 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Source-Free Domain Adaptation with Temporal Imputation for Time Series Data
Jul 14, 2023
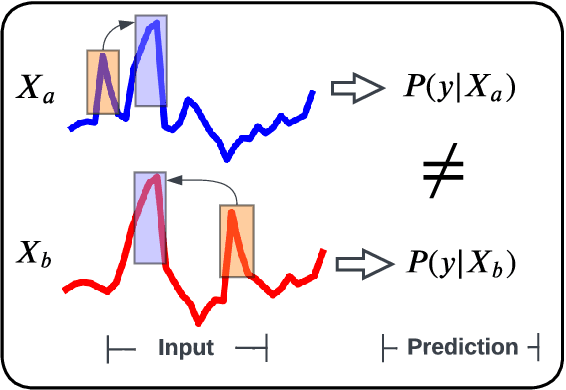
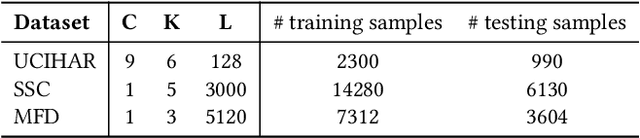
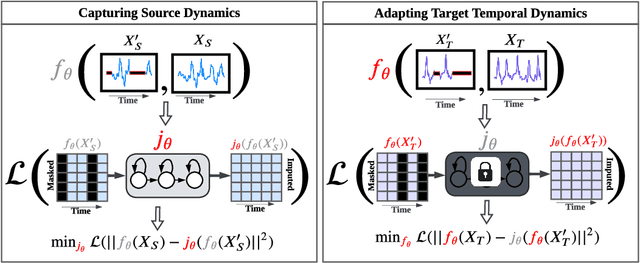
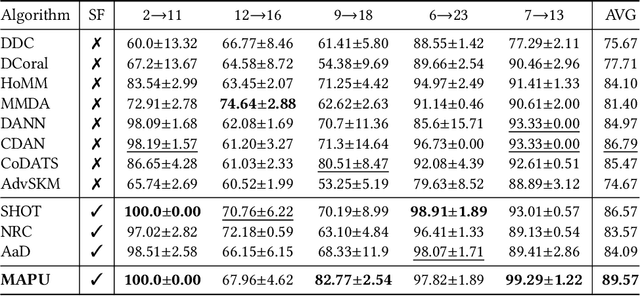
Source-free domain adaptation (SFDA) aims to adapt a pretrained model from a labeled source domain to an unlabeled target domain without access to the source domain data, preserving source domain privacy. Despite its prevalence in visual applications, SFDA is largely unexplored in time series applications. The existing SFDA methods that are mainly designed for visual applications may fail to handle the temporal dynamics in time series, leading to impaired adaptation performance. To address this challenge, this paper presents a simple yet effective approach for source-free domain adaptation on time series data, namely MAsk and imPUte (MAPU). First, to capture temporal information of the source domain, our method performs random masking on the time series signals while leveraging a novel temporal imputer to recover the original signal from a masked version in the embedding space. Second, in the adaptation step, the imputer network is leveraged to guide the target model to produce target features that are temporally consistent with the source features. To this end, our MAPU can explicitly account for temporal dependency during the adaptation while avoiding the imputation in the noisy input space. Our method is the first to handle temporal consistency in SFDA for time series data and can be seamlessly equipped with other existing SFDA methods. Extensive experiments conducted on three real-world time series datasets demonstrate that our MAPU achieves significant performance gain over existing methods. Our code is available at \url{https://github.com/mohamedr002/MAPU_SFDA_TS}.
Learn from Incomplete Tactile Data: Tactile Representation Learning with Masked Autoencoders
Jul 14, 2023
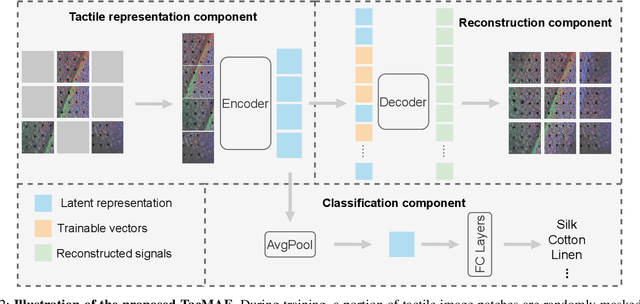

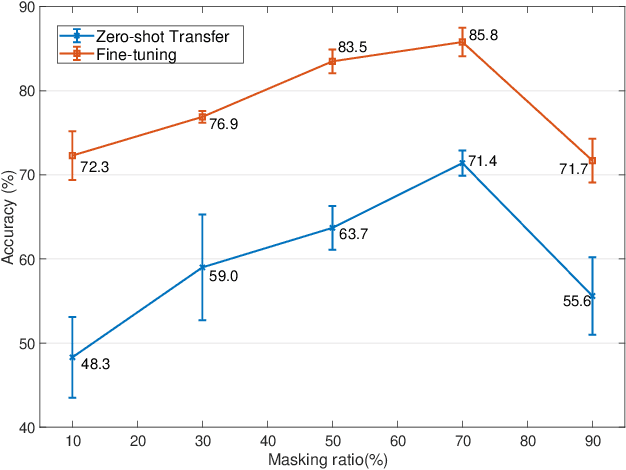
The missing signal caused by the objects being occluded or an unstable sensor is a common challenge during data collection. Such missing signals will adversely affect the results obtained from the data, and this issue is observed more frequently in robotic tactile perception. In tactile perception, due to the limited working space and the dynamic environment, the contact between the tactile sensor and the object is frequently insufficient and unstable, which causes the partial loss of signals, thus leading to incomplete tactile data. The tactile data will therefore contain fewer tactile cues with low information density. In this paper, we propose a tactile representation learning method, named TacMAE, based on Masked Autoencoder to address the problem of incomplete tactile data in tactile perception. In our framework, a portion of the tactile image is masked out to simulate the missing contact region. By reconstructing the missing signals in the tactile image, the trained model can achieve a high-level understanding of surface geometry and tactile properties from limited tactile cues. The experimental results of tactile texture recognition show that our proposed TacMAE can achieve a high recognition accuracy of 71.4% in the zero-shot transfer and 85.8% after fine-tuning, which are 15.2% and 8.2% higher than the results without using masked modeling. The extensive experiments on YCB objects demonstrate the knowledge transferability of our proposed method and the potential to improve efficiency in tactile exploration.
On Interpolating Experts and Multi-Armed Bandits
Jul 14, 2023Learning with expert advice and multi-armed bandit are two classic online decision problems which differ on how the information is observed in each round of the game. We study a family of problems interpolating the two. For a vector $\mathbf{m}=(m_1,\dots,m_K)\in \mathbb{N}^K$, an instance of $\mathbf{m}$-MAB indicates that the arms are partitioned into $K$ groups and the $i$-th group contains $m_i$ arms. Once an arm is pulled, the losses of all arms in the same group are observed. We prove tight minimax regret bounds for $\mathbf{m}$-MAB and design an optimal PAC algorithm for its pure exploration version, $\mathbf{m}$-BAI, where the goal is to identify the arm with minimum loss with as few rounds as possible. We show that the minimax regret of $\mathbf{m}$-MAB is $\Theta\left(\sqrt{T\sum_{k=1}^K\log (m_k+1)}\right)$ and the minimum number of pulls for an $(\epsilon,0.05)$-PAC algorithm of $\mathbf{m}$-BAI is $\Theta\left(\frac{1}{\epsilon^2}\cdot \sum_{k=1}^K\log (m_k+1)\right)$. Both our upper bounds and lower bounds for $\mathbf{m}$-MAB can be extended to a more general setting, namely the bandit with graph feedback, in terms of the clique cover and related graph parameters. As consequences, we obtained tight minimax regret bounds for several families of feedback graphs.
Global path preference and local response: A reward decomposition approach for network path choice analysis in the presence of locally perceived attributes
Jul 14, 2023This study performs an attribute-level analysis of the global and local path preferences of network travelers. To this end, a reward decomposition approach is proposed and integrated into a link-based recursive (Markovian) path choice model. The approach decomposes the instantaneous reward function associated with each state-action pair into the global utility, a function of attributes globally perceived from anywhere in the network, and the local utility, a function of attributes that are only locally perceived from the current state. Only the global utility then enters the value function of each state, representing the future expected utility toward the destination. This global-local path choice model with decomposed reward functions allows us to analyze to what extent and which attributes affect the global and local path choices of agents. Moreover, unlike most adaptive path choice models, the proposed model can be estimated based on revealed path observations (without the information of plans) and as efficiently as deterministic recursive path choice models. The model was applied to the real pedestrian path choice observations in an urban street network where the green view index was extracted as a visual street quality from Google Street View images. The result revealed that pedestrians locally perceive and react to the visual street quality, rather than they have the pre-trip global perception on it. Furthermore, the simulation results using the estimated models suggested the importance of location selection of interventions when policy-related attributes are only locally perceived by travelers.
Valid Information Guidance Network for Compressed Video Quality Enhancement
Feb 28, 2023

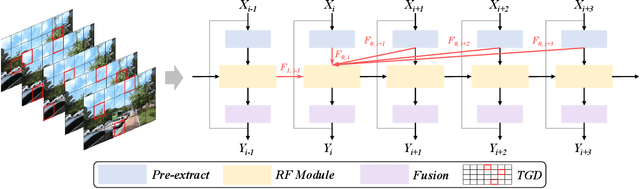
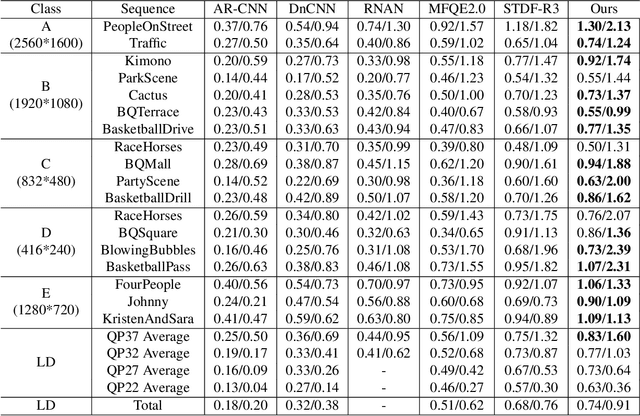
In recent years deep learning methods have shown great superiority in compressed video quality enhancement tasks. Existing methods generally take the raw video as the ground truth and extract practical information from consecutive frames containing various artifacts. However, they do not fully exploit the valid information of compressed and raw videos to guide the quality enhancement for compressed videos. In this paper, we propose a unique Valid Information Guidance scheme (VIG) to enhance the quality of compressed videos by mining valid information from both compressed videos and raw videos. Specifically, we propose an efficient framework, Compressed Redundancy Filtering (CRF) network, to balance speed and enhancement. After removing the redundancy by filtering the information, CRF can use the valid information of the compressed video to reconstruct the texture. Furthermore, we propose a progressive Truth Guidance Distillation (TGD) strategy, which does not need to design additional teacher models and distillation loss functions. By only using the ground truth as input to guide the model to aggregate the correct spatio-temporal correspondence across the raw frames, TGD can significantly improve the enhancement effect without increasing the extra training cost. Extensive experiments show that our method achieves the state-of-the-art performance of compressed video quality enhancement in terms of accuracy and efficiency.
GraSS: Contrastive Learning with Gradient Guided Sampling Strategy for Remote Sensing Image Semantic Segmentation
Jun 28, 2023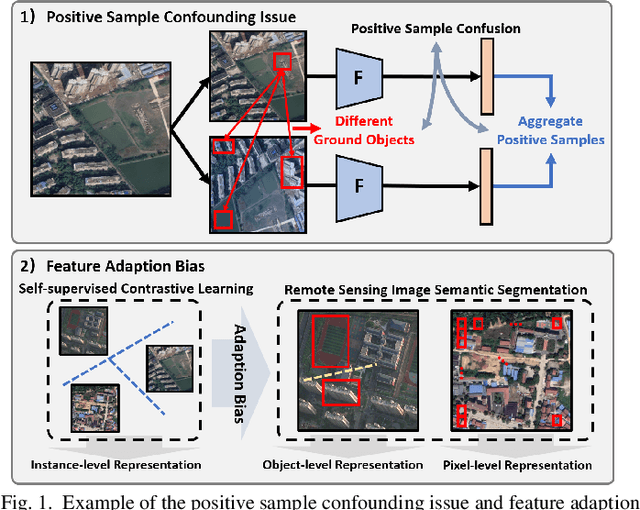
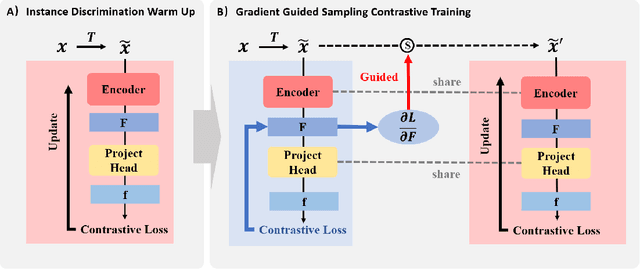
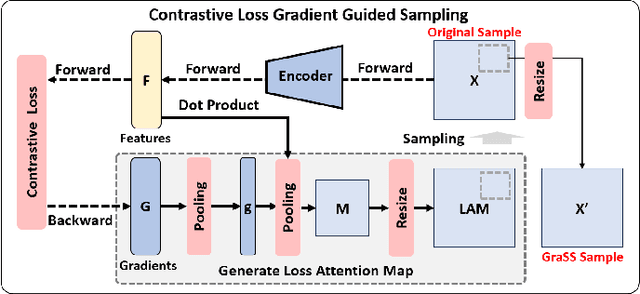
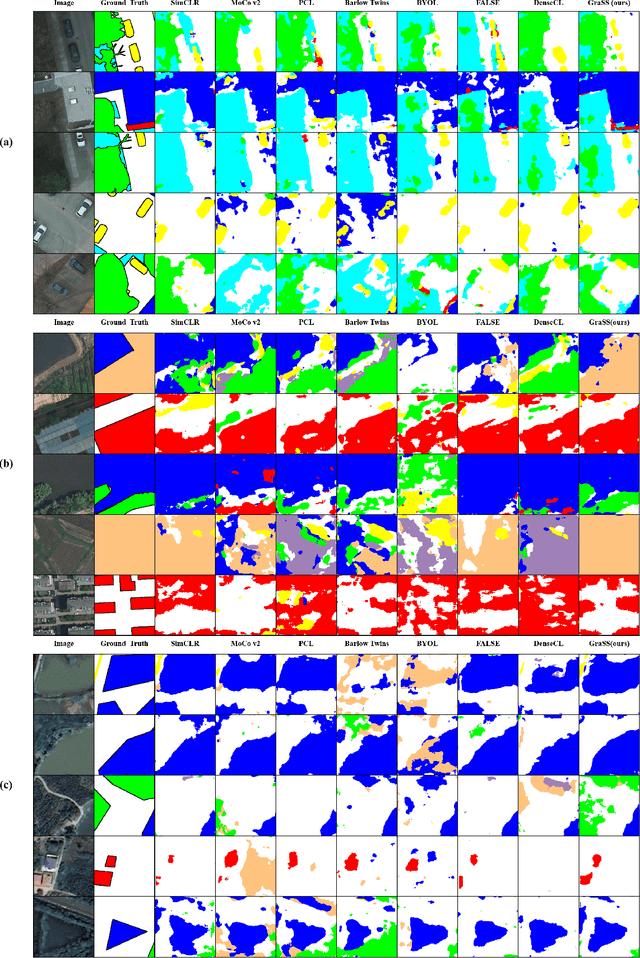
Self-supervised contrastive learning (SSCL) has achieved significant milestones in remote sensing image (RSI) understanding. Its essence lies in designing an unsupervised instance discrimination pretext task to extract image features from a large number of unlabeled images that are beneficial for downstream tasks. However, existing instance discrimination based SSCL suffer from two limitations when applied to the RSI semantic segmentation task: 1) Positive sample confounding issue; 2) Feature adaptation bias. It introduces a feature adaptation bias when applied to semantic segmentation tasks that require pixel-level or object-level features. In this study, We observed that the discrimination information can be mapped to specific regions in RSI through the gradient of unsupervised contrastive loss, these specific regions tend to contain singular ground objects. Based on this, we propose contrastive learning with Gradient guided Sampling Strategy (GraSS) for RSI semantic segmentation. GraSS consists of two stages: Instance Discrimination warm-up (ID warm-up) and Gradient guided Sampling contrastive training (GS training). The ID warm-up aims to provide initial discrimination information to the contrastive loss gradients. The GS training stage aims to utilize the discrimination information contained in the contrastive loss gradients and adaptively select regions in RSI patches that contain more singular ground objects, in order to construct new positive and negative samples. Experimental results on three open datasets demonstrate that GraSS effectively enhances the performance of SSCL in high-resolution RSI semantic segmentation. Compared to seven baseline methods from five different types of SSCL, GraSS achieves an average improvement of 1.57\% and a maximum improvement of 3.58\% in terms of mean intersection over the union. The source code is available at https://github.com/GeoX-Lab/GraSS
SimpleMTOD: A Simple Language Model for Multimodal Task-Oriented Dialogue with Symbolic Scene Representation
Jul 10, 2023
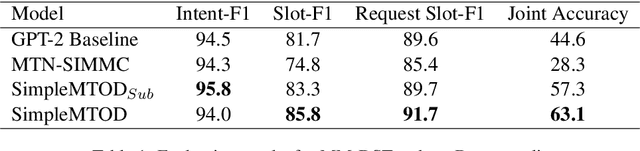
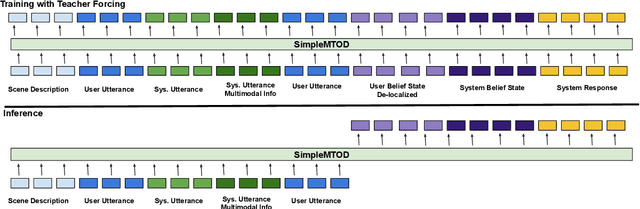

SimpleMTOD is a simple language model which recasts several sub-tasks in multimodal task-oriented dialogues as sequence prediction tasks. SimpleMTOD is built on a large-scale transformer-based auto-regressive architecture, which has already proven to be successful in uni-modal task-oriented dialogues, and effectively leverages transfer learning from pre-trained GPT-2. In-order to capture the semantics of visual scenes, we introduce both local and de-localized tokens for objects within a scene. De-localized tokens represent the type of an object rather than the specific object itself and so possess a consistent meaning across the dataset. SimpleMTOD achieves a state-of-the-art BLEU score (0.327) in the Response Generation sub-task of the SIMMC 2.0 test-std dataset while performing on par in other multimodal sub-tasks: Disambiguation, Coreference Resolution, and Dialog State Tracking. This is despite taking a minimalist approach for extracting visual (and non-visual) information. In addition the model does not rely on task-specific architectural changes such as classification heads.
Fairness and Diversity in Recommender Systems: A Survey
Jul 10, 2023Recommender systems are effective tools for mitigating information overload and have seen extensive applications across various domains. However, the single focus on utility goals proves to be inadequate in addressing real-world concerns, leading to increasing attention to fairness-aware and diversity-aware recommender systems. While most existing studies explore fairness and diversity independently, we identify strong connections between these two domains. In this survey, we first discuss each of them individually and then dive into their connections. Additionally, motivated by the concepts of user-level and item-level fairness, we broaden the understanding of diversity to encompass not only the item level but also the user level. With this expanded perspective on user and item-level diversity, we re-interpret fairness studies from the viewpoint of diversity. This fresh perspective enhances our understanding of fairness-related work and paves the way for potential future research directions. Papers discussed in this survey along with public code links are available at https://github.com/YuyingZhao/Awesome-Fairness-and-Diversity-Papers-in-Recommender-Systems .
Real-time Percussive Technique Recognition and Embedding Learning for the Acoustic Guitar
Jul 13, 2023Real-time music information retrieval (RT-MIR) has much potential to augment the capabilities of traditional acoustic instruments. We develop RT-MIR techniques aimed at augmenting percussive fingerstyle, which blends acoustic guitar playing with guitar body percussion. We formulate several design objectives for RT-MIR systems for augmented instrument performance: (i) causal constraint, (ii) perceptually negligible action-to-sound latency, (iii) control intimacy support, (iv) synthesis control support. We present and evaluate real-time guitar body percussion recognition and embedding learning techniques based on convolutional neural networks (CNNs) and CNNs jointly trained with variational autoencoders (VAEs). We introduce a taxonomy of guitar body percussion based on hand part and location. We follow a cross-dataset evaluation approach by collecting three datasets labelled according to the taxonomy. The embedding quality of the models is assessed using KL-Divergence across distributions corresponding to different taxonomic classes. Results indicate that the networks are strong classifiers especially in a simplified 2-class recognition task, and the VAEs yield improved class separation compared to CNNs as evidenced by increased KL-Divergence across distributions. We argue that the VAE embedding quality could support control intimacy and rich interaction when the latent space's parameters are used to control an external synthesis engine. Further design challenges around generalisation to different datasets have been identified.
An Improved Metric of Informational Masking for Perceptual Audio Quality Measurement
Jul 13, 2023Perceptual audio quality measurement systems algorithmically analyze the output of audio processing systems to estimate possible perceived quality degradation using perceptual models of human audition. In this manner, they save the time and resources associated with the design and execution of listening tests (LTs). Models of disturbance audibility predicting peripheral auditory masking in quality measurement systems have considerably increased subjective quality prediction performance of signals processed by perceptual audio codecs. Additionally, cognitive effects have also been known to regulate perceived distortion severity by influencing their salience. However, the performance gains due to cognitive effect models in quality measurement systems were inconsistent so far, particularly for music signals. Firstly, this paper presents an improved model of informational masking (IM) -- an important cognitive effect in quality perception -- that considers disturbance information complexity around the masking threshold. Secondly, we incorporate the proposed IM metric into a quality measurement systems using a novel interaction analysis procedure between cognitive effects and distortion metrics. The procedure establishes interactions between cognitive effects and distortion metrics using LT data. The proposed IM metric is shown to outperform previously proposed IM metrics in a validation task against subjective quality scores from large and diverse LT databases. Particularly, the proposed system showed an increased quality prediction of music signals coded with bandwidth extension techniques, where other models frequently fail.