 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semantic Communications with Explicit Semantic Base for Image Transmission
Aug 12, 2023
Semantic communications, aiming at ensuring the successful delivery of the meaning of information, are expected to be one of the potential techniques for the next generation communications. However, the knowledge forming and synchronizing mechanism that enables semantic communication systems to extract and interpret the semantics of information according to the communication intents is still immature. In this paper, we propose a semantic image transmission framework with explicit semantic base (Seb), where Sebs are generated and employed as the knowledge shared between the transmitter and the receiver with flexible granularity. To represent images with Sebs, a novel Seb-based reference image generator is proposed to generate Sebs and then decompose the transmitted images. To further encode/decode the residual information for precise image reconstruction, a Seb-based image encoder/decoder is proposed. The key components of the proposed framework are optimized jointly by end-to-end (E2E) training, where the loss function is dedicated designed to tackle the problem of nondifferentiable operation in Seb-based reference image generator by introducing a gradient approximation mechanism. Extensive experiments show that the proposed framework outperforms state-of-art works by 0.5 - 1.5 dB in peak signal-to-noise ratio (PSNR) w.r.t. different signal-to-noise ratio (SNR).
A Unified Transformer-based Network for multimodal Emotion Recognition
Aug 27, 2023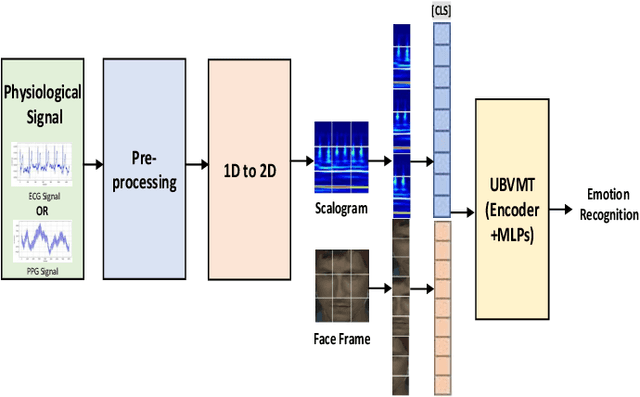

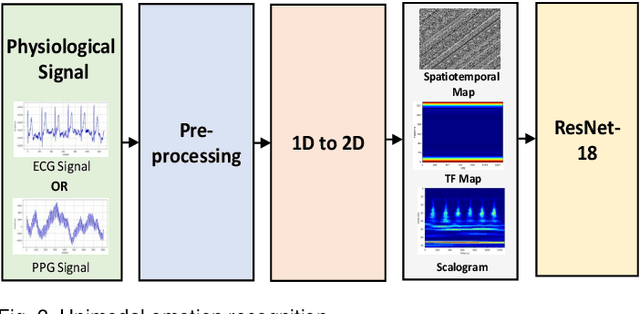
The development of transformer-based models has resulted in significant advances in addressing various vision and NLP-based research challenges. However, the progress made in transformer-based methods has not been effectively applied to biosensing research. This paper presents a novel Unified Biosensor-Vision Multi-modal Transformer-based (UBVMT) method to classify emotions in an arousal-valence space by combining a 2D representation of an ECG/PPG signal with the face information. To achieve this goal, we first investigate and compare the unimodal emotion recognition performance of three image-based representations of the ECG/PPG signal. We then present our UBVMT network which is trained to perform emotion recognition by combining the 2D image-based representation of the ECG/PPG signal and the facial expression features. Our unified transformer model consists of homogeneous transformer blocks that take as an input the 2D representation of the ECG/PPG signal and the corresponding face frame for emotion representation learning with minimal modality-specific design. Our UBVMT model is trained by reconstructing masked patches of video frames and 2D images of ECG/PPG signals, and contrastive modeling to align face and ECG/PPG data. Extensive experiments on the MAHNOB-HCI and DEAP datasets show that our Unified UBVMT-based model produces comparable results to the state-of-the-art techniques.
Balanced Representation Learning for Long-tailed Skeleton-based Action Recognition
Aug 27, 2023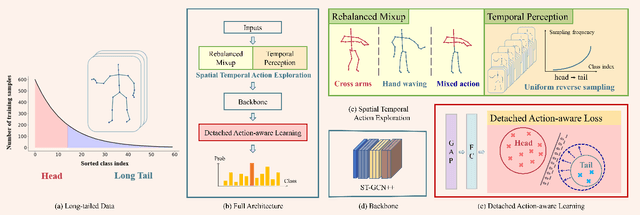
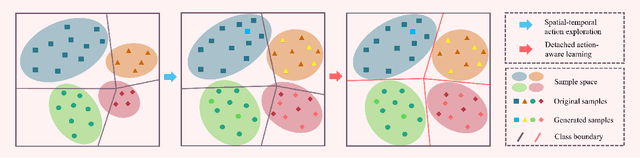
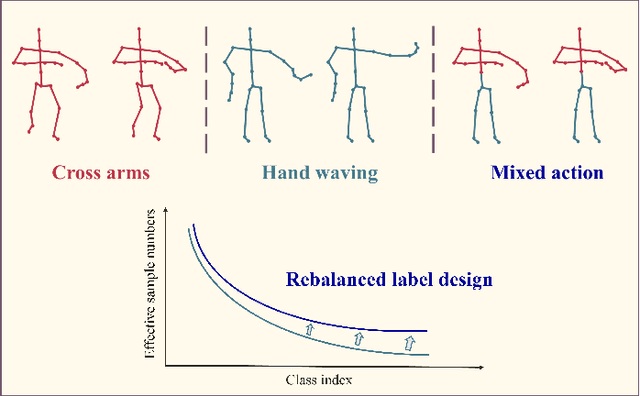
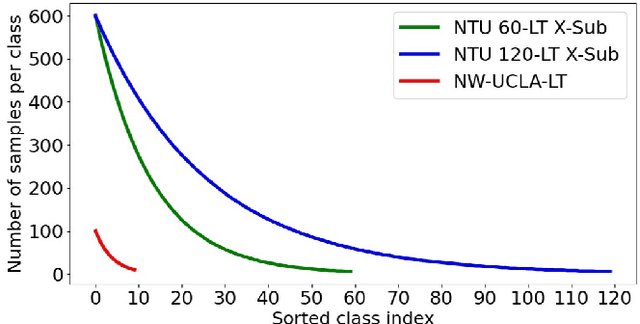
Skeleton-based action recognition has recently made significant progress. However, data imbalance is still a great challenge in real-world scenarios. The performance of current action recognition algorithms declines sharply when training data suffers from heavy class imbalance. The imbalanced data actually degrades the representations learned by these methods and becomes the bottleneck for action recognition. How to learn unbiased representations from imbalanced action data is the key to long-tailed action recognition. In this paper, we propose a novel balanced representation learning method to address the long-tailed problem in action recognition. Firstly, a spatial-temporal action exploration strategy is presented to expand the sample space effectively, generating more valuable samples in a rebalanced manner. Secondly, we design a detached action-aware learning schedule to further mitigate the bias in the representation space. The schedule detaches the representation learning of tail classes from training and proposes an action-aware loss to impose more effective constraints. Additionally, a skip-modal representation is proposed to provide complementary structural information. The proposed method is validated on four skeleton datasets, NTU RGB+D 60, NTU RGB+D 120, NW-UCLA, and Kinetics. It not only achieves consistently large improvement compared to the state-of-the-art (SOTA) methods, but also demonstrates a superior generalization capacity through extensive experiments. Our code is available at https://github.com/firework8/BRL.
Practical Edge Detection via Robust Collaborative Learning
Aug 27, 2023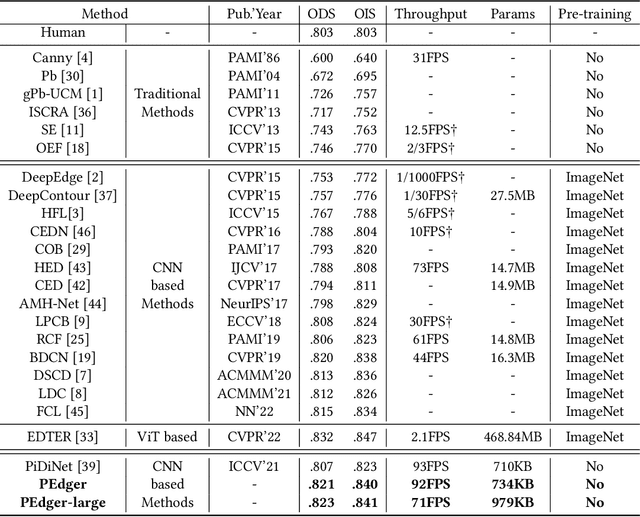

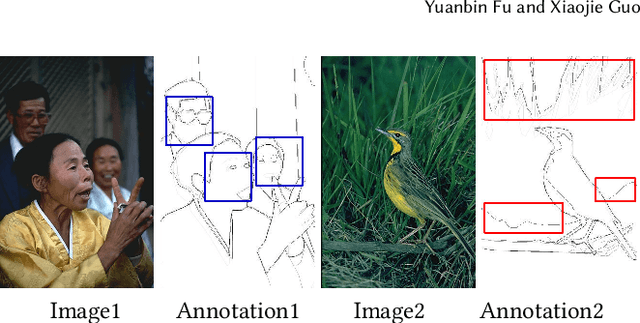
Edge detection, as a core component in a wide range of visionoriented tasks, is to identify object boundaries and prominent edges in natural images. An edge detector is desired to be both efficient and accurate for practical use. To achieve the goal, two key issues should be concerned: 1) How to liberate deep edge models from inefficient pre-trained backbones that are leveraged by most existing deep learning methods, for saving the computational cost and cutting the model size; and 2) How to mitigate the negative influence from noisy or even wrong labels in training data, which widely exist in edge detection due to the subjectivity and ambiguity of annotators, for the robustness and accuracy. In this paper, we attempt to simultaneously address the above problems via developing a collaborative learning based model, termed PEdger. The principle behind our PEdger is that, the information learned from different training moments and heterogeneous (recurrent and non recurrent in this work) architectures, can be assembled to explore robust knowledge against noisy annotations, even without the help of pre-training on extra data. Extensive ablation studies together with quantitative and qualitative experimental comparisons on the BSDS500 and NYUD datasets are conducted to verify the effectiveness of our design, and demonstrate its superiority over other competitors in terms of accuracy, speed, and model size. Codes can be found at https://github.co/ForawardStar/PEdger.
FFEINR: Flow Feature-Enhanced Implicit Neural Representation for Spatio-temporal Super-Resolution
Aug 27, 2023Large-scale numerical simulations are capable of generating data up to terabytes or even petabytes. As a promising method of data reduction, super-resolution (SR) has been widely studied in the scientific visualization community. However, most of them are based on deep convolutional neural networks (CNNs) or generative adversarial networks (GANs) and the scale factor needs to be determined before constructing the network. As a result, a single training session only supports a fixed factor and has poor generalization ability. To address these problems, this paper proposes a Feature-Enhanced Implicit Neural Representation (FFEINR) for spatio-temporal super-resolution of flow field data. It can take full advantage of the implicit neural representation in terms of model structure and sampling resolution. The neural representation is based on a fully connected network with periodic activation functions, which enables us to obtain lightweight models. The learned continuous representation can decode the low-resolution flow field input data to arbitrary spatial and temporal resolutions, allowing for flexible upsampling. The training process of FFEINR is facilitated by introducing feature enhancements for the input layer, which complements the contextual information of the flow field. To demonstrate the effectiveness of the proposed method, a series of experiments are conducted on different datasets by setting different hyperparameters. The results show that FFEINR achieves significantly better results than the trilinear interpolation method.
Viia-hand: a Reach-and-grasp Restoration System Integrating Voice interaction, Computer vision and Auditory feedback for Blind Amputees
Aug 14, 2023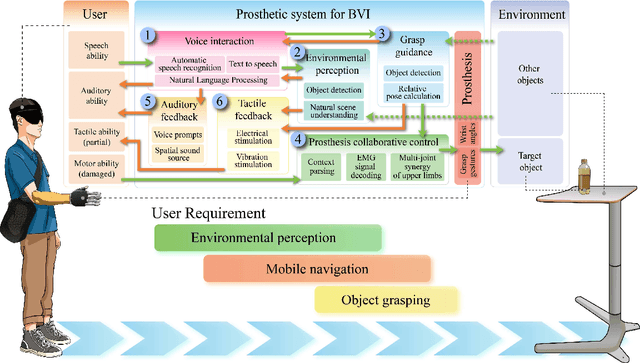
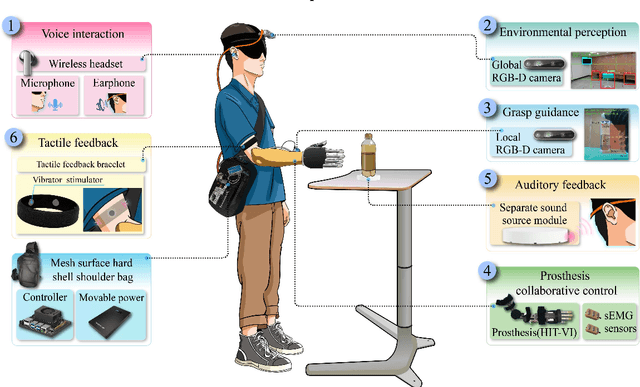

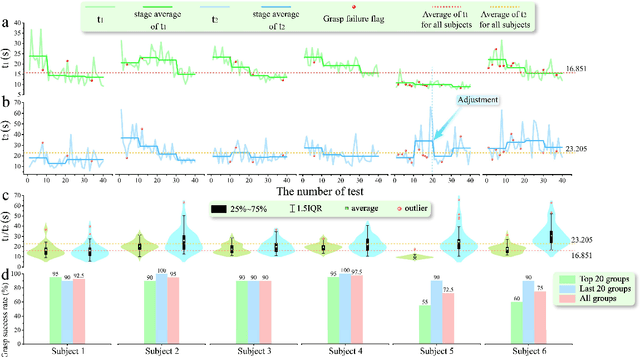
Visual feedback plays a crucial role in the process of amputation patients completing grasping in the field of prosthesis control. However, for blind and visually impaired (BVI) amputees, the loss of both visual and grasping abilities makes the "easy" reach-and-grasp task a feasible challenge. In this paper, we propose a novel multi-sensory prosthesis system helping BVI amputees with sensing, navigation and grasp operations. It combines modules of voice interaction, environmental perception, grasp guidance, collaborative control, and auditory/tactile feedback. In particular, the voice interaction module receives user instructions and invokes other functional modules according to the instructions. The environmental perception and grasp guidance module obtains environmental information through computer vision, and feedbacks the information to the user through auditory feedback modules (voice prompts and spatial sound sources) and tactile feedback modules (vibration stimulation). The prosthesis collaborative control module obtains the context information of the grasp guidance process and completes the collaborative control of grasp gestures and wrist angles of prosthesis in conjunction with the user's control intention in order to achieve stable grasp of various objects. This paper details a prototyping design (named viia-hand) and presents its preliminary experimental verification on healthy subjects completing specific reach-and-grasp tasks. Our results showed that, with the help of our new design, the subjects were able to achieve a precise reach and reliable grasp of the target objects in a relatively cluttered environment. Additionally, the system is extremely user-friendly, as users can quickly adapt to it with minimal training.
Recurrent Self-Supervised Video Denoising with Denser Receptive Field
Aug 07, 2023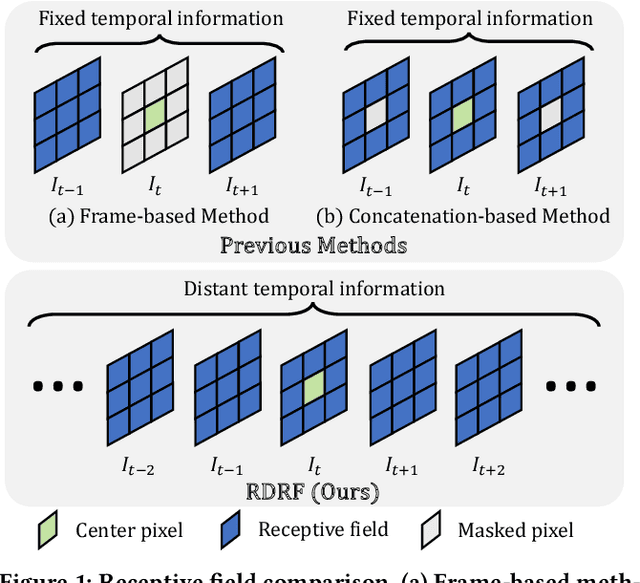
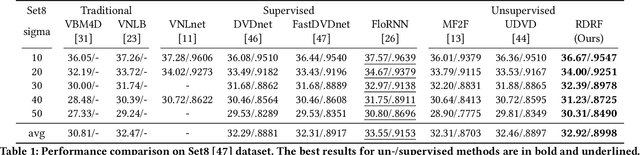
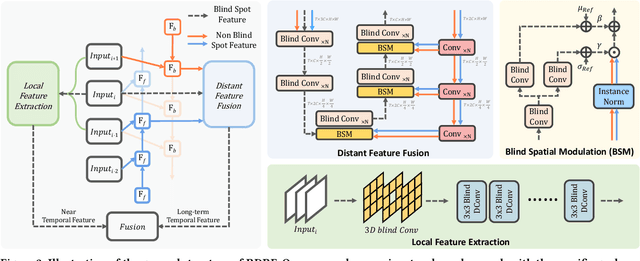
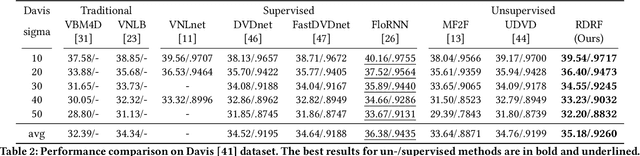
Self-supervised video denoising has seen decent progress through the use of blind spot networks. However, under their blind spot constraints, previous self-supervised video denoising methods suffer from significant information loss and texture destruction in either the whole reference frame or neighbor frames, due to their inadequate consideration of the receptive field. Moreover, the limited number of available neighbor frames in previous methods leads to the discarding of distant temporal information. Nonetheless, simply adopting existing recurrent frameworks does not work, since they easily break the constraints on the receptive field imposed by self-supervision. In this paper, we propose RDRF for self-supervised video denoising, which not only fully exploits both the reference and neighbor frames with a denser receptive field, but also better leverages the temporal information from both local and distant neighbor features. First, towards a comprehensive utilization of information from both reference and neighbor frames, RDRF realizes a denser receptive field by taking more neighbor pixels along the spatial and temporal dimensions. Second, it features a self-supervised recurrent video denoising framework, which concurrently integrates distant and near-neighbor temporal features. This enables long-term bidirectional information aggregation, while mitigating error accumulation in the plain recurrent framework. Our method exhibits superior performance on both synthetic and real video denoising datasets. Codes will be available at https://github.com/Wang-XIaoDingdd/RDRF.
Dynamic Kernel-Based Adaptive Spatial Aggregation for Learned Image Compression
Aug 17, 2023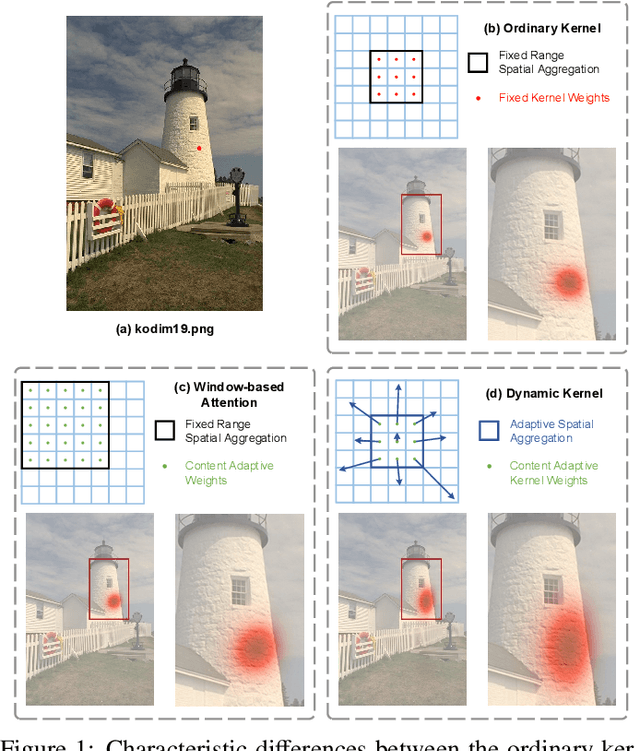
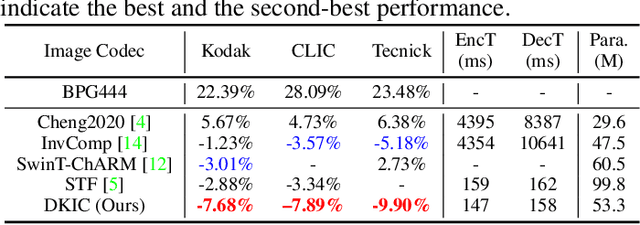
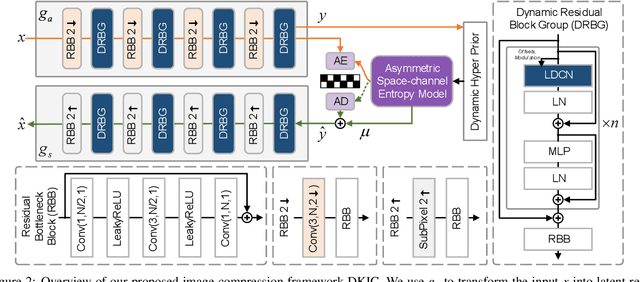
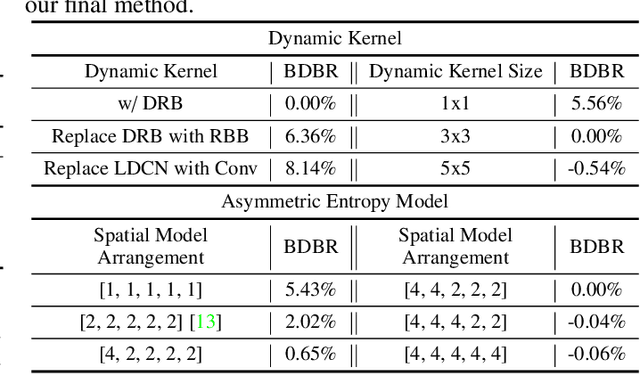
Learned image compression methods have shown superior rate-distortion performance and remarkable potential compared to traditional compression methods. Most existing learned approaches use stacked convolution or window-based self-attention for transform coding, which aggregate spatial information in a fixed range. In this paper, we focus on extending spatial aggregation capability and propose a dynamic kernel-based transform coding. The proposed adaptive aggregation generates kernel offsets to capture valid information in the content-conditioned range to help transform. With the adaptive aggregation strategy and the sharing weights mechanism, our method can achieve promising transform capability with acceptable model complexity. Besides, according to the recent progress of entropy model, we define a generalized coarse-to-fine entropy model, considering the coarse global context, the channel-wise, and the spatial context. Based on it, we introduce dynamic kernel in hyper-prior to generate more expressive global context. Furthermore, we propose an asymmetric spatial-channel entropy model according to the investigation of the spatial characteristics of the grouped latents. The asymmetric entropy model aims to reduce statistical redundancy while maintaining coding efficiency. Experimental results demonstrate that our method achieves superior rate-distortion performance on three benchmarks compared to the state-of-the-art learning-based methods.
CONVERT:Contrastive Graph Clustering with Reliable Augmentation
Aug 17, 2023
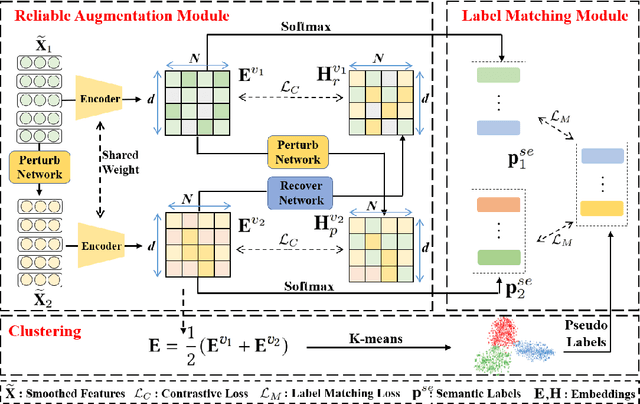
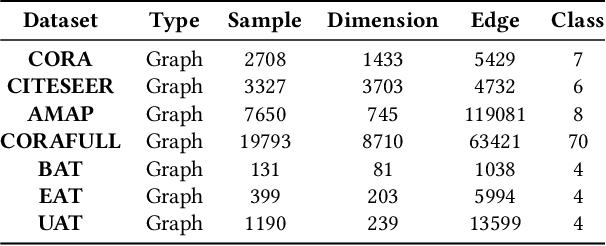
Contrastive graph node clustering via learnable data augmentation is a hot research spot in the field of unsupervised graph learning. The existing methods learn the sampling distribution of a pre-defined augmentation to generate data-driven augmentations automatically. Although promising clustering performance has been achieved, we observe that these strategies still rely on pre-defined augmentations, the semantics of the augmented graph can easily drift. The reliability of the augmented view semantics for contrastive learning can not be guaranteed, thus limiting the model performance. To address these problems, we propose a novel CONtrastiVe Graph ClustEring network with Reliable AugmenTation (COVERT). Specifically, in our method, the data augmentations are processed by the proposed reversible perturb-recover network. It distills reliable semantic information by recovering the perturbed latent embeddings. Moreover, to further guarantee the reliability of semantics, a novel semantic loss is presented to constrain the network via quantifying the perturbation and recovery. Lastly, a label-matching mechanism is designed to guide the model by clustering information through aligning the semantic labels and the selected high-confidence clustering pseudo labels. Extensive experimental results on seven datasets demonstrate the effectiveness of the proposed method. We release the code and appendix of CONVERT at https://github.com/xihongyang1999/CONVERT on GitHub.
Reviewing Evolution of Learning Functions and Semantic Information Measures for Understanding Deep Learning
May 23, 2023A new trend in deep learning, represented by Mutual Information Neural Estimation (MINE) and Information Noise Contrast Estimation (InfoNCE), is emerging. In this trend, similarity functions and Estimated Mutual Information (EMI) are used as learning and objective functions. Coincidentally, EMI is essentially the same as Semantic Mutual Information (SeMI) proposed by the author 30 years ago. This paper first reviews the evolutionary histories of semantic information measures and learning functions. Then, it briefly introduces the author's semantic information G theory with the rate-fidelity function R(G) (G denotes SeMI, and R(G) extends R(D)) and its applications to multi-label learning, the maximum Mutual Information (MI) classification, and mixture models. Then it discusses how we should understand the relationship between SeMI and Shan-non's MI, two generalized entropies (fuzzy entropy and coverage entropy), Autoencoders, Gibbs distributions, and partition functions from the perspective of the R(G) function or the G theory. An important conclusion is that mixture models and Restricted Boltzmann Machines converge because SeMI is maximized, and Shannon's MI is minimized, making information efficiency G/R close to 1. A potential opportunity is to simplify deep learning by using Gaussian channel mixture models for pre-training deep neural networks' latent layers without considering gradients. It also discusses how the SeMI measure is used as the reward function (reflecting purposiveness) for reinforcement learning. The G theory helps interpret deep learning but is far from enough. Combining semantic information theory and deep learning will accelerate their development.