 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Image-based Visual Servo Control for Aerial Manipulation Using a Fully-Actuated UAV
Jun 28, 2023


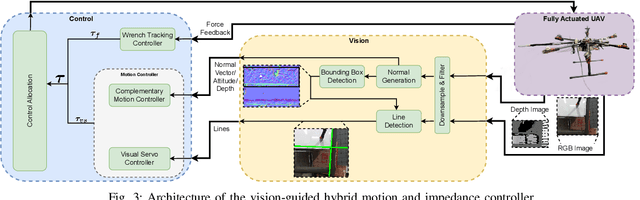
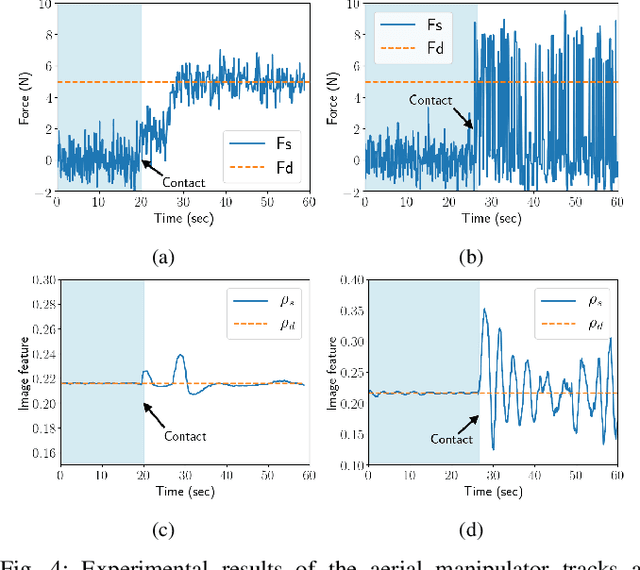
Using Unmanned Aerial Vehicles (UAVs) to perform high-altitude manipulation tasks beyond just passive visual application can reduce the time, cost, and risk of human workers. Prior research on aerial manipulation has relied on either ground truth state estimate or GPS/total station with some Simultaneous Localization and Mapping (SLAM) algorithms, which may not be practical for many applications close to infrastructure with degraded GPS signal or featureless environments. Visual servo can avoid the need to estimate robot pose. Existing works on visual servo for aerial manipulation either address solely end-effector position control or rely on precise velocity measurement and pre-defined visual visual marker with known pattern. Furthermore, most of previous work used under-actuated UAVs, resulting in complicated mechanical and hence control design for the end-effector. This paper develops an image-based visual servo control strategy for bridge maintenance using a fully-actuated UAV. The main components are (1) a visual line detection and tracking system, (2) a hybrid impedance force and motion control system. Our approach does not rely on either robot pose/velocity estimation from an external localization system or pre-defined visual markers. The complexity of the mechanical system and controller architecture is also minimized due to the fully-actuated nature. Experiments show that the system can effectively execute motion tracking and force holding using only the visual guidance for the bridge painting. To the best of our knowledge, this is one of the first studies on aerial manipulation using visual servo that is capable of achieving both motion and force control without the need of external pose/velocity information or pre-defined visual guidance.
Learning to Pan-sharpening with Memories of Spatial Details
Jun 28, 2023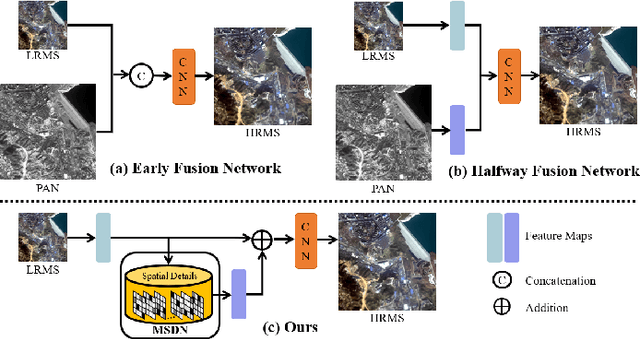


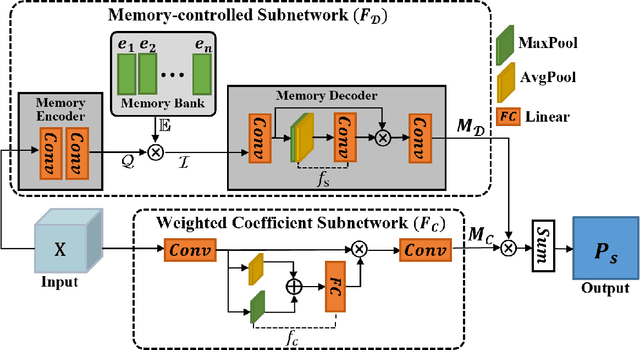
Pan-sharpening, as one of the most commonly used techniques in remote sensing systems, aims to inject spatial details from panchromatic images into multi-spectral images to obtain high-resolution MS images. Since deep learning has received widespread attention because of its powerful fitting ability and efficient feature extraction, a variety of pan-sharpening methods have been proposed to achieve remarkable performance. However, current pan-sharpening methods usually require the paired PAN and MS images as the input, which limits their usage in some scenarios. To address this issue, in this paper, we observe that the spatial details from PAN images are mainly high-frequency cues, i.e., the edges reflect the contour of input PAN images. This motivates us to develop a PAN-agnostic representation to store some base edges, so as to compose the contour for the corresponding PAN image via them. As a result, we can perform the pan-sharpening task with only the MS image when inference. To this end, a memory-based network is adapted to extract and memorize the spatial details during the training phase and is used to replace the process of obtaining spatial information from PAN images when inference, which is called Memory-based Spatial Details Network (MSDN). We finally integrate the proposed MSDN module into the existing DL-based pan-sharpening methods to achieve an end-to-end pan-sharpening network. With extensive experiments on the Gaofen1 and WorldView-4 satellites, we verify that our method constructs good spatial details without PAN images and achieves the best performance. The code is available at https://github.com/Zhao-Tian-yi/Learning-to-Pan-sharpening-with-Memories-of-Spatial-Details.git.
Diffusion in Diffusion: Cyclic One-Way Diffusion for Text-Vision-Conditioned Generation
Jun 17, 2023


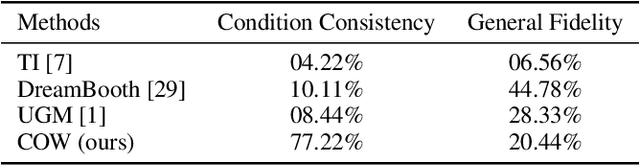
Text-to-Image (T2I) generation with diffusion models allows users to control the semantic content in the synthesized images given text conditions. As a further step toward a more customized image creation application, we introduce a new multi-modality generation setting that synthesizes images based on not only the semantic-level textual input but also on the pixel-level visual conditions. Existing literature first converts the given visual information to semantic-level representation by connecting it to languages, and then incorporates it into the original denoising process. Seemingly intuitive, such methodological design loses the pixel values during the semantic transition, thus failing to fulfill the task scenario where the preservation of low-level vision is desired (e.g., ID of a given face image). To this end, we propose Cyclic One-Way Diffusion (COW), a training-free framework for creating customized images with respect to semantic text and pixel-visual conditioning. Notably, we observe that sub-regions of an image impose mutual interference, just like physical diffusion, to achieve ultimate harmony along the denoising trajectory. Thus we propose to repetitively utilize the given visual condition in a cyclic way, by planting the visual condition as a high-concentration "seed" at the initialization step of the denoising process, and "diffuse" it into a harmonious picture by controlling a one-way information flow from the visual condition. We repeat the destroy-and-construct process multiple times to gradually but steadily impose the internal diffusion process within the image. Experiments on the challenging one-shot face and text-conditioned image synthesis task demonstrate our superiority in terms of speed, image quality, and conditional fidelity compared to learning-based text-vision conditional methods. Project page is available at: https://bigaandsmallq.github.io/COW/
MI-SegNet: Mutual Information-Based US Segmentation for Unseen Domain Generalization
Mar 22, 2023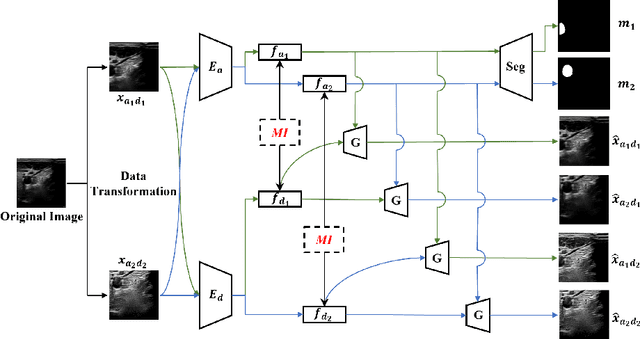
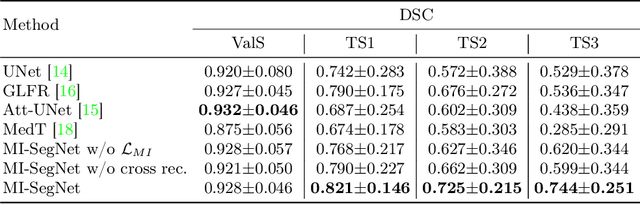

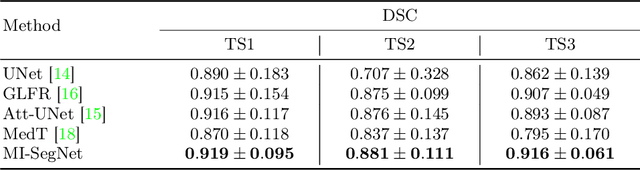
Generalization capabilities of learning-based medical image segmentation across domains are currently limited by the performance degradation caused by the domain shift, particularly for ultrasound (US) imaging. The quality of US images heavily relies on carefully tuned acoustic parameters, which vary across sonographers, machines, and settings. To improve the generalizability on US images across domains, we propose MI-SegNet, a novel mutual information (MI) based framework to explicitly disentangle the anatomical and domain feature representations; therefore, robust domain-independent segmentation can be expected. Two encoders are employed to extract the relevant features for the disentanglement. The segmentation only uses the anatomical feature map for its prediction. In order to force the encoders to learn meaningful feature representations a cross-reconstruction method is used during training. Transformations, specific to either domain or anatomy are applied to guide the encoders in their respective feature extraction task. Additionally, any MI present in both feature maps is punished to further promote separate feature spaces. We validate the generalizability of the proposed domain-independent segmentation approach on several datasets with varying parameters and machines. Furthermore, we demonstrate the effectiveness of the proposed MI-SegNet serving as a pre-trained model by comparing it with state-of-the-art networks.
An overview on the evaluated video retrieval tasks at TRECVID 2022
Jun 22, 2023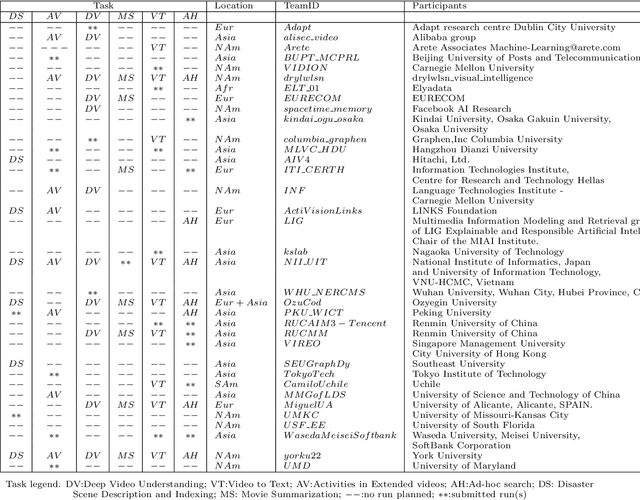

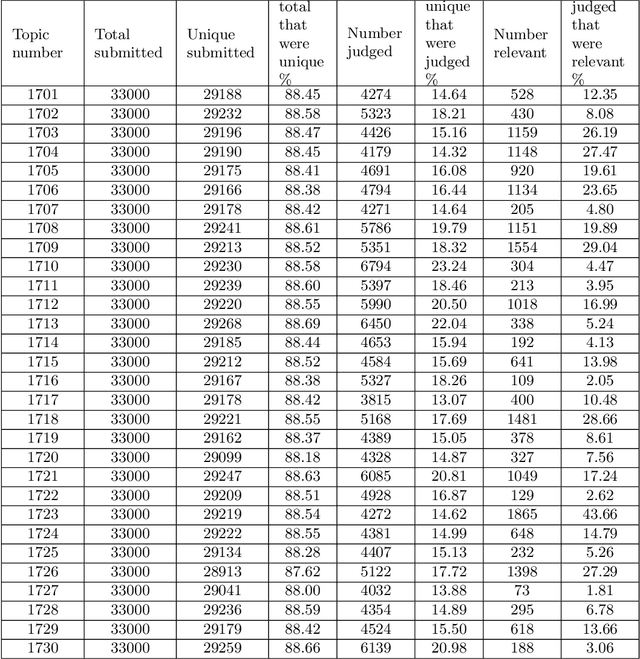
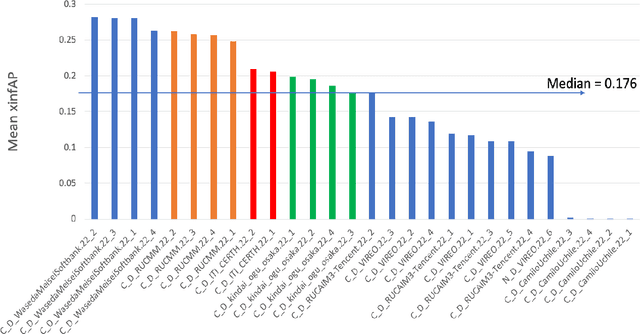
The TREC Video Retrieval Evaluation (TRECVID) is a TREC-style video analysis and retrieval evaluation with the goal of promoting progress in research and development of content-based exploitation and retrieval of information from digital video via open, tasks-based evaluation supported by metrology. Over the last twenty-one years this effort has yielded a better understanding of how systems can effectively accomplish such processing and how one can reliably benchmark their performance. TRECVID has been funded by NIST (National Institute of Standards and Technology) and other US government agencies. In addition, many organizations and individuals worldwide contribute significant time and effort. TRECVID 2022 planned for the following six tasks: Ad-hoc video search, Video to text captioning, Disaster scene description and indexing, Activity in extended videos, deep video understanding, and movie summarization. In total, 35 teams from various research organizations worldwide signed up to join the evaluation campaign this year. This paper introduces the tasks, datasets used, evaluation frameworks and metrics, as well as a high-level results overview.
Efficient quantum image representation and compression circuit using zero-discarded state preparation approach
Jun 22, 2023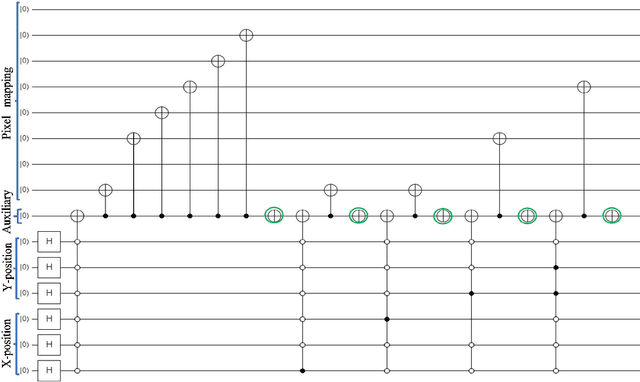
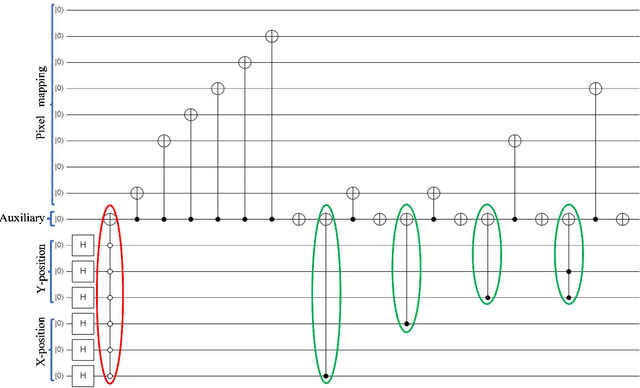
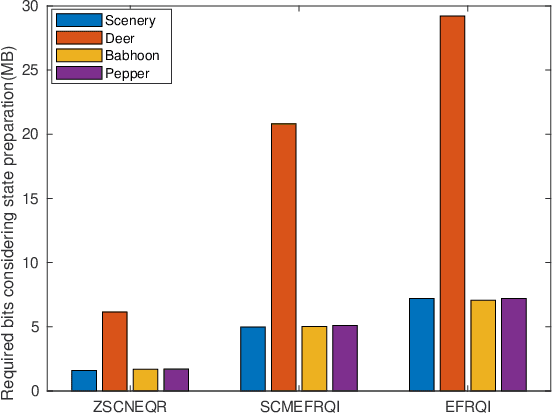
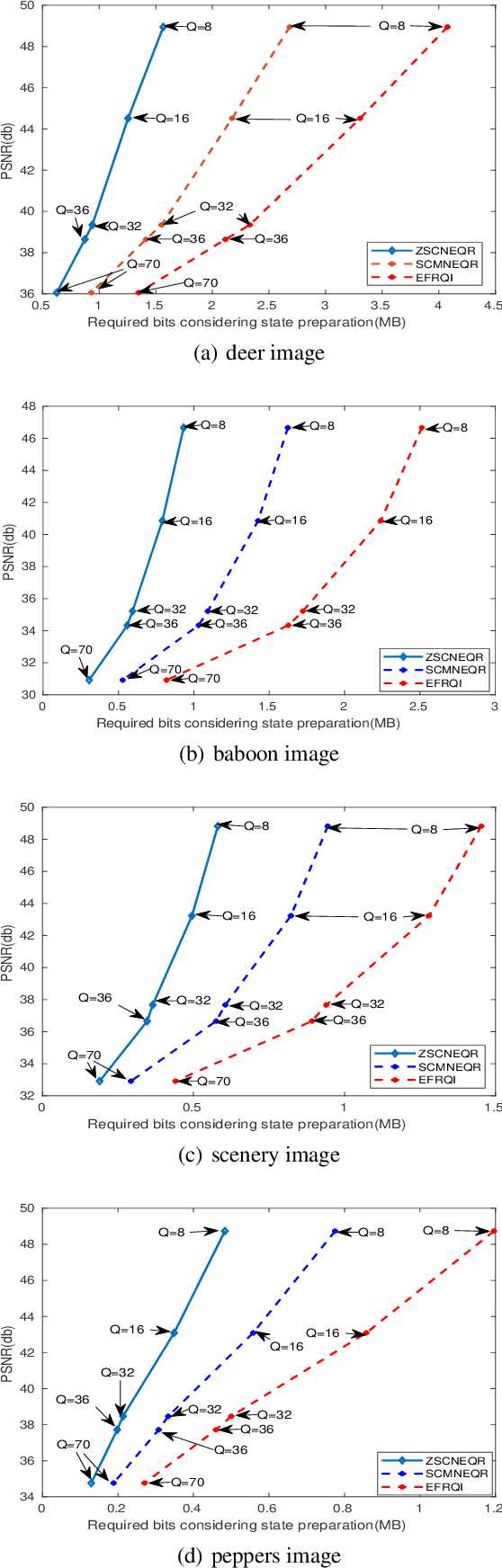
Quantum image computing draws a lot of attention due to storing and processing image data faster than classical. With increasing the image size, the number of connections also increases, leading to the circuit complex. Therefore, efficient quantum image representation and compression issues are still challenging. The encoding of images for representation and compression in quantum systems is different from classical ones. In quantum, encoding of position is more concerned which is the major difference from the classical. In this paper, a novel zero-discarded state connection novel enhance quantum representation (ZSCNEQR) approach is introduced to reduce complexity further by discarding '0' in the location representation information. In the control operational gate, only input '1' contribute to its output thus, discarding zero makes the proposed ZSCNEQR circuit more efficient. The proposed ZSCNEQR approach significantly reduced the required bit for both representation and compression. The proposed method requires 11.76\% less qubits compared to the recent existing method. The results show that the proposed approach is highly effective for representing and compressing images compared to the two relevant existing methods in terms of rate-distortion performance.
Learning from Visual Observation via Offline Pretrained State-to-Go Transformer
Jun 22, 2023Learning from visual observation (LfVO), aiming at recovering policies from only visual observation data, is promising yet a challenging problem. Existing LfVO approaches either only adopt inefficient online learning schemes or require additional task-specific information like goal states, making them not suited for open-ended tasks. To address these issues, we propose a two-stage framework for learning from visual observation. In the first stage, we introduce and pretrain State-to-Go (STG) Transformer offline to predict and differentiate latent transitions of demonstrations. Subsequently, in the second stage, the STG Transformer provides intrinsic rewards for downstream reinforcement learning tasks where an agent learns merely from intrinsic rewards. Empirical results on Atari and Minecraft show that our proposed method outperforms baselines and in some tasks even achieves performance comparable to the policy learned from environmental rewards. These results shed light on the potential of utilizing video-only data to solve difficult visual reinforcement learning tasks rather than relying on complete offline datasets containing states, actions, and rewards. The project's website and code can be found at https://sites.google.com/view/stgtransformer.
Continuous Online Extrinsic Calibration of Fisheye Camera and LiDAR
Jun 22, 2023
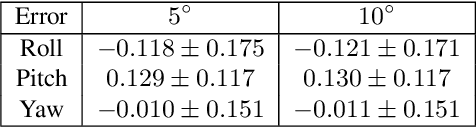
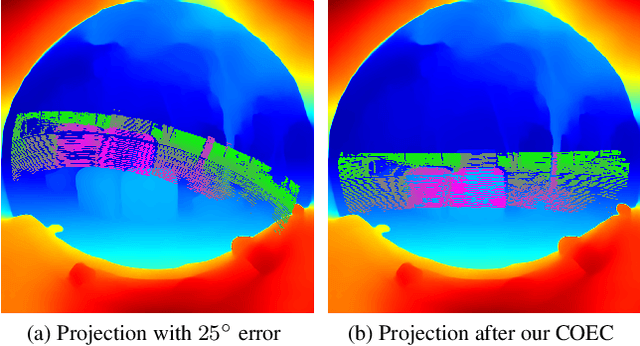
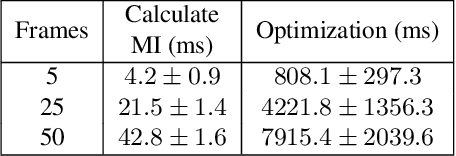
Automated driving systems use multi-modal sensor suites to ensure the reliable, redundant and robust perception of the operating domain, for example camera and LiDAR. An accurate extrinsic calibration is required to fuse the camera and LiDAR data into a common spatial reference frame required by high-level perception functions. Over the life of the vehicle the value of the extrinsic calibration can change due physical disturbances, introducing an error into the high-level perception functions. Therefore there is a need for continuous online extrinsic calibration algorithms which can automatically update the value of the camera-LiDAR calibration during the life of the vehicle using only sensor data. We propose using mutual information between the camera image's depth estimate, provided by commonly available monocular depth estimation networks, and the LiDAR pointcloud's geometric distance as a optimization metric for extrinsic calibration. Our method requires no calibration target, no ground truth training data and no expensive offline optimization. We demonstrate our algorithm's accuracy, precision, speed and self-diagnosis capability on the KITTI-360 data set.
DocILE 2023 Teaser: Document Information Localization and Extraction
Jan 29, 2023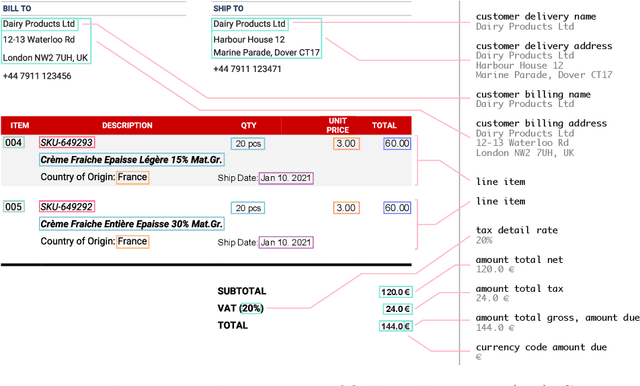
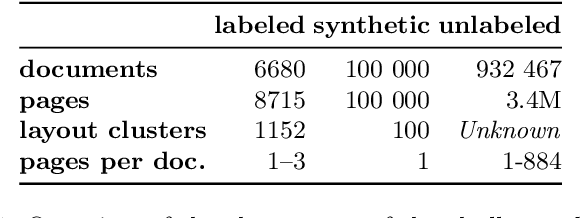


The lack of data for information extraction (IE) from semi-structured business documents is a real problem for the IE community. Publications relying on large-scale datasets use only proprietary, unpublished data due to the sensitive nature of such documents. Publicly available datasets are mostly small and domain-specific. The absence of a large-scale public dataset or benchmark hinders the reproducibility and cross-evaluation of published methods. The DocILE 2023 competition, hosted as a lab at the CLEF 2023 conference and as an ICDAR 2023 competition, will run the first major benchmark for the tasks of Key Information Localization and Extraction (KILE) and Line Item Recognition (LIR) from business documents. With thousands of annotated real documents from open sources, a hundred thousand of generated synthetic documents, and nearly a million unlabeled documents, the DocILE lab comes with the largest publicly available dataset for KILE and LIR. We are looking forward to contributions from the Computer Vision, Natural Language Processing, Information Retrieval, and other communities. The data, baselines, code and up-to-date information about the lab and competition are available at https://docile.rossum.ai/.
eCat: An End-to-End Model for Multi-Speaker TTS & Many-to-Many Fine-Grained Prosody Transfer
Jun 20, 2023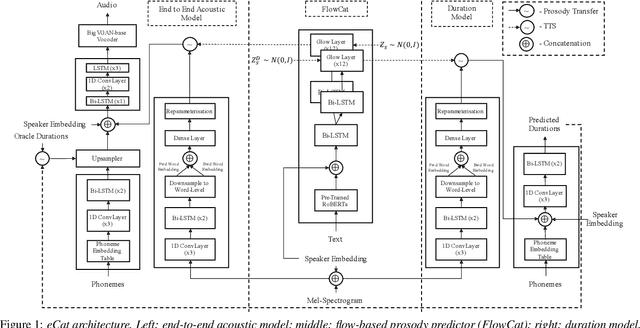
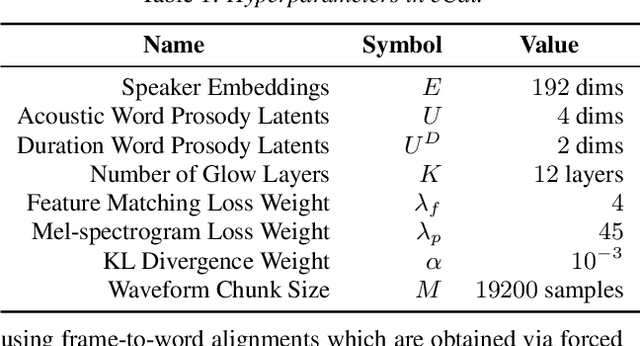
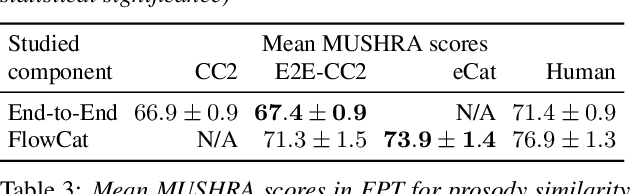
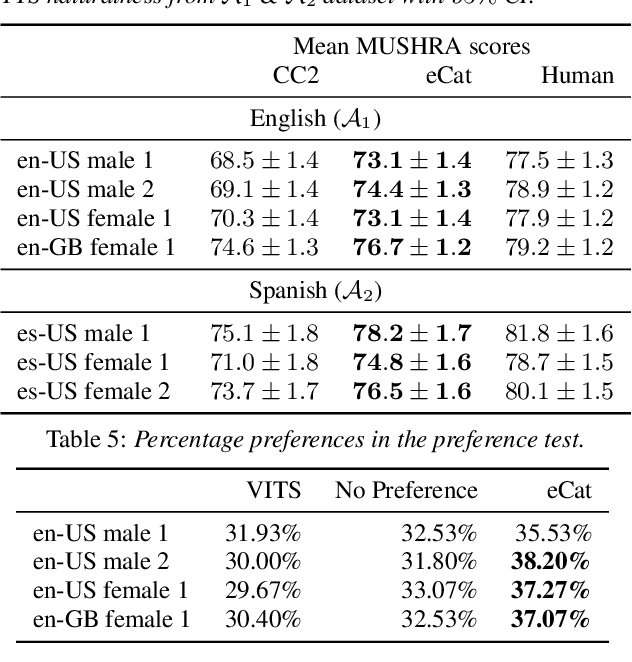
We present eCat, a novel end-to-end multispeaker model capable of: a) generating long-context speech with expressive and contextually appropriate prosody, and b) performing fine-grained prosody transfer between any pair of seen speakers. eCat is trained using a two-stage training approach. In Stage I, the model learns speaker-independent word-level prosody representations in an end-to-end fashion from speech. In Stage II, we learn to predict the prosody representations using the contextual information available in text. We compare eCat to CopyCat2, a model capable of both fine-grained prosody transfer (FPT) and multi-speaker TTS. We show that eCat statistically significantly reduces the gap in naturalness between CopyCat2 and human recordings by an average of 46.7% across 2 languages, 3 locales, and 7 speakers, along with better target-speaker similarity in FPT. We also compare eCat to VITS, and show a statistically significant preference.