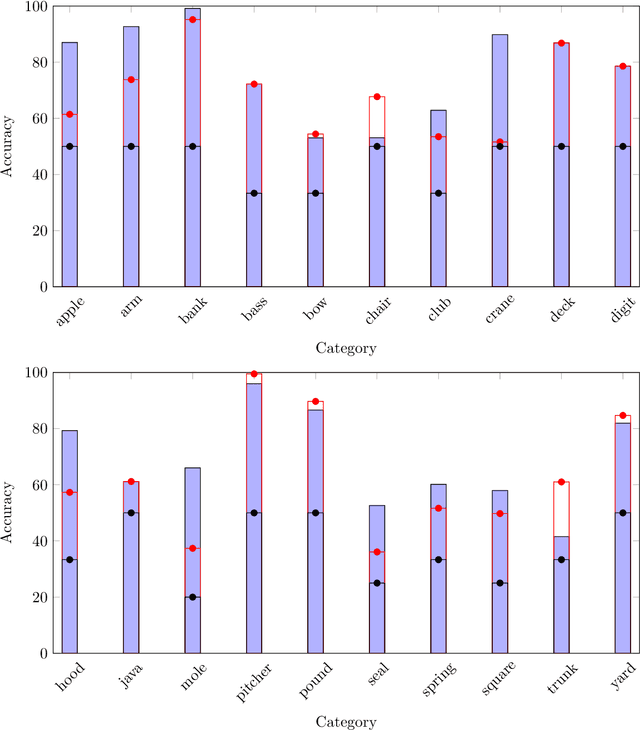
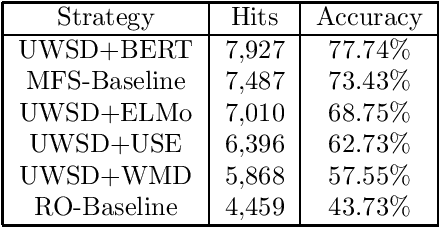
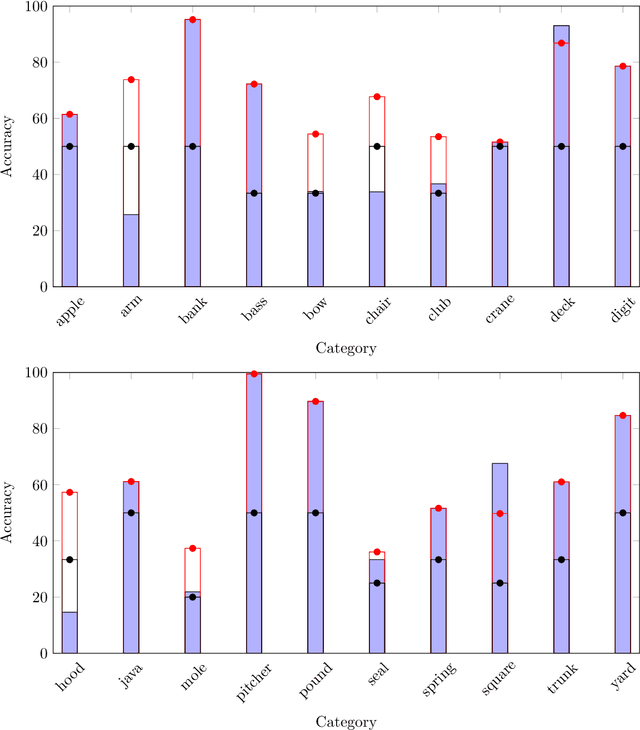

The issue of word sense ambiguity poses a significant challenge in natural language processing due to the scarcity of annotated data to feed machine learning models to face the challenge. Therefore, unsupervised word sense disambiguation methods have been developed to overcome that challenge without relying on annotated data. This research proposes a new context-aware approach to unsupervised word sense disambiguation, which provides a flexible mechanism for incorporating contextual information into the similarity measurement process. We experiment with a popular benchmark dataset to evaluate the proposed strategy and compare its performance with state-of-the-art unsupervised word sense disambiguation techniques. The experimental results indicate that our approach substantially enhances disambiguation accuracy and surpasses the performance of several existing techniques. Our findings underscore the significance of integrating contextual information in semantic similarity measurements to manage word sense ambiguity in unsupervised scenarios effectively.
Model-free Reinforcement Learning of Semantic Communication by Stochastic Policy Gradient
May 05, 2023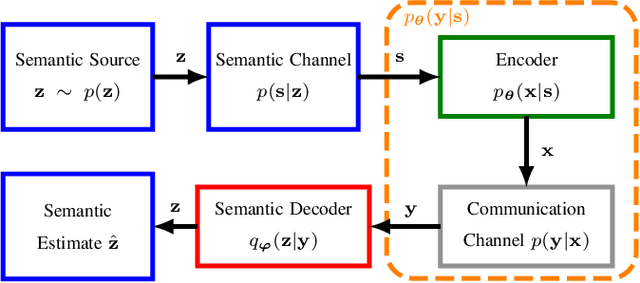
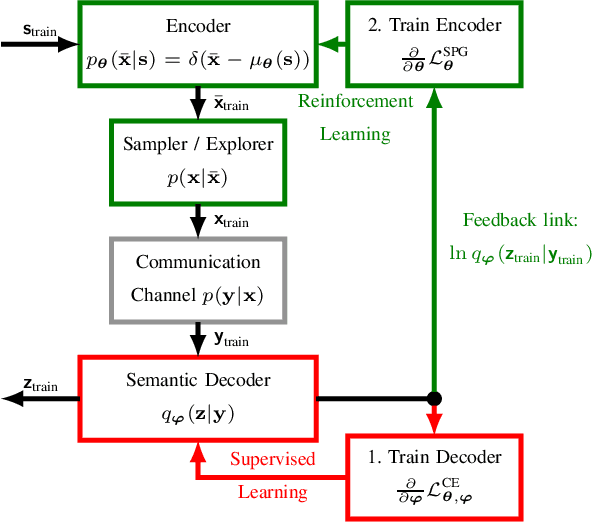
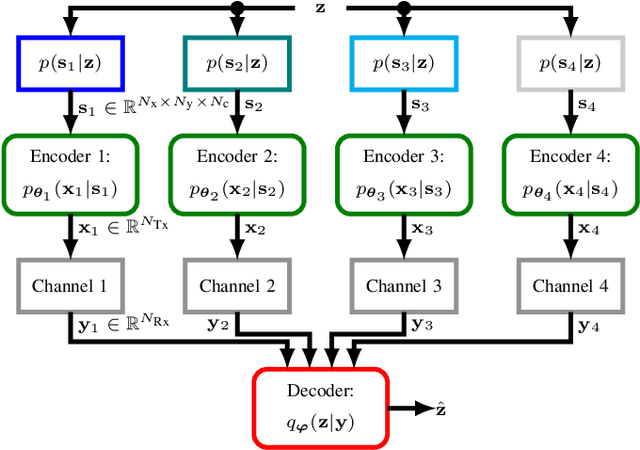
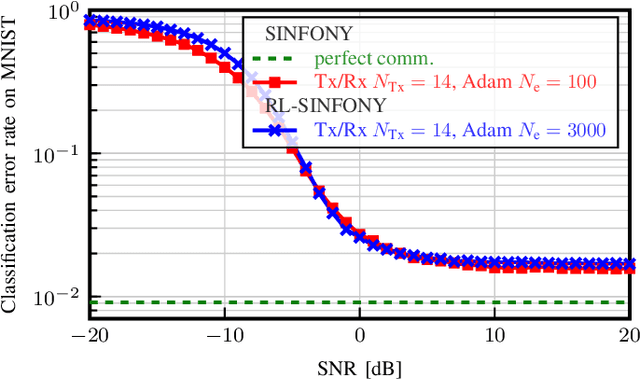
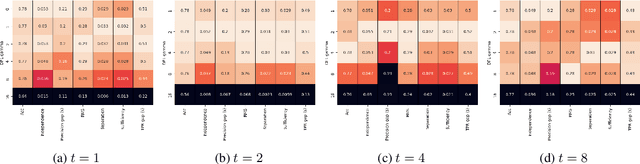
Motivated by the recent success of Machine Learning tools in wireless communications, the idea of semantic communication by Weaver from 1949 has gained attention. It breaks with Shannon's classic design paradigm by aiming to transmit the meaning, i.e., semantics, of a message instead of its exact version, allowing for information rate savings. In this work, we apply the Stochastic Policy Gradient (SPG) to design a semantic communication system by reinforcement learning, not requiring a known or differentiable channel model - a crucial step towards deployment in practice. Further, we motivate the use of SPG for both classic and semantic communication from the maximization of the mutual information between received and target variables. Numerical results show that our approach achieves comparable performance to a model-aware approach based on the reparametrization trick, albeit with a decreased convergence rate.
MORTY: Structured Summarization for Targeted Information Extraction from Scholarly Articles
Dec 11, 2022Information extraction from scholarly articles is a challenging task due to the sizable document length and implicit information hidden in text, figures, and citations. Scholarly information extraction has various applications in exploration, archival, and curation services for digital libraries and knowledge management systems. We present MORTY, an information extraction technique that creates structured summaries of text from scholarly articles. Our approach condenses the article's full-text to property-value pairs as a segmented text snippet called structured summary. We also present a sizable scholarly dataset combining structured summaries retrieved from a scholarly knowledge graph and corresponding publicly available scientific articles, which we openly publish as a resource for the research community. Our results show that structured summarization is a suitable approach for targeted information extraction that complements other commonly used methods such as question answering and named entity recognition.
Debiasing NLP Models Without Demographic Information
Dec 20, 2022

Models trained from real-world data tend to imitate and amplify social biases. Although there are many methods suggested to mitigate biases, they require a preliminary information on the types of biases that should be mitigated (e.g., gender or racial bias) and the social groups associated with each data sample. In this work, we propose a debiasing method that operates without any prior knowledge of the demographics in the dataset, detecting biased examples based on an auxiliary model that predicts the main model's success and down-weights them during the training process. Results on racial and gender bias demonstrate that it is possible to mitigate social biases without having to use a costly demographic annotation process.
Information-Based Sensor Placement for Data-Driven Estimation of Unsteady Flows
Mar 22, 2023Estimation of unsteady flow fields around flight vehicles may improve flow interactions and lead to enhanced vehicle performance. Although flow-field representations can be very high-dimensional, their dynamics can have low-order representations and may be estimated using a few, appropriately placed measurements. This paper presents a sensor-selection framework for the intended application of data-driven, flow-field estimation. This framework combines data-driven modeling, steady-state Kalman Filter design, and a sparsification technique for sequential selection of sensors. This paper also uses the sensor selection framework to design sensor arrays that can perform well across a variety of operating conditions. Flow estimation results on numerical data show that the proposed framework produces arrays that are highly effective at flow-field estimation for the flow behind and an airfoil at a high angle of attack using embedded pressure sensors. Analysis of the flow fields reveals that paths of impinging stagnation points along the airfoil's surface during a shedding period of the flow are highly informative locations for placement of pressure sensors.
PromptNER: A Prompting Method for Few-shot Named Entity Recognition via k Nearest Neighbor Search
May 20, 2023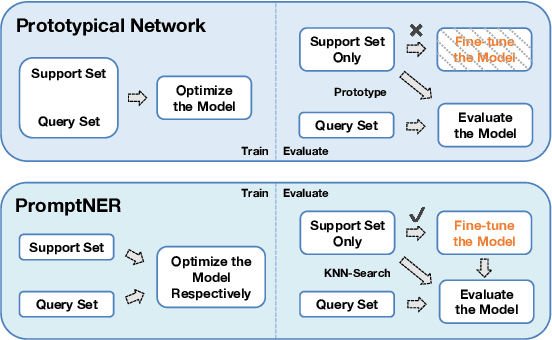
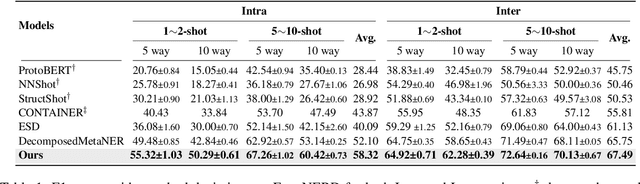

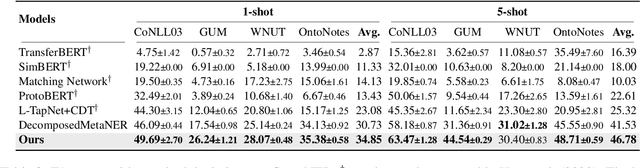
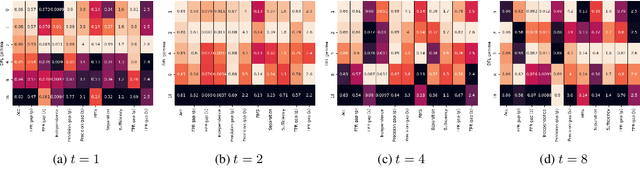
Few-shot Named Entity Recognition (NER) is a task aiming to identify named entities via limited annotated samples. Recently, prototypical networks have shown promising performance in few-shot NER. Most of prototypical networks will utilize the entities from the support set to construct label prototypes and use the query set to compute span-level similarities and optimize these label prototype representations. However, these methods are usually unsuitable for fine-tuning in the target domain, where only the support set is available. In this paper, we propose PromptNER: a novel prompting method for few-shot NER via k nearest neighbor search. We use prompts that contains entity category information to construct label prototypes, which enables our model to fine-tune with only the support set. Our approach achieves excellent transfer learning ability, and extensive experiments on the Few-NERD and CrossNER datasets demonstrate that our model achieves superior performance over state-of-the-art methods.
An Asynchronous Wireless Network for Capturing Event-Driven Data from Large Populations of Autonomous Sensors
May 20, 2023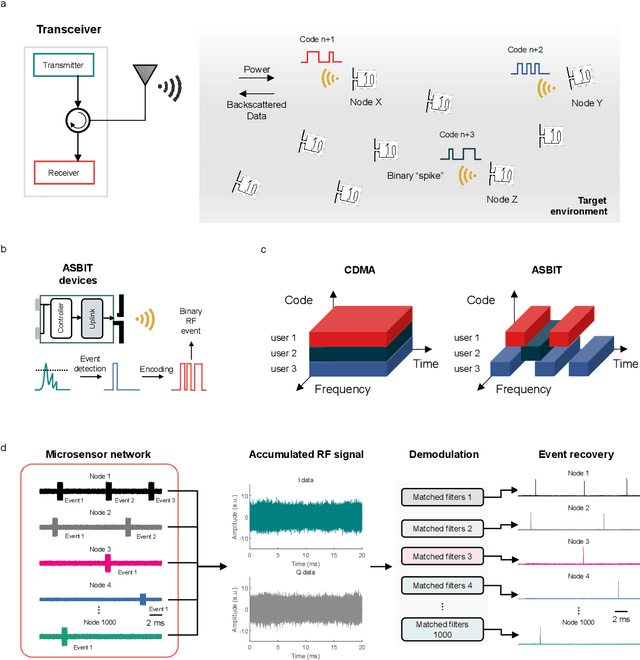
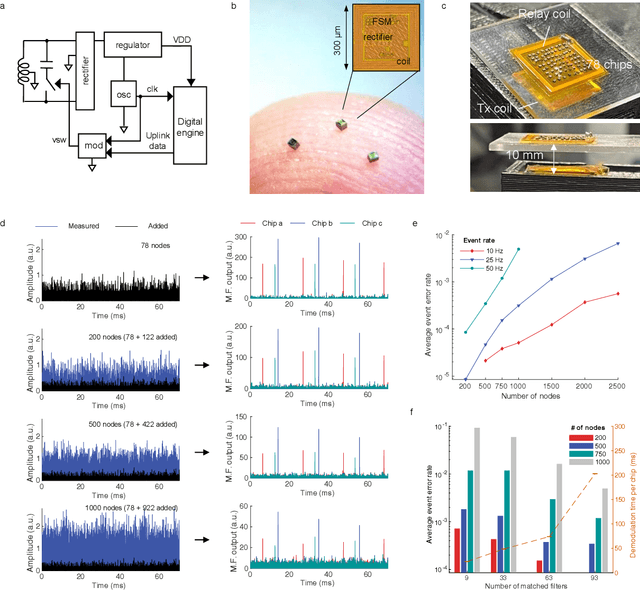
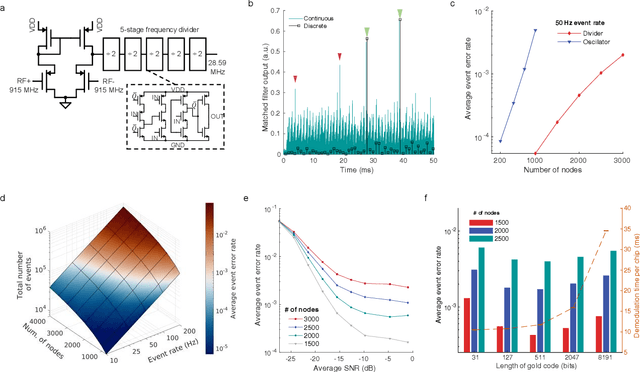
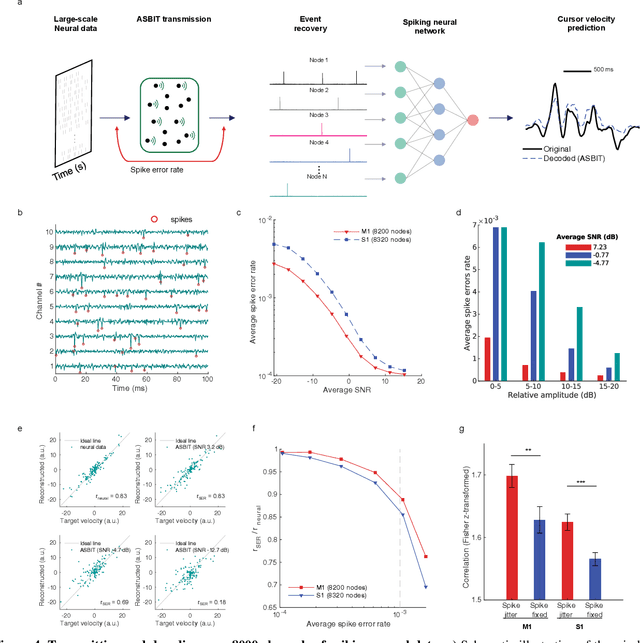
We introduce a wireless RF network concept for capturing sparse event-driven data from large populations of spatially distributed autonomous microsensors, possibly numbered in the thousands. Each sensor is assumed to be a microchip capable of event detection in transforming time-varying inputs to spike trains. Inspired by brain information processing, we have developed a spectrally efficient, low-error rate asynchronous networking concept based on a code-division multiple access method. We characterize the network performance of several dozen submillimeter-size silicon microchips experimentally, complemented by larger scale in silico simulations. A comparison is made between different implementations of on-chip clocks. Testing the notion that spike-based wireless communication is naturally matched with downstream sensor population analysis by neuromorphic computing techniques, we then deploy a spiking neural network (SNN) machine learning model to decode data from eight thousand spiking neurons in the primate cortex for accurate prediction of hand movement in a cursor control task.
GFDC: A Granule Fusion Density-Based Clustering with Evidential Reasoning
May 20, 2023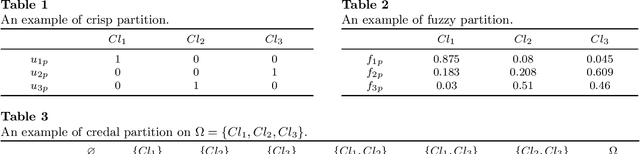
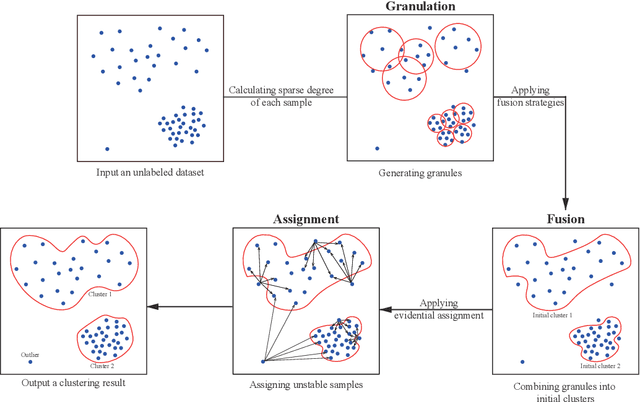
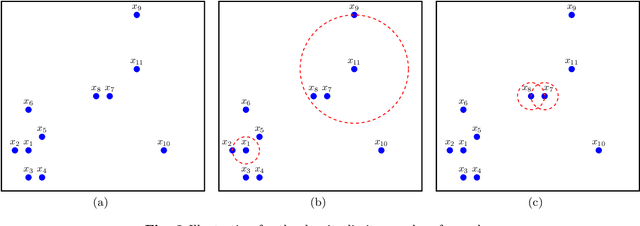

Currently, density-based clustering algorithms are widely applied because they can detect clusters with arbitrary shapes. However, they perform poorly in measuring global density, determining reasonable cluster centers or structures, assigning samples accurately and handling data with large density differences among clusters. To overcome their drawbacks, this paper proposes a granule fusion density-based clustering with evidential reasoning (GFDC). Both local and global densities of samples are measured by a sparse degree metric first. Then information granules are generated in high-density and low-density regions, assisting in processing clusters with significant density differences. Further, three novel granule fusion strategies are utilized to combine granules into stable cluster structures, helping to detect clusters with arbitrary shapes. Finally, by an assignment method developed from Dempster-Shafer theory, unstable samples are assigned. After using GFDC, a reasonable clustering result and some identified outliers can be obtained. The experimental results on extensive datasets demonstrate the effectiveness of GFDC.
Patton: Language Model Pretraining on Text-Rich Networks
May 20, 2023
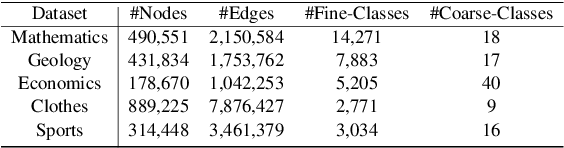
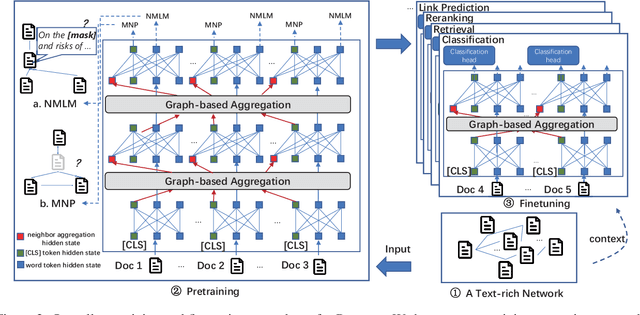
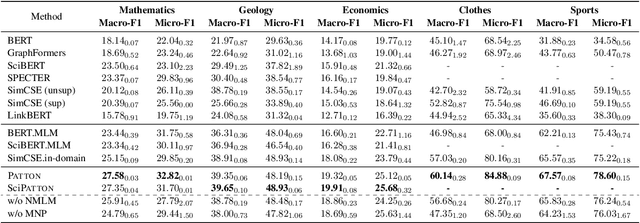
A real-world text corpus sometimes comprises not only text documents but also semantic links between them (e.g., academic papers in a bibliographic network are linked by citations and co-authorships). Text documents and semantic connections form a text-rich network, which empowers a wide range of downstream tasks such as classification and retrieval. However, pretraining methods for such structures are still lacking, making it difficult to build one generic model that can be adapted to various tasks on text-rich networks. Current pretraining objectives, such as masked language modeling, purely model texts and do not take inter-document structure information into consideration. To this end, we propose our PretrAining on TexT-Rich NetwOrk framework Patton. Patton includes two pretraining strategies: network-contextualized masked language modeling and masked node prediction, to capture the inherent dependency between textual attributes and network structure. We conduct experiments on four downstream tasks in five datasets from both academic and e-commerce domains, where Patton outperforms baselines significantly and consistently.
Learning to Rank the Importance of Nodes in Road Networks Based on Multi-Graph Fusion
May 20, 2023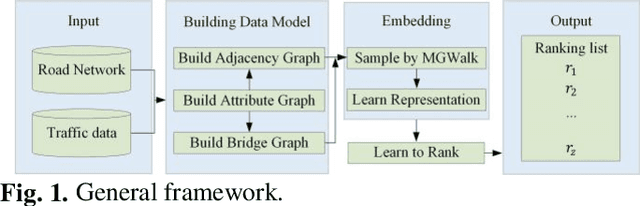
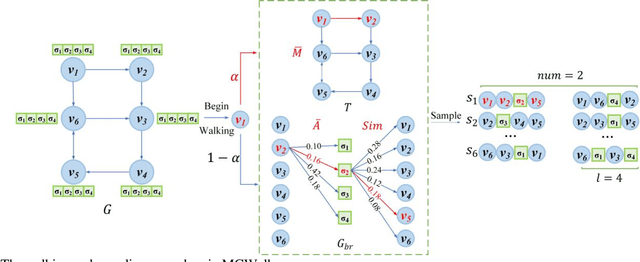
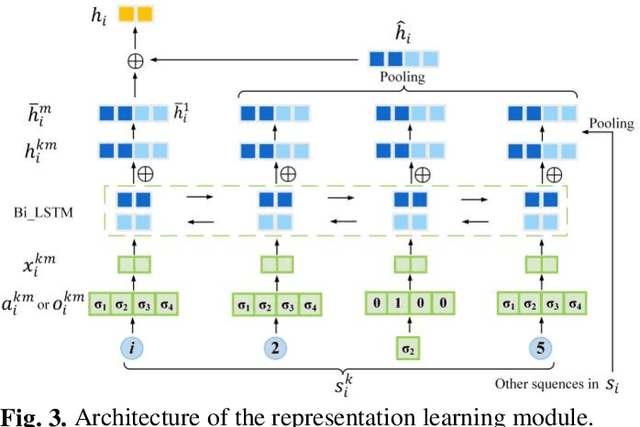
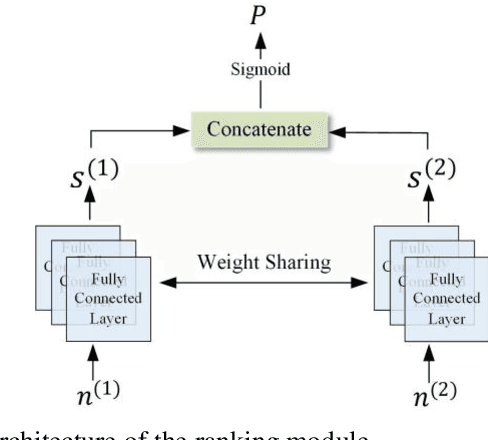
Identifying important nodes with strong propagation capabilities in road networks is a significant topic in the field of urban planning. However, existing methods for evaluating nodes importance consider only topological information and traffic volumes, ignoring the diversity of characteristics in road networks, such as the number of lanes and average speed of road segments, limiting their performance. To address this issue, this paper proposes a graph learning-based node ranking method (MGL2Rank) that integrates the rich characteristics of the road network. In this method, we first develop a sampling algorithm (MGWalk) that utilizes multi-graph fusion to establish association between road segments based on their attributes. Then, an embedding module is proposed to learn latent representation for each road segment. Finally, the obtained node representation is used to learn importance ranking of road segments. We conduct simulation experiments on the regional road network of Shenyang city and demonstrate the effectiveness of our proposed method. The data and source code of MGL2Rank are available at https://github.com/ZJ726.