 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubgroup Performance Analysis in Hidden Stratifications
Mar 13, 2025



Machine learning (ML) models may suffer from significant performance disparities between patient groups. Identifying such disparities by monitoring performance at a granular level is crucial for safely deploying ML to each patient. Traditional subgroup analysis based on metadata can expose performance disparities only if the available metadata (e.g., patient sex) sufficiently reflects the main reasons for performance variability, which is not common. Subgroup discovery techniques that identify cohesive subgroups based on learned feature representations appear as a potential solution: They could expose hidden stratifications and provide more granular subgroup performance reports. However, subgroup discovery is challenging to evaluate even as a standalone task, as ground truth stratification labels do not exist in real data. Subgroup discovery has thus neither been applied nor evaluated for the application of subgroup performance monitoring. Here, we apply subgroup discovery for performance monitoring in chest x-ray and skin lesion classification. We propose novel evaluation strategies and show that a simplified subgroup discovery method without access to classification labels or metadata can expose larger performance disparities than traditional metadata-based subgroup analysis. We provide the first compelling evidence that subgroup discovery can serve as an important tool for comprehensive performance validation and monitoring of trustworthy AI in medicine.
Prototype-Based Multiple Instance Learning for Gigapixel Whole Slide Image Classification
Mar 11, 2025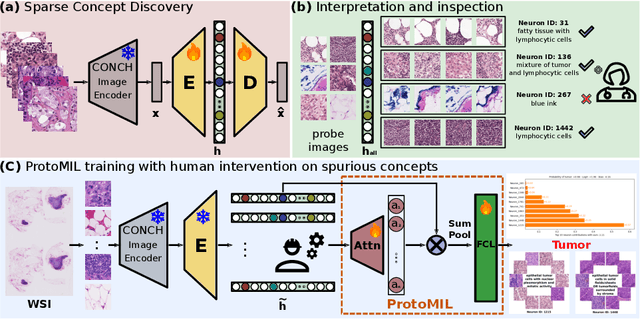
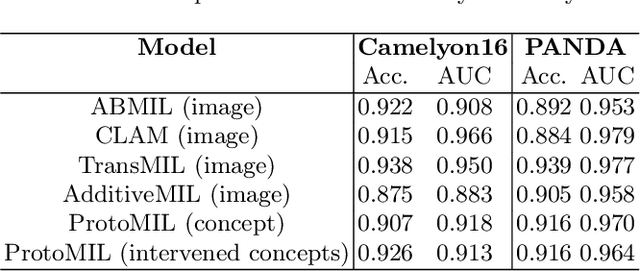
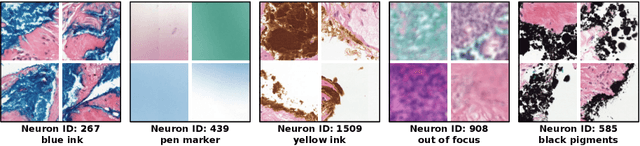
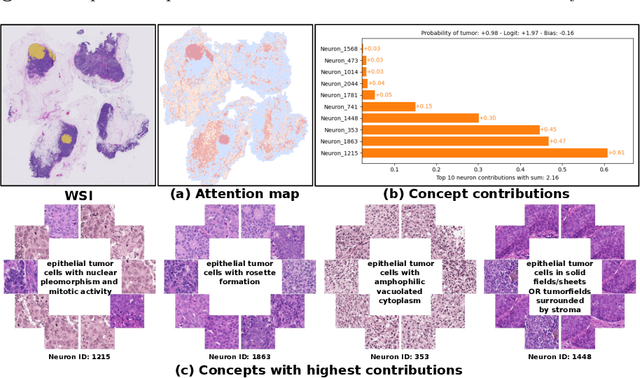
Multiple Instance Learning (MIL) methods have succeeded remarkably in histopathology whole slide image (WSI) analysis. However, most MIL models only offer attention-based explanations that do not faithfully capture the model's decision mechanism and do not allow human-model interaction. To address these limitations, we introduce ProtoMIL, an inherently interpretable MIL model for WSI analysis that offers user-friendly explanations and supports human intervention. Our approach employs a sparse autoencoder to discover human-interpretable concepts from the image feature space, which are then used to train ProtoMIL. The model represents predictions as linear combinations of concepts, making the decision process transparent. Furthermore, ProtoMIL allows users to perform model interventions by altering the input concepts. Experiments on two widely used pathology datasets demonstrate that ProtoMIL achieves a classification performance comparable to state-of-the-art MIL models while offering intuitively understandable explanations. Moreover, we demonstrate that our method can eliminate reliance on diagnostically irrelevant information via human intervention, guiding the model toward being right for the right reason. Code will be publicly available at https://github.com/ss-sun/ProtoMIL.
Label-free Concept Based Multiple Instance Learning for Gigapixel Histopathology
Jan 06, 2025



Multiple Instance Learning (MIL) methods allow for gigapixel Whole-Slide Image (WSI) analysis with only slide-level annotations. Interpretability is crucial for safely deploying such algorithms in high-stakes medical domains. Traditional MIL methods offer explanations by highlighting salient regions. However, such spatial heatmaps provide limited insights for end users. To address this, we propose a novel inherently interpretable WSI-classification approach that uses human-understandable pathology concepts to generate explanations. Our proposed Concept MIL model leverages recent advances in vision-language models to directly predict pathology concepts based on image features. The model's predictions are obtained through a linear combination of the concepts identified on the top-K patches of a WSI, enabling inherent explanations by tracing each concept's influence on the prediction. In contrast to traditional concept-based interpretable models, our approach eliminates the need for costly human annotations by leveraging the vision-language model. We validate our method on two widely used pathology datasets: Camelyon16 and PANDA. On both datasets, Concept MIL achieves AUC and accuracy scores over 0.9, putting it on par with state-of-the-art models. We further find that 87.1\% (Camelyon16) and 85.3\% (PANDA) of the top 20 patches fall within the tumor region. A user study shows that the concepts identified by our model align with the concepts used by pathologists, making it a promising strategy for human-interpretable WSI classification.
Attri-Net: A Globally and Locally Inherently Interpretable Model for Multi-Label Classification Using Class-Specific Counterfactuals
Jun 08, 2024



Interpretability is crucial for machine learning algorithms in high-stakes medical applications. However, high-performing neural networks typically cannot explain their predictions. Post-hoc explanation methods provide a way to understand neural networks but have been shown to suffer from conceptual problems. Moreover, current research largely focuses on providing local explanations for individual samples rather than global explanations for the model itself. In this paper, we propose Attri-Net, an inherently interpretable model for multi-label classification that provides local and global explanations. Attri-Net first counterfactually generates class-specific attribution maps to highlight the disease evidence, then performs classification with logistic regression classifiers based solely on the attribution maps. Local explanations for each prediction can be obtained by interpreting the attribution maps weighted by the classifiers' weights. Global explanation of whole model can be obtained by jointly considering learned average representations of the attribution maps for each class (called the class centers) and the weights of the linear classifiers. To ensure the model is ``right for the right reason", we further introduce a mechanism to guide the model's explanations to align with human knowledge. Our comprehensive evaluations show that Attri-Net can generate high-quality explanations consistent with clinical knowledge while not sacrificing classification performance.
Right for the Wrong Reason: Can Interpretable ML Techniques Detect Spurious Correlations?
Aug 08, 2023



While deep neural network models offer unmatched classification performance, they are prone to learning spurious correlations in the data. Such dependencies on confounding information can be difficult to detect using performance metrics if the test data comes from the same distribution as the training data. Interpretable ML methods such as post-hoc explanations or inherently interpretable classifiers promise to identify faulty model reasoning. However, there is mixed evidence whether many of these techniques are actually able to do so. In this paper, we propose a rigorous evaluation strategy to assess an explanation technique's ability to correctly identify spurious correlations. Using this strategy, we evaluate five post-hoc explanation techniques and one inherently interpretable method for their ability to detect three types of artificially added confounders in a chest x-ray diagnosis task. We find that the post-hoc technique SHAP, as well as the inherently interpretable Attri-Net provide the best performance and can be used to reliably identify faulty model behavior.
Inherently Interpretable Multi-Label Classification Using Class-Specific Counterfactuals
Mar 01, 2023



Interpretability is essential for machine learning algorithms in high-stakes application fields such as medical image analysis. However, high-performing black-box neural networks do not provide explanations for their predictions, which can lead to mistrust and suboptimal human-ML collaboration. Post-hoc explanation techniques, which are widely used in practice, have been shown to suffer from severe conceptual problems. Furthermore, as we show in this paper, current explanation techniques do not perform adequately in the multi-label scenario, in which multiple medical findings may co-occur in a single image. We propose Attri-Net, an inherently interpretable model for multi-label classification. Attri-Net is a powerful classifier that provides transparent, trustworthy, and human-understandable explanations. The model first generates class-specific attribution maps based on counterfactuals to identify which image regions correspond to certain medical findings. Then a simple logistic regression classifier is used to make predictions based solely on these attribution maps. We compare Attri-Net to five post-hoc explanation techniques and one inherently interpretable classifier on three chest X-ray datasets. We find that Attri-Net produces high-quality multi-label explanations consistent with clinical knowledge and has comparable classification performance to state-of-the-art classification models.