 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Context-Aware Transformer Pre-Training for Answer Sentence Selection
May 24, 2023
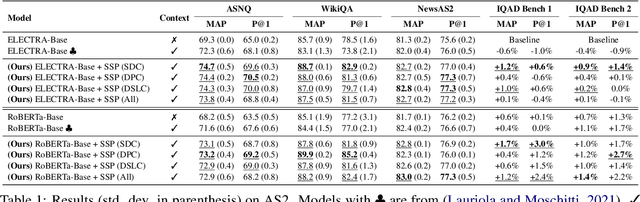
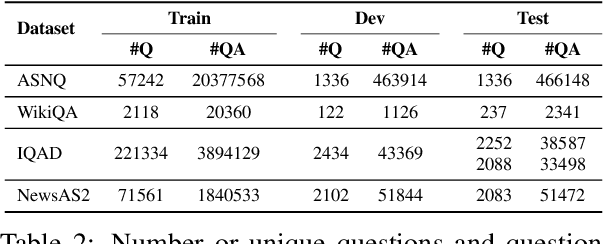
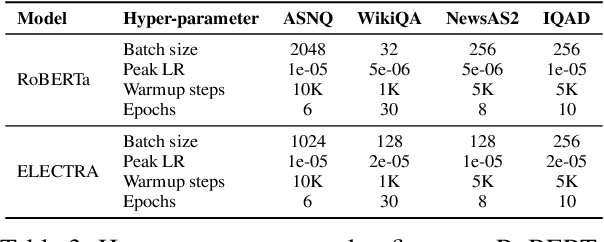

Answer Sentence Selection (AS2) is a core component for building an accurate Question Answering pipeline. AS2 models rank a set of candidate sentences based on how likely they answer a given question. The state of the art in AS2 exploits pre-trained transformers by transferring them on large annotated datasets, while using local contextual information around the candidate sentence. In this paper, we propose three pre-training objectives designed to mimic the downstream fine-tuning task of contextual AS2. This allows for specializing LMs when fine-tuning for contextual AS2. Our experiments on three public and two large-scale industrial datasets show that our pre-training approaches (applied to RoBERTa and ELECTRA) can improve baseline contextual AS2 accuracy by up to 8% on some datasets.
Some of the variables, some of the parameters, some of the times, with some physics known: Identification with partial information
Apr 27, 2023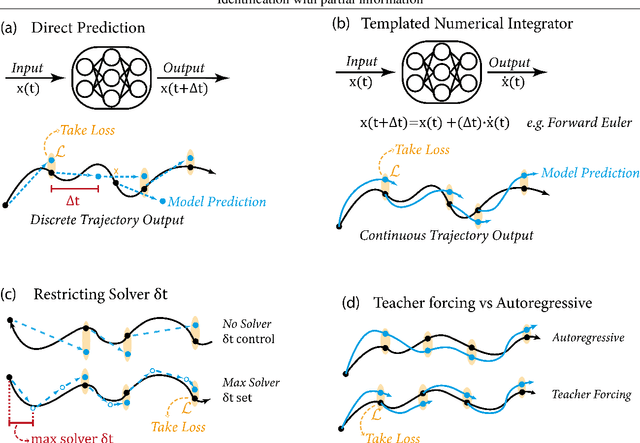
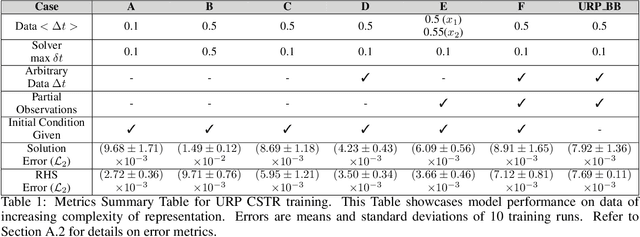
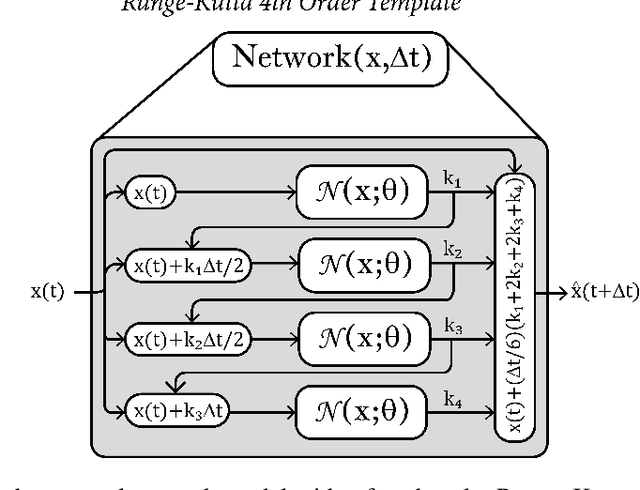
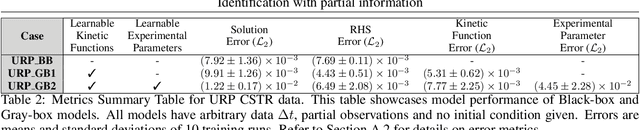
Experimental data is often comprised of variables measured independently, at different sampling rates (non-uniform ${\Delta}$t between successive measurements); and at a specific time point only a subset of all variables may be sampled. Approaches to identifying dynamical systems from such data typically use interpolation, imputation or subsampling to reorganize or modify the training data $\textit{prior}$ to learning. Partial physical knowledge may also be available $\textit{a priori}$ (accurately or approximately), and data-driven techniques can complement this knowledge. Here we exploit neural network architectures based on numerical integration methods and $\textit{a priori}$ physical knowledge to identify the right-hand side of the underlying governing differential equations. Iterates of such neural-network models allow for learning from data sampled at arbitrary time points $\textit{without}$ data modification. Importantly, we integrate the network with available partial physical knowledge in "physics informed gray-boxes"; this enables learning unknown kinetic rates or microbial growth functions while simultaneously estimating experimental parameters.
Learning for Edge-Weighted Online Bipartite Matching with Robustness Guarantees
May 31, 2023
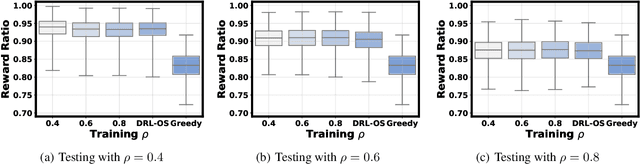
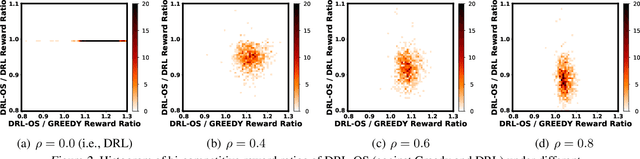

Many problems, such as online ad display, can be formulated as online bipartite matching. The crucial challenge lies in the nature of sequentially-revealed online item information, based on which we make irreversible matching decisions at each step. While numerous expert online algorithms have been proposed with bounded worst-case competitive ratios, they may not offer satisfactory performance in average cases. On the other hand, reinforcement learning (RL) has been applied to improve the average performance, but it lacks robustness and can perform arbitrarily poorly. In this paper, we propose a novel RL-based approach to edge-weighted online bipartite matching with robustness guarantees (LOMAR), achieving both good average-case and worst-case performance. The key novelty of LOMAR is a new online switching operation which, based on a judicious condition to hedge against future uncertainties, decides whether to follow the expert's decision or the RL decision for each online item. We prove that for any $\rho\in[0,1]$, LOMAR is $\rho$-competitive against any given expert online algorithm. To improve the average performance, we train the RL policy by explicitly considering the online switching operation. Finally, we run empirical experiments to demonstrate the advantages of LOMAR compared to existing baselines. Our code is available at: https://github.com/Ren-Research/LOMAR
Additional Positive Enables Better Representation Learning for Medical Images
May 31, 2023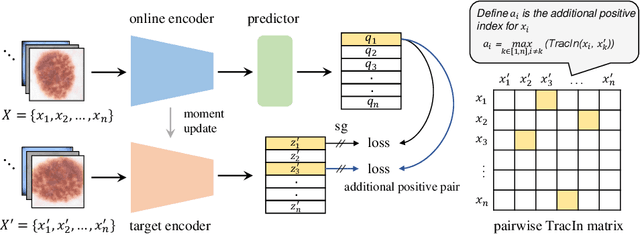
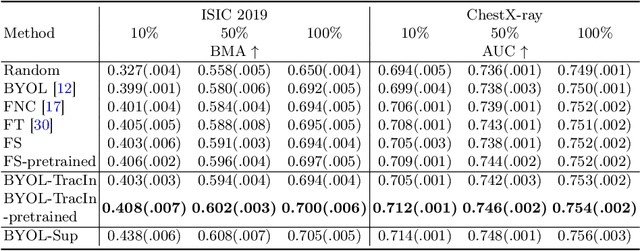
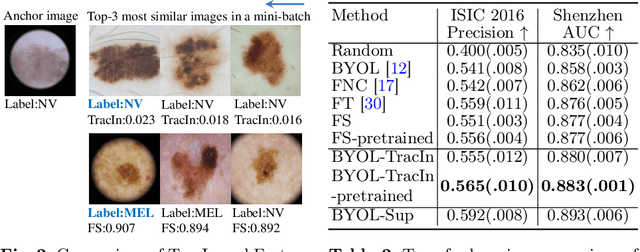
This paper presents a new way to identify additional positive pairs for BYOL, a state-of-the-art (SOTA) self-supervised learning framework, to improve its representation learning ability. Unlike conventional BYOL which relies on only one positive pair generated by two augmented views of the same image, we argue that information from different images with the same label can bring more diversity and variations to the target features, thus benefiting representation learning. To identify such pairs without any label, we investigate TracIn, an instance-based and computationally efficient influence function, for BYOL training. Specifically, TracIn is a gradient-based method that reveals the impact of a training sample on a test sample in supervised learning. We extend it to the self-supervised learning setting and propose an efficient batch-wise per-sample gradient computation method to estimate the pairwise TracIn to represent the similarity of samples in the mini-batch during training. For each image, we select the most similar sample from other images as the additional positive and pull their features together with BYOL loss. Experimental results on two public medical datasets (i.e., ISIC 2019 and ChestX-ray) demonstrate that the proposed method can improve the classification performance compared to other competitive baselines in both semi-supervised and transfer learning settings.
A Unified Framework for U-Net Design and Analysis
May 31, 2023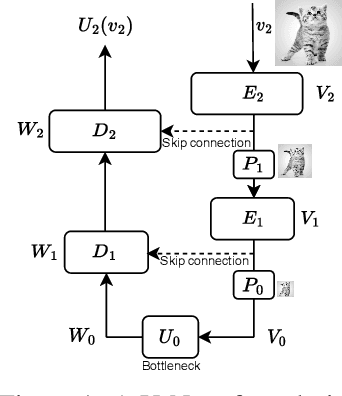
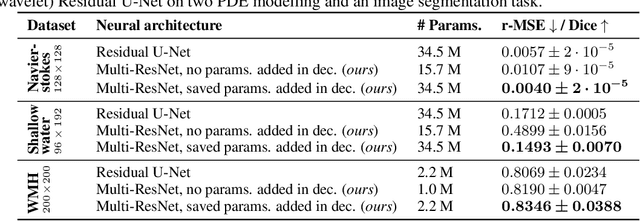
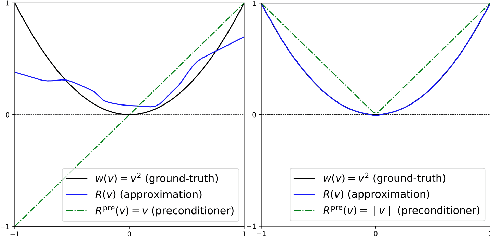

U-Nets are a go-to, state-of-the-art neural architecture across numerous tasks for continuous signals on a square such as images and Partial Differential Equations (PDE), however their design and architecture is understudied. In this paper, we provide a framework for designing and analysing general U-Net architectures. We present theoretical results which characterise the role of the encoder and decoder in a U-Net, their high-resolution scaling limits and their conjugacy to ResNets via preconditioning. We propose Multi-ResNets, U-Nets with a simplified, wavelet-based encoder without learnable parameters. Further, we show how to design novel U-Net architectures which encode function constraints, natural bases, or the geometry of the data. In diffusion models, our framework enables us to identify that high-frequency information is dominated by noise exponentially faster, and show how U-Nets with average pooling exploit this. In our experiments, we demonstrate how Multi-ResNets achieve competitive and often superior performance compared to classical U-Nets in image segmentation, PDE surrogate modelling, and generative modelling with diffusion models. Our U-Net framework paves the way to study the theoretical properties of U-Nets and design natural, scalable neural architectures for a multitude of problems beyond the square.
A Framework For Refining Text Classification and Object Recognition from Academic Articles
May 31, 2023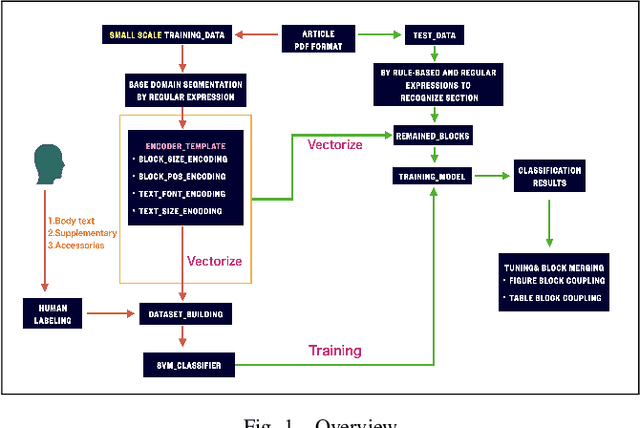

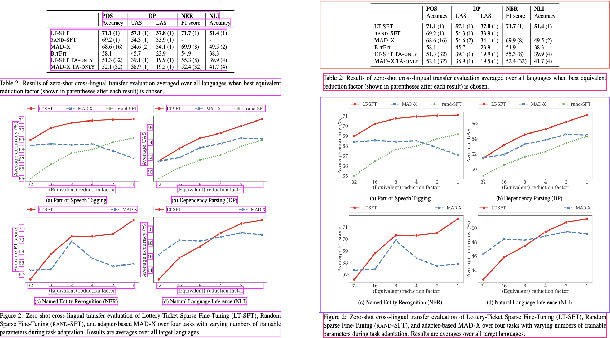
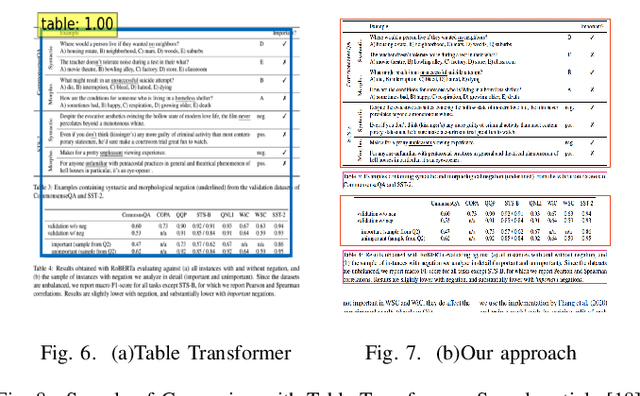
With the widespread use of the internet, it has become increasingly crucial to extract specific information from vast amounts of academic articles efficiently. Data mining techniques are generally employed to solve this issue. However, data mining for academic articles is challenging since it requires automatically extracting specific patterns in complex and unstructured layout documents. Current data mining methods for academic articles employ rule-based(RB) or machine learning(ML) approaches. However, using rule-based methods incurs a high coding cost for complex typesetting articles. On the other hand, simply using machine learning methods requires annotation work for complex content types within the paper, which can be costly. Furthermore, only using machine learning can lead to cases where patterns easily recognized by rule-based methods are mistakenly extracted. To overcome these issues, from the perspective of analyzing the standard layout and typesetting used in the specified publication, we emphasize implementing specific methods for specific characteristics in academic articles. We have developed a novel Text Block Refinement Framework (TBRF), a machine learning and rule-based scheme hybrid. We used the well-known ACL proceeding articles as experimental data for the validation experiment. The experiment shows that our approach achieved over 95% classification accuracy and 90% detection accuracy for tables and figures.
Adversary for Social Good: Leveraging Adversarial Attacks to Protect Personal Attribute Privacy
Jun 04, 2023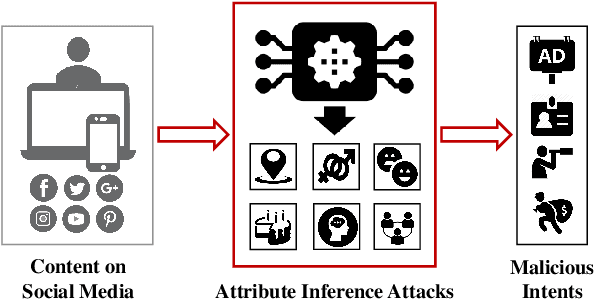
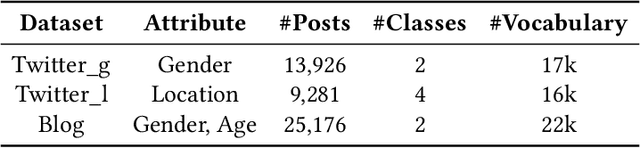
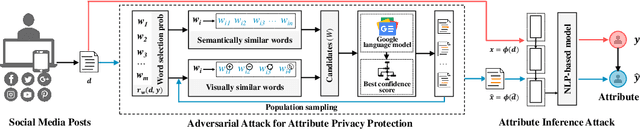
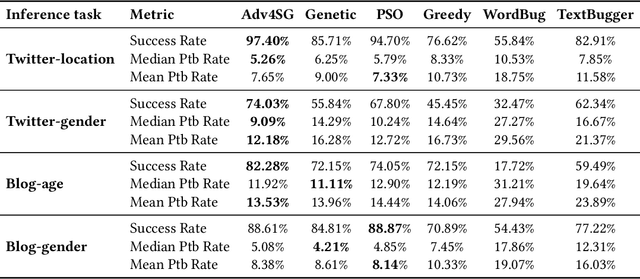
Social media has drastically reshaped the world that allows billions of people to engage in such interactive environments to conveniently create and share content with the public. Among them, text data (e.g., tweets, blogs) maintains the basic yet important social activities and generates a rich source of user-oriented information. While those explicit sensitive user data like credentials has been significantly protected by all means, personal private attribute (e.g., age, gender, location) disclosure due to inference attacks is somehow challenging to avoid, especially when powerful natural language processing (NLP) techniques have been effectively deployed to automate attribute inferences from implicit text data. This puts users' attribute privacy at risk. To address this challenge, in this paper, we leverage the inherent vulnerability of machine learning to adversarial attacks, and design a novel text-space Adversarial attack for Social Good, called Adv4SG. In other words, we cast the problem of protecting personal attribute privacy as an adversarial attack formulation problem over the social media text data to defend against NLP-based attribute inference attacks. More specifically, Adv4SG proceeds with a sequence of word perturbations under given constraints such that the probed attribute cannot be identified correctly. Different from the prior works, we advance Adv4SG by considering social media property, and introducing cost-effective mechanisms to expedite attribute obfuscation over text data under the black-box setting. Extensive experiments on real-world social media datasets have demonstrated that our method can effectively degrade the inference accuracy with less computational cost over different attribute settings, which substantially helps mitigate the impacts of inference attacks and thus achieve high performance in user attribute privacy protection.
Building Intelligence in the Mechanical Domain -- Harvesting the Reservoir Computing Power in Origami to Achieve Information Perception Tasks
Feb 10, 2023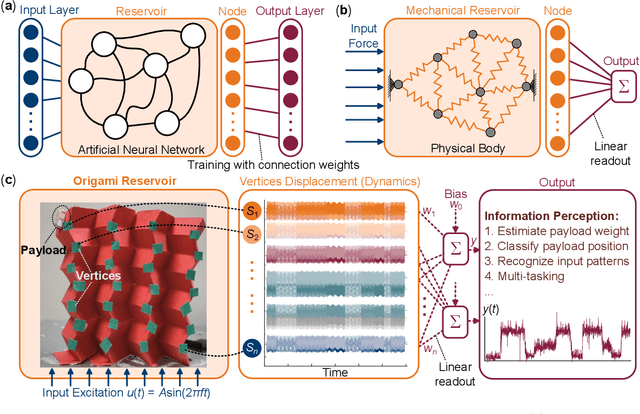
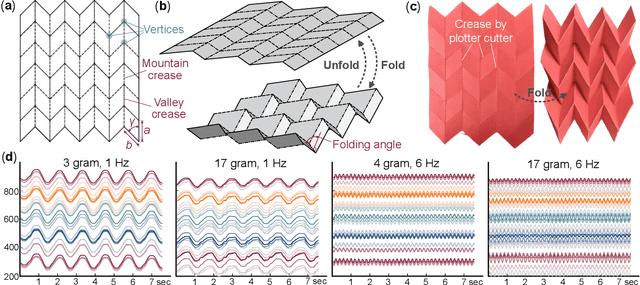
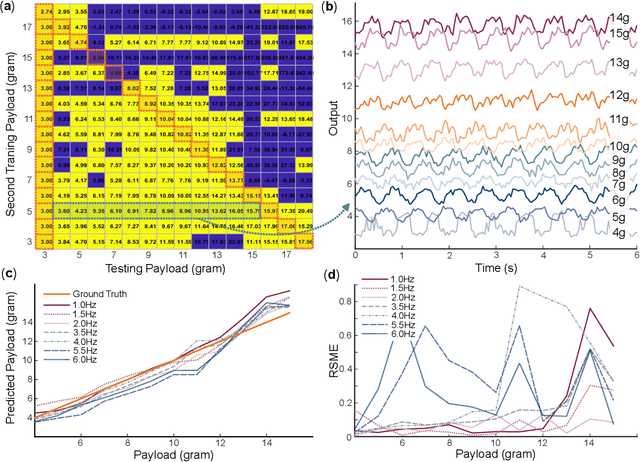
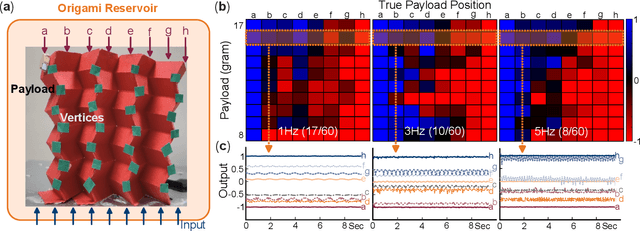
In this paper, we experimentally examine the cognitive capability of a simple, paper-based Miura-ori -- using the physical reservoir computing framework -- to achieve different information perception tasks. The body dynamics of Miura-ori (aka. its vertices displacements), which is excited by a simple harmonic base excitation, can be exploited as the reservoir computing resource. By recording these dynamics with a high-resolution camera and image processing program and then using linear regression for training, we show that the origami reservoir has sufficient computing capacity to estimate the weight and position of a payload. It can also recognize the input frequency and magnitude patterns. Furthermore, multitasking is achievable by simultaneously applying two targeted functions to the same reservoir state matrix. Therefore, we demonstrate that Miura-ori can assess the dynamic interactions between its body and ambient environment to extract meaningful information -- an intelligent behavior in the mechanical domain. Given that Miura-ori has been widely used to construct deployable structures, lightweight materials, and compliant robots, enabling such information perception tasks can add a new dimension to the functionality of such a versatile structure.
CIF-PT: Bridging Speech and Text Representations for Spoken Language Understanding via Continuous Integrate-and-Fire Pre-Training
May 27, 2023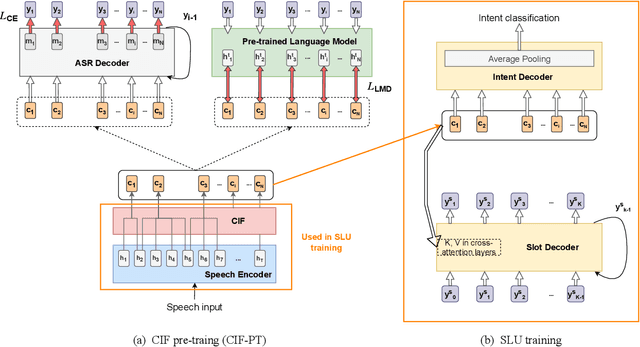
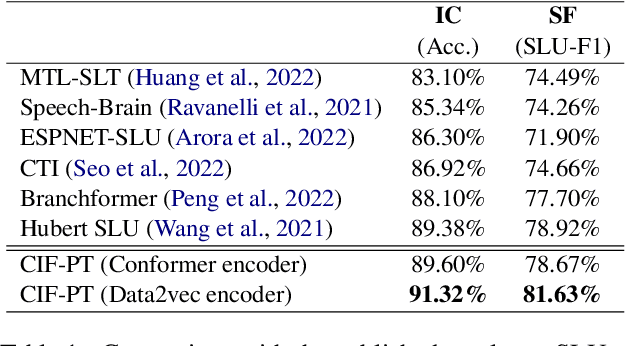
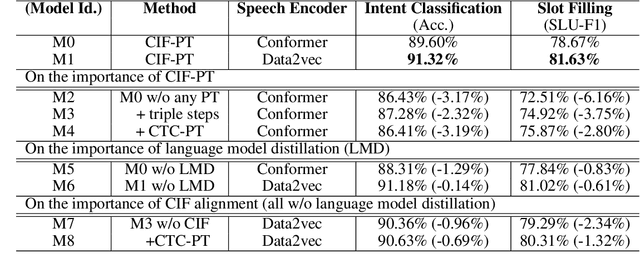
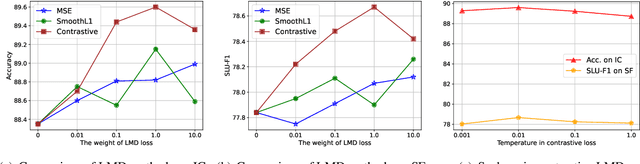
Speech or text representation generated by pre-trained models contains modal-specific information that could be combined for benefiting spoken language understanding (SLU) tasks. In this work, we propose a novel pre-training paradigm termed Continuous Integrate-and-Fire Pre-Training (CIF-PT). It relies on a simple but effective frame-to-token alignment: continuous integrate-and-fire (CIF) to bridge the representations between speech and text. It jointly performs speech-to-text training and language model distillation through CIF as the pre-training (PT). Evaluated on SLU benchmark SLURP dataset, CIF-PT outperforms the state-of-the-art model by 1.94% of accuracy and 2.71% of SLU-F1 on the tasks of intent classification and slot filling, respectively. We also observe the cross-modal representation extracted by CIF-PT obtains better performance than other neural interfaces for the tasks of SLU, including the dominant speech representation learned from self-supervised pre-training.
Gradient-free optimization of highly smooth functions: improved analysis and a new algorithm
Jun 03, 2023
This work studies minimization problems with zero-order noisy oracle information under the assumption that the objective function is highly smooth and possibly satisfies additional properties. We consider two kinds of zero-order projected gradient descent algorithms, which differ in the form of the gradient estimator. The first algorithm uses a gradient estimator based on randomization over the $\ell_2$ sphere due to Bach and Perchet (2016). We present an improved analysis of this algorithm on the class of highly smooth and strongly convex functions studied in the prior work, and we derive rates of convergence for two more general classes of non-convex functions. Namely, we consider highly smooth functions satisfying the Polyak-{\L}ojasiewicz condition and the class of highly smooth functions with no additional property. The second algorithm is based on randomization over the $\ell_1$ sphere, and it extends to the highly smooth setting the algorithm that was recently proposed for Lipschitz convex functions in Akhavan et al. (2022). We show that, in the case of noiseless oracle, this novel algorithm enjoys better bounds on bias and variance than the $\ell_2$ randomization and the commonly used Gaussian randomization algorithms, while in the noisy case both $\ell_1$ and $\ell_2$ algorithms benefit from similar improved theoretical guarantees. The improvements are achieved thanks to a new proof techniques based on Poincar\'e type inequalities for uniform distributions on the $\ell_1$ or $\ell_2$ spheres. The results are established under weak (almost adversarial) assumptions on the noise. Moreover, we provide minimax lower bounds proving optimality or near optimality of the obtained upper bounds in several cases.