 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A mirror-Unet architecture for PET/CT lesion segmentation
Sep 23, 2023
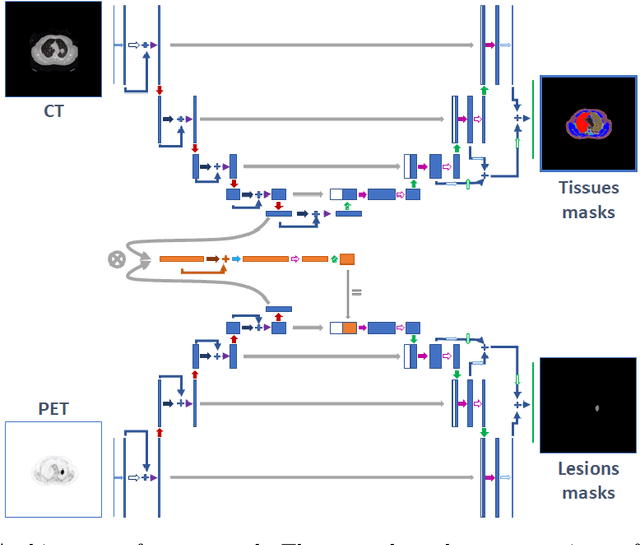
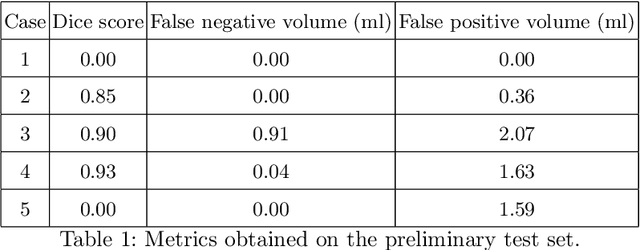
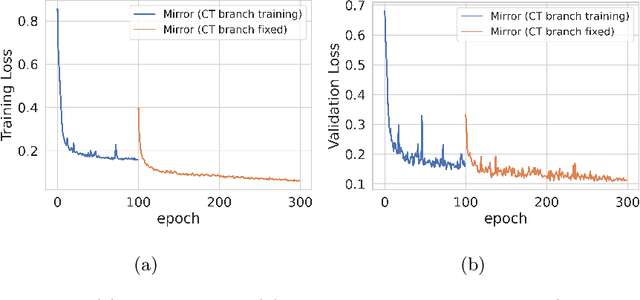
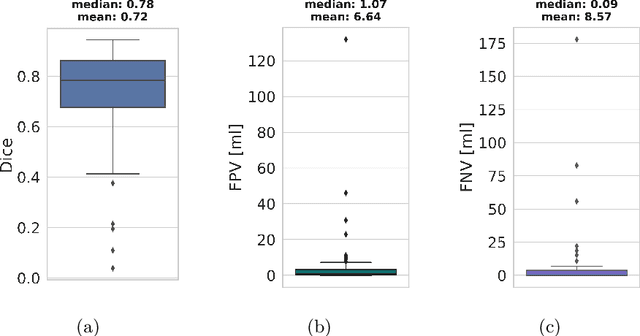
Automatic lesion detection and segmentation from [${}^{18}$F]FDG PET/CT scans is a challenging task, due to the diversity of shapes, sizes, FDG uptake and location they may present, besides the fact that physiological uptake is also present on healthy tissues. In this work, we propose a deep learning method aimed at the segmentation of oncologic lesions, based on a combination of two UNet-3D branches. First, one of the network's branches is trained to segment a group of tissues from CT images. The other branch is trained to segment the lesions from PET images, combining on the bottleneck the embedded information of CT branch, already trained. We trained and validated our networks on the AutoPET MICCAI 2023 Challenge dataset. Our code is available at: https://github.com/yrotstein/AutoPET2023_Mv1.
Memory Injections: Correcting Multi-Hop Reasoning Failures during Inference in Transformer-Based Language Models
Sep 12, 2023Answering multi-hop reasoning questions requires retrieving and synthesizing information from diverse sources. Large Language Models (LLMs) struggle to perform such reasoning consistently. Here we propose an approach to pinpoint and rectify multi-hop reasoning failures through targeted memory injections on LLM attention heads. First, we analyze the per-layer activations of GPT-2 models in response to single and multi-hop prompts. We then propose a mechanism that allows users to inject pertinent prompt-specific information, which we refer to as "memories," at critical LLM locations during inference. By thus enabling the LLM to incorporate additional relevant information during inference, we enhance the quality of multi-hop prompt completions. We show empirically that a simple, efficient, and targeted memory injection into a key attention layer can often increase the probability of the desired next token in multi-hop tasks, by up to 424%.
Increasing diversity of omni-directional images generated from single image using cGAN based on MLPMixer
Sep 15, 2023
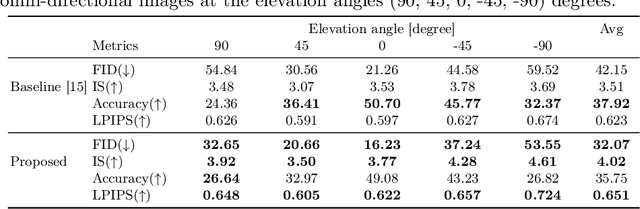
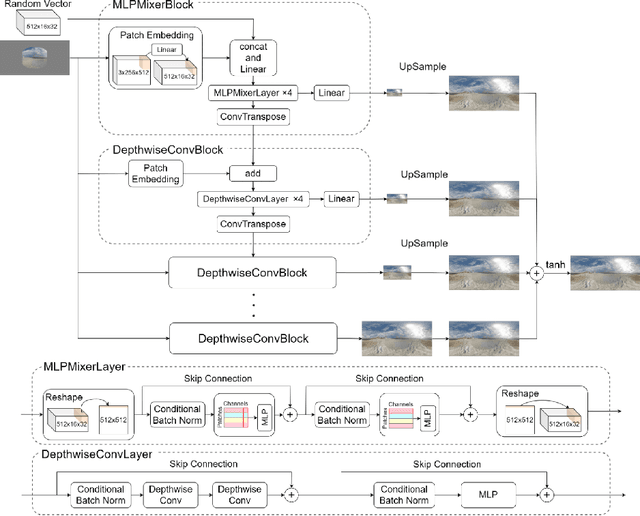
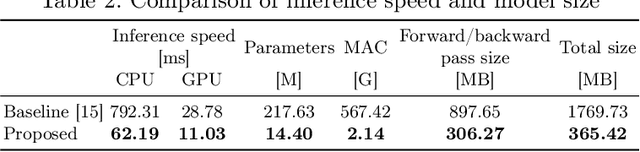
This paper proposes a novel approach to generating omni-directional images from a single snapshot picture. The previous method has relied on the generative adversarial networks based on convolutional neural networks (CNN). Although this method has successfully generated omni-directional images, CNN has two drawbacks for this task. First, since a convolutional layer only processes a local area, it is difficult to propagate the information of an input snapshot picture embedded in the center of the omni-directional image to the edges of the image. Thus, the omni-directional images created by the CNN-based generator tend to have less diversity at the edges of the generated images, creating similar scene images. Second, the CNN-based model requires large video memory in graphics processing units due to the nature of the deep structure in CNN since shallow-layer networks only receives signals from a limited range of the receptive field. To solve these problems, MLPMixer-based method was proposed in this paper. The MLPMixer has been proposed as an alternative to the self-attention in the transformer, which captures long-range dependencies and contextual information. This enables to propagate information efficiently in the omni-directional image generation task. As a result, competitive performance has been achieved with reduced memory consumption and computational cost, in addition to increasing diversity of the generated omni-directional images.
How to Model Brushless Electric Motors for the Design of Lightweight Robotic Systems
Sep 29, 2023A key step in the development of lightweight, high performance robotic systems is the modeling and selection of permanent magnet brushless direct current (BLDC) electric motors. Typical modeling analyses are completed a priori, and provide insight for properly sizing a motor for an application, specifying the required operating voltage and current, as well as assessing the thermal response and other design attributes (e.g.transmission ratio). However, to perform these modeling analyses, proper information about the motor's characteristics are needed, which are often obtained from manufacturer datasheets. Through our own experience and communications with manufacturers, we have noticed a lack of clarity and standardization in modeling BLDC motors, compounded by vague or inconsistent terminology used in motor datasheets. The purpose of this tutorial is to concisely describe the governing equations for BLDC motor analyses used in the design process, as well as highlight potential errors that can arise from incorrect usage. We present a power-invariant conversion from phase and line-to-line reference frames to a familiar q-axis DC motor representation, which provides a ``brushed'' analogue of a three phase BLDC motor that is convenient for analysis and design. We highlight potential errors including incorrect calculations of winding resistive heat loss, improper estimation of motor torque via the motor's torque constant, and incorrect estimation of the required bus voltage or resulting angular velocity limitations. A unified and condensed set of governing equations is available for designers in the Appendix. The intent of this work is to provide a consolidated mathematical foundation for modeling BLDC motors that addresses existing confusion and fosters high performance designs of future robotic systems.
CONFLATOR: Incorporating Switching Point based Rotatory Positional Encodings for Code-Mixed Language Modeling
Sep 11, 2023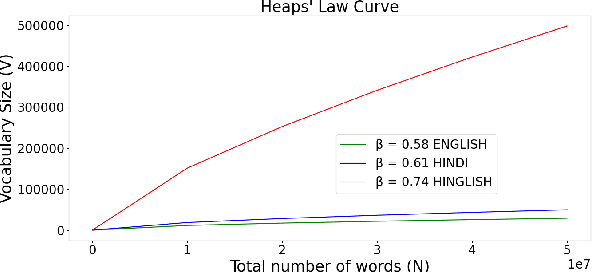
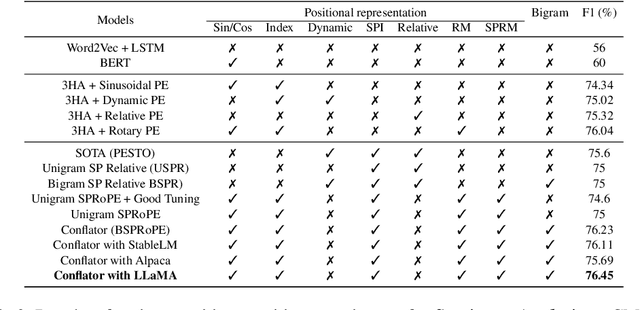
The mixing of two or more languages is called Code-Mixing (CM). CM is a social norm in multilingual societies. Neural Language Models (NLMs) like transformers have been very effective on many NLP tasks. However, NLM for CM is an under-explored area. Though transformers are capable and powerful, they cannot always encode positional/sequential information since they are non-recurrent. Therefore, to enrich word information and incorporate positional information, positional encoding is defined. We hypothesize that Switching Points (SPs), i.e., junctions in the text where the language switches (L1 -> L2 or L2-> L1), pose a challenge for CM Language Models (LMs), and hence give special emphasis to switching points in the modeling process. We experiment with several positional encoding mechanisms and show that rotatory positional encodings along with switching point information yield the best results. We introduce CONFLATOR: a neural language modeling approach for code-mixed languages. CONFLATOR tries to learn to emphasize switching points using smarter positional encoding, both at unigram and bigram levels. CONFLATOR outperforms the state-of-the-art on two tasks based on code-mixed Hindi and English (Hinglish): (i) sentiment analysis and (ii) machine translation.
Self-supervised Multi-view Clustering in Computer Vision: A Survey
Sep 18, 2023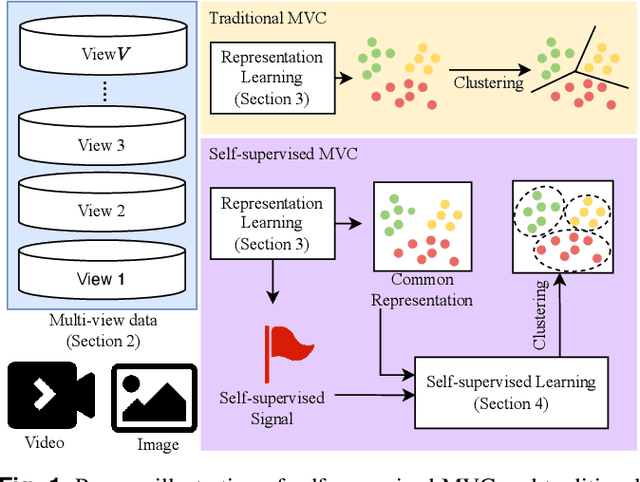
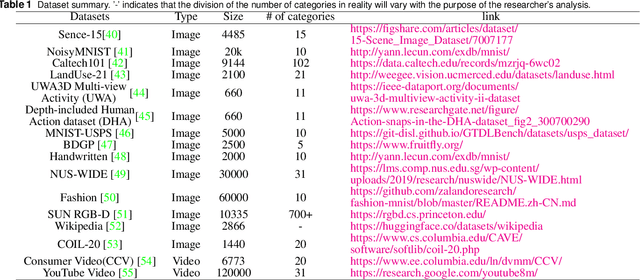
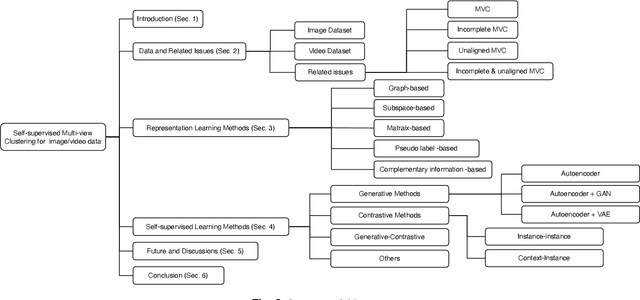
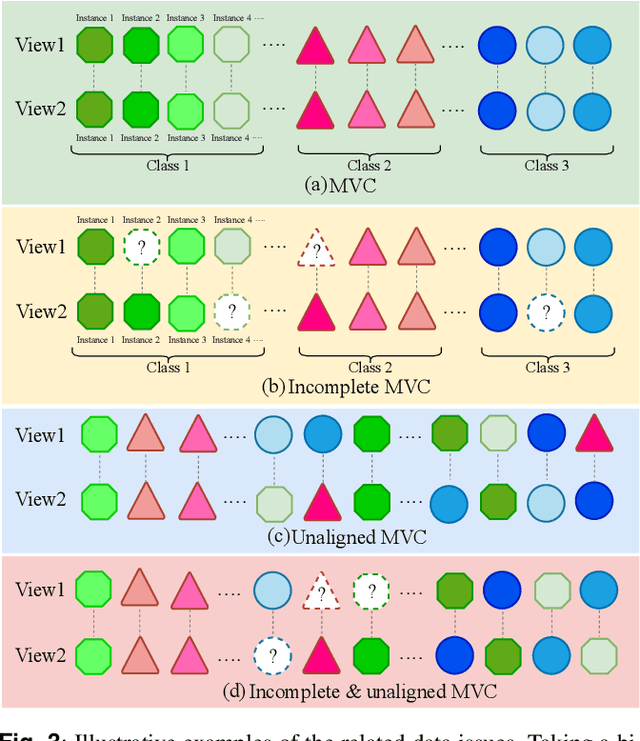
Multi-view clustering (MVC) has had significant implications in cross-modal representation learning and data-driven decision-making in recent years. It accomplishes this by leveraging the consistency and complementary information among multiple views to cluster samples into distinct groups. However, as contrastive learning continues to evolve within the field of computer vision, self-supervised learning has also made substantial research progress and is progressively becoming dominant in MVC methods. It guides the clustering process by designing proxy tasks to mine the representation of image and video data itself as supervisory information. Despite the rapid development of self-supervised MVC, there has yet to be a comprehensive survey to analyze and summarize the current state of research progress. Therefore, this paper explores the reasons and advantages of the emergence of self-supervised MVC and discusses the internal connections and classifications of common datasets, data issues, representation learning methods, and self-supervised learning methods. This paper does not only introduce the mechanisms for each category of methods but also gives a few examples of how these techniques are used. In the end, some open problems are pointed out for further investigation and development.
AutoFuse: Automatic Fusion Networks for Deformable Medical Image Registration
Sep 11, 2023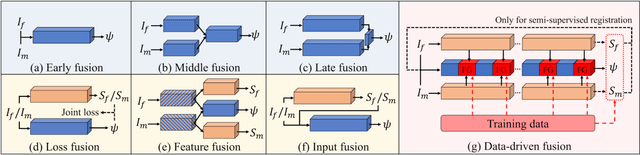
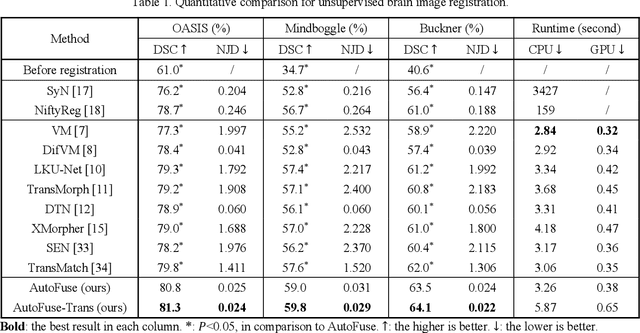
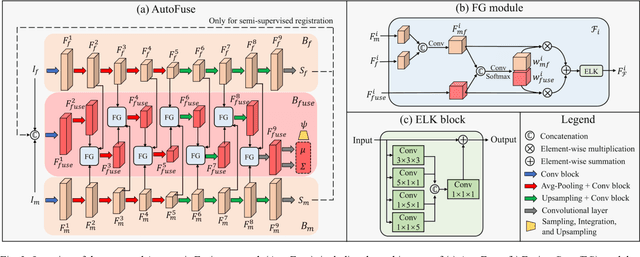
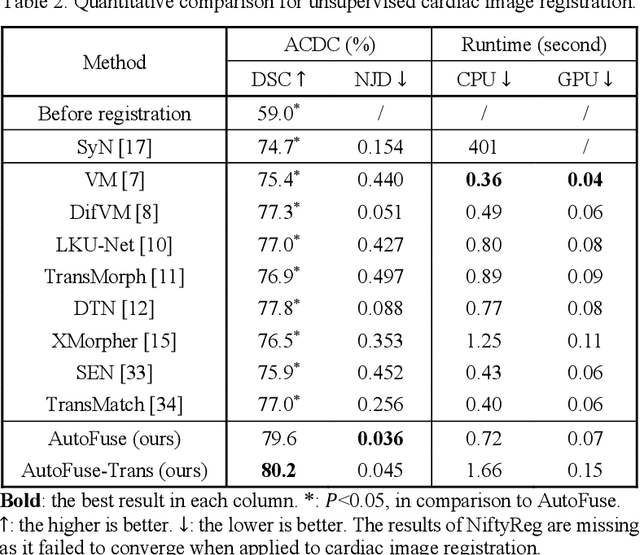
Deformable image registration aims to find a dense non-linear spatial correspondence between a pair of images, which is a crucial step for many medical tasks such as tumor growth monitoring and population analysis. Recently, Deep Neural Networks (DNNs) have been widely recognized for their ability to perform fast end-to-end registration. However, DNN-based registration needs to explore the spatial information of each image and fuse this information to characterize spatial correspondence. This raises an essential question: what is the optimal fusion strategy to characterize spatial correspondence? Existing fusion strategies (e.g., early fusion, late fusion) were empirically designed to fuse information by manually defined prior knowledge, which inevitably constrains the registration performance within the limits of empirical designs. In this study, we depart from existing empirically-designed fusion strategies and develop a data-driven fusion strategy for deformable image registration. To achieve this, we propose an Automatic Fusion network (AutoFuse) that provides flexibility to fuse information at many potential locations within the network. A Fusion Gate (FG) module is also proposed to control how to fuse information at each potential network location based on training data. Our AutoFuse can automatically optimize its fusion strategy during training and can be generalizable to both unsupervised registration (without any labels) and semi-supervised registration (with weak labels provided for partial training data). Extensive experiments on two well-benchmarked medical registration tasks (inter- and intra-patient registration) with eight public datasets show that our AutoFuse outperforms state-of-the-art unsupervised and semi-supervised registration methods.
Disruption Detection for a Cognitive Digital Supply Chain Twin Using Hybrid Deep Learning
Sep 25, 2023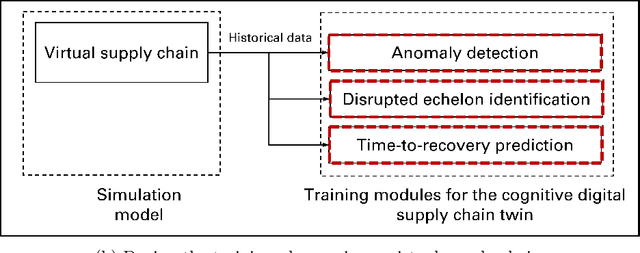
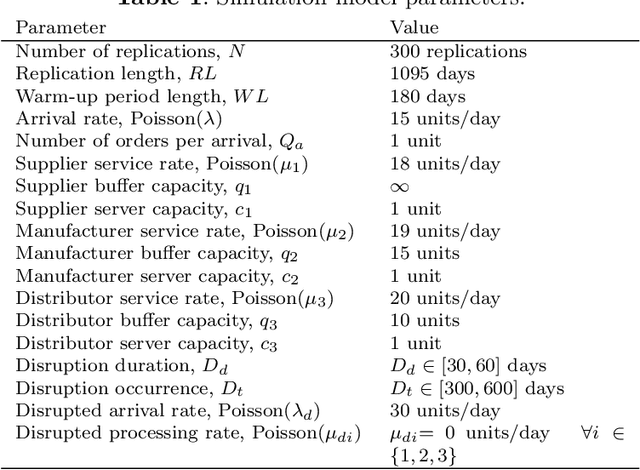
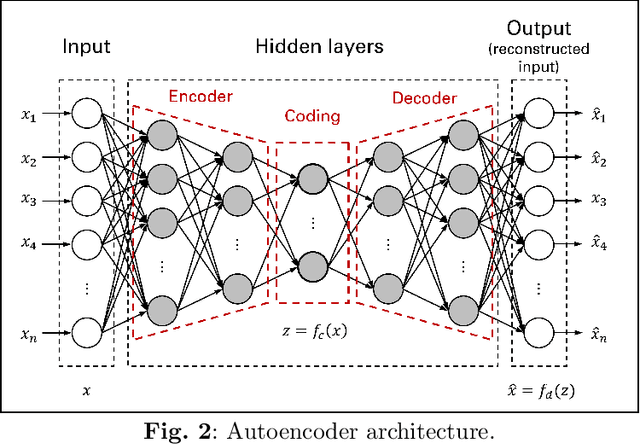

Purpose: Recent disruptive events, such as COVID-19 and Russia-Ukraine conflict, had a significant impact of global supply chains. Digital supply chain twins have been proposed in order to provide decision makers with an effective and efficient tool to mitigate disruption impact. Methods: This paper introduces a hybrid deep learning approach for disruption detection within a cognitive digital supply chain twin framework to enhance supply chain resilience. The proposed disruption detection module utilises a deep autoencoder neural network combined with a one-class support vector machine algorithm. In addition, long-short term memory neural network models are developed to identify the disrupted echelon and predict time-to-recovery from the disruption effect. Results: The obtained information from the proposed approach will help decision-makers and supply chain practitioners make appropriate decisions aiming at minimizing negative impact of disruptive events based on real-time disruption detection data. The results demonstrate the trade-off between disruption detection model sensitivity, encountered delay in disruption detection, and false alarms. This approach has seldom been used in recent literature addressing this issue.
Accurate and Interactive Visual-Inertial Sensor Calibration with Next-Best-View and Next-Best-Trajectory Suggestion
Sep 25, 2023Visual-Inertial (VI) sensors are popular in robotics, self-driving vehicles, and augmented and virtual reality applications. In order to use them for any computer vision or state-estimation task, a good calibration is essential. However, collecting informative calibration data in order to render the calibration parameters observable is not trivial for a non-expert. In this work, we introduce a novel VI calibration pipeline that guides a non-expert with the use of a graphical user interface and information theory in collecting informative calibration data with Next-Best-View and Next-Best-Trajectory suggestions to calibrate the intrinsics, extrinsics, and temporal misalignment of a VI sensor. We show through experiments that our method is faster, more accurate, and more consistent than state-of-the-art alternatives. Specifically, we show how calibrations with our proposed method achieve higher accuracy estimation results when used by state-of-the-art VI Odometry as well as VI-SLAM approaches. The source code of our software can be found on: https://github.com/chutsu/yac.
Learning to Abstain From Uninformative Data
Sep 25, 2023Learning and decision-making in domains with naturally high noise-to-signal ratio, such as Finance or Healthcare, is often challenging, while the stakes are very high. In this paper, we study the problem of learning and acting under a general noisy generative process. In this problem, the data distribution has a significant proportion of uninformative samples with high noise in the label, while part of the data contains useful information represented by low label noise. This dichotomy is present during both training and inference, which requires the proper handling of uninformative data during both training and testing. We propose a novel approach to learning under these conditions via a loss inspired by the selective learning theory. By minimizing this loss, the model is guaranteed to make a near-optimal decision by distinguishing informative data from uninformative data and making predictions. We build upon the strength of our theoretical guarantees by describing an iterative algorithm, which jointly optimizes both a predictor and a selector, and evaluates its empirical performance in a variety of settings.