 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuConTE: Dual-Granularity Text Encoder with Topology-Constrained Attention for Text-attributed Graphs
Apr 19, 2026Text-attributed graphs integrate semantic information of node texts with topological structure, offering significant value in various applications such as document classification and information extraction. Existing approaches typically encode textual content using language models (LMs), followed by graph neural networks (GNNs) to process structural information. However, during the LM-based text encoding phase, most methods not only perform semantic interaction solely at the word-token granularity, but also neglect the structural dependencies among texts from different nodes. In this work, we propose DuConTE, a dual-granularity text encoder with topology-constrained attention. The model employs a cascaded architecture of two pretrained LMs, encoding semantics first at the word-token granularity and then at the node granularity. During the self-attention computation in each LM, we dynamically adjust the attention mask matrix based on node connectivity, guiding the model to learn semantic correlations informed by the graph structure. Furthermore, when composing node representations from word-token embeddings, we separately evaluate the importance of tokens under the center-node context and the neighborhood context, enabling the capture of more contextually relevant semantic information. Extensive experiments on multiple benchmark datasets demonstrate that DuConTE achieves state-of-the-art performance on the majority of them.
SMAP: A Novel Heterogeneous Information Framework for Scenario-based Optimal Model Assignment
May 23, 2023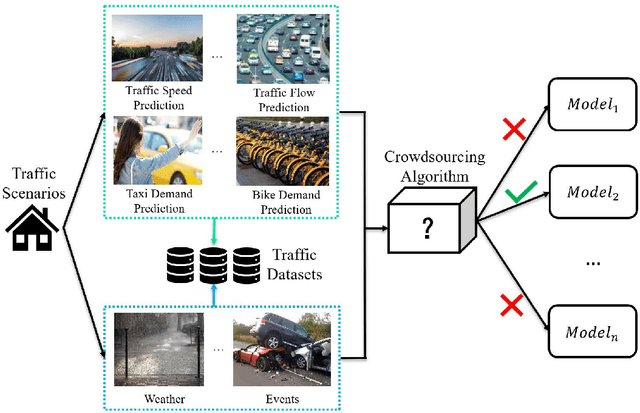
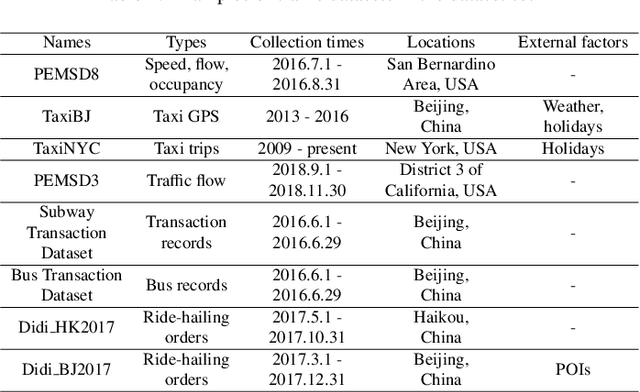
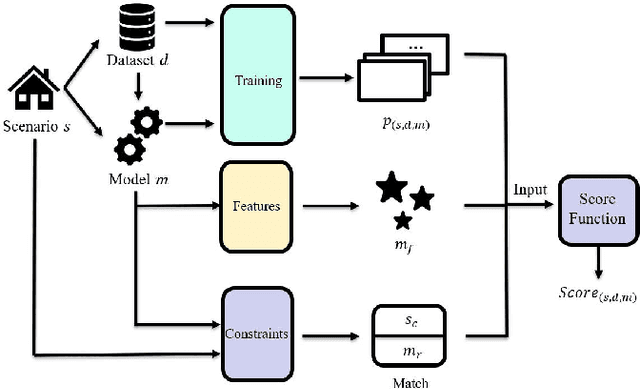
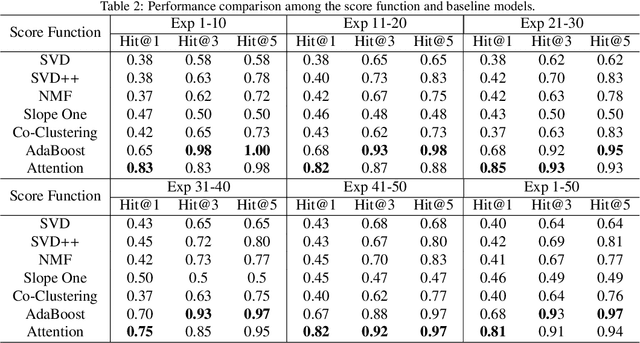
The increasing maturity of big data applications has led to a proliferation of models targeting the same objectives within the same scenarios and datasets. However, selecting the most suitable model that considers model's features while taking specific requirements and constraints into account still poses a significant challenge. Existing methods have focused on worker-task assignments based on crowdsourcing, they neglect the scenario-dataset-model assignment problem. To address this challenge, a new problem named the Scenario-based Optimal Model Assignment (SOMA) problem is introduced and a novel framework entitled Scenario and Model Associative percepts (SMAP) is developed. SMAP is a heterogeneous information framework that can integrate various types of information to intelligently select a suitable dataset and allocate the optimal model for a specific scenario. To comprehensively evaluate models, a new score function that utilizes multi-head attention mechanisms is proposed. Moreover, a novel memory mechanism named the mnemonic center is developed to store the matched heterogeneous information and prevent duplicate matching. Six popular traffic scenarios are selected as study cases and extensive experiments are conducted on a dataset to verify the effectiveness and efficiency of SMAP and the score function.