 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Implementing Edge Based Object Detection For Microplastic Debris
Jul 30, 2023

Plastic has imbibed itself as an indispensable part of our day to day activities, becoming a source of problems due to its non-biodegradable nature and cheaper production prices. With these problems, comes the challenge of mitigating and responding to the aftereffects of disposal or the lack of proper disposal which leads to waste concentrating in locations and disturbing ecosystems for both plants and animals. As plastic debris levels continue to rise with the accumulation of waste in garbage patches in landfills and more hazardously in natural water bodies, swift action is necessary to plug or cease this flow. While manual sorting operations and detection can offer a solution, they can be augmented using highly advanced computer imagery linked with robotic appendages for removing wastes. The primary application of focus in this report are the much-discussed Computer Vision and Open Vision which have gained novelty for their light dependence on internet and ability to relay information in remote areas. These applications can be applied to the creation of edge-based mobility devices that can as a counter to the growing problem of plastic debris in oceans and rivers, demanding little connectivity and still offering the same results with reasonably timed maintenance. The principal findings of this project cover the various methods that were tested and deployed to detect waste in images, as well as comparing them against different waste types. The project has been able to produce workable models that can perform on time detection of sampled images using an augmented CNN approach. Latter portions of the project have also achieved a better interpretation of the necessary preprocessing steps required to arrive at the best accuracies, including the best hardware for expanding waste detection studies to larger environments.
Semantic-Aware Dual Contrastive Learning for Multi-label Image Classification
Jul 27, 2023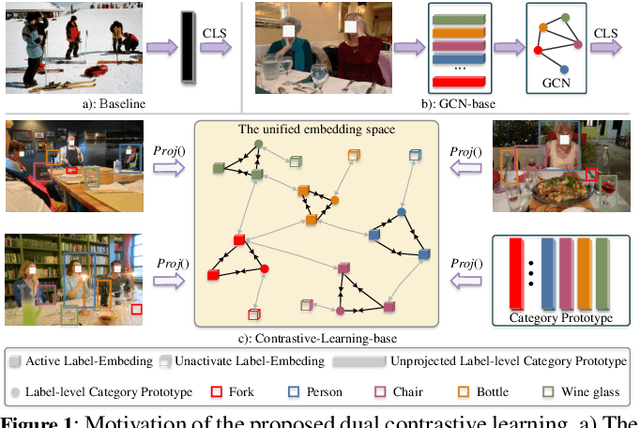
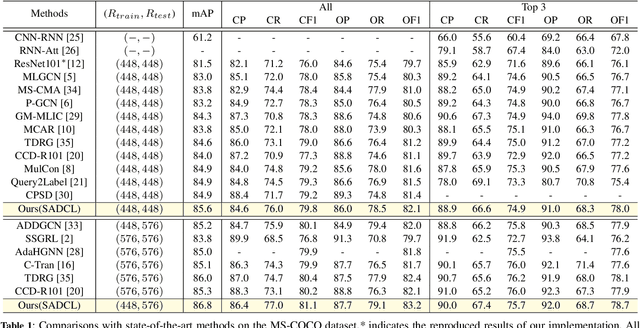
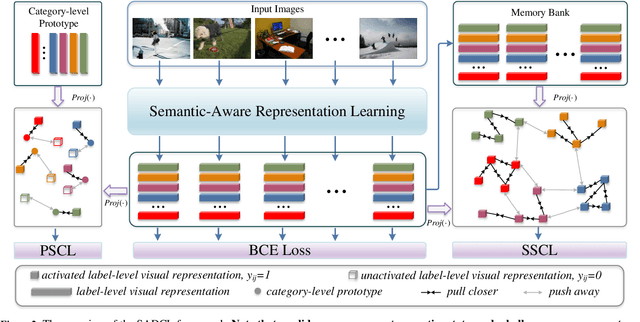
Extracting image semantics effectively and assigning corresponding labels to multiple objects or attributes for natural images is challenging due to the complex scene contents and confusing label dependencies. Recent works have focused on modeling label relationships with graph and understanding object regions using class activation maps (CAM). However, these methods ignore the complex intra- and inter-category relationships among specific semantic features, and CAM is prone to generate noisy information. To this end, we propose a novel semantic-aware dual contrastive learning framework that incorporates sample-to-sample contrastive learning (SSCL) as well as prototype-to-sample contrastive learning (PSCL). Specifically, we leverage semantic-aware representation learning to extract category-related local discriminative features and construct category prototypes. Then based on SSCL, label-level visual representations of the same category are aggregated together, and features belonging to distinct categories are separated. Meanwhile, we construct a novel PSCL module to narrow the distance between positive samples and category prototypes and push negative samples away from the corresponding category prototypes. Finally, the discriminative label-level features related to the image content are accurately captured by the joint training of the above three parts. Experiments on five challenging large-scale public datasets demonstrate that our proposed method is effective and outperforms the state-of-the-art methods. Code and supplementary materials are released on https://github.com/yu-gi-oh-leilei/SADCL.
How to Scale Your EMA
Jul 27, 2023
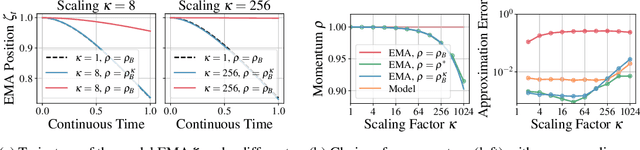
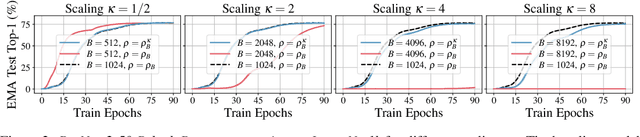
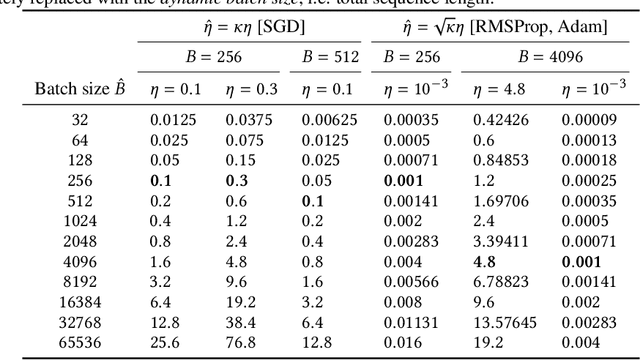
Preserving training dynamics across batch sizes is an important tool for practical machine learning as it enables the trade-off between batch size and wall-clock time. This trade-off is typically enabled by a scaling rule, for example, in stochastic gradient descent, one should scale the learning rate linearly with the batch size. Another important tool for practical machine learning is the model Exponential Moving Average (EMA), which is a model copy that does not receive gradient information, but instead follows its target model with some momentum. This model EMA can improve the robustness and generalization properties of supervised learning, stabilize pseudo-labeling, and provide a learning signal for Self-Supervised Learning (SSL). Prior works have treated the model EMA separately from optimization, leading to different training dynamics across batch sizes and lower model performance. In this work, we provide a scaling rule for optimization in the presence of model EMAs and demonstrate its validity across a range of architectures, optimizers, and data modalities. We also show the rule's validity where the model EMA contributes to the optimization of the target model, enabling us to train EMA-based pseudo-labeling and SSL methods at small and large batch sizes. For SSL, we enable training of BYOL up to batch size 24,576 without sacrificing performance, optimally a 6$\times$ wall-clock time reduction.
Right for the Wrong Reason: Can Interpretable ML Techniques Detect Spurious Correlations?
Jul 23, 2023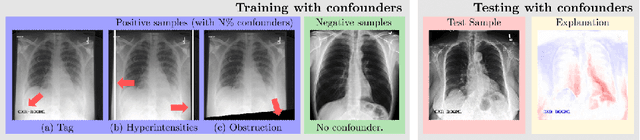
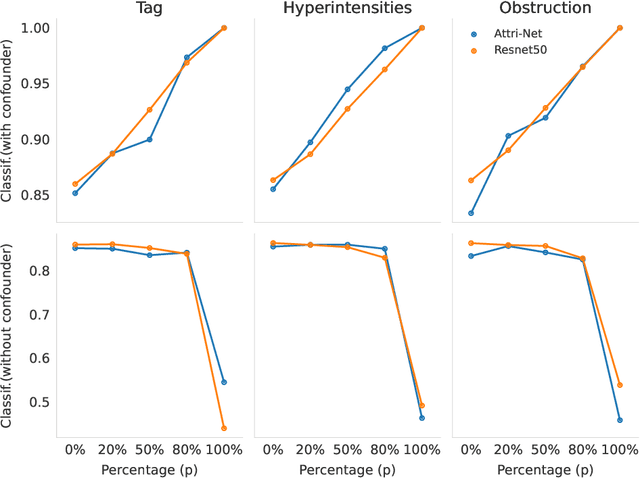
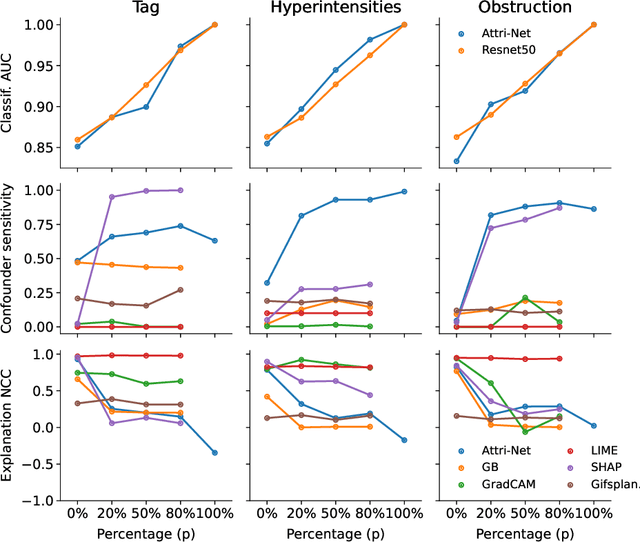
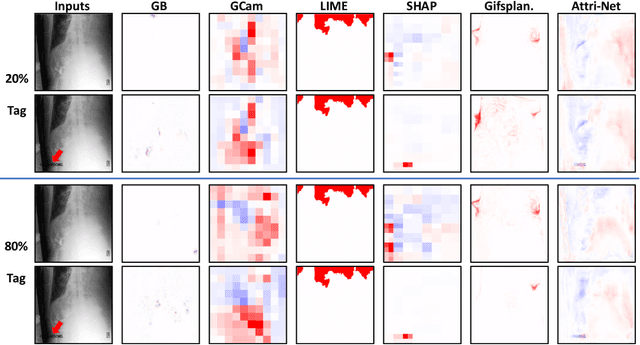
While deep neural network models offer unmatched classification performance, they are prone to learning spurious correlations in the data. Such dependencies on confounding information can be difficult to detect using performance metrics if the test data comes from the same distribution as the training data. Interpretable ML methods such as post-hoc explanations or inherently interpretable classifiers promise to identify faulty model reasoning. However, there is mixed evidence whether many of these techniques are actually able to do so. In this paper, we propose a rigorous evaluation strategy to assess an explanation technique's ability to correctly identify spurious correlations. Using this strategy, we evaluate five post-hoc explanation techniques and one inherently interpretable method for their ability to detect three types of artificially added confounders in a chest x-ray diagnosis task. We find that the post-hoc technique SHAP, as well as the inherently interpretable Attri-Net provide the best performance and can be used to reliably identify faulty model behavior.
RANSAC-NN: Unsupervised Image Outlier Detection using RANSAC
Jul 23, 2023Image outlier detection (OD) is crucial for ensuring the quality and accuracy of image datasets used in computer vision tasks. The majority of OD algorithms, however, have not been targeted toward image data. Consequently, the results of applying such algorithms to images are often suboptimal. In this work, we propose RANSAC-NN, a novel unsupervised OD algorithm specifically designed for images. By comparing images in a RANSAC-based approach, our algorithm automatically predicts the outlier score of each image without additional training or label information. We evaluate RANSAC-NN against state-of-the-art OD algorithms on 15 diverse datasets. Without any hyperparameter tuning, RANSAC-NN consistently performs favorably in contrast to other algorithms in almost every dataset category. Furthermore, we provide a detailed analysis to understand each RANSAC-NN component, and we demonstrate its potential applications in image mislabeled detection. Code for RANSAC-NN is provided at https://github.com/mxtsai/ransac-nn
Comparative analysis using classification methods versus early stage diabetes
Jul 23, 2023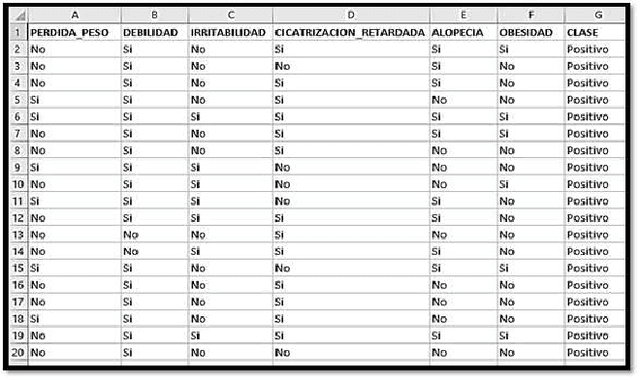
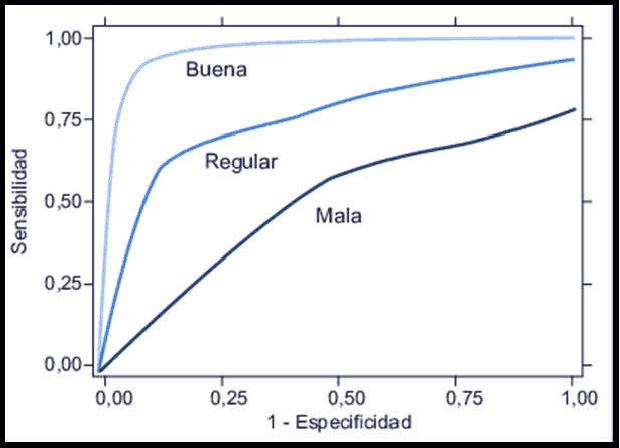

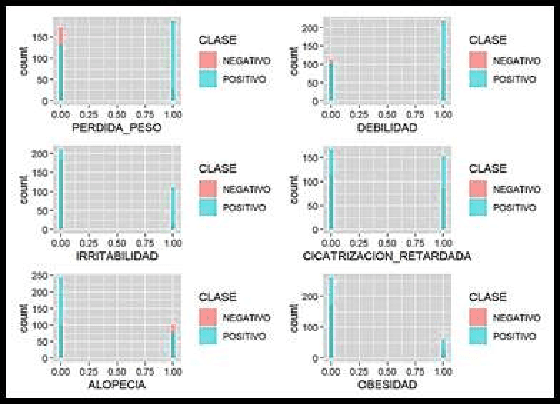
In this research work, a comparative analysis was carried out using classification methods such as: Discriminant Analysis and Logistic Regression to subsequently predict whether a person may have the presence of early stage diabetes. For this purpose, use was made of a database of the UC IRVINE platform of the year 2020 where specific variables that influence diabetes were used for a better result. Likewise in terms of methodology, the corresponding analysis was performed for each of the 3 classification methods and then take them to a comparative table and analyze the results obtained. Finally we can add that the majority of the studies carried out applying the classification methods to the diseases can be clearly seen that there is a certain attachment and more use of the logistic regression classification method, on the other hand, in the results we could see significant differences in terms of the 2 classification methods that were applied, which was valuable information for later drawing final conclusions.
Sim-to-Real Model-Based and Model-Free Deep Reinforcement Learning for Tactile Pushing
Jul 26, 2023
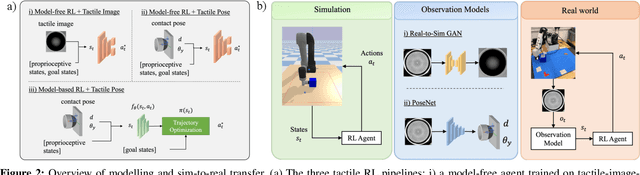
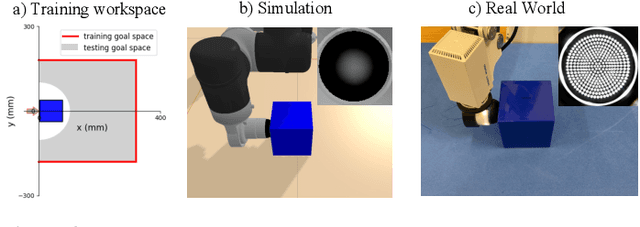
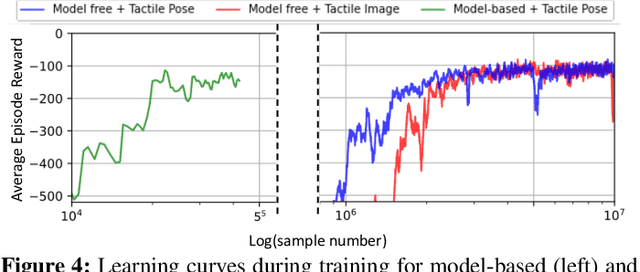
Object pushing presents a key non-prehensile manipulation problem that is illustrative of more complex robotic manipulation tasks. While deep reinforcement learning (RL) methods have demonstrated impressive learning capabilities using visual input, a lack of tactile sensing limits their capability for fine and reliable control during manipulation. Here we propose a deep RL approach to object pushing using tactile sensing without visual input, namely tactile pushing. We present a goal-conditioned formulation that allows both model-free and model-based RL to obtain accurate policies for pushing an object to a goal. To achieve real-world performance, we adopt a sim-to-real approach. Our results demonstrate that it is possible to train on a single object and a limited sample of goals to produce precise and reliable policies that can generalize to a variety of unseen objects and pushing scenarios without domain randomization. We experiment with the trained agents in harsh pushing conditions, and show that with significantly more training samples, a model-free policy can outperform a model-based planner, generating shorter and more reliable pushing trajectories despite large disturbances. The simplicity of our training environment and effective real-world performance highlights the value of rich tactile information for fine manipulation. Code and videos are available at https://sites.google.com/view/tactile-rl-pushing/.
Dynamic Domain Discrepancy Adjustment for Active Multi-Domain Adaptation
Jul 26, 2023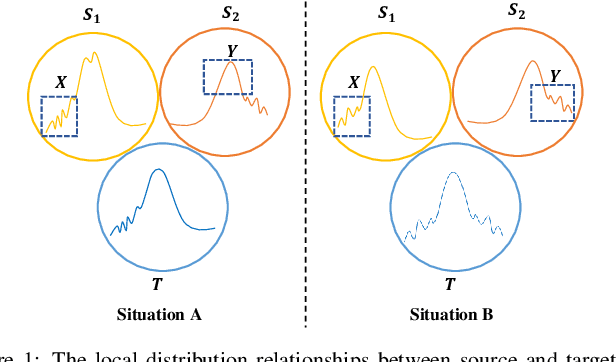
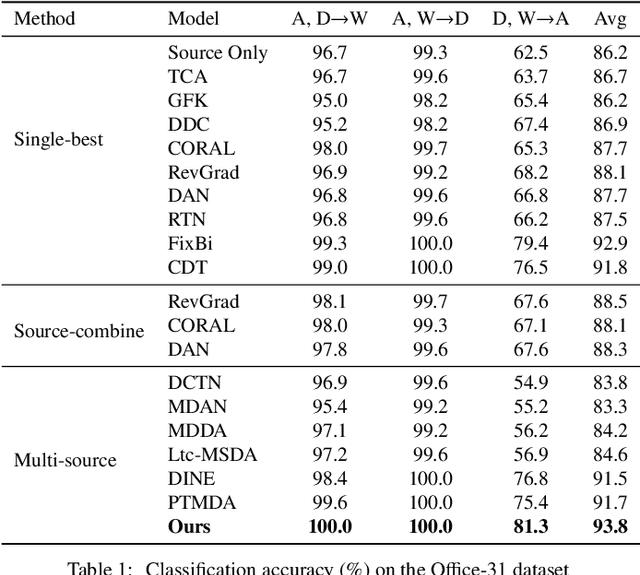
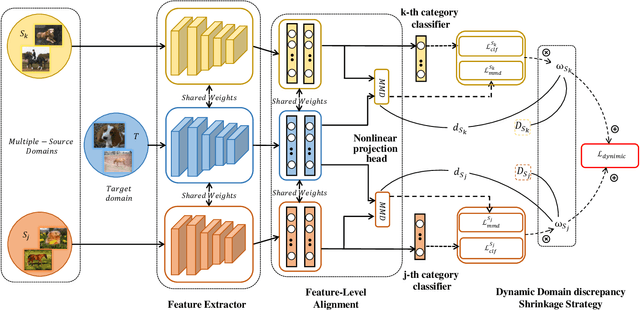
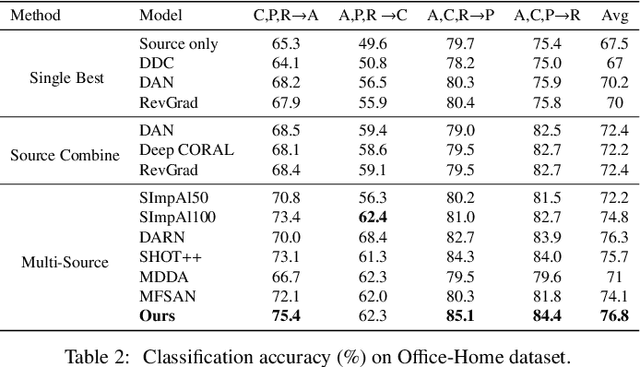
Multi-source unsupervised domain adaptation (MUDA) aims to transfer knowledge from related source domains to an unlabeled target domain. While recent MUDA methods have shown promising results, most focus on aligning the overall feature distributions across source domains, which can lead to negative effects due to redundant features within each domain. Moreover, there is a significant performance gap between MUDA and supervised methods. To address these challenges, we propose a novel approach called Dynamic Domain Discrepancy Adjustment for Active Multi-Domain Adaptation (D3AAMDA). Firstly, we establish a multi-source dynamic modulation mechanism during the training process based on the degree of distribution differences between source and target domains. This mechanism controls the alignment level of features between each source domain and the target domain, effectively leveraging the local advantageous feature information within the source domains. Additionally, we propose a Multi-source Active Boundary Sample Selection (MABS) strategy, which utilizes a guided dynamic boundary loss to design an efficient query function for selecting important samples. This strategy achieves improved generalization to the target domain with minimal sampling costs. We extensively evaluate our proposed method on commonly used domain adaptation datasets, comparing it against existing UDA and ADA methods. The experimental results unequivocally demonstrate the superiority of our approach.
ProtoASNet: Dynamic Prototypes for Inherently Interpretable and Uncertainty-Aware Aortic Stenosis Classification in Echocardiography
Jul 26, 2023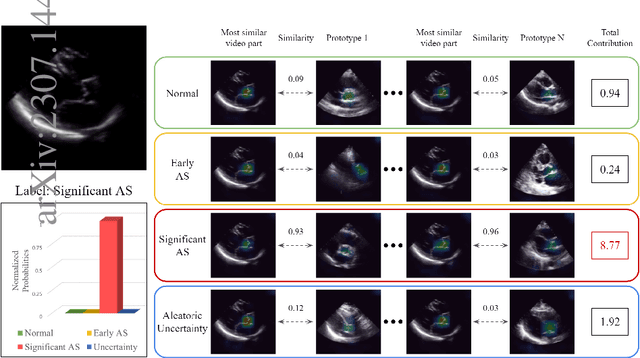
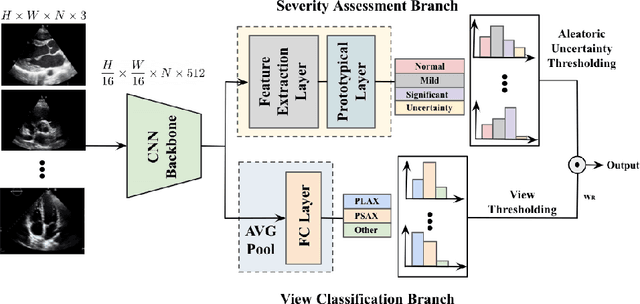
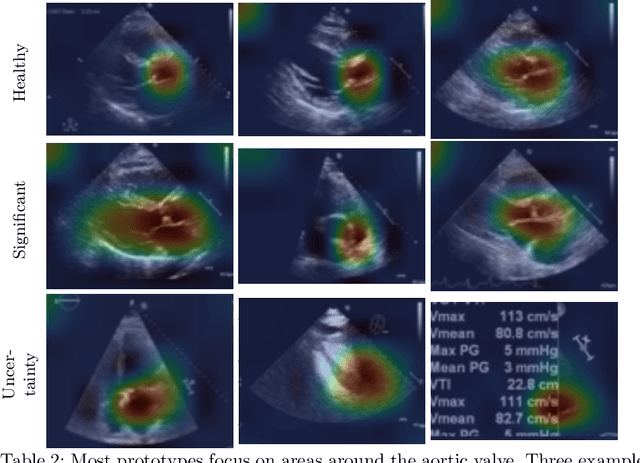
Aortic stenosis (AS) is a common heart valve disease that requires accurate and timely diagnosis for appropriate treatment. Most current automatic AS severity detection methods rely on black-box models with a low level of trustworthiness, which hinders clinical adoption. To address this issue, we propose ProtoASNet, a prototypical network that directly detects AS from B-mode echocardiography videos, while making interpretable predictions based on the similarity between the input and learned spatio-temporal prototypes. This approach provides supporting evidence that is clinically relevant, as the prototypes typically highlight markers such as calcification and restricted movement of aortic valve leaflets. Moreover, ProtoASNet utilizes abstention loss to estimate aleatoric uncertainty by defining a set of prototypes that capture ambiguity and insufficient information in the observed data. This provides a reliable system that can detect and explain when it may fail. We evaluate ProtoASNet on a private dataset and the publicly available TMED-2 dataset, where it outperforms existing state-of-the-art methods with an accuracy of 80.0% and 79.7%, respectively. Furthermore, ProtoASNet provides interpretability and an uncertainty measure for each prediction, which can improve transparency and facilitate the interactive usage of deep networks to aid clinical decision-making. Our source code is available at: https://github.com/hooman007/ProtoASNet.
Multi-UAV Enabled Integrated Sensing and Wireless Powered Communication: A Robust Multi-Objective Approach
Jul 26, 2023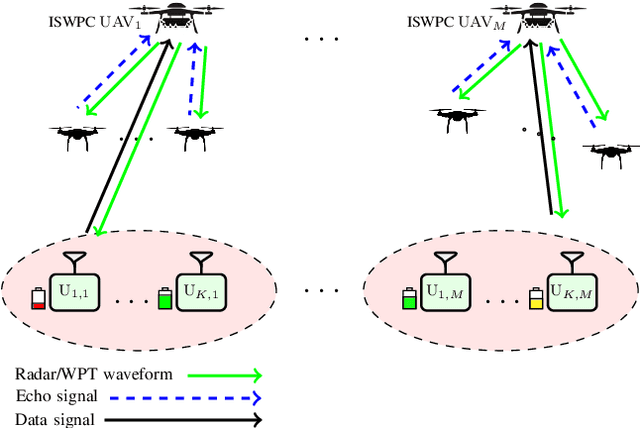
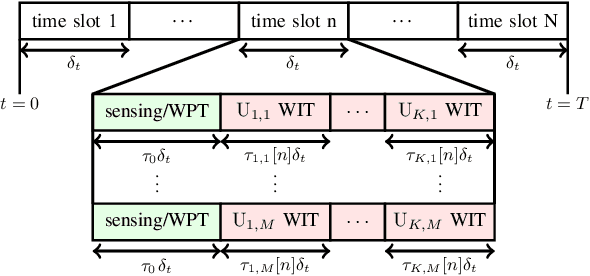
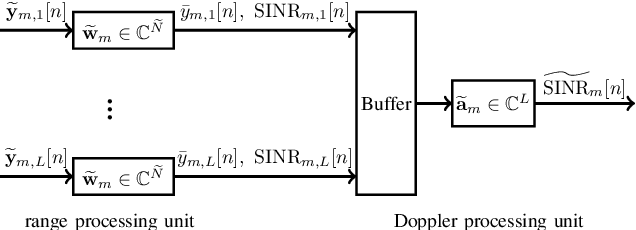
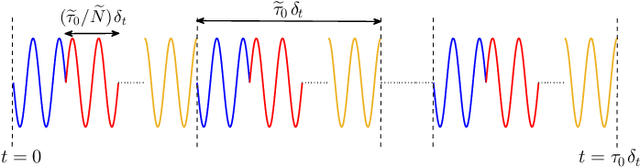
In this paper, we consider an integrated sensing and communication (ISAC) system with wireless power transfer (WPT) where multiple unmanned aerial vehicle (UAV)-based radars serve multiple clusters of energy-limited communication users in addition to their sensing functionality. In this architecture, the radars sense the environment in phase 1 (namely sensing phase) and meanwhile, the communications users (nodes) harvest and store the energy from the radar transmit signals. The stored energy is then used for information transmission from the nodes to UAVs in phase 2, i.e., uplink phase. Performance of the radar systems depends on the transmit signals as well as the receive filters; the energy of the transmit signals also affects the communication network because it serves as the source of uplink powers. Therefore, we cast a multi-objective design problem addressing performance of both radar and communication systems via optimizing UAV trajectories, radar transmit waveforms, radar receive filters, time scheduling and uplink powers. The design problem is further formulated as a robust non-convex optimization problem taking into account the the user location uncertainty. Hence, we devise a method based on alternating optimization followed by concepts of fractional programming, S-procedure, and tricky majorization-minimization (MM) technique to tackle it. Numerical examples illustrate the effectiveness of the proposed method for different scenarios.