 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Group channel pruning and spatial attention distilling for object detection
Jun 02, 2023
Due to the over-parameterization of neural networks, many model compression methods based on pruning and quantization have emerged. They are remarkable in reducing the size, parameter number, and computational complexity of the model. However, most of the models compressed by such methods need the support of special hardware and software, which increases the deployment cost. Moreover, these methods are mainly used in classification tasks, and rarely directly used in detection tasks. To address these issues, for the object detection network we introduce a three-stage model compression method: dynamic sparse training, group channel pruning, and spatial attention distilling. Firstly, to select out the unimportant channels in the network and maintain a good balance between sparsity and accuracy, we put forward a dynamic sparse training method, which introduces a variable sparse rate, and the sparse rate will change with the training process of the network. Secondly, to reduce the effect of pruning on network accuracy, we propose a novel pruning method called group channel pruning. In particular, we divide the network into multiple groups according to the scales of the feature layer and the similarity of module structure in the network, and then we use different pruning thresholds to prune the channels in each group. Finally, to recover the accuracy of the pruned network, we use an improved knowledge distillation method for the pruned network. Especially, we extract spatial attention information from the feature maps of specific scales in each group as knowledge for distillation. In the experiments, we use YOLOv4 as the object detection network and PASCAL VOC as the training dataset. Our method reduces the parameters of the model by 64.7 % and the calculation by 34.9%.
* Appl Intell
AI Transparency in the Age of LLMs: A Human-Centered Research Roadmap
Jun 02, 2023
The rise of powerful large language models (LLMs) brings about tremendous opportunities for innovation but also looming risks for individuals and society at large. We have reached a pivotal moment for ensuring that LLMs and LLM-infused applications are developed and deployed responsibly. However, a central pillar of responsible AI -- transparency -- is largely missing from the current discourse around LLMs. It is paramount to pursue new approaches to provide transparency for LLMs, and years of research at the intersection of AI and human-computer interaction (HCI) highlight that we must do so with a human-centered perspective: Transparency is fundamentally about supporting appropriate human understanding, and this understanding is sought by different stakeholders with different goals in different contexts. In this new era of LLMs, we must develop and design approaches to transparency by considering the needs of stakeholders in the emerging LLM ecosystem, the novel types of LLM-infused applications being built, and the new usage patterns and challenges around LLMs, all while building on lessons learned about how people process, interact with, and make use of information. We reflect on the unique challenges that arise in providing transparency for LLMs, along with lessons learned from HCI and responsible AI research that has taken a human-centered perspective on AI transparency. We then lay out four common approaches that the community has taken to achieve transparency -- model reporting, publishing evaluation results, providing explanations, and communicating uncertainty -- and call out open questions around how these approaches may or may not be applied to LLMs. We hope this provides a starting point for discussion and a useful roadmap for future research.
Autonomous GIS: the next-generation AI-powered GIS
May 10, 2023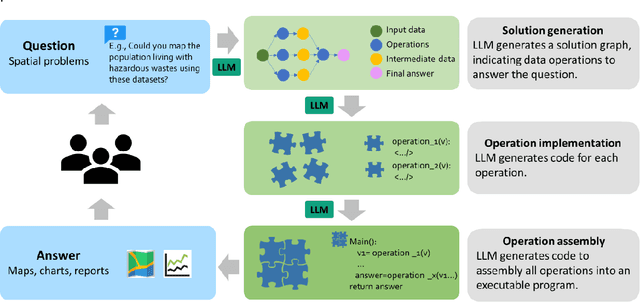
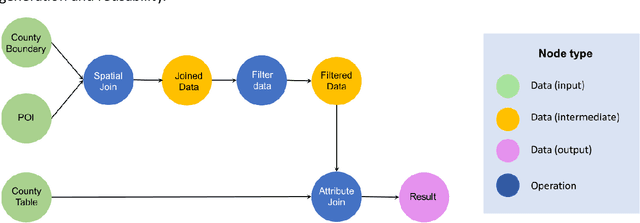


Large Language Models (LLMs), such as ChatGPT, demonstrate a strong understanding of human natural language and have been explored and applied in various fields, including reasoning, creative writing, code generation, translation, and information retrieval. By adopting LLM as the reasoning core, we propose Autonomous GIS, an AI-powered geographic information system (GIS) that leverages the LLM's general abilities in natural language understanding, reasoning and coding for addressing spatial problems with automatic spatial data collection, analysis and visualization. We envision that autonomous GIS will need to achieve five autonomous goals including self-generating, self-organizing, self-verifying, self-executing, and self-growing. We introduce the design principles of autonomous GIS to achieve these five autonomous goals from the aspects of information sufficiency, LLM ability, and agent architecture. We developed a prototype system called LLM-Geo using GPT-4 API in a Python environment, demonstrating what an autonomous GIS looks like and how it delivers expected results without human intervention using two case studies. For both case studies, LLM-Geo successfully returned accurate results, including aggregated numbers, graphs, and maps, significantly reducing manual operation time. Although still lacking several important modules such as logging and code testing, LLM-Geo demonstrates a potential path towards next-generation AI-powered GIS. We advocate for the GIScience community to dedicate more effort to the research and development of autonomous GIS, making spatial analysis easier, faster, and more accessible to a broader audience.
Finding Meaningful Distributions of ML Black-boxes under Forensic Investigation
May 10, 2023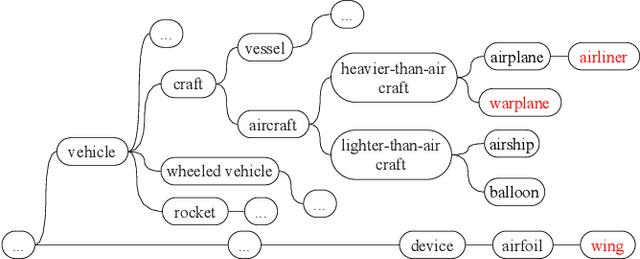
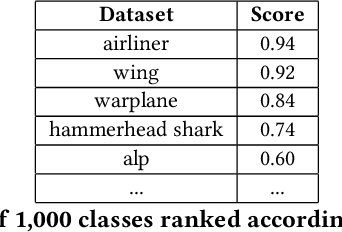
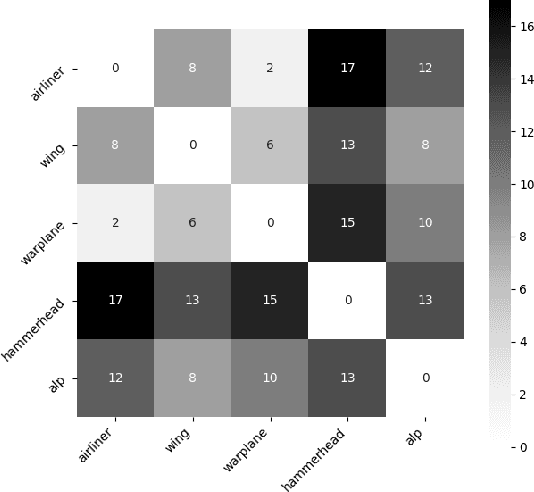
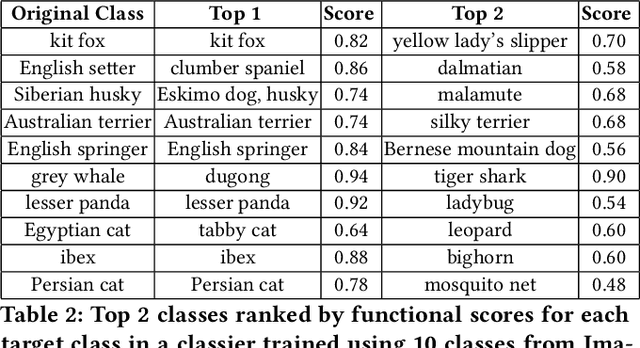
Given a poorly documented neural network model, we take the perspective of a forensic investigator who wants to find out the model's data domain (e.g. whether on face images or traffic signs). Although existing methods such as membership inference and model inversion can be used to uncover some information about an unknown model, they still require knowledge of the data domain to start with. In this paper, we propose solving this problem by leveraging on comprehensive corpus such as ImageNet to select a meaningful distribution that is close to the original training distribution and leads to high performance in follow-up investigations. The corpus comprises two components, a large dataset of samples and meta information such as hierarchical structure and textual information on the samples. Our goal is to select a set of samples from the corpus for the given model. The core of our method is an objective function that considers two criteria on the selected samples: the model functional properties (derived from the dataset), and semantics (derived from the metadata). We also give an algorithm to efficiently search the large space of all possible subsets w.r.t. the objective function. Experimentation results show that the proposed method is effective. For example, cloning a given model (originally trained with CIFAR-10) by using Caltech 101 can achieve 45.5% accuracy. By using datasets selected by our method, the accuracy is improved to 72.0%.
P-vectors: A Parallel-Coupled TDNN/Transformer Network for Speaker Verification
May 25, 2023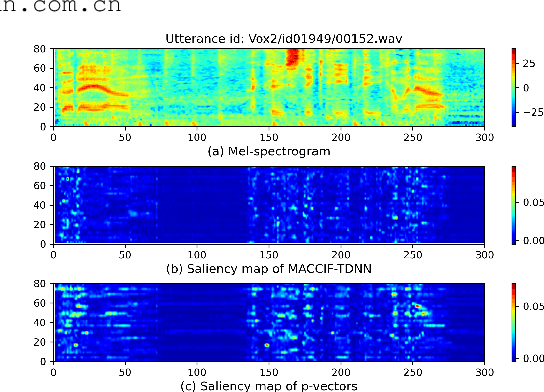
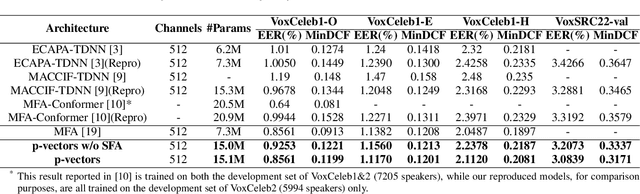
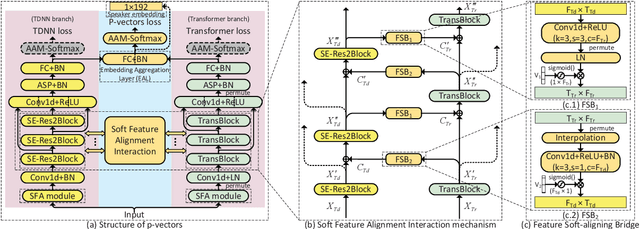

Typically, the Time-Delay Neural Network (TDNN) and Transformer can serve as a backbone for Speaker Verification (SV). Both of them have advantages and disadvantages from the perspective of global and local feature modeling. How to effectively integrate these two style features is still an open issue. In this paper, we explore a Parallel-coupled TDNN/Transformer Network (p-vectors) to replace the serial hybrid networks. The p-vectors allows TDNN and Transformer to learn the complementary information from each other through Soft Feature Alignment Interaction (SFAI) under the premise of preserving local and global features. Also, p-vectors uses the Spatial Frequency-channel Attention (SFA) to enhance the spatial interdependence modeling for input features. Finally, the outputs of dual branches of p-vectors are combined by Embedding Aggregation Layer (EAL). Experiments show that p-vectors outperforms MACCIF-TDNN and MFA-Conformer with relative improvements of 11.5% and 13.9% in EER on VoxCeleb1-O.
Contrastive Training of Complex-Valued Autoencoders for Object Discovery
May 25, 2023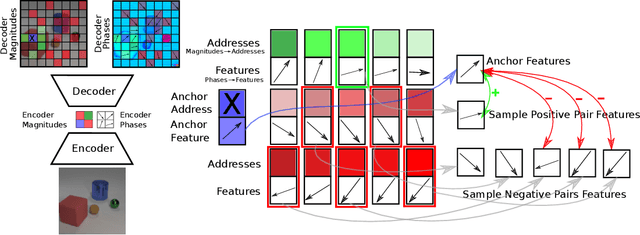
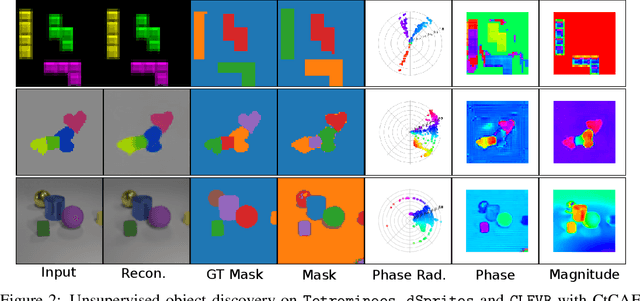
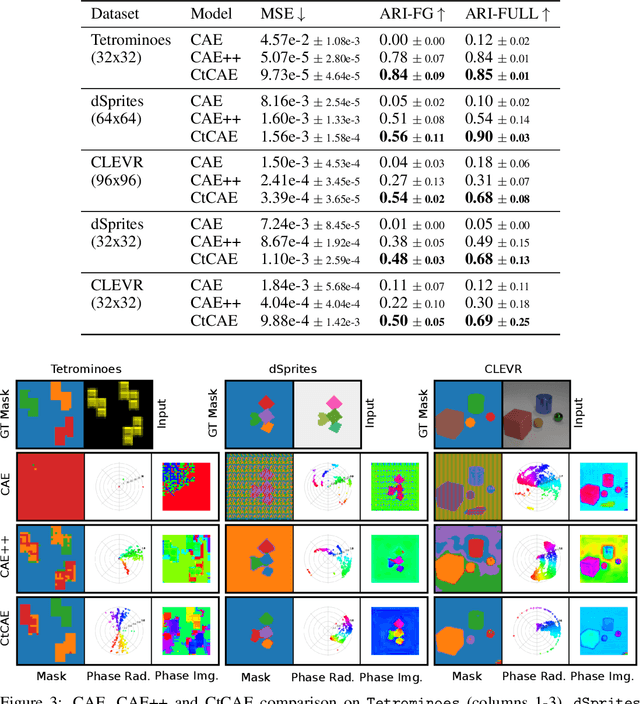
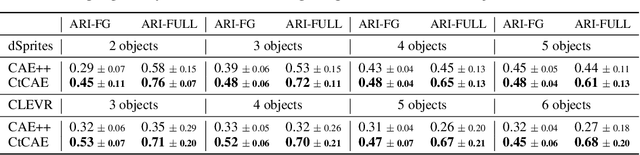
Current state-of-the-art object-centric models use slots and attention-based routing for binding. However, this class of models has several conceptual limitations: the number of slots is hardwired; all slots have equal capacity; training has high computational cost; there are no object-level relational factors within slots. Synchrony-based models in principle can address these limitations by using complex-valued activations which store binding information in their phase components. However, working examples of such synchrony-based models have been developed only very recently, and are still limited to toy grayscale datasets and simultaneous storage of less than three objects in practice. Here we introduce architectural modifications and a novel contrastive learning method that greatly improve the state-of-the-art synchrony-based model. For the first time, we obtain a class of synchrony-based models capable of discovering objects in an unsupervised manner in multi-object color datasets and simultaneously representing more than three objects
Market Making with Deep Reinforcement Learning from Limit Order Books
May 25, 2023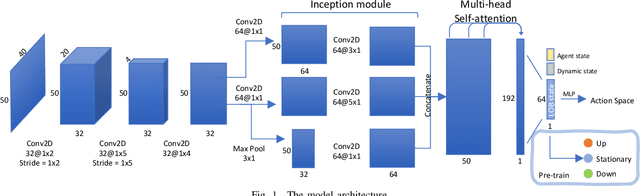
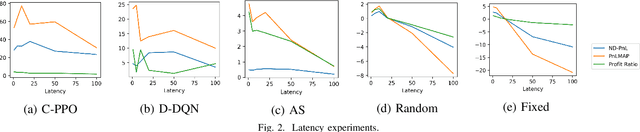
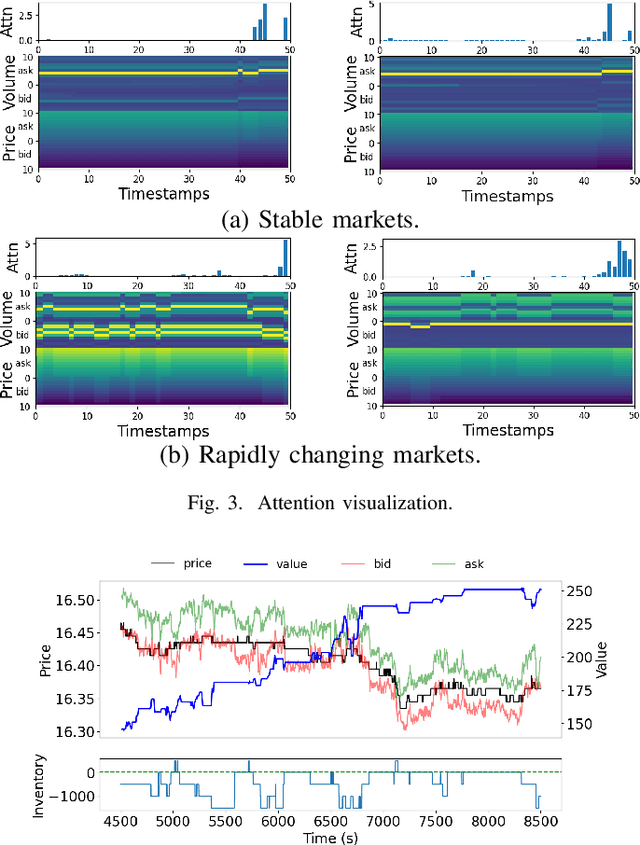
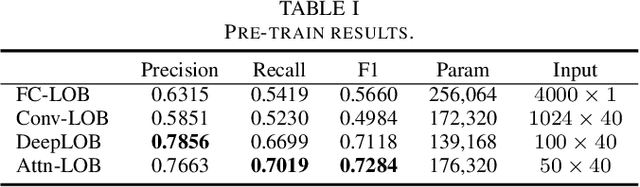
Market making (MM) is an important research topic in quantitative finance, the agent needs to continuously optimize ask and bid quotes to provide liquidity and make profits. The limit order book (LOB) contains information on all active limit orders, which is an essential basis for decision-making. The modeling of evolving, high-dimensional and low signal-to-noise ratio LOB data is a critical challenge. Traditional MM strategy relied on strong assumptions such as price process, order arrival process, etc. Previous reinforcement learning (RL) works handcrafted market features, which is insufficient to represent the market. This paper proposes a RL agent for market making with LOB data. We leverage a neural network with convolutional filters and attention mechanism (Attn-LOB) for feature extraction from LOB. We design a new continuous action space and a hybrid reward function for the MM task. Finally, we conduct comprehensive experiments on latency and interpretability, showing that our agent has good applicability.
Exploiting Noise as a Resource for Computation and Learning in Spiking Neural Networks
May 25, 2023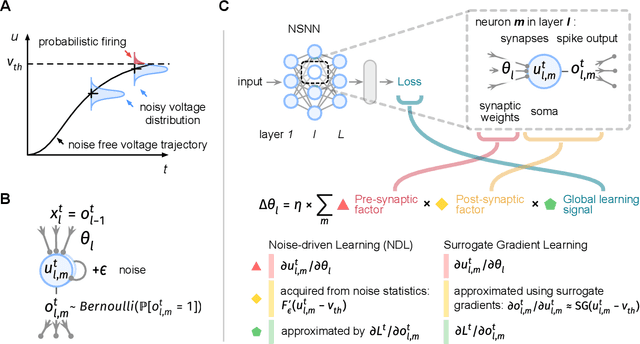
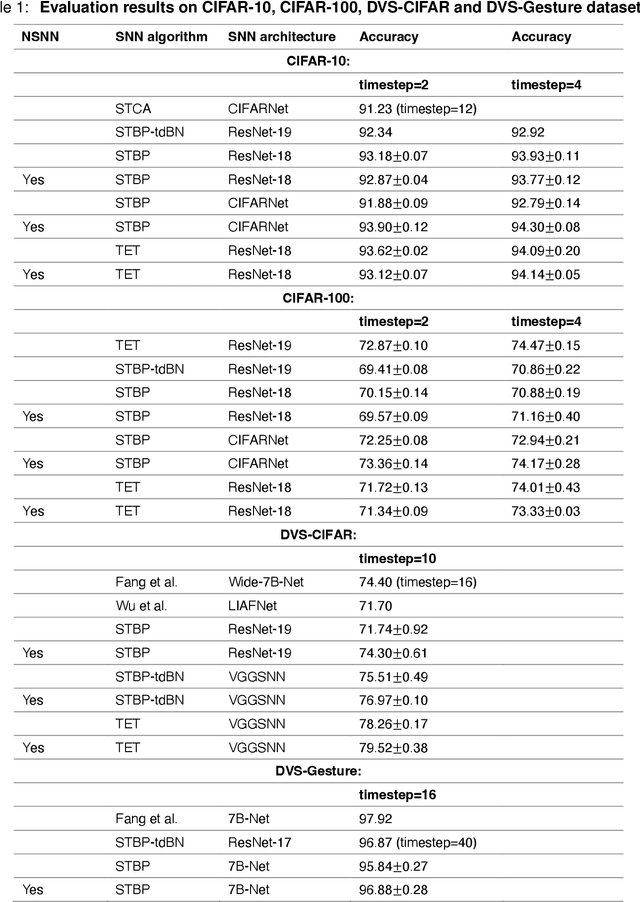
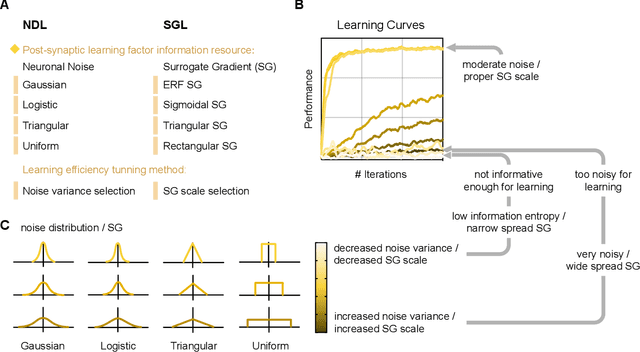
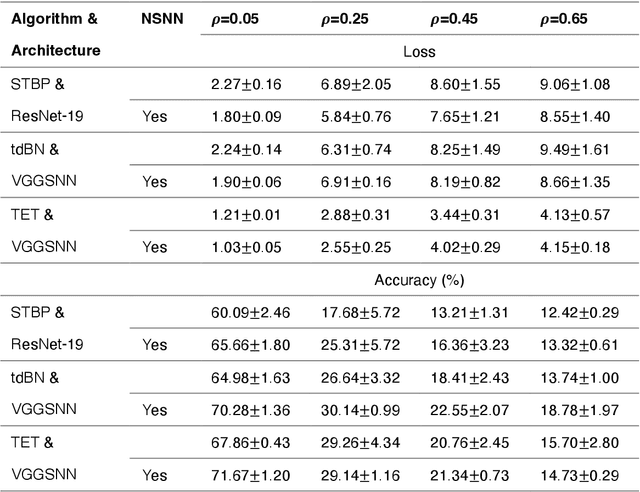
Networks of spiking neurons underpin the extraordinary information-processing capabilities of the brain and have emerged as pillar models in neuromorphic intelligence. Despite extensive research on spiking neural networks (SNNs), most are established on deterministic models. Integrating noise into SNNs leads to biophysically more realistic neural dynamics and may benefit model performance. This work presents the noisy spiking neural network (NSNN) and the noise-driven learning rule (NDL) by introducing a spiking neuron model incorporating noisy neuronal dynamics. Our approach shows how noise may act as a resource for computation and learning and theoretically provides a framework for general SNNs. Moreover, NDL provides an insightful rationale for surrogate gradients. By incorporating various SNN architectures and algorithms, we show that our approach exhibits competitive performance and improved robustness against challenging perturbations than deterministic SNNs. Additionally, we demonstrate the utility of the NSNN model for neural coding studies. Overall, NSNN offers a powerful, flexible, and easy-to-use tool for machine learning practitioners and computational neuroscience researchers.
Learning to Act through Evolution of Neural Diversity in Random Neural Networks
May 25, 2023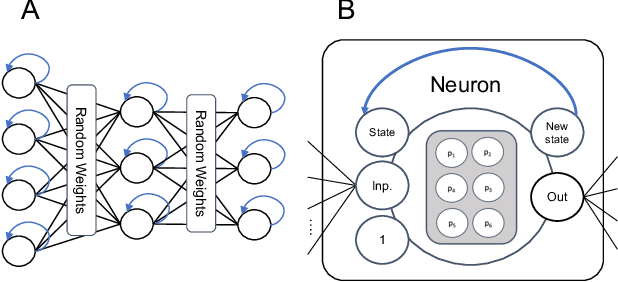


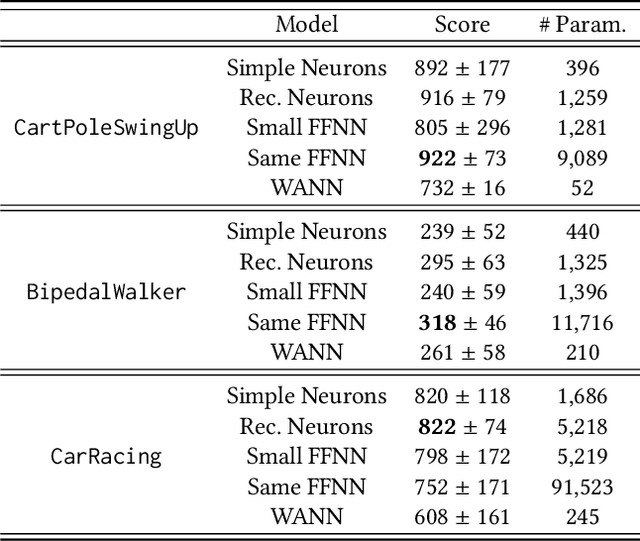
Biological nervous systems consist of networks of diverse, sophisticated information processors in the form of neurons of different classes. In most artificial neural networks (ANNs), neural computation is abstracted to an activation function that is usually shared between all neurons within a layer or even the whole network; training of ANNs focuses on synaptic optimization. In this paper, we propose the optimization of neuro-centric parameters to attain a set of diverse neurons that can perform complex computations. Demonstrating the promise of the approach, we show that evolving neural parameters alone allows agents to solve various reinforcement learning tasks without optimizing any synaptic weights. While not aiming to be an accurate biological model, parameterizing neurons to a larger degree than the current common practice, allows us to ask questions about the computational abilities afforded by neural diversity in random neural networks. The presented results open up interesting future research directions, such as combining evolved neural diversity with activity-dependent plasticity.
Novel deep learning methods for 3D flow field segmentation and classification
May 10, 2023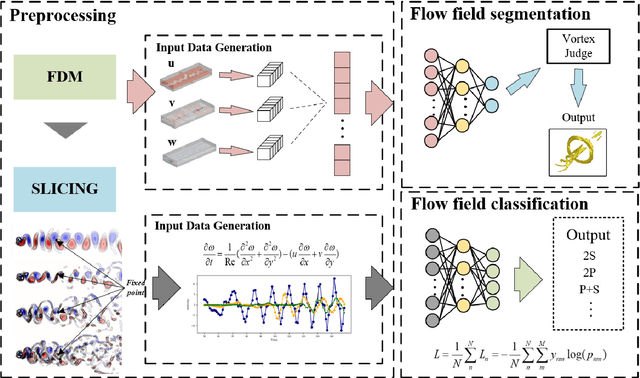
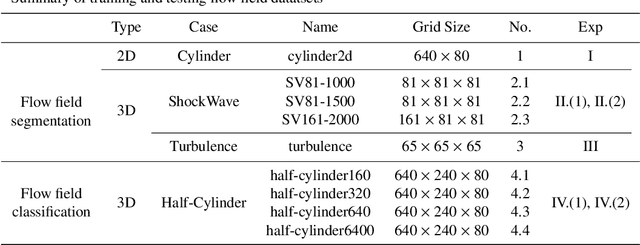
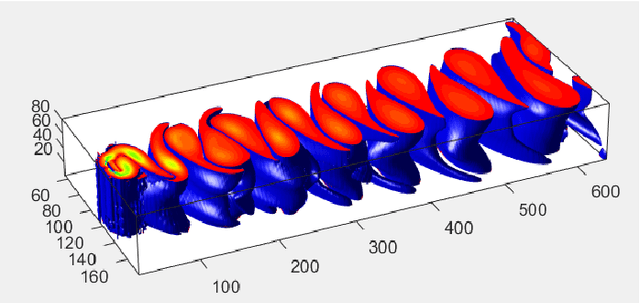
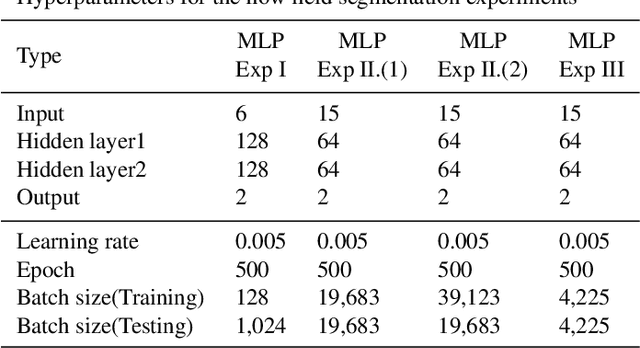
Flow field segmentation and classification help researchers to understand vortex structure and thus turbulent flow. Existing deep learning methods mainly based on global information and focused on 2D circumstance. Based on flow field theory, we propose novel flow field segmentation and classification deep learning methods in three-dimensional space. We construct segmentation criterion based on local velocity information and classification criterion based on the relationship between local vorticity and vortex wake, to identify vortex structure in 3D flow field, and further classify the type of vortex wakes accurately and rapidly. Simulation experiment results showed that, compared with existing methods, our segmentation method can identify the vortex area more accurately, while the time consumption is reduced more than 50\%; our classification method can reduce the time consumption by more than 90\% while maintaining the same classification accuracy level.