 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fusing VHR Post-disaster Aerial Imagery and LiDAR Data for Roof Classification in the Caribbean using CNNs
Aug 07, 2023
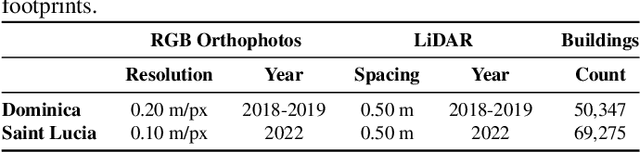

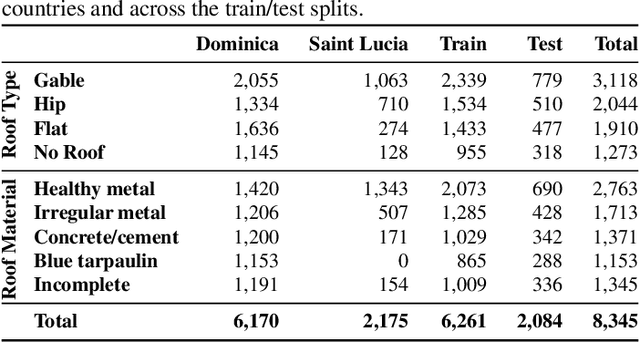

Accurate and up-to-date information on building characteristics is essential for vulnerability assessment; however, the high costs and long timeframes associated with conducting traditional field surveys can be an obstacle to obtaining critical exposure datasets needed for disaster risk management. In this work, we leverage deep learning techniques for the automated classification of roof characteristics from very high-resolution orthophotos and airborne LiDAR data obtained in Dominica following Hurricane Maria in 2017. We demonstrate that the fusion of multimodal earth observation data performs better than using any single data source alone. Using our proposed methods, we achieve F1 scores of 0.93 and 0.92 for roof type and roof material classification, respectively. This work is intended to help governments produce more timely building information to improve resilience and disaster response in the Caribbean.
Boosting Chinese ASR Error Correction with Dynamic Error Scaling Mechanism
Aug 07, 2023
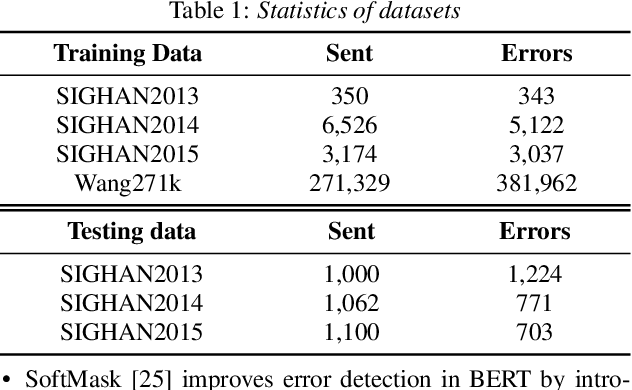
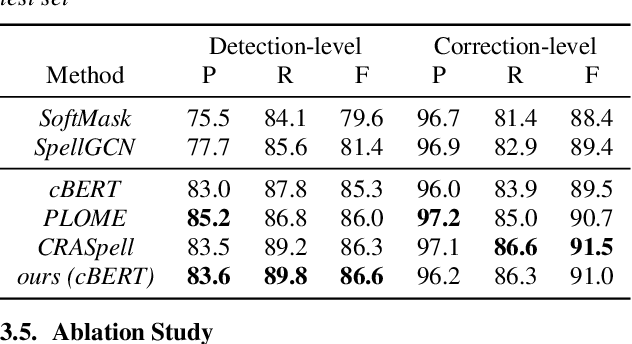
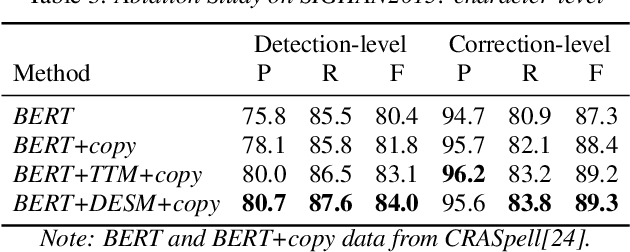
Chinese Automatic Speech Recognition (ASR) error correction presents significant challenges due to the Chinese language's unique features, including a large character set and borderless, morpheme-based structure. Current mainstream models often struggle with effectively utilizing word-level features and phonetic information. This paper introduces a novel approach that incorporates a dynamic error scaling mechanism to detect and correct phonetically erroneous text generated by ASR output. This mechanism operates by dynamically fusing word-level features and phonetic information, thereby enriching the model with additional semantic data. Furthermore, our method implements unique error reduction and amplification strategies to address the issues of matching wrong words caused by incorrect characters. Experimental results indicate substantial improvements in ASR error correction, demonstrating the effectiveness of our proposed method and yielding promising results on established datasets.
ZRIGF: An Innovative Multimodal Framework for Zero-Resource Image-Grounded Dialogue Generation
Aug 02, 2023
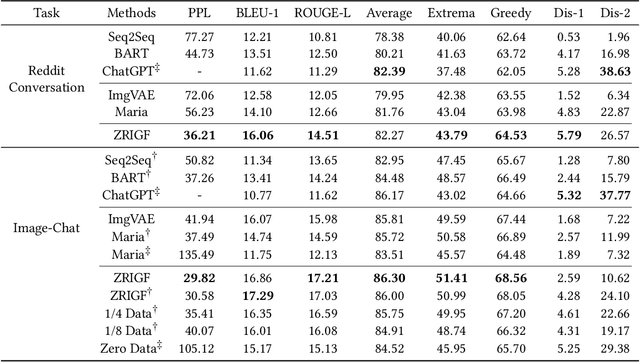
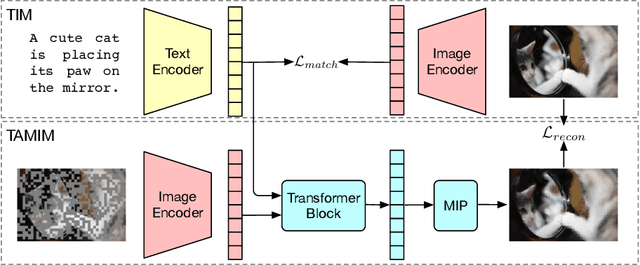

Image-grounded dialogue systems benefit greatly from integrating visual information, resulting in high-quality response generation. However, current models struggle to effectively utilize such information in zero-resource scenarios, mainly due to the disparity between image and text modalities. To overcome this challenge, we propose an innovative multimodal framework, called ZRIGF, which assimilates image-grounded information for dialogue generation in zero-resource situations. ZRIGF implements a two-stage learning strategy, comprising contrastive pre-training and generative pre-training. Contrastive pre-training includes a text-image matching module that maps images and texts into a unified encoded vector space, along with a text-assisted masked image modeling module that preserves pre-training visual features and fosters further multimodal feature alignment. Generative pre-training employs a multimodal fusion module and an information transfer module to produce insightful responses based on harmonized multimodal representations. Comprehensive experiments conducted on both text-based and image-grounded dialogue datasets demonstrate ZRIGF's efficacy in generating contextually pertinent and informative responses. Furthermore, we adopt a fully zero-resource scenario in the image-grounded dialogue dataset to demonstrate our framework's robust generalization capabilities in novel domains. The code is available at https://github.com/zhangbo-nlp/ZRIGF.
Spatio-Temporal Branching for Motion Prediction using Motion Increments
Aug 02, 2023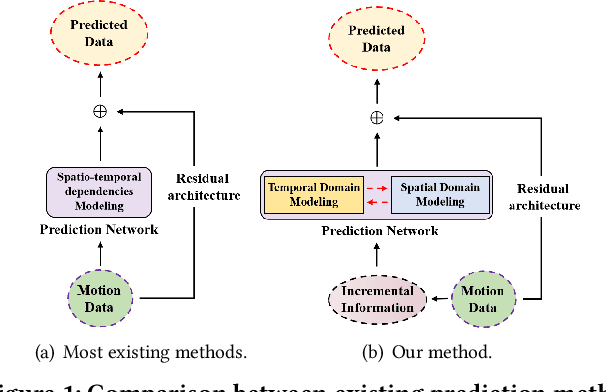
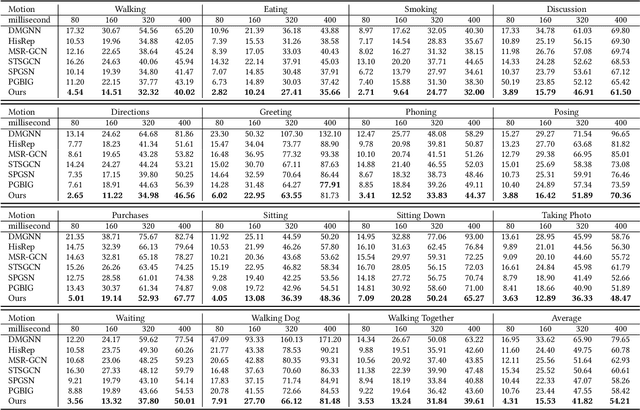
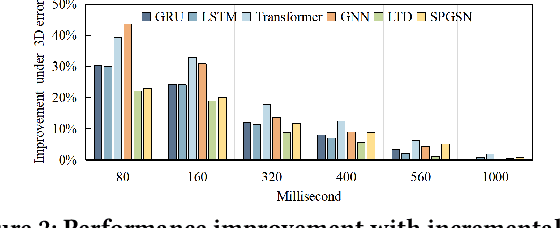
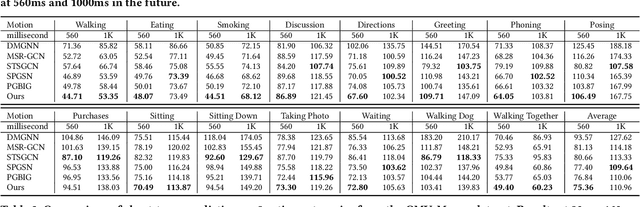
Human motion prediction (HMP) has emerged as a popular research topic due to its diverse applications, but it remains a challenging task due to the stochastic and aperiodic nature of future poses. Traditional methods rely on hand-crafted features and machine learning techniques, which often struggle to model the complex dynamics of human motion. Recent deep learning-based methods have achieved success by learning spatio-temporal representations of motion, but these models often overlook the reliability of motion data. Additionally, the temporal and spatial dependencies of skeleton nodes are distinct. The temporal relationship captures motion information over time, while the spatial relationship describes body structure and the relationships between different nodes. In this paper, we propose a novel spatio-temporal branching network using incremental information for HMP, which decouples the learning of temporal-domain and spatial-domain features, extracts more motion information, and achieves complementary cross-domain knowledge learning through knowledge distillation. Our approach effectively reduces noise interference and provides more expressive information for characterizing motion by separately extracting temporal and spatial features. We evaluate our approach on standard HMP benchmarks and outperform state-of-the-art methods in terms of prediction accuracy.
Characterization of cough sounds using statistical analysis
Aug 06, 2023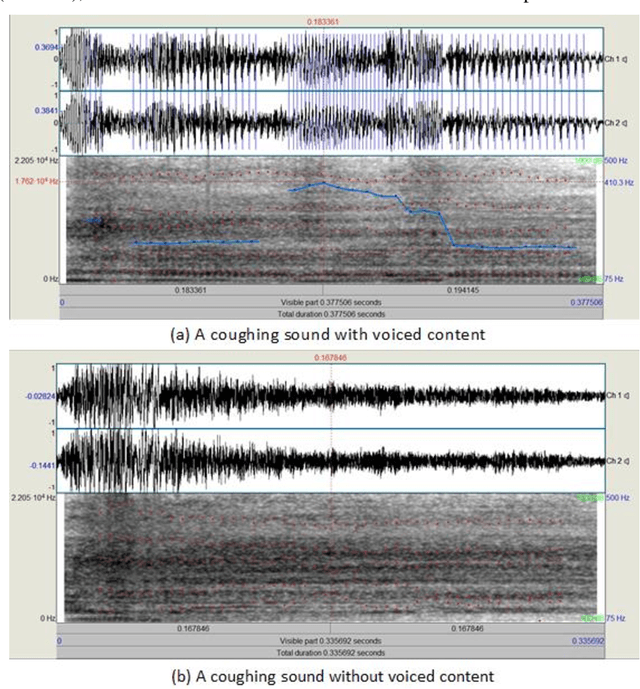
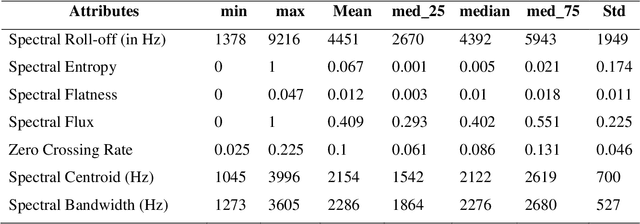
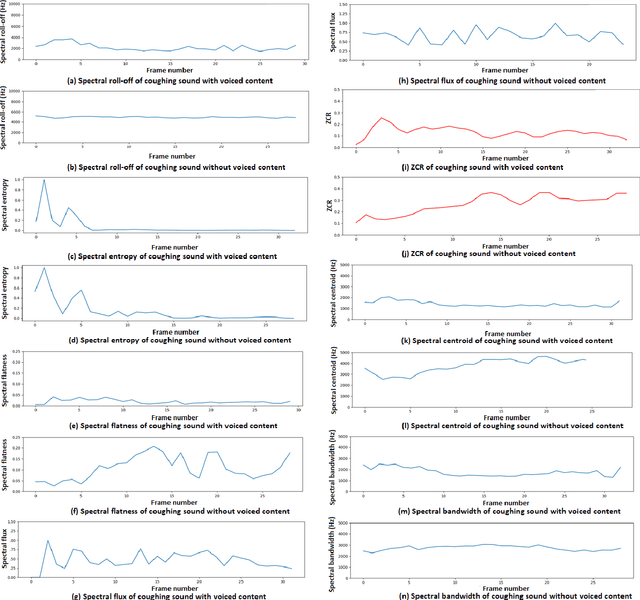
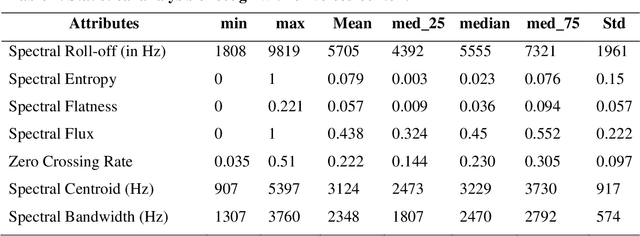
Cough is a primary symptom of most respiratory diseases, and changes in cough characteristics provide valuable information for diagnosing respiratory diseases. The characterization of cough sounds still lacks concrete evidence, which makes it difficult to accurately distinguish between different types of coughs and other sounds. The objective of this research work is to characterize cough sounds with voiced content and cough sounds without voiced content. Further, the cough sound characteristics are compared with the characteristics of speech. The proposed method to achieve this goal utilized spectral roll-off, spectral entropy, spectral flatness, spectral flux, zero crossing rate, spectral centroid, and spectral bandwidth attributes which describe the cough sounds related to the respiratory system, glottal information, and voice model. These attributes are then subjected to statistical analysis using the measures of minimum, maximum, mean, median, and standard deviation. The experimental results show that the mean and frequency distribution of spectral roll-off, spectral centroid, and spectral bandwidth are found to be higher for cough sounds than for speech signals. Spectral flatness levels in cough sounds will rise to 0.22, whereas spectral flux varies between 0.3 and 0.6. The Zero Crossing Rate (ZCR) of most frames of cough sounds is between 0.05 and 0.4. These attributes contribute significant information while characterizing cough sounds.
Comparative Analysis of the wav2vec 2.0 Feature Extractor
Aug 08, 2023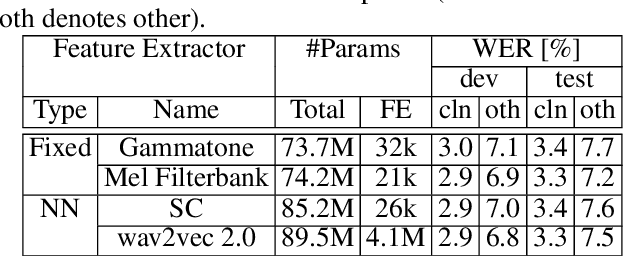
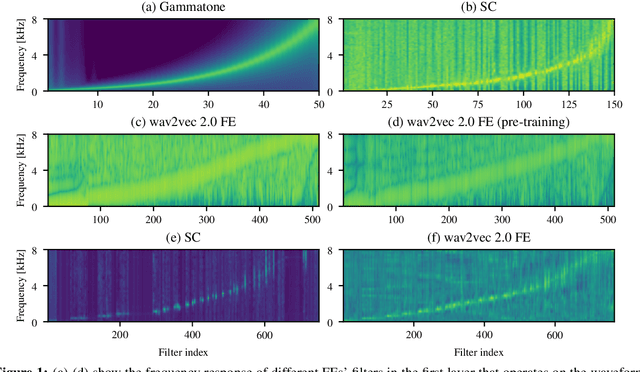
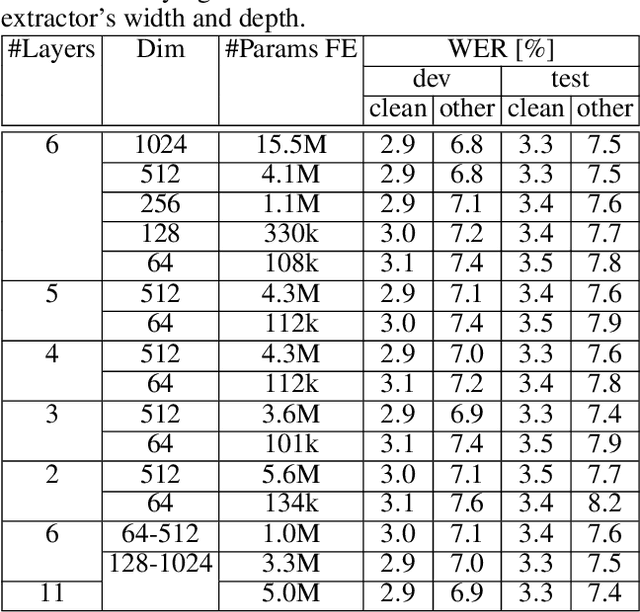
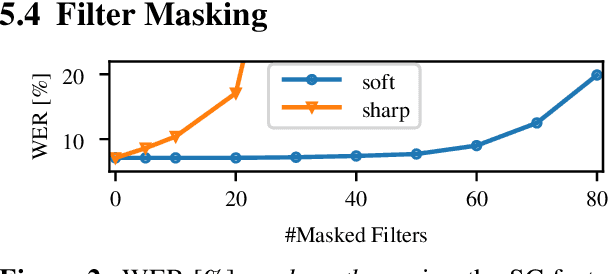
Automatic speech recognition (ASR) systems typically use handcrafted feature extraction pipelines. To avoid their inherent information loss and to achieve more consistent modeling from speech to transcribed text, neural raw waveform feature extractors (FEs) are an appealing approach. Also the wav2vec 2.0 model, which has recently gained large popularity, uses a convolutional FE which operates directly on the speech waveform. However, it is not yet studied extensively in the literature. In this work, we study its capability to replace the standard feature extraction methods in a connectionist temporal classification (CTC) ASR model and compare it to an alternative neural FE. We show that both are competitive with traditional FEs on the LibriSpeech benchmark and analyze the effect of the individual components. Furthermore, we analyze the learned filters and show that the most important information for the ASR system is obtained by a set of bandpass filters.
SMAP: A Novel Heterogeneous Information Framework for Scenario-based Optimal Model Assignment
May 23, 2023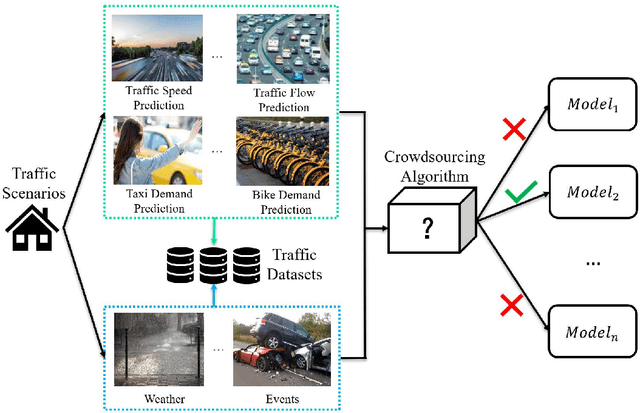
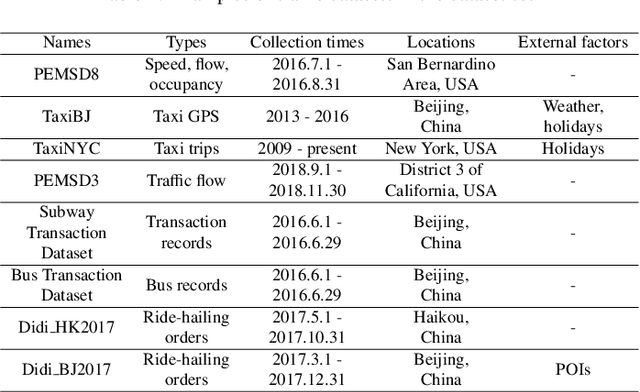
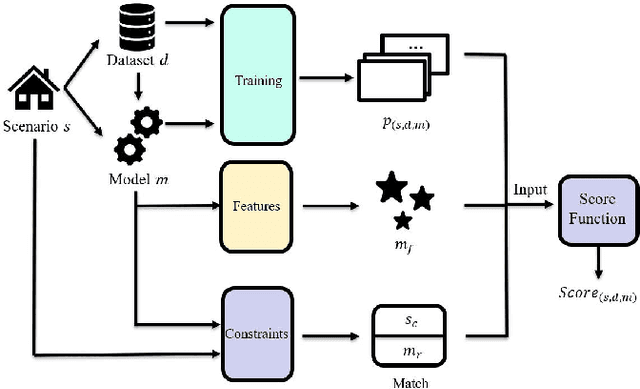
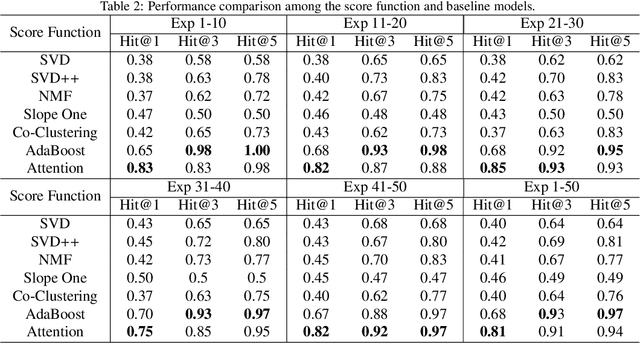
The increasing maturity of big data applications has led to a proliferation of models targeting the same objectives within the same scenarios and datasets. However, selecting the most suitable model that considers model's features while taking specific requirements and constraints into account still poses a significant challenge. Existing methods have focused on worker-task assignments based on crowdsourcing, they neglect the scenario-dataset-model assignment problem. To address this challenge, a new problem named the Scenario-based Optimal Model Assignment (SOMA) problem is introduced and a novel framework entitled Scenario and Model Associative percepts (SMAP) is developed. SMAP is a heterogeneous information framework that can integrate various types of information to intelligently select a suitable dataset and allocate the optimal model for a specific scenario. To comprehensively evaluate models, a new score function that utilizes multi-head attention mechanisms is proposed. Moreover, a novel memory mechanism named the mnemonic center is developed to store the matched heterogeneous information and prevent duplicate matching. Six popular traffic scenarios are selected as study cases and extensive experiments are conducted on a dataset to verify the effectiveness and efficiency of SMAP and the score function.
Uncertainty and Explainable Analysis of Machine Learning Model for Reconstruction of Sonic Slowness Logs
Aug 24, 2023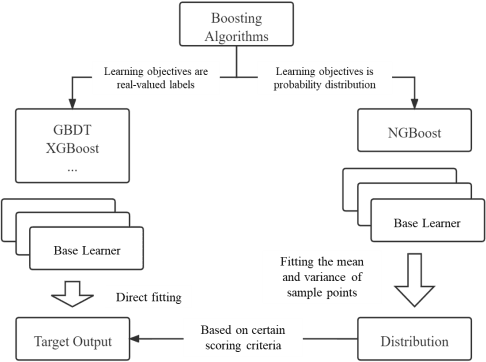
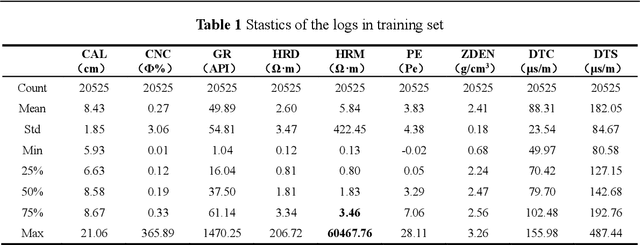
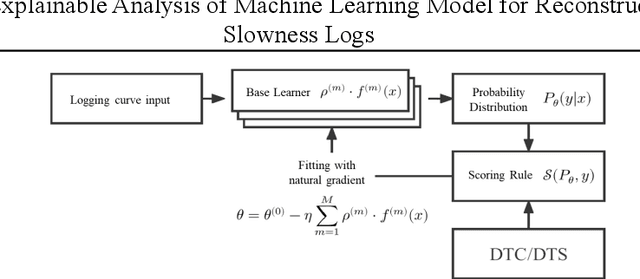
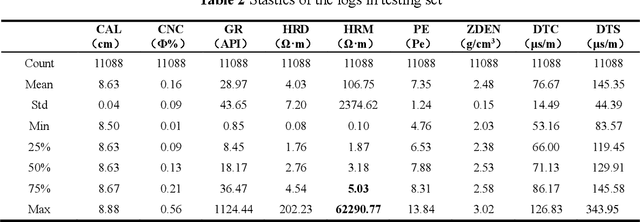
Logs are valuable information for oil and gas fields as they help to determine the lithology of the formations surrounding the borehole and the location and reserves of subsurface oil and gas reservoirs. However, important logs are often missing in horizontal or old wells, which poses a challenge in field applications. In this paper, we utilize data from the 2020 machine learning competition of the SPWLA, which aims to predict the missing compressional wave slowness and shear wave slowness logs using other logs in the same borehole. We employ the NGBoost algorithm to construct an Ensemble Learning model that can predicate the results as well as their uncertainty. Furthermore, we combine the SHAP method to investigate the interpretability of the machine learning model. We compare the performance of the NGBosst model with four other commonly used Ensemble Learning methods, including Random Forest, GBDT, XGBoost, LightGBM. The results show that the NGBoost model performs well in the testing set and can provide a probability distribution for the prediction results. In addition, the variance of the probability distribution of the predicted log can be used to justify the quality of the constructed log. Using the SHAP explainable machine learning model, we calculate the importance of each input log to the predicted results as well as the coupling relationship among input logs. Our findings reveal that the NGBoost model tends to provide greater slowness prediction results when the neutron porosity and gamma ray are large, which is consistent with the cognition of petrophysical models. Furthermore, the machine learning model can capture the influence of the changing borehole caliper on slowness, where the influence of borehole caliper on slowness is complex and not easy to establish a direct relationship. These findings are in line with the physical principle of borehole acoustics.
Self-information Domain-based Neural CSI Compression with Feature Coupling
Apr 30, 2023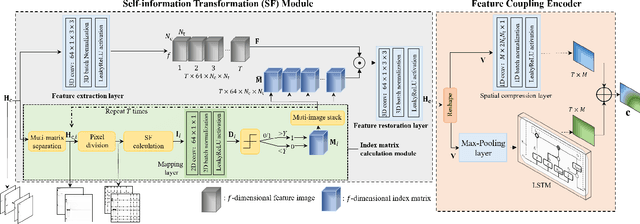
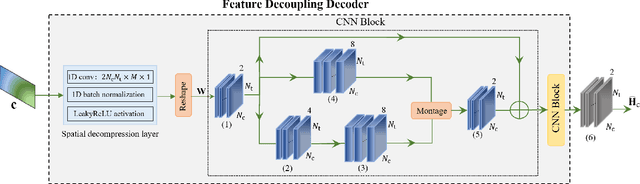
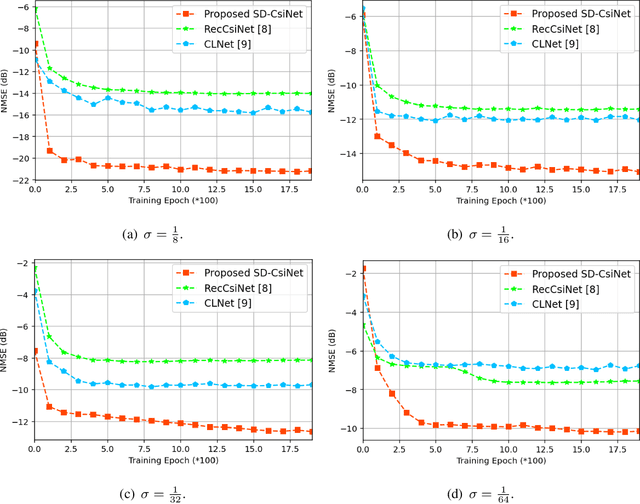

Deep learning (DL)-based channel state information (CSI) feedback methods compressed the CSI matrix by exploiting its delay and angle features straightforwardly, while the measure in terms of information contained in the CSI matrix has rarely been considered. Based on this observation, we introduce self-information as an informative CSI representation from the perspective of information theory, which reflects the amount of information of the original CSI matrix in an explicit way. Then, a novel DL-based network is proposed for temporal CSI compression in the self-information domain, namely SD-CsiNet. The proposed SD-CsiNet projects the raw CSI onto a self-information matrix in the newly-defined self-information domain, extracts both temporal and spatial features of the self-information matrix, and then couples these two features for effective compression. Experimental results verify the effectiveness of the proposed SD-CsiNet by exploiting the self-information of CSI. Particularly for compression ratios 1/8 and 1/16, the SD-CsiNet respectively achieves 7.17 dB and 3.68 dB performance gains compared to state-of-the-art methods.
Deep Learning for Diverse Data Types Steganalysis: A Review
Aug 08, 2023Steganography and steganalysis are two interrelated aspects of the field of information security. Steganography seeks to conceal communications, whereas steganalysis is aimed to either find them or even, if possible, recover the data they contain. Steganography and steganalysis have attracted a great deal of interest, particularly from law enforcement. Steganography is often used by cybercriminals and even terrorists to avoid being captured while in possession of incriminating evidence, even encrypted, since cryptography is prohibited or restricted in many countries. Therefore, knowledge of cutting-edge techniques to uncover concealed information is crucial in exposing illegal acts. Over the last few years, a number of strong and reliable steganography and steganalysis techniques have been introduced in the literature. This review paper provides a comprehensive overview of deep learning-based steganalysis techniques used to detect hidden information within digital media. The paper covers all types of cover in steganalysis, including image, audio, and video, and discusses the most commonly used deep learning techniques. In addition, the paper explores the use of more advanced deep learning techniques, such as deep transfer learning (DTL) and deep reinforcement learning (DRL), to enhance the performance of steganalysis systems. The paper provides a systematic review of recent research in the field, including data sets and evaluation metrics used in recent studies. It also presents a detailed analysis of DTL-based steganalysis approaches and their performance on different data sets. The review concludes with a discussion on the current state of deep learning-based steganalysis, challenges, and future research directions.