 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Properties of Continuous Diffusion Spoken Language Models
Apr 27, 2026Speech-only spoken language models (SLMs) lag behind text and text-speech models in performance, with recent discrete autoregressive (AR) SLMs indicating significant computational and data demands to match text models. Since discretizing continuous speech for AR creates bottlenecks, we explore whether continuous diffusion (CD) SLM is more viable. To quantify the SLMs linguistic quality, we introduce the phoneme Jensen-Shannon divergence (pJSD) metric. Our analysis reveals CD SLMs, mirroring AR behavior, exhibit scaling laws for validation loss and pJSD, and show optimal token-to-parameter ratios decreasing as compute scales. However, for the latter, loss becomes insensitive to choice of data and model sizes, showing potential for fast inference. Scaling CD SLMs to 16B parameters with tens of millions of hours of conversational data enables generation of emotive, prosodic, multi-speaker, multilingual speech, though achieving long-form coherence remains a significant challenge.
The Design Space of Tri-Modal Masked Diffusion Models
Feb 25, 2026Discrete diffusion models have emerged as strong alternatives to autoregressive language models, with recent work initializing and fine-tuning a base unimodal model for bimodal generation. Diverging from previous approaches, we introduce the first tri-modal masked diffusion model pretrained from scratch on text, image-text, and audio-text data. We systematically analyze multimodal scaling laws, modality mixing ratios, noise schedules, and batch-size effects, and we provide optimized inference sampling defaults. Our batch-size analysis yields a novel stochastic differential equation (SDE)-based reparameterization that eliminates the need for tuning the optimal batch size as reported in recent work. This reparameterization decouples the physical batch size, often chosen based on compute constraints (GPU saturation, FLOP efficiency, wall-clock time), from the logical batch size, chosen to balance gradient variance during stochastic optimization. Finally, we pretrain a preliminary 3B-parameter tri-modal model on 6.4T tokens, demonstrating the capabilities of a unified design and achieving strong results in text generation, text-to-image tasks, and text-to-speech tasks. Our work represents the largest-scale systematic open study of multimodal discrete diffusion models conducted to date, providing insights into scaling behaviors across multiple modalities.
A Small-Scale System for Autoregressive Program Synthesis Enabling Controlled Experimentation
Feb 09, 2026What research can be pursued with small models trained to complete true programs? Typically, researchers study program synthesis via large language models (LLMs) which introduce issues such as knowing what is in or out of distribution, understanding fine-tuning effects, understanding the effects of tokenization, and higher demand on compute and storage to carry out experiments. We present a system called Cadmus which includes an integer virtual machine (VM), a dataset composed of true programs of diverse tasks, and an autoregressive transformer model that is trained for under \$200 of compute cost. The system can be used to study program completion, out-of-distribution representations, inductive reasoning, and instruction following in a setting where researchers have effective and affordable fine-grained control of the training distribution and the ability to inspect and instrument models. Smaller models working on complex reasoning tasks enable instrumentation and investigations that may be prohibitively expensive on larger models. To demonstrate that these tasks are complex enough to be of interest, we show that these Cadmus models outperform GPT-5 (by achieving 100\% accuracy while GPT-5 has 95\% accuracy) even on a simple task of completing correct, integer arithmetic programs in our domain-specific language (DSL) while providing transparency into the dataset's relationship to the problem. We also show that GPT-5 brings unknown priors into its reasoning process when solving the same tasks, demonstrating a confounding factor that prevents the use of large-scale LLMs for some investigations where the training set relationship to the task needs to be fully understood.
Distillation Scaling Laws
Feb 12, 2025We provide a distillation scaling law that estimates distilled model performance based on a compute budget and its allocation between the student and teacher. Our findings reduce the risks associated with using distillation at scale; compute allocation for both the teacher and student models can now be done to maximize student performance. We provide compute optimal distillation recipes for when 1) a teacher exists, or 2) a teacher needs training. If many students are to be distilled, or a teacher already exists, distillation outperforms supervised pretraining until a compute level which grows predictably with student size. If one student is to be distilled and a teacher also needs training, supervised learning should be done instead. Additionally, we provide insights across our large scale study of distillation, which increase our understanding of distillation and inform experimental design.
Theory, Analysis, and Best Practices for Sigmoid Self-Attention
Sep 06, 2024



Attention is a key part of the transformer architecture. It is a sequence-to-sequence mapping that transforms each sequence element into a weighted sum of values. The weights are typically obtained as the softmax of dot products between keys and queries. Recent work has explored alternatives to softmax attention in transformers, such as ReLU and sigmoid activations. In this work, we revisit sigmoid attention and conduct an in-depth theoretical and empirical analysis. Theoretically, we prove that transformers with sigmoid attention are universal function approximators and benefit from improved regularity compared to softmax attention. Through detailed empirical analysis, we identify stabilization of large initial attention norms during the early stages of training as a crucial factor for the successful training of models with sigmoid attention, outperforming prior attempts. We also introduce FLASHSIGMOID, a hardware-aware and memory-efficient implementation of sigmoid attention yielding a 17% inference kernel speed-up over FLASHATTENTION2 on H100 GPUs. Experiments across language, vision, and speech show that properly normalized sigmoid attention matches the strong performance of softmax attention on a wide range of domains and scales, which previous attempts at sigmoid attention were unable to fully achieve. Our work unifies prior art and establishes best practices for sigmoid attention as a drop-in softmax replacement in transformers.
Poly-View Contrastive Learning
Mar 08, 2024



Contrastive learning typically matches pairs of related views among a number of unrelated negative views. Views can be generated (e.g. by augmentations) or be observed. We investigate matching when there are more than two related views which we call poly-view tasks, and derive new representation learning objectives using information maximization and sufficient statistics. We show that with unlimited computation, one should maximize the number of related views, and with a fixed compute budget, it is beneficial to decrease the number of unique samples whilst increasing the number of views of those samples. In particular, poly-view contrastive models trained for 128 epochs with batch size 256 outperform SimCLR trained for 1024 epochs at batch size 4096 on ImageNet1k, challenging the belief that contrastive models require large batch sizes and many training epochs.
Bootstrap Your Own Variance
Dec 06, 2023



Understanding model uncertainty is important for many applications. We propose Bootstrap Your Own Variance (BYOV), combining Bootstrap Your Own Latent (BYOL), a negative-free Self-Supervised Learning (SSL) algorithm, with Bayes by Backprop (BBB), a Bayesian method for estimating model posteriors. We find that the learned predictive std of BYOV vs. a supervised BBB model is well captured by a Gaussian distribution, providing preliminary evidence that the learned parameter posterior is useful for label free uncertainty estimation. BYOV improves upon the deterministic BYOL baseline (+2.83% test ECE, +1.03% test Brier) and presents better calibration and reliability when tested with various augmentations (eg: +2.4% test ECE, +1.2% test Brier for Salt & Pepper noise).
How to Scale Your EMA
Jul 27, 2023



Preserving training dynamics across batch sizes is an important tool for practical machine learning as it enables the trade-off between batch size and wall-clock time. This trade-off is typically enabled by a scaling rule, for example, in stochastic gradient descent, one should scale the learning rate linearly with the batch size. Another important tool for practical machine learning is the model Exponential Moving Average (EMA), which is a model copy that does not receive gradient information, but instead follows its target model with some momentum. This model EMA can improve the robustness and generalization properties of supervised learning, stabilize pseudo-labeling, and provide a learning signal for Self-Supervised Learning (SSL). Prior works have treated the model EMA separately from optimization, leading to different training dynamics across batch sizes and lower model performance. In this work, we provide a scaling rule for optimization in the presence of model EMAs and demonstrate its validity across a range of architectures, optimizers, and data modalities. We also show the rule's validity where the model EMA contributes to the optimization of the target model, enabling us to train EMA-based pseudo-labeling and SSL methods at small and large batch sizes. For SSL, we enable training of BYOL up to batch size 24,576 without sacrificing performance, optimally a 6$\times$ wall-clock time reduction.
Elastic Weight Consolidation Improves the Robustness of Self-Supervised Learning Methods under Transfer
Oct 28, 2022Self-supervised representation learning (SSL) methods provide an effective label-free initial condition for fine-tuning downstream tasks. However, in numerous realistic scenarios, the downstream task might be biased with respect to the target label distribution. This in turn moves the learned fine-tuned model posterior away from the initial (label) bias-free self-supervised model posterior. In this work, we re-interpret SSL fine-tuning under the lens of Bayesian continual learning and consider regularization through the Elastic Weight Consolidation (EWC) framework. We demonstrate that self-regularization against an initial SSL backbone improves worst sub-group performance in Waterbirds by 5% and Celeb-A by 2% when using the ViT-B/16 architecture. Furthermore, to help simplify the use of EWC with SSL, we pre-compute and publicly release the Fisher Information Matrix (FIM), evaluated with 10,000 ImageNet-1K variates evaluated on large modern SSL architectures including ViT-B/16 and ResNet50 trained with DINO.
Stochastic Contrastive Learning
Oct 01, 2021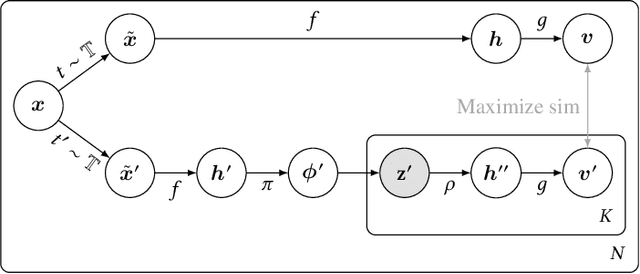

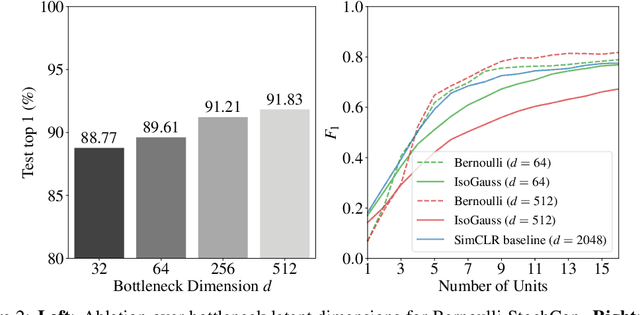
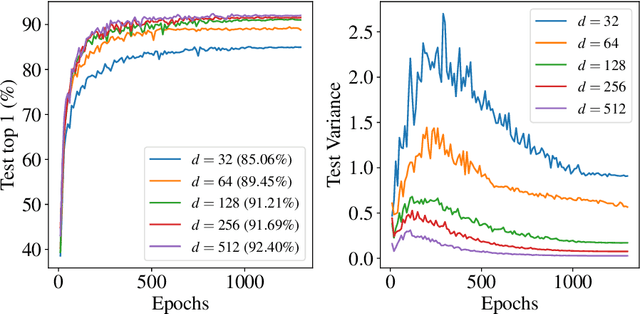
While state-of-the-art contrastive Self-Supervised Learning (SSL) models produce results competitive with their supervised counterparts, they lack the ability to infer latent variables. In contrast, prescribed latent variable (LV) models enable attributing uncertainty, inducing task specific compression, and in general allow for more interpretable representations. In this work, we introduce LV approximations to large scale contrastive SSL models. We demonstrate that this addition improves downstream performance (resulting in 96.42% and 77.49% test top-1 fine-tuned performance on CIFAR10 and ImageNet respectively with a ResNet50) as well as producing highly compressed representations (588x reduction) that are useful for interpretability, classification and regression downstream tasks.