 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
What Else Do I Need to Know? The Effect of Background Information on Users' Reliance on AI Systems
May 23, 2023
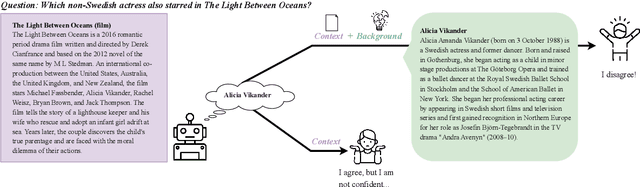
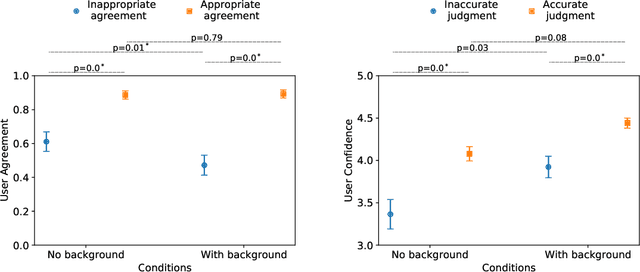
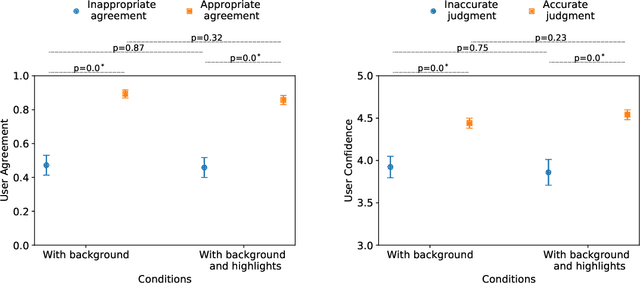
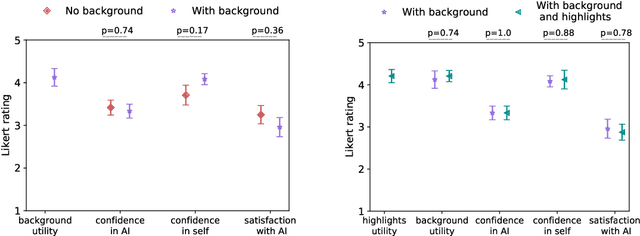
AI systems have shown impressive performance at answering questions by retrieving relevant context. However, with the increasingly large models, it is impossible and often undesirable to constrain models' knowledge or reasoning to only the retrieved context. This leads to a mismatch between the information that these models access to derive the answer and the information available to the user consuming the AI predictions to assess the AI predicted answer. In this work, we study how users interact with AI systems in absence of sufficient information to assess AI predictions. Further, we ask the question of whether adding the requisite background alleviates the concerns around over-reliance in AI predictions. Our study reveals that users rely on AI predictions even in the absence of sufficient information needed to assess its correctness. Providing the relevant background, however, helps users catch AI errors better, reducing over-reliance on incorrect AI predictions. On the flip side, background information also increases users' confidence in their correct as well as incorrect judgments. Contrary to common expectation, aiding a user's perusal of the context and the background through highlights is not helpful in alleviating the issue of over-confidence stemming from availability of more information. Our work aims to highlight the gap between how NLP developers perceive informational need in human-AI interaction and the actual human interaction with the information available to them.
System-Initiated Transitions from Chit-Chat to Task-Oriented Dialogues with Transition Info Extractor and Transition Sentence Generator
Aug 06, 2023


In this work, we study dialogue scenarios that start from chit-chat but eventually switch to task-related services, and investigate how a unified dialogue model, which can engage in both chit-chat and task-oriented dialogues, takes the initiative during the dialogue mode transition from chit-chat to task-oriented in a coherent and cooperative manner. We firstly build a {transition info extractor} (TIE) that keeps track of the preceding chit-chat interaction and detects the potential user intention to switch to a task-oriented service. Meanwhile, in the unified model, a {transition sentence generator} (TSG) is extended through efficient Adapter tuning and transition prompt learning. When the TIE successfully finds task-related information from the preceding chit-chat, such as a transition domain, then the TSG is activated automatically in the unified model to initiate this transition by generating a transition sentence under the guidance of transition information extracted by TIE. The experimental results show promising performance regarding the proactive transitions. We achieve an additional large improvement on TIE model by utilizing Conditional Random Fields (CRF). The TSG can flexibly generate transition sentences while maintaining the unified capabilities of normal chit-chat and task-oriented response generation.
Towards a Modular Architecture for Science Factories
Aug 18, 2023

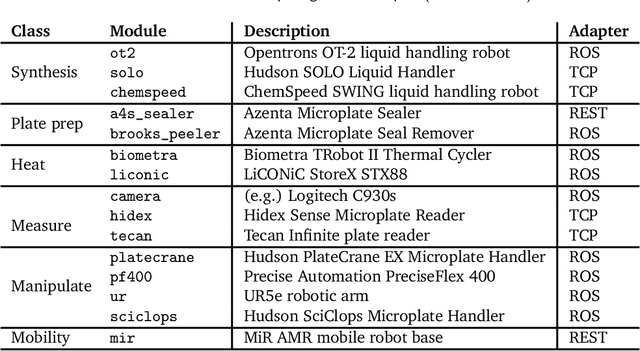
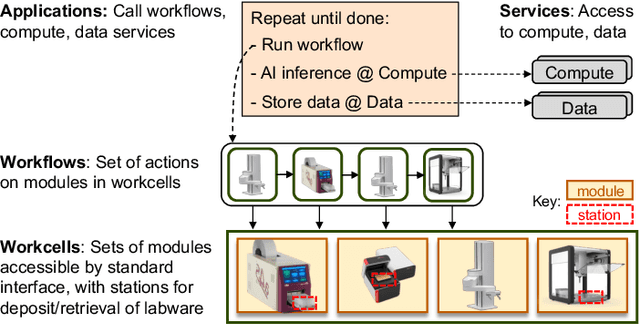
Advances in robotic automation, high-performance computing (HPC), and artificial intelligence (AI) encourage us to conceive of science factories: large, general-purpose computation- and AI-enabled self-driving laboratories (SDLs) with the generality and scale needed both to tackle large discovery problems and to support thousands of scientists. Science factories require modular hardware and software that can be replicated for scale and (re)configured to support many applications. To this end, we propose a prototype modular science factory architecture in which reconfigurable modules encapsulating scientific instruments are linked with manipulators to form workcells, that can themselves be combined to form larger assemblages, and linked with distributed computing for simulation, AI model training and inference, and related tasks. Workflows that perform sets of actions on modules can be specified, and various applications, comprising workflows plus associated computational and data manipulation steps, can be run concurrently. We report on our experiences prototyping this architecture and applying it in experiments involving 15 different robotic apparatus, five applications (one in education, two in biology, two in materials), and a variety of workflows, across four laboratories. We describe the reuse of modules, workcells, and workflows in different applications, the migration of applications between workcells, and the use of digital twins, and suggest directions for future work aimed at yet more generality and scalability. Code and data are available at https://ad-sdl.github.io/wei2023 and in the Supplementary Information
DOMINO: Domain-invariant Hyperdimensional Classification for Multi-Sensor Time Series Data
Aug 18, 2023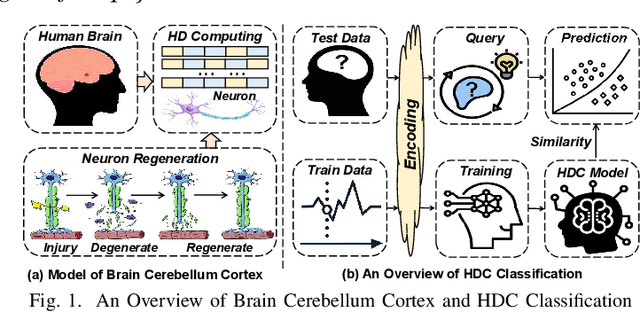
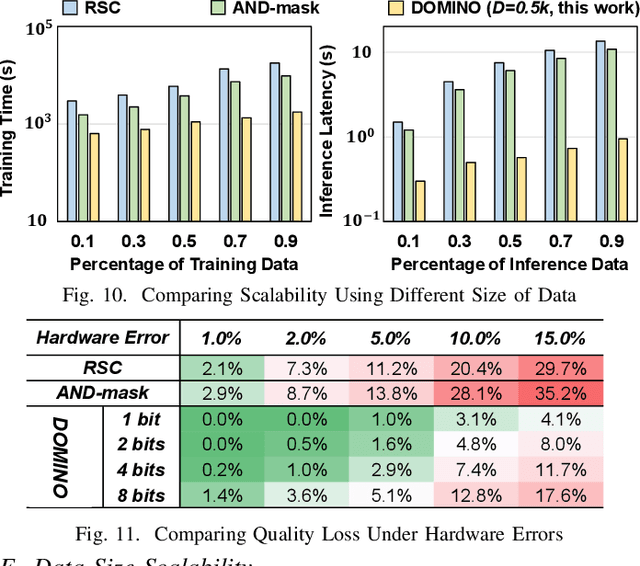
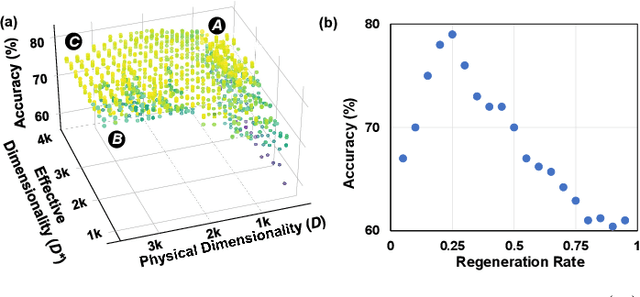
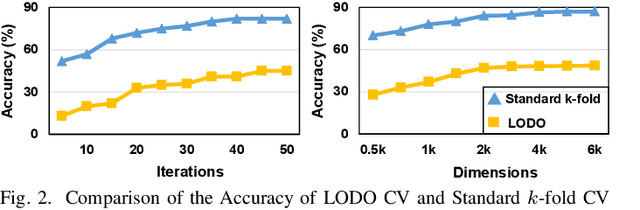
With the rapid evolution of the Internet of Things, many real-world applications utilize heterogeneously connected sensors to capture time-series information. Edge-based machine learning (ML) methodologies are often employed to analyze locally collected data. However, a fundamental issue across data-driven ML approaches is distribution shift. It occurs when a model is deployed on a data distribution different from what it was trained on, and can substantially degrade model performance. Additionally, increasingly sophisticated deep neural networks (DNNs) have been proposed to capture spatial and temporal dependencies in multi-sensor time series data, requiring intensive computational resources beyond the capacity of today's edge devices. While brain-inspired hyperdimensional computing (HDC) has been introduced as a lightweight solution for edge-based learning, existing HDCs are also vulnerable to the distribution shift challenge. In this paper, we propose DOMINO, a novel HDC learning framework addressing the distribution shift problem in noisy multi-sensor time-series data. DOMINO leverages efficient and parallel matrix operations on high-dimensional space to dynamically identify and filter out domain-variant dimensions. Our evaluation on a wide range of multi-sensor time series classification tasks shows that DOMINO achieves on average 2.04% higher accuracy than state-of-the-art (SOTA) DNN-based domain generalization techniques, and delivers 16.34x faster training and 2.89x faster inference. More importantly, DOMINO performs notably better when learning from partially labeled and highly imbalanced data, providing 10.93x higher robustness against hardware noises than SOTA DNNs.
Open-vocabulary Video Question Answering: A New Benchmark for Evaluating the Generalizability of Video Question Answering Models
Aug 18, 2023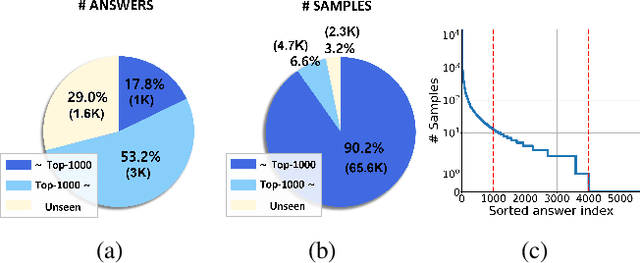
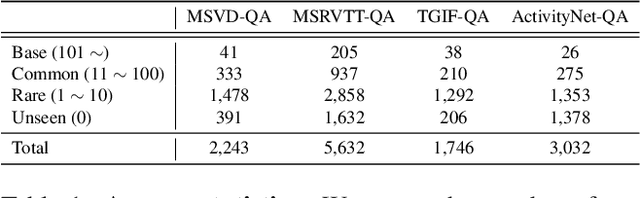
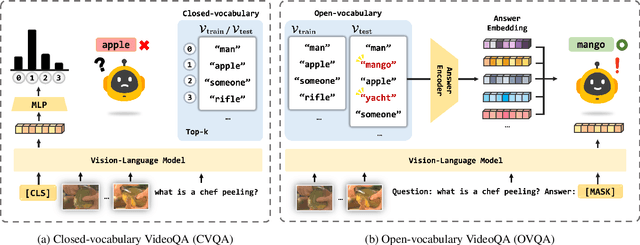
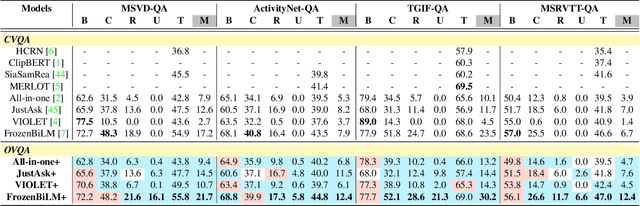
Video Question Answering (VideoQA) is a challenging task that entails complex multi-modal reasoning. In contrast to multiple-choice VideoQA which aims to predict the answer given several options, the goal of open-ended VideoQA is to answer questions without restricting candidate answers. However, the majority of previous VideoQA models formulate open-ended VideoQA as a classification task to classify the video-question pairs into a fixed answer set, i.e., closed-vocabulary, which contains only frequent answers (e.g., top-1000 answers). This leads the model to be biased toward only frequent answers and fail to generalize on out-of-vocabulary answers. We hence propose a new benchmark, Open-vocabulary Video Question Answering (OVQA), to measure the generalizability of VideoQA models by considering rare and unseen answers. In addition, in order to improve the model's generalization power, we introduce a novel GNN-based soft verbalizer that enhances the prediction on rare and unseen answers by aggregating the information from their similar words. For evaluation, we introduce new baselines by modifying the existing (closed-vocabulary) open-ended VideoQA models and improve their performances by further taking into account rare and unseen answers. Our ablation studies and qualitative analyses demonstrate that our GNN-based soft verbalizer further improves the model performance, especially on rare and unseen answers. We hope that our benchmark OVQA can serve as a guide for evaluating the generalizability of VideoQA models and inspire future research. Code is available at https://github.com/mlvlab/OVQA.
NAPA-VQ: Neighborhood Aware Prototype Augmentation with Vector Quantization for Continual Learning
Aug 18, 2023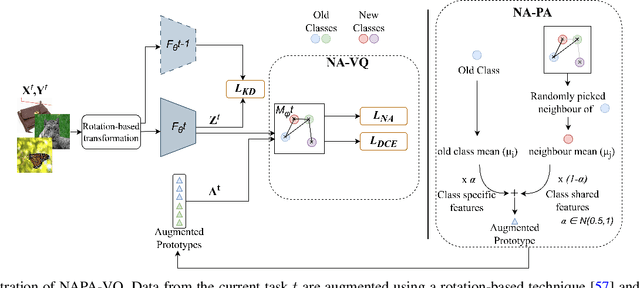
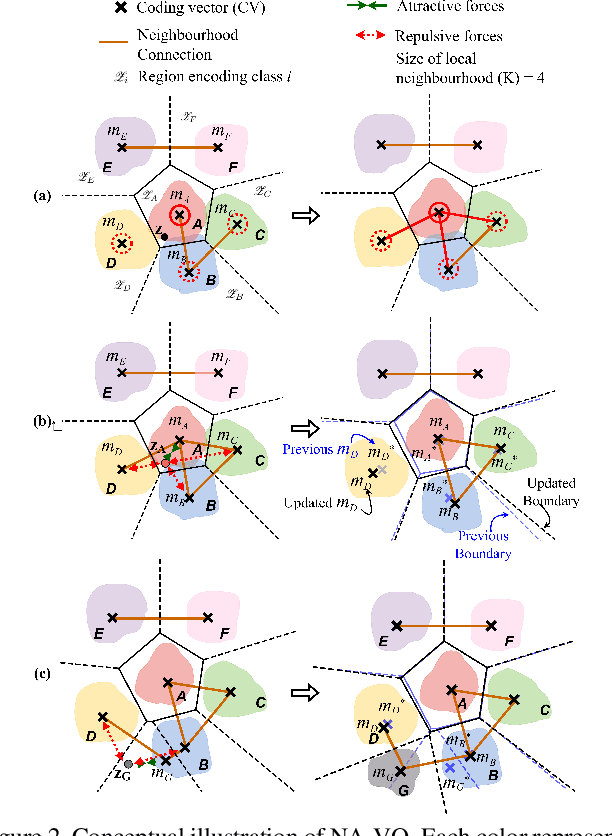
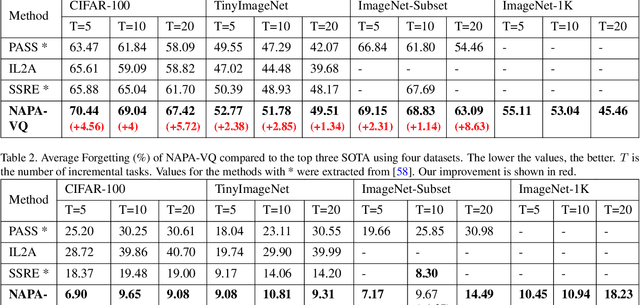
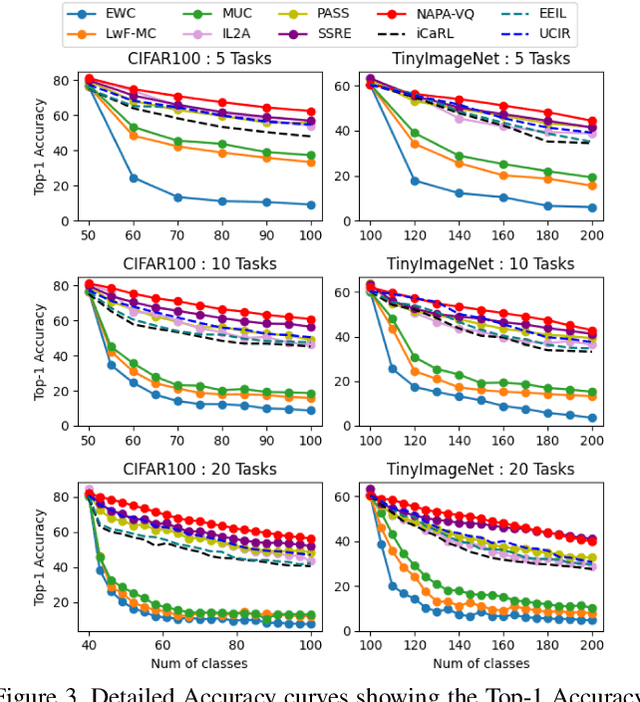
Catastrophic forgetting; the loss of old knowledge upon acquiring new knowledge, is a pitfall faced by deep neural networks in real-world applications. Many prevailing solutions to this problem rely on storing exemplars (previously encountered data), which may not be feasible in applications with memory limitations or privacy constraints. Therefore, the recent focus has been on Non-Exemplar based Class Incremental Learning (NECIL) where a model incrementally learns about new classes without using any past exemplars. However, due to the lack of old data, NECIL methods struggle to discriminate between old and new classes causing their feature representations to overlap. We propose NAPA-VQ: Neighborhood Aware Prototype Augmentation with Vector Quantization, a framework that reduces this class overlap in NECIL. We draw inspiration from Neural Gas to learn the topological relationships in the feature space, identifying the neighboring classes that are most likely to get confused with each other. This neighborhood information is utilized to enforce strong separation between the neighboring classes as well as to generate old class representative prototypes that can better aid in obtaining a discriminative decision boundary between old and new classes. Our comprehensive experiments on CIFAR-100, TinyImageNet, and ImageNet-Subset demonstrate that NAPA-VQ outperforms the State-of-the-art NECIL methods by an average improvement of 5%, 2%, and 4% in accuracy and 10%, 3%, and 9% in forgetting respectively. Our code can be found in https://github.com/TamashaM/NAPA-VQ.git.
Lightweight Self-Knowledge Distillation with Multi-source Information Fusion
May 16, 2023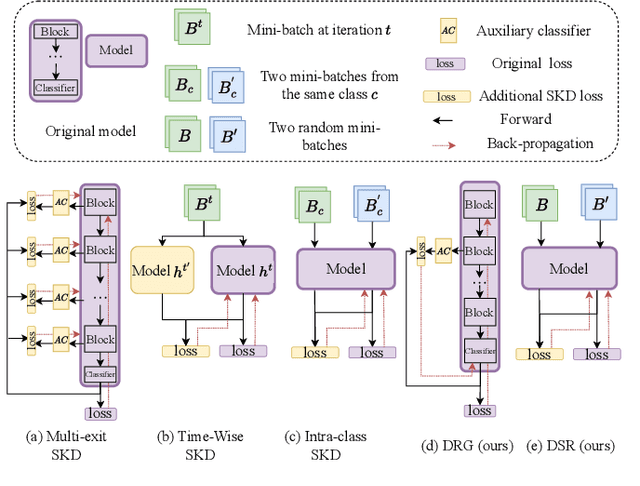
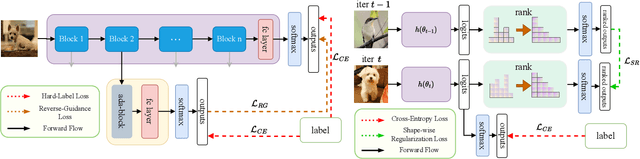
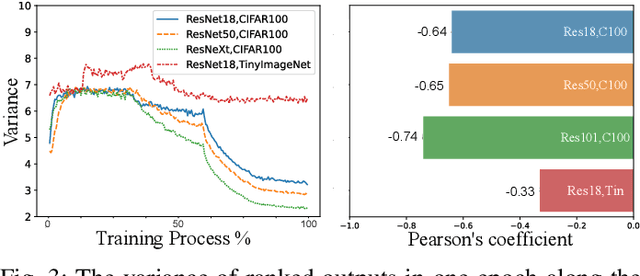
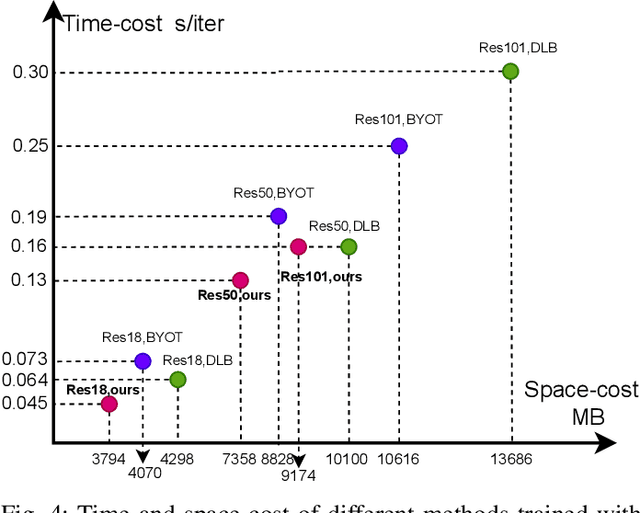
Knowledge Distillation (KD) is a powerful technique for transferring knowledge between neural network models, where a pre-trained teacher model is used to facilitate the training of the target student model. However, the availability of a suitable teacher model is not always guaranteed. To address this challenge, Self-Knowledge Distillation (SKD) attempts to construct a teacher model from itself. Existing SKD methods add Auxiliary Classifiers (AC) to intermediate layers of the model or use the history models and models with different input data within the same class. However, these methods are computationally expensive and only capture time-wise and class-wise features of data. In this paper, we propose a lightweight SKD framework that utilizes multi-source information to construct a more informative teacher. Specifically, we introduce a Distillation with Reverse Guidance (DRG) method that considers different levels of information extracted by the model, including edge, shape, and detail of the input data, to construct a more informative teacher. Additionally, we design a Distillation with Shape-wise Regularization (DSR) method that ensures a consistent shape of ranked model output for all data. We validate the performance of the proposed DRG, DSR, and their combination through comprehensive experiments on various datasets and models. Our results demonstrate the superiority of the proposed methods over baselines (up to 2.87%) and state-of-the-art SKD methods (up to 1.15%), while being computationally efficient and robust. The code is available at https://github.com/xucong-parsifal/LightSKD.
Pseudo-online framework for BCI evaluation: A MOABB perspective
Aug 21, 2023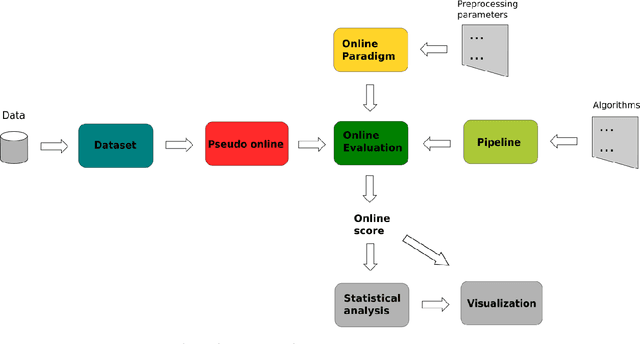

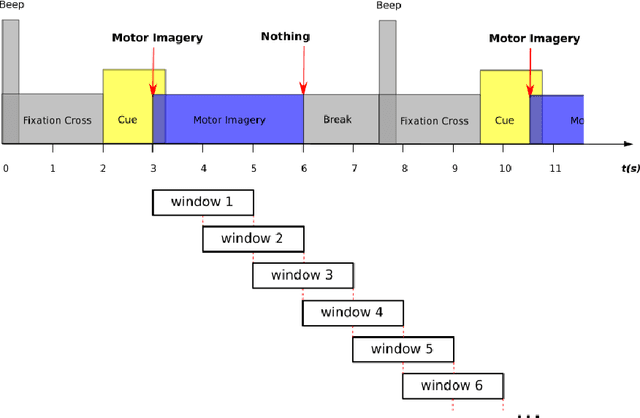
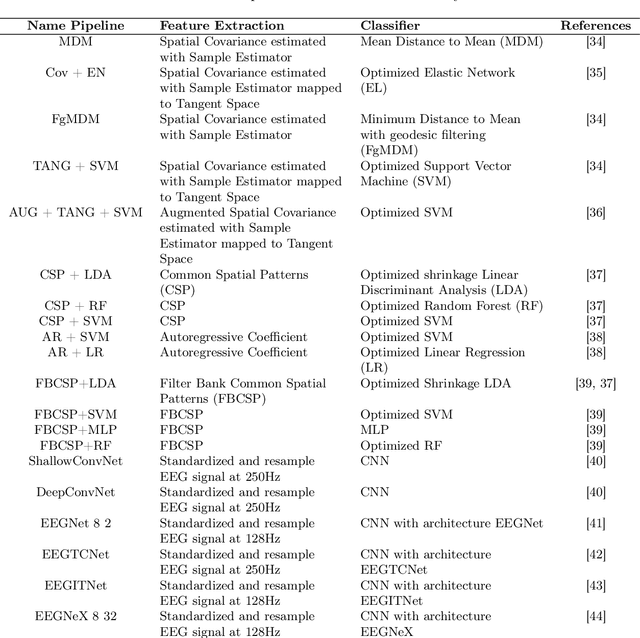
Objective: BCI (Brain-Computer Interface) technology operates in three modes: online, offline, and pseudo-online. In the online mode, real-time EEG data is constantly analyzed. In offline mode, the signal is acquired and processed afterwards. The pseudo-online mode processes collected data as if they were received in real-time. The main difference is that the offline mode often analyzes the whole data, while the online and pseudo-online modes only analyze data in short time windows. Offline analysis is usually done with asynchronous BCIs, which restricts analysis to predefined time windows. Asynchronous BCI, compatible with online and pseudo-online modes, allows flexible mental activity duration. Offline processing tends to be more accurate, while online analysis is better for therapeutic applications. Pseudo-online implementation approximates online processing without real-time constraints. Many BCI studies being offline introduce biases compared to real-life scenarios, impacting classification algorithm performance. Approach: The objective of this research paper is therefore to extend the current MOABB framework, operating in offline mode, so as to allow a comparison of different algorithms in a pseudo-online setting with the use of a technology based on overlapping sliding windows. To do this will require the introduction of a idle state event in the dataset that takes into account all different possibilities that are not task thinking. To validate the performance of the algorithms we will use the normalized Matthews Correlation Coefficient (nMCC) and the Information Transfer Rate (ITR). Main results: We analyzed the state-of-the-art algorithms of the last 15 years over several Motor Imagery (MI) datasets composed by several subjects, showing the differences between the two approaches from a statistical point of view. Significance: The ability to analyze the performance of different algorithms in offline and pseudo-online modes will allow the BCI community to obtain more accurate and comprehensive reports regarding the performance of classification algorithms.
Analysing the Resourcefulness of the Paragraph for Precedence Retrieval
Jul 29, 2023
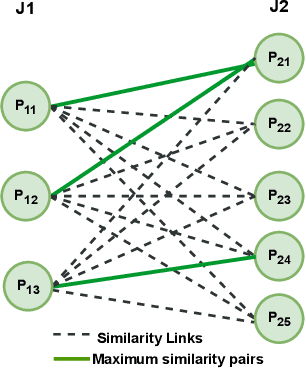
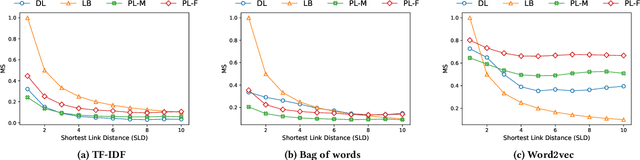
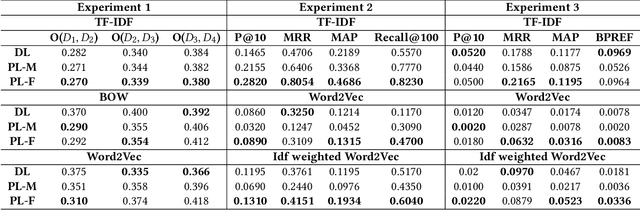
Developing methods for extracting relevant legal information to aid legal practitioners is an active research area. In this regard, research efforts are being made by leveraging different kinds of information, such as meta-data, citations, keywords, sentences, paragraphs, etc. Similar to any text document, legal documents are composed of paragraphs. In this paper, we have analyzed the resourcefulness of paragraph-level information in capturing similarity among judgments for improving the performance of precedence retrieval. We found that the paragraph-level methods could capture the similarity among the judgments with only a few paragraph interactions and exhibit more discriminating power over the baseline document-level method. Moreover, the comparison results on two benchmark datasets for the precedence retrieval on the Indian supreme court judgments task show that the paragraph-level methods exhibit comparable performance with the state-of-the-art methods
Discovering the Symptom Patterns of COVID-19 from Recovered and Deceased Patients Using Apriori Association Rule Mining
Aug 13, 2023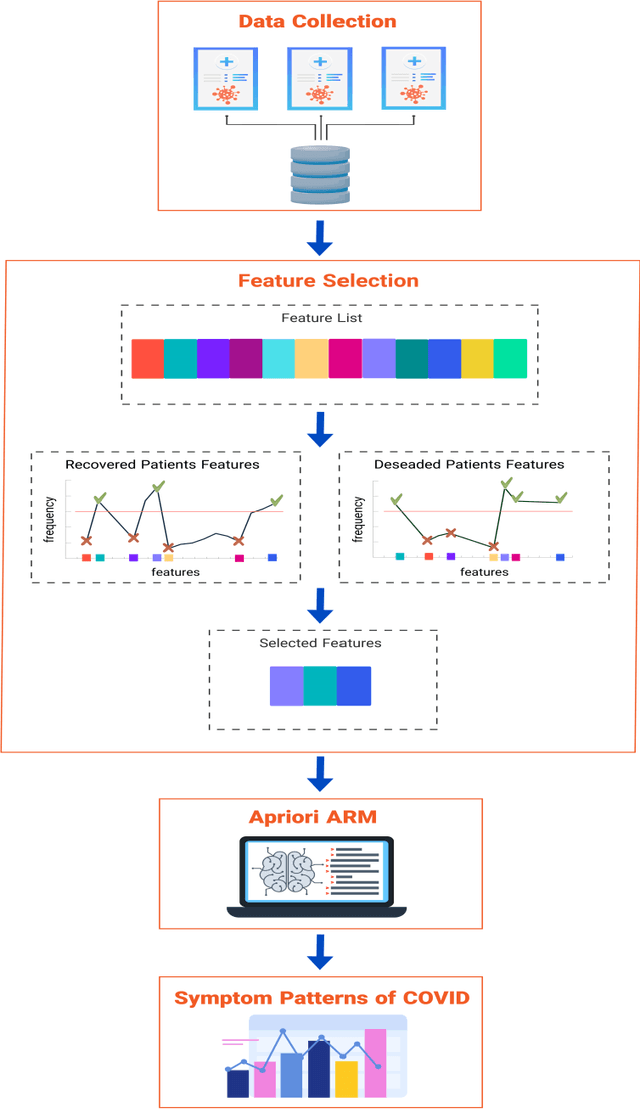

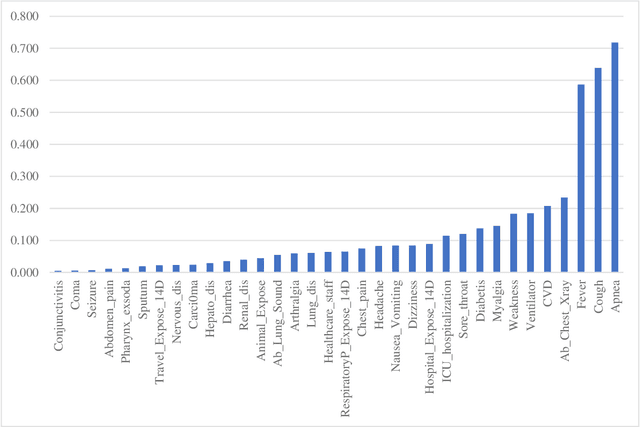
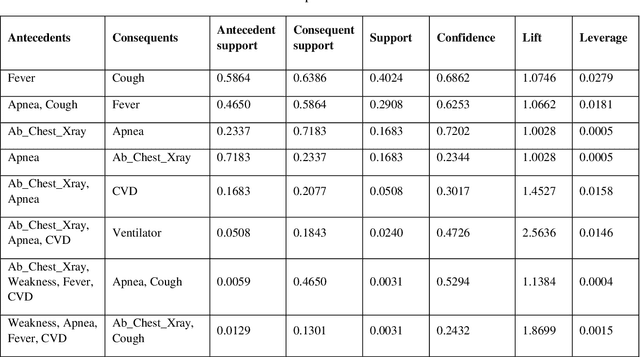
The COVID-19 pandemic has a devastating impact globally, claiming millions of lives and causing significant social and economic disruptions. In order to optimize decision-making and allocate limited resources, it is essential to identify COVID-19 symptoms and determine the severity of each case. Machine learning algorithms offer a potent tool in the medical field, particularly in mining clinical datasets for useful information and guiding scientific decisions. Association rule mining is a machine learning technique for extracting hidden patterns from data. This paper presents an application of association rule mining based Apriori algorithm to discover symptom patterns from COVID-19 patients. The study, using 2875 records of patient, identified the most common symptoms as apnea (72%), cough (64%), fever (59%), weakness (18%), myalgia (14.5%), and sore throat (12%). The proposed method provides clinicians with valuable insight into disease that can assist them in managing and treating it effectively.