 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Online Ad Procurement in Non-stationary Autobidding Worlds
Jul 10, 2023

Today's online advertisers procure digital ad impressions through interacting with autobidding platforms: advertisers convey high level procurement goals via setting levers such as budget, target return-on-investment, max cost per click, etc.. Then ads platforms subsequently procure impressions on advertisers' behalf, and report final procurement conversions (e.g. click) to advertisers. In practice, advertisers may receive minimal information on platforms' procurement details, and procurement outcomes are subject to non-stationary factors like seasonal patterns, occasional system corruptions, and market trends which make it difficult for advertisers to optimize lever decisions effectively. Motivated by this, we present an online learning framework that helps advertisers dynamically optimize ad platform lever decisions while subject to general long-term constraints in a realistic bandit feedback environment with non-stationary procurement outcomes. In particular, we introduce a primal-dual algorithm for online decision making with multi-dimension decision variables, bandit feedback and long-term uncertain constraints. We show that our algorithm achieves low regret in many worlds when procurement outcomes are generated through procedures that are stochastic, adversarial, adversarially corrupted, periodic, and ergodic, respectively, without having to know which procedure is the ground truth. Finally, we emphasize that our proposed algorithm and theoretical results extend beyond the applications of online advertising.
Ethicist: Targeted Training Data Extraction Through Loss Smoothed Soft Prompting and Calibrated Confidence Estimation
Jul 10, 2023
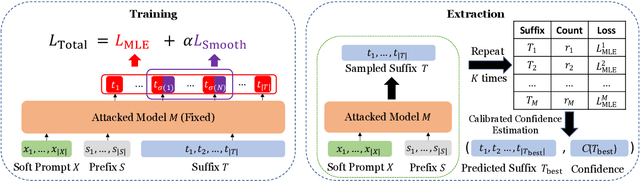
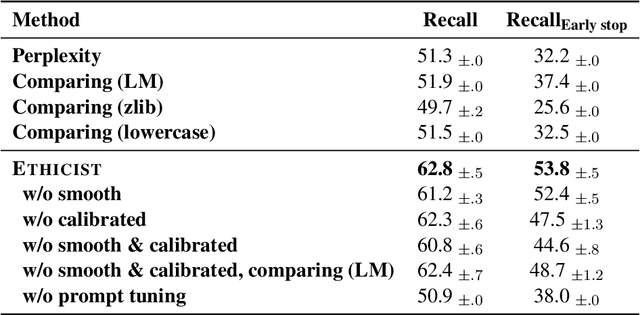
Large pre-trained language models achieve impressive results across many tasks. However, recent works point out that pre-trained language models may memorize a considerable fraction of their training data, leading to the privacy risk of information leakage. In this paper, we propose a method named Ethicist for targeted training data extraction through loss smoothed soft prompting and calibrated confidence estimation, investigating how to recover the suffix in the training data when given a prefix. To elicit memorization in the attacked model, we tune soft prompt embeddings while keeping the model fixed. We further propose a smoothing loss that smooths the loss distribution of the suffix tokens to make it easier to sample the correct suffix. In order to select the most probable suffix from a collection of sampled suffixes and estimate the prediction confidence, we propose a calibrated confidence estimation method, which normalizes the confidence of the generated suffixes with a local estimation. We show that Ethicist significantly improves the extraction performance on a recently proposed public benchmark. We also investigate several factors influencing the data extraction performance, including decoding strategy, model scale, prefix length, and suffix length. Our code is available at https://github.com/thu-coai/Targeted-Data-Extraction.
Counterfactual Explanation for Fairness in Recommendation
Jul 10, 2023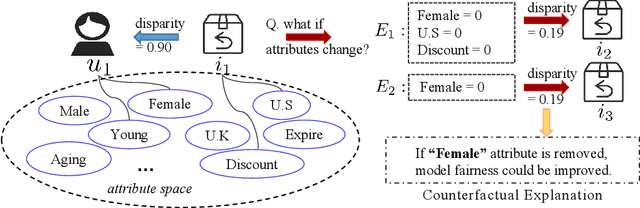
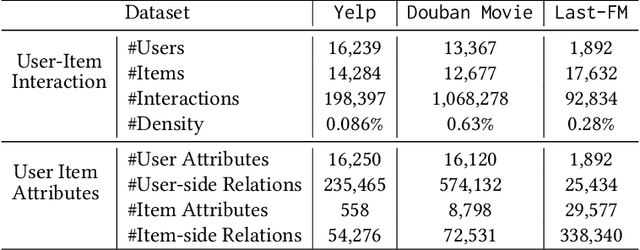
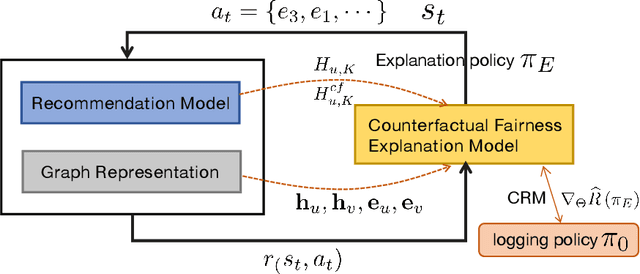
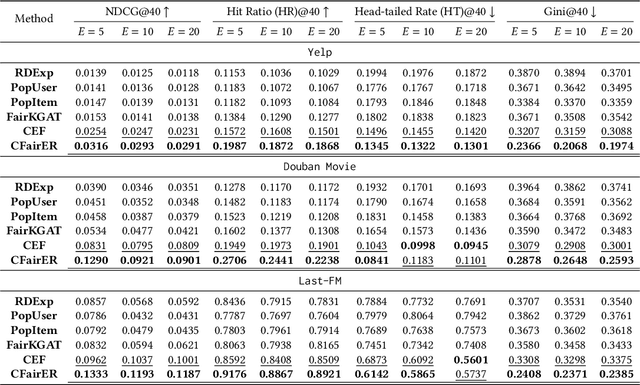
Fairness-aware recommendation eliminates discrimination issues to build trustworthy recommendation systems.Explaining the causes of unfair recommendations is critical, as it promotes fairness diagnostics, and thus secures users' trust in recommendation models. Existing fairness explanation methods suffer high computation burdens due to the large-scale search space and the greedy nature of the explanation search process. Besides, they perform score-based optimizations with continuous values, which are not applicable to discrete attributes such as gender and race. In this work, we adopt the novel paradigm of counterfactual explanation from causal inference to explore how minimal alterations in explanations change model fairness, to abandon the greedy search for explanations. We use real-world attributes from Heterogeneous Information Networks (HINs) to empower counterfactual reasoning on discrete attributes. We propose a novel Counterfactual Explanation for Fairness (CFairER) that generates attribute-level counterfactual explanations from HINs for recommendation fairness. Our CFairER conducts off-policy reinforcement learning to seek high-quality counterfactual explanations, with an attentive action pruning reducing the search space of candidate counterfactuals. The counterfactual explanations help to provide rational and proximate explanations for model fairness, while the attentive action pruning narrows the search space of attributes. Extensive experiments demonstrate our proposed model can generate faithful explanations while maintaining favorable recommendation performance.
Improving Heterogeneous Graph Learning with Weighted Mixed-Curvature Product Manifold
Jul 10, 2023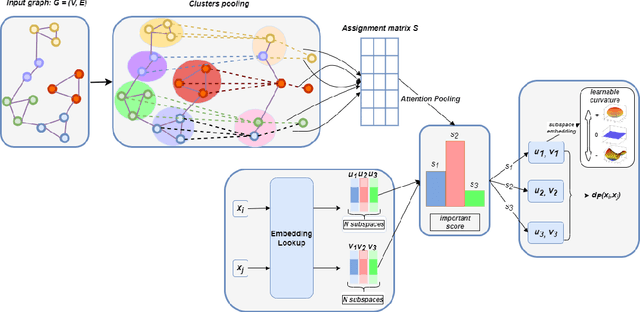
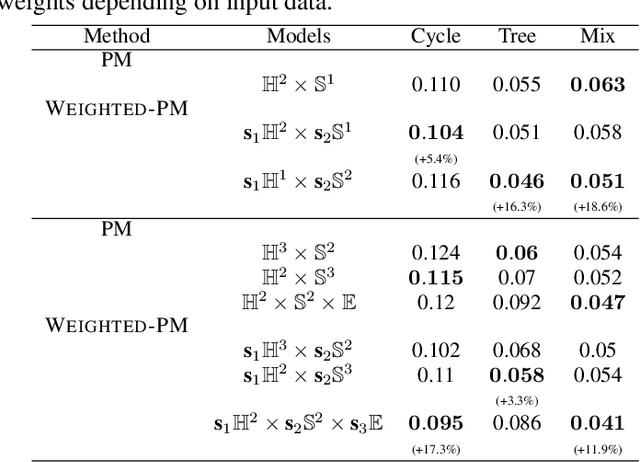
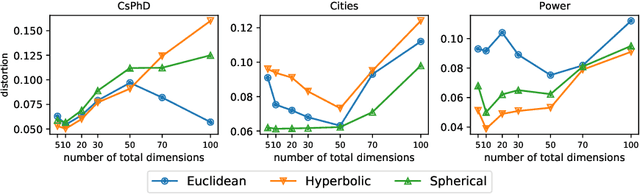
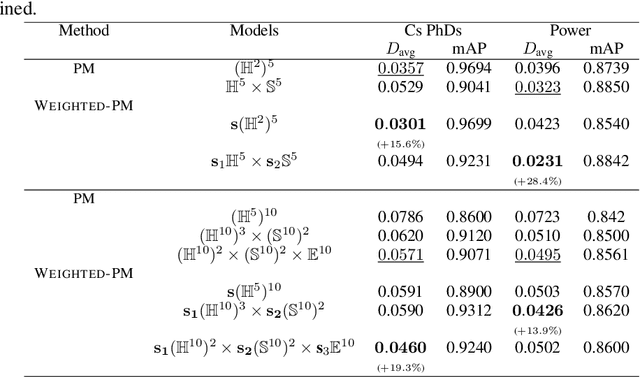
In graph representation learning, it is important that the complex geometric structure of the input graph, e.g. hidden relations among nodes, is well captured in embedding space. However, standard Euclidean embedding spaces have a limited capacity in representing graphs of varying structures. A promising candidate for the faithful embedding of data with varying structure is product manifolds of component spaces of different geometries (spherical, hyperbolic, or euclidean). In this paper, we take a closer look at the structure of product manifold embedding spaces and argue that each component space in a product contributes differently to expressing structures in the input graph, hence should be weighted accordingly. This is different from previous works which consider the roles of different components equally. We then propose WEIGHTED-PM, a data-driven method for learning embedding of heterogeneous graphs in weighted product manifolds. Our method utilizes the topological information of the input graph to automatically determine the weight of each component in product spaces. Extensive experiments on synthetic and real-world graph datasets demonstrate that WEIGHTED-PM is capable of learning better graph representations with lower geometric distortion from input data, and performs better on multiple downstream tasks, such as word similarity learning, top-$k$ recommendation, and knowledge graph embedding.
Where to Drop Sensors from Aerial Robots to Monitor a Surface-Level Phenomenon?
Jul 10, 2023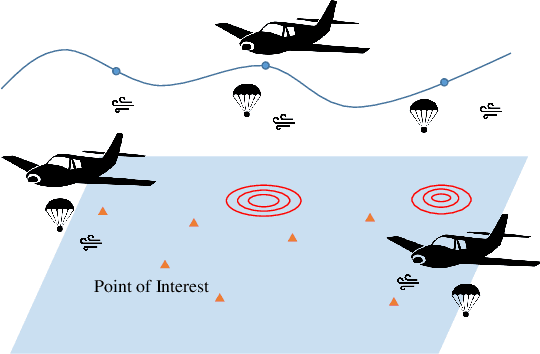
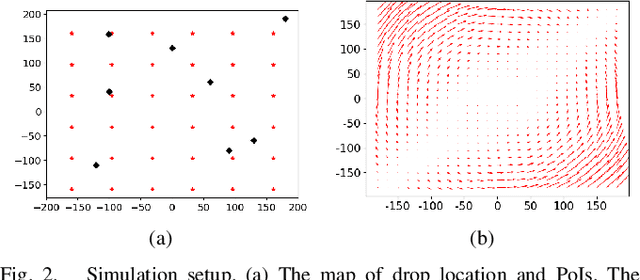
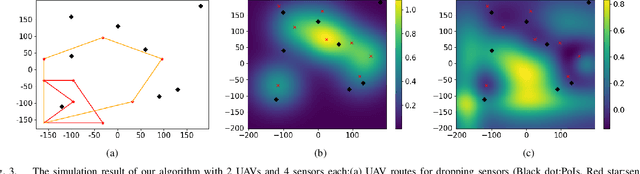
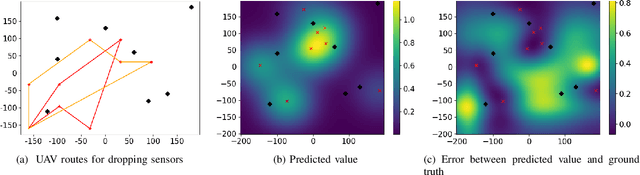
We consider the problem of routing a team of energy-constrained Unmanned Aerial Vehicles (UAVs) to drop unmovable sensors for monitoring a task area in the presence of stochastic wind disturbances. In prior work on mobile sensor routing problems, sensors and their carrier are one integrated platform, and sensors are assumed to be able to take measurements at exactly desired locations. By contrast, airdropping the sensors onto the ground can introduce stochasticity in the landing locations of the sensors. We focus on addressing this stochasticity in sensor locations from the path-planning perspective. Specifically, we formulate the problem (Multi-UAV Sensor Drop) as a variant of the Submodular Team Orienteering Problem with one additional constraint on the number of sensors on each UAV. The objective is to maximize the Mutual Information between the phenomenon at Points of Interest (PoIs) and the measurements that sensors will take at stochastic locations. We show that such an objective is computationally expensive to evaluate. To tackle this challenge, we propose a surrogate objective with a closed-form expression based on the expected mean and expected covariance of the Gaussian Process. We propose a heuristic algorithm to solve the optimization problem with the surrogate objective. The formulation and the algorithms are validated through extensive simulations.
Automotive Radar Mutual Interference Mitigation Based on Hough Transform in Time-Frequency Domain
Jul 10, 2023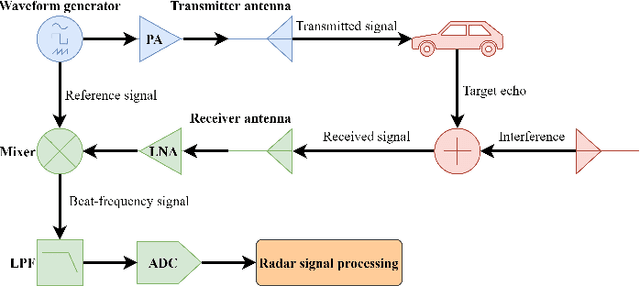

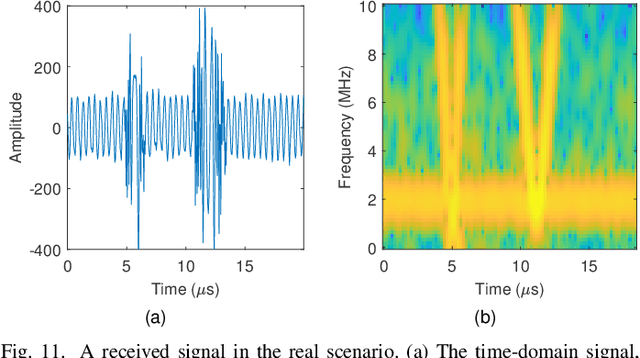
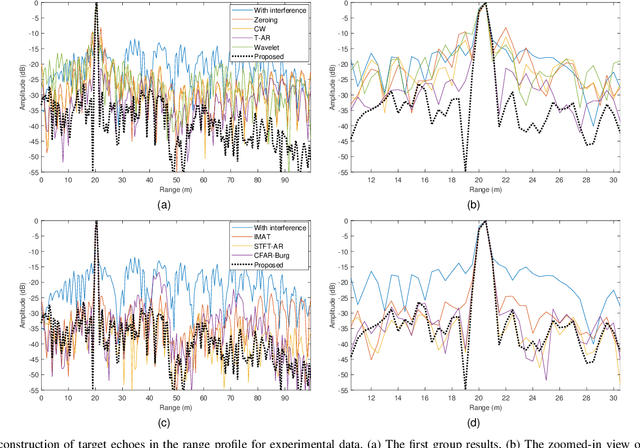
With the development of autonomous driving technology, automotive radar has received unprecedented attention due to its day-and-night and all-weather working capability. It is worthwhile to note that more and more vehicles are equipped with automotive radars, resulting in mutual interference between radars. The interference reduces radar target detection performance, making perception information unreliable. In this paper, a novel interference mitigation method based on power-weighted Hough transform is proposed for solving the radar mutual interference and improving the safety of autonomous driving systems. Firstly, the frequency modulation characteristics of interference signals and target echo signals are analyzed, and differences between the two signals are introduced. Secondly, based on the straight line detection technique, the power of the mutual interference signal in time-frequency domain is accumulated, and the accurate position of the interference is located. Finally, the target echo is recovered by autoregressive model. Compared with existing state-of-the-art methods, the proposed method has the ability to retain more useful signals after the interference mitigation, and achieve better interference detection robustness under low signal-to-noise ratio conditions. Simulation experiments and real scenario experiments verify the effectiveness of the proposed method and show its superiority.
Your spouse needs professional help: Determining the Contextual Appropriateness of Messages through Modeling Social Relationships
Jul 06, 2023
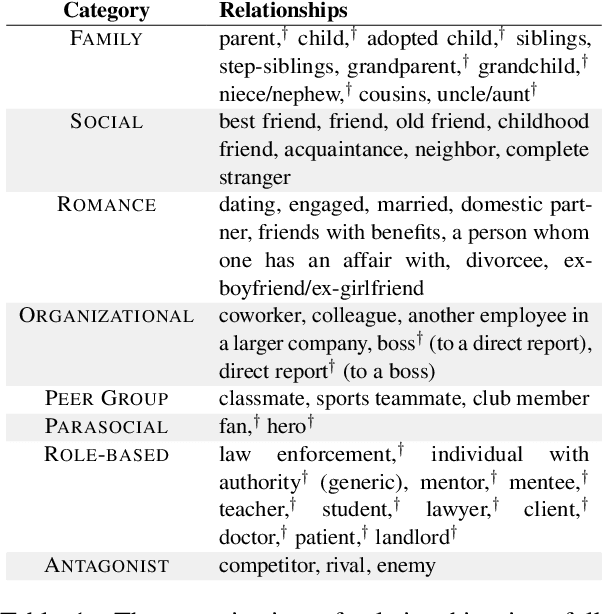
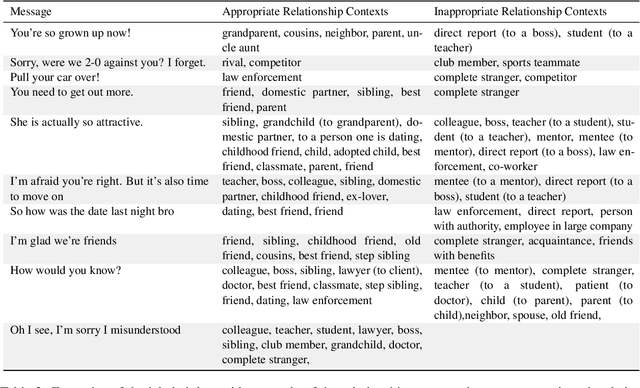
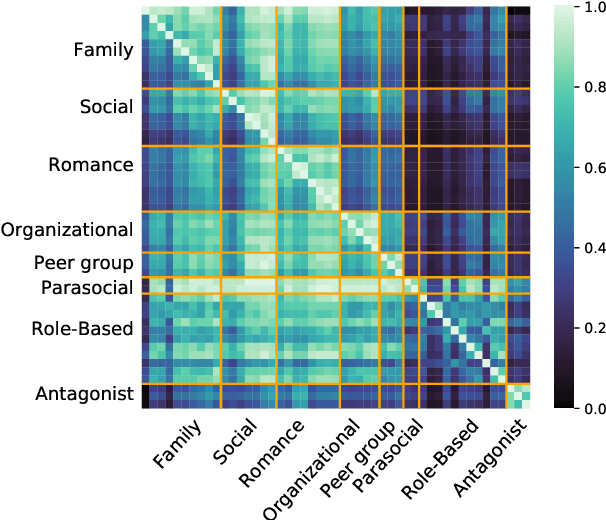
Understanding interpersonal communication requires, in part, understanding the social context and norms in which a message is said. However, current methods for identifying offensive content in such communication largely operate independent of context, with only a few approaches considering community norms or prior conversation as context. Here, we introduce a new approach to identifying inappropriate communication by explicitly modeling the social relationship between the individuals. We introduce a new dataset of contextually-situated judgments of appropriateness and show that large language models can readily incorporate relationship information to accurately identify appropriateness in a given context. Using data from online conversations and movie dialogues, we provide insight into how the relationships themselves function as implicit norms and quantify the degree to which context-sensitivity is needed in different conversation settings. Further, we also demonstrate that contextual-appropriateness judgments are predictive of other social factors expressed in language such as condescension and politeness.
Enhanced Multimodal Representation Learning with Cross-modal KD
Jun 13, 2023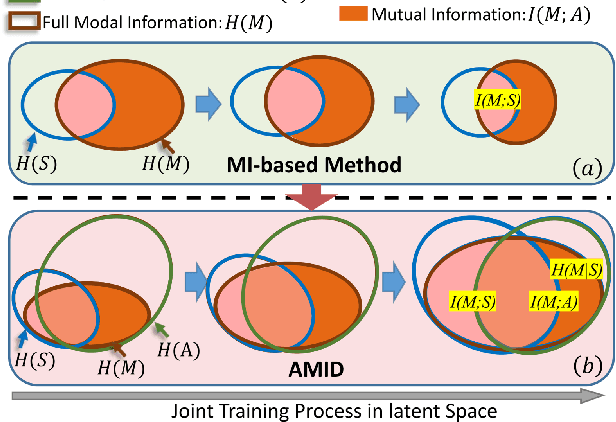
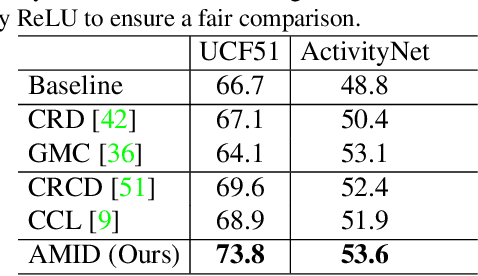

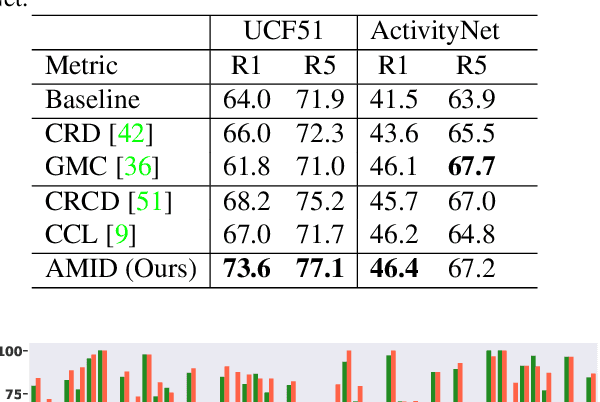
This paper explores the tasks of leveraging auxiliary modalities which are only available at training to enhance multimodal representation learning through cross-modal Knowledge Distillation (KD). The widely adopted mutual information maximization-based objective leads to a short-cut solution of the weak teacher, i.e., achieving the maximum mutual information by simply making the teacher model as weak as the student model. To prevent such a weak solution, we introduce an additional objective term, i.e., the mutual information between the teacher and the auxiliary modality model. Besides, to narrow down the information gap between the student and teacher, we further propose to minimize the conditional entropy of the teacher given the student. Novel training schemes based on contrastive learning and adversarial learning are designed to optimize the mutual information and the conditional entropy, respectively. Experimental results on three popular multimodal benchmark datasets have shown that the proposed method outperforms a range of state-of-the-art approaches for video recognition, video retrieval and emotion classification.
Improving End-to-End Neural Diarization Using Conversational Summary Representations
Jun 24, 2023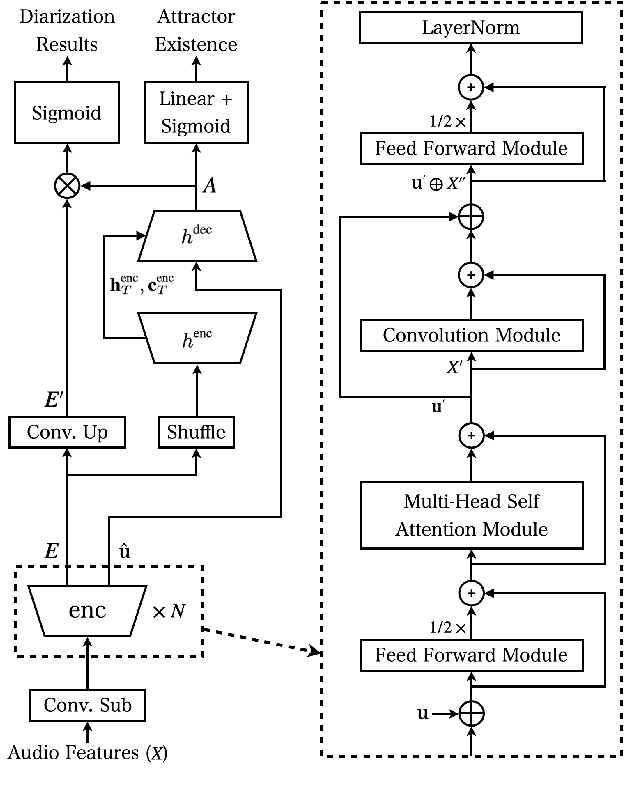
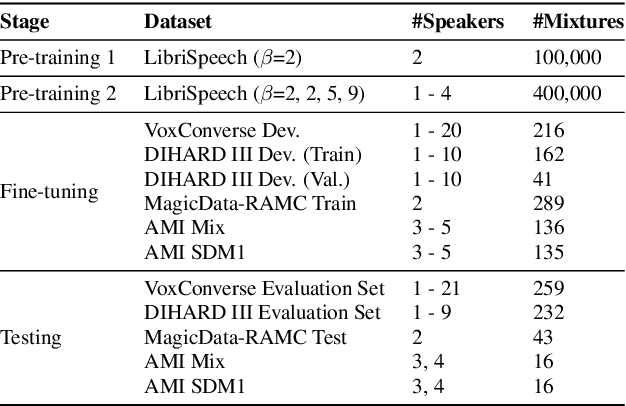
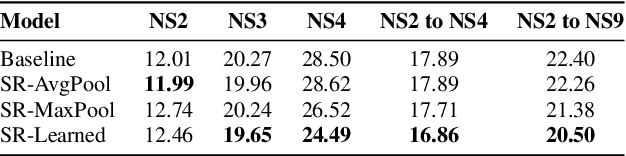
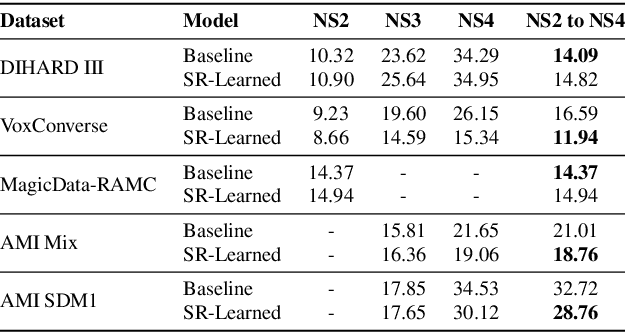
Speaker diarization is a task concerned with partitioning an audio recording by speaker identity. End-to-end neural diarization with encoder-decoder based attractor calculation (EEND-EDA) aims to solve this problem by directly outputting diarization results for a flexible number of speakers. Currently, the EDA module responsible for generating speaker-wise attractors is conditioned on zero vectors providing no relevant information to the network. In this work, we extend EEND-EDA by replacing the input zero vectors to the decoder with learned conversational summary representations. The updated EDA module sequentially generates speaker-wise attractors based on utterance-level information. We propose three methods to initialize the summary vector and conduct an investigation into varying input recording lengths. On a range of publicly available test sets, our model achieves an absolute DER performance improvement of 1.90 % when compared to the baseline.
Digital Health Discussion Through Articles Published Until the Year 2021: A Digital Topic Modeling Approach
Jul 14, 2023


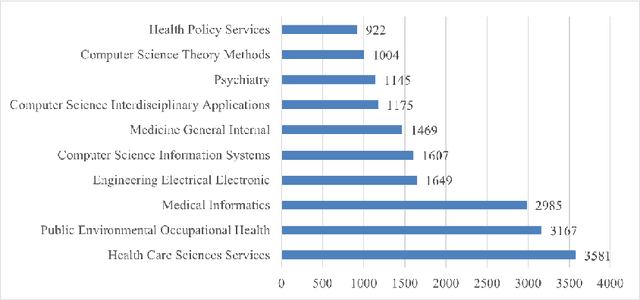
The digital health industry has grown in popularity since the 2010s, but there has been limited analysis of the topics discussed in the field across academic disciplines. This study aims to analyze the research trends of digital health-related articles published on the Web of Science until 2021, in order to understand the concentration, scope, and characteristics of the research. 15,950 digital health-related papers from the top 10 academic fields were analyzed using the Web of Science. The papers were grouped into three domains: public health, medicine, and electrical engineering and computer science (EECS). Two time periods (2012-2016 and 2017-2021) were compared using Latent Dirichlet Allocation (LDA) for topic modeling. The number of topics was determined based on coherence score, and topic compositions were compared using a homogeneity test. The number of optimal topics varied across domains and time periods. For public health, the first and second halves had 13 and 19 topics, respectively. Medicine had 14 and 25 topics, and EECS had 7 and 21 topics. Text analysis revealed shared topics among the domains, but with variations in composition. The homogeneity test confirmed significant differences between the groups (p<2.2e-16). Six dominant themes emerged, including journal article methodology, information technology, medical issues, population demographics, social phenomena, and healthcare. Digital health research is expanding and evolving, particularly in relation to Covid-19, where topics such as depression and mental disorders, education, and physical activity have gained prominence. There was no bias in topic composition among the three domains, but other fields like kinesiology or psychology could contribute to future digital health research. Exploring expanded topics that reflect people's needs for digital health over time will be crucial.