 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReviewing Evolution of Learning Functions and Semantic Information Measures for Understanding Deep Learning
May 23, 2023A new trend in deep learning, represented by Mutual Information Neural Estimation (MINE) and Information Noise Contrast Estimation (InfoNCE), is emerging. In this trend, similarity functions and Estimated Mutual Information (EMI) are used as learning and objective functions. Coincidentally, EMI is essentially the same as Semantic Mutual Information (SeMI) proposed by the author 30 years ago. This paper first reviews the evolutionary histories of semantic information measures and learning functions. Then, it briefly introduces the author's semantic information G theory with the rate-fidelity function R(G) (G denotes SeMI, and R(G) extends R(D)) and its applications to multi-label learning, the maximum Mutual Information (MI) classification, and mixture models. Then it discusses how we should understand the relationship between SeMI and Shan-non's MI, two generalized entropies (fuzzy entropy and coverage entropy), Autoencoders, Gibbs distributions, and partition functions from the perspective of the R(G) function or the G theory. An important conclusion is that mixture models and Restricted Boltzmann Machines converge because SeMI is maximized, and Shannon's MI is minimized, making information efficiency G/R close to 1. A potential opportunity is to simplify deep learning by using Gaussian channel mixture models for pre-training deep neural networks' latent layers without considering gradients. It also discusses how the SeMI measure is used as the reward function (reflecting purposiveness) for reinforcement learning. The G theory helps interpret deep learning but is far from enough. Combining semantic information theory and deep learning will accelerate their development.
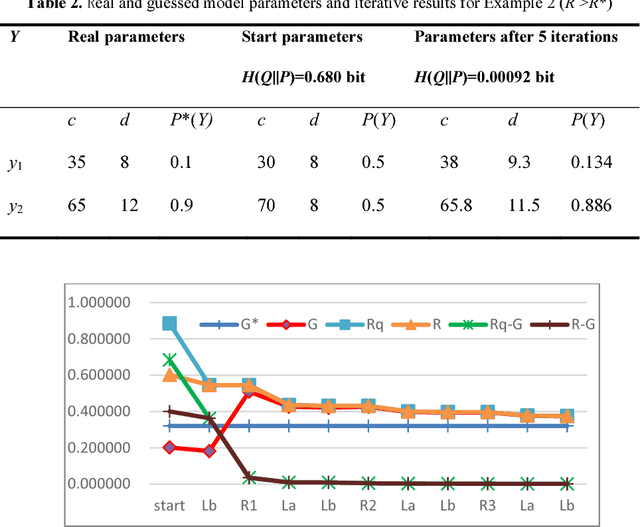
Understanding and Accelerating EM Algorithm's Convergence by Fair Competition Principle and Rate-Verisimilitude Function
Apr 21, 2021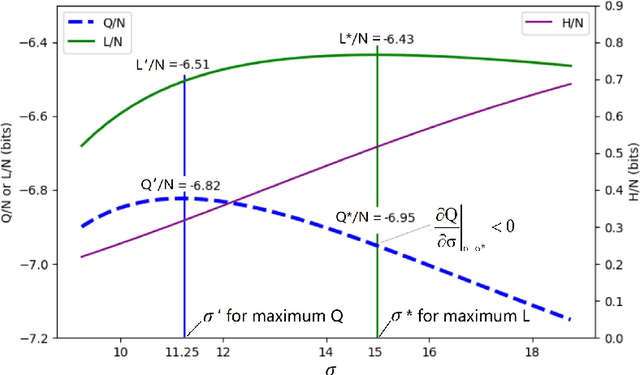
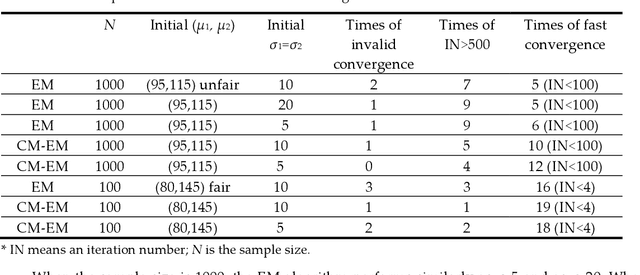
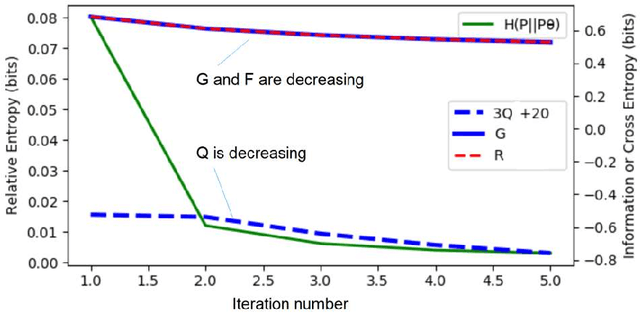
Why can the Expectation-Maximization (EM) algorithm for mixture models converge? Why can different initial parameters cause various convergence difficulties? The Q-L synchronization theory explains that the observed data log-likelihood L and the complete data log-likelihood Q are positively correlated; we can achieve maximum L by maximizing Q. According to this theory, the Deterministic Annealing EM (DAEM) algorithm's authors make great efforts to eliminate locally maximal Q for avoiding L's local convergence. However, this paper proves that in some cases, Q may and should decrease for L to increase; slow or local convergence exists only because of small samples and unfair competition. This paper uses marriage competition to explain different convergence difficulties and proposes the Fair Competition Principle (FCP) with an initialization map for improving initializations. It uses the rate-verisimilitude function, extended from the rate-distortion function, to explain the convergence of the EM and improved EM algorithms. This convergence proof adopts variational and iterative methods that Shannon et al. used for analyzing rate-distortion functions. The initialization map can vastly save both algorithms' running times for binary Gaussian mixtures. The FCP and the initialization map are useful for complicated mixtures but not sufficient; we need further studies for specific methods.
Fair Marriage Principle and Initialization Map for the EM Algorithm
Jul 25, 2020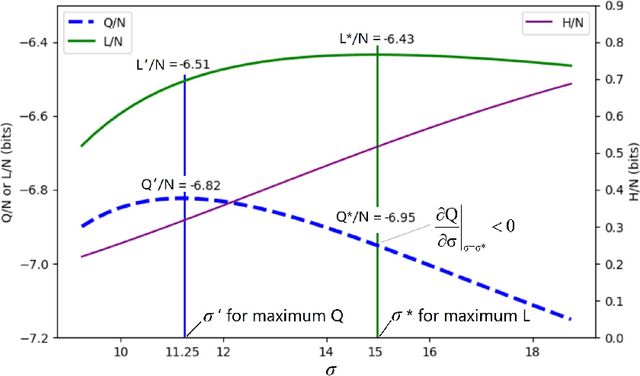
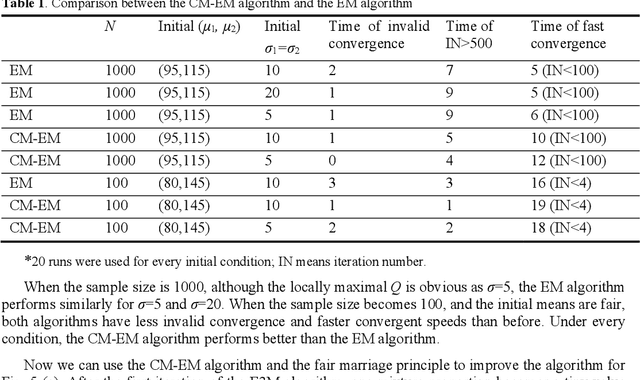
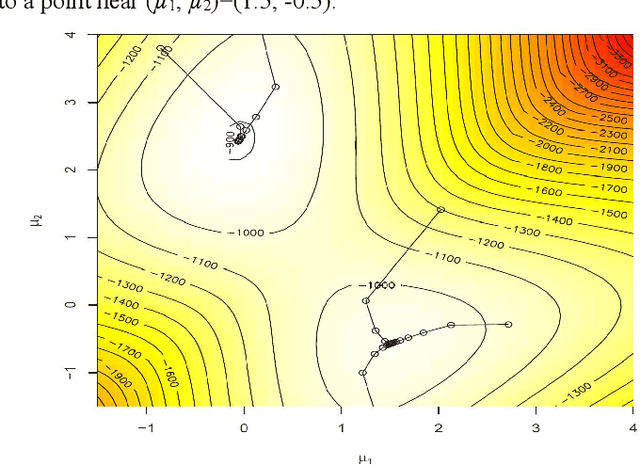
The popular convergence theory of the EM algorithm explains that the observed incomplete data log-likelihood L and the complete data log-likelihood Q are positively correlated, and we can maximize L by maximizing Q. The Deterministic Annealing EM (DAEM) algorithm was hence proposed for avoiding locally maximal Q. This paper provides different conclusions: 1) The popular convergence theory is wrong; 2) The locally maximal Q can affect the convergent speed, but cannot block the global convergence; 3) Like marriage competition, unfair competition between two components may vastly decrease the globally convergent speed; 4) Local convergence exists because the sample is too small, and unfair competition exists; 5) An improved EM algorithm, called the Channel Matching (CM) EM algorithm, can accelerate the global convergence. This paper provides an initialization map with two means as two axes for the example of a binary Gaussian mixture studied by the authors of DAEM algorithm. This map can tell how fast the convergent speeds are for different initial means and why points in some areas are not suitable as initial points. A two-dimensional example indicates that the big sample or the fair initialization can avoid global convergence. For more complicated mixture models, we need further study to convert the fair marriage principle to specific methods for the initializations.
Channels' Confirmation and Predictions' Confirmation: from the Medical Test to the Raven Paradox
Jan 17, 2020
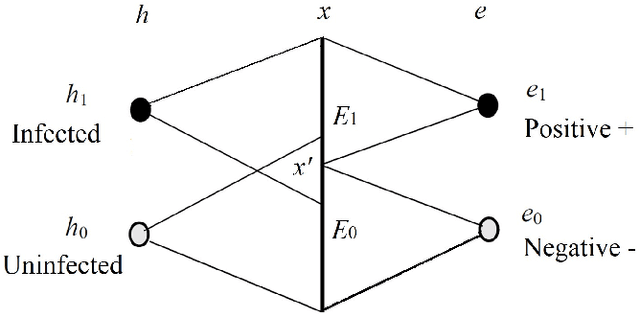
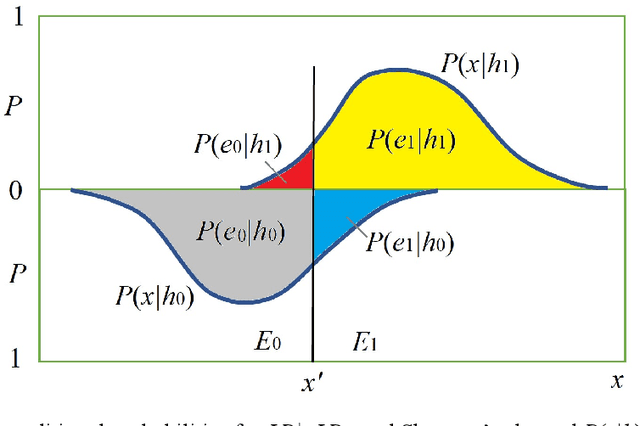
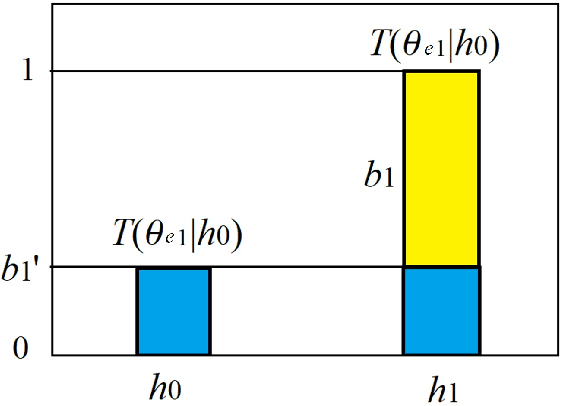
After long arguments between positivism and falsificationism, the verification of universal hypotheses was replaced with the confirmation of uncertain major premises. Unfortunately, Hemple discovered the Raven Paradox (RP). Then, Carnap used the logical probability increment as the confirmation measure. So far, many confirmation measures have been proposed. Measure F among them proposed by Kemeny and Oppenheim possesses symmetries and asymmetries proposed by Elles and Fitelson, monotonicity proposed by Greco et al., and normalizing property suggested by many researchers. Based on the semantic information theory, a measure b* similar to F is derived from the medical test. Like the likelihood ratio, b* and F can only indicate the quality of channels or the testing means instead of the quality of probability predictions. And, it is still not easy to use b*, F, or another measure to clarify the RP. For this reason, measure c* similar to the correct rate is derived. The c* has the simple form: (a-c)/max(a, c); it supports the Nicod Criterion and undermines the Equivalence Condition, and hence, can be used to eliminate the RP. Some examples are provided to show why it is difficult to use one of popular confirmation measures to eliminate the RP. Measure F, b*, and c* indicate that fewer counterexamples' existence is more essential than more positive examples' existence, and hence, are compatible with Popper's falsification thought.
The CM Algorithm for the Maximum Mutual Information Classifications of Unseen Instances
Jan 28, 2019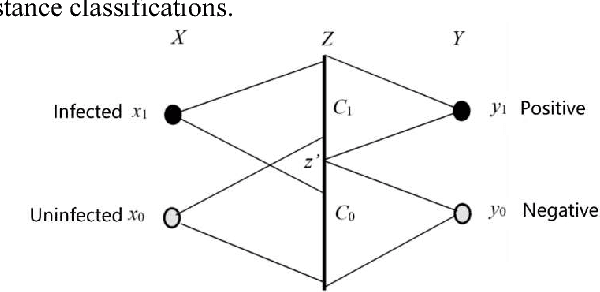
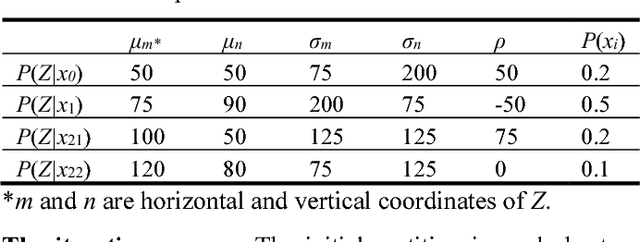
The Maximum Mutual Information (MMI) criterion is different from the Least Error Rate (LER) criterion. It can reduce failing to report small probability events. This paper introduces the Channels Matching (CM) algorithm for the MMI classifications of unseen instances. It also introduces some semantic information methods, which base the CM algorithm. In the CM algorithm, label learning is to let the semantic channel match the Shannon channel (Matching I) whereas classifying is to let the Shannon channel match the semantic channel (Matching II). We can achieve the MMI classifications by repeating Matching I and II. For low-dimensional feature spaces, we only use parameters to construct n likelihood functions for n different classes (rather than to construct partitioning boundaries as gradient descent) and expresses the boundaries by numerical values. Without searching in parameter spaces, the computation of the CM algorithm for low-dimensional feature spaces is very simple and fast. Using a two-dimensional example, we test the speed and reliability of the CM algorithm by different initial partitions. For most initial partitions, two iterations can make the mutual information surpass 99% of the convergent MMI. The analysis indicates that for high-dimensional feature spaces, we may combine the CM algorithm with neural networks to improve the MMI classifications for faster and more reliable convergence.
From the EM Algorithm to the CM-EM Algorithm for Global Convergence of Mixture Models
Oct 26, 2018
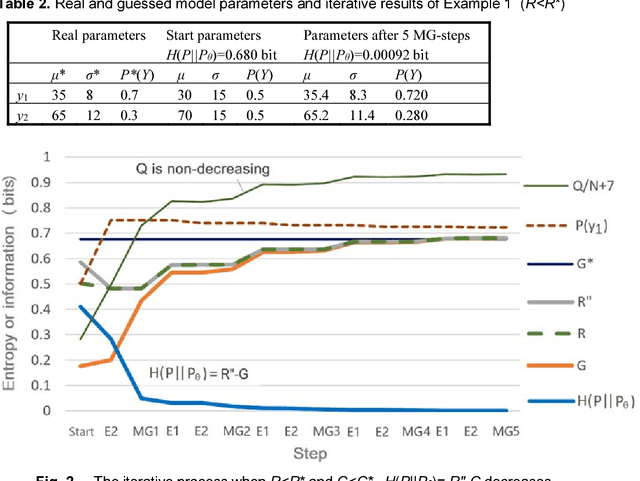
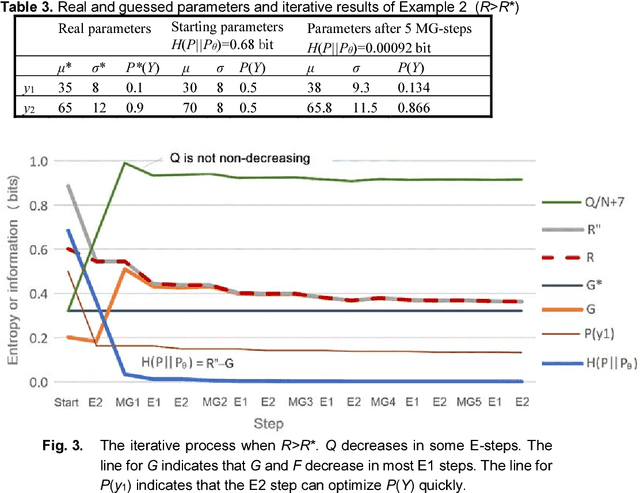
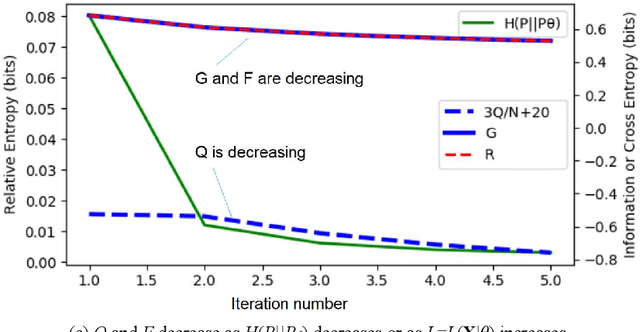
The Expectation-Maximization (EM) algorithm for mixture models often results in slow or invalid convergence. The popular convergence proof affirms that the likelihood increases with Q; Q is increasing in the M -step and non-decreasing in the E-step. The author found that (1) Q may and should decrease in some E-steps; (2) The Shannon channel from the E-step is improper and hence the expectation is improper. The author proposed the CM-EM algorithm (CM means Channel's Matching), which adds a step to optimize the mixture ratios for the proper Shannon channel and maximizes G, average log-normalized-likelihood, in the M-step. Neal and Hinton's Maximization-Maximization (MM) algorithm use F instead of Q to speed the convergence. Maximizing G is similar to maximizing F. The new convergence proof is similar to Beal's proof with the variational method. It first proves that the minimum relative entropy equals the minimum R-G (R is mutual information), then uses variational and iterative methods that Shannon et al. use for rate-distortion functions to prove the global convergence. Some examples show that Q and F should and may decrease in some E-steps. For the same example, the EM, MM, and CM-EM algorithms need about 36, 18, and 9 iterations respectively.
From Bayesian Inference to Logical Bayesian Inference: A New Mathematical Frame for Semantic Communication and Machine Learning
Sep 03, 2018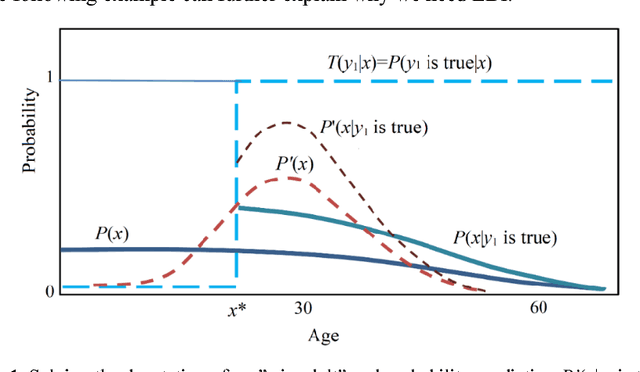
Bayesian Inference (BI) uses the Bayes' posterior whereas Logical Bayesian Inference (LBI) uses the truth function or membership function as the inference tool. LBI was proposed because BI was not compatible with the classical Bayes' prediction and didn't use logical probability and hence couldn't express semantic meaning. In LBI, statistical probability and logical probability are strictly distinguished, used at the same time, and linked by the third kind of Bayes' Theorem. The Shannon channel consists of a set of transition probability functions whereas the semantic channel consists of a set of truth functions. When a sample is large enough, we can directly derive the semantic channel from Shannon's channel. Otherwise, we can use parameters to construct truth functions and use the Maximum Semantic Information (MSI) criterion to optimize the truth functions. The MSI criterion is equivalent to the Maximum Likelihood (ML) criterion, and compatible with the Regularized Least Square (RLS) criterion. By matching the two channels one with another, we can obtain the Channels' Matching (CM) algorithm. This algorithm can improve multi-label classifications, maximum likelihood estimations (including unseen instance classifications), and mixture models. In comparison with BI, LBI 1) uses the prior P(X) of X instead of that of Y or {\theta} and fits cases where the source P(X) changes, 2) can be used to solve the denotations of labels, and 3) is more compatible with the classical Bayes' prediction and likelihood method. LBI also provides a confirmation measure between -1 and 1 for induction.
Semantic Channel and Shannon's Channel Mutually Match for Multi-Label Classification
May 02, 2018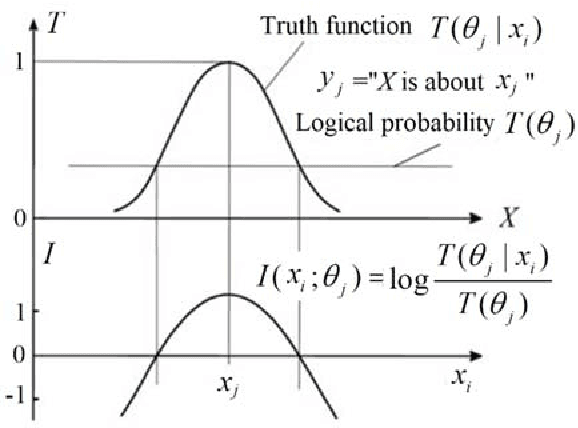
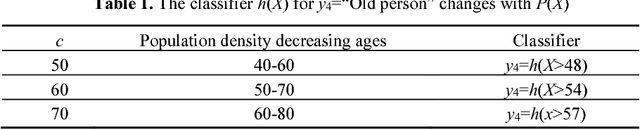
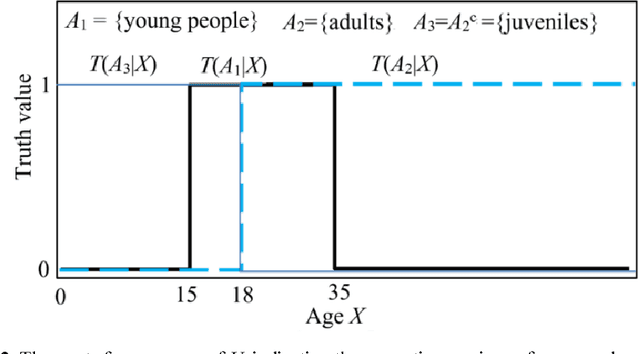
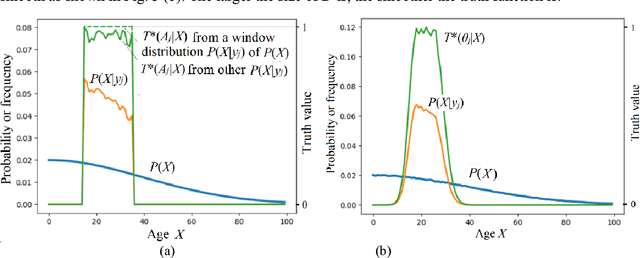
A group of transition probability functions form a Shannon's channel whereas a group of truth functions form a semantic channel. Label learning is to let semantic channels match Shannon's channels and label selection is to let Shannon's channels match semantic channels. The Channel Matching (CM) algorithm is provided for multi-label classification. This algorithm adheres to maximum semantic information criterion which is compatible with maximum likelihood criterion and regularized least squares criterion. If samples are very large, we can directly convert Shannon's channels into semantic channels by the third kind of Bayes' theorem; otherwise, we can train truth functions with parameters by sampling distributions. A label may be a Boolean function of some atomic labels. For simplifying learning, we may only obtain the truth functions of some atomic label. For a given label, instances are divided into three kinds (positive, negative, and unclear) instead of two kinds as in popular studies so that the problem with binary relevance is avoided. For each instance, the classifier selects a compound label with most semantic information or richest connotation. As a predictive model, the semantic channel does not change with the prior probability distribution (source) of instances. It still works when the source is changed. The classifier changes with the source, and hence can overcome class-imbalance problem. It is shown that the old population's increasing will change the classifier for label "Old" and has been impelling the semantic evolution of "Old". The CM iteration algorithm for unseen instance classification is introduced.
From Shannon's Channel to Semantic Channel via New Bayes' Formulas for Machine Learning
Mar 22, 2018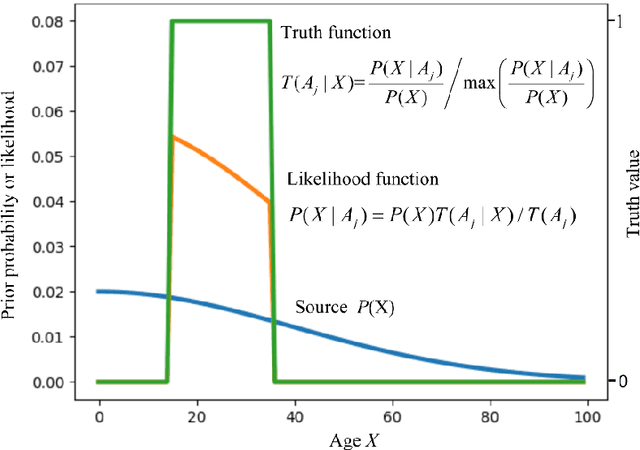

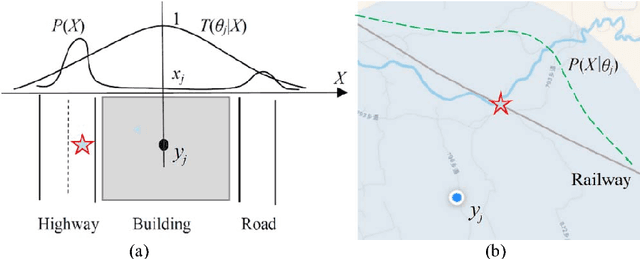
A group of transition probability functions form a Shannon's channel whereas a group of truth functions form a semantic channel. By the third kind of Bayes' theorem, we can directly convert a Shannon's channel into an optimized semantic channel. When a sample is not big enough, we can use a truth function with parameters to produce the likelihood function, then train the truth function by the conditional sampling distribution. The third kind of Bayes' theorem is proved. A semantic information theory is simply introduced. The semantic information measure reflects Popper's hypothesis-testing thought. The Semantic Information Method (SIM) adheres to maximum semantic information criterion which is compatible with maximum likelihood criterion and Regularized Least Squares criterion. It supports Wittgenstein's view: the meaning of a word lies in its use. Letting the two channels mutually match, we obtain the Channels' Matching (CM) algorithm for machine learning. The CM algorithm is used to explain the evolution of the semantic meaning of natural language, such as "Old age". The semantic channel for medical tests and the confirmation measures of test-positive and test-negative are discussed. The applications of the CM algorithm to semi-supervised learning and non-supervised learning are simply introduced. As a predictive model, the semantic channel fits variable sources and hence can overcome class-imbalance problem. The SIM strictly distinguishes statistical probability and logical probability and uses both at the same time. This method is compatible with the thoughts of Bayes, Fisher, Shannon, Zadeh, Tarski, Davidson, Wittgenstein, and Popper.It is a competitive alternative to Bayesian inference.
Illustrating Color Evolution and Color Blindness by the Decoding Model of Color Vision
Dec 12, 2010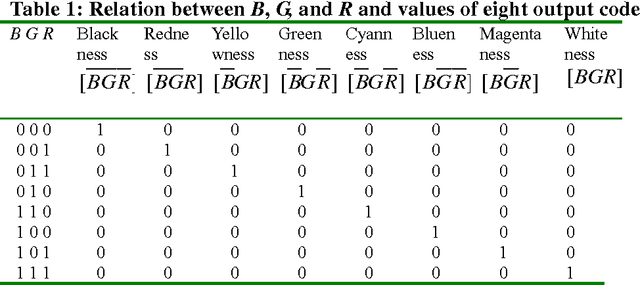
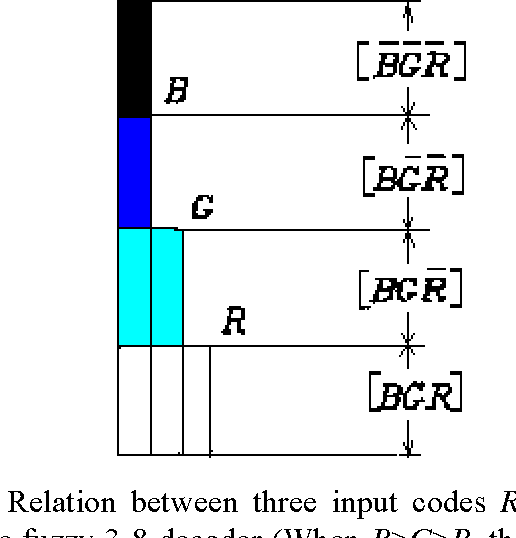
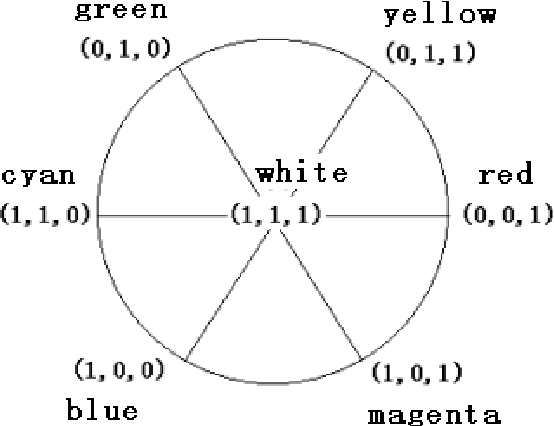
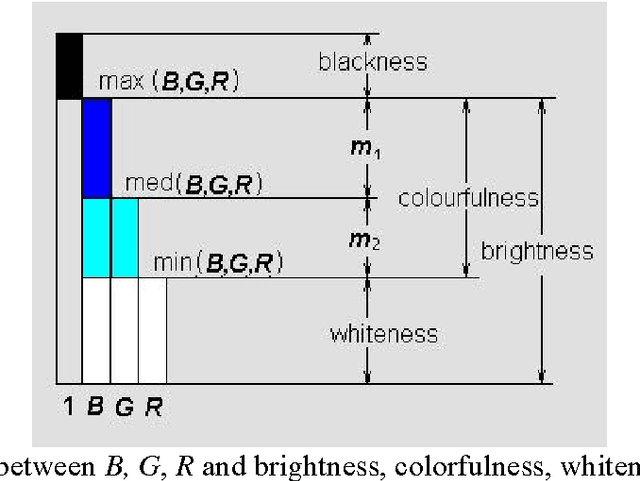
A symmetrical model of color vision, the decoding model as a new version of zone model, was introduced. The model adopts new continuous-valued logic and works in a way very similar to the way a 3-8 decoder in a numerical circuit works. By the decoding model, Young and Helmholtz's tri-pigment theory and Hering's opponent theory are unified more naturally; opponent process, color evolution, and color blindness are illustrated more concisely. According to the decoding model, we can obtain a transform from RGB system to HSV system, which is formally identical to the popular transform for computer graphics provided by Smith (1978). Advantages, problems, and physiological tests of the decoding model are also discussed.