 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiPerRAG: High-Performance Retrieval Augmented Generation for Scientific Insights
May 07, 2025The volume of scientific literature is growing exponentially, leading to underutilized discoveries, duplicated efforts, and limited cross-disciplinary collaboration. Retrieval Augmented Generation (RAG) offers a way to assist scientists by improving the factuality of Large Language Models (LLMs) in processing this influx of information. However, scaling RAG to handle millions of articles introduces significant challenges, including the high computational costs associated with parsing documents and embedding scientific knowledge, as well as the algorithmic complexity of aligning these representations with the nuanced semantics of scientific content. To address these issues, we introduce HiPerRAG, a RAG workflow powered by high performance computing (HPC) to index and retrieve knowledge from more than 3.6 million scientific articles. At its core are Oreo, a high-throughput model for multimodal document parsing, and ColTrast, a query-aware encoder fine-tuning algorithm that enhances retrieval accuracy by using contrastive learning and late-interaction techniques. HiPerRAG delivers robust performance on existing scientific question answering benchmarks and two new benchmarks introduced in this work, achieving 90% accuracy on SciQ and 76% on PubMedQA-outperforming both domain-specific models like PubMedGPT and commercial LLMs such as GPT-4. Scaling to thousands of GPUs on the Polaris, Sunspot, and Frontier supercomputers, HiPerRAG delivers million document-scale RAG workflows for unifying scientific knowledge and fostering interdisciplinary innovation.
LSHBloom: Memory-efficient, Extreme-scale Document Deduplication
Nov 06, 2024Deduplication is a major focus for assembling and curating training datasets for large language models (LLM) -- detecting and eliminating additional instances of the same content -- in large collections of technical documents. Unrestrained, duplicates in the training dataset increase training costs and lead to undesirable properties such as memorization in trained models or cheating on evaluation. Contemporary approaches to document-level deduplication are often extremely expensive in both runtime and memory. We propose LSHBloom, an extension to MinhashLSH, which replaces the expensive LSHIndex with lightweight Bloom filters. LSHBloom demonstrates the same deduplication performance as MinhashLSH with only a marginal increase in false positives (as low as 1e-5 in our experiments); demonstrates competitive runtime (270\% faster than MinhashLSH on peS2o); and, crucially, uses just 0.6\% of the disk space required by MinhashLSH to deduplicate peS2o. We demonstrate that this space advantage scales with increased dataset size -- at the extreme scale of several billion documents, LSHBloom promises a 250\% speedup and a 54$\times$ space advantage over traditional MinHashLSH scaling deduplication of text datasets to many billions of documents.
SoK: On Finding Common Ground in Loss Landscapes Using Deep Model Merging Techniques
Oct 16, 2024



Understanding neural networks is crucial to creating reliable and trustworthy deep learning models. Most contemporary research in interpretability analyzes just one model at a time via causal intervention or activation analysis. Yet despite successes, these methods leave significant gaps in our understanding of the training behaviors of neural networks, how their inner representations emerge, and how we can predictably associate model components with task-specific behaviors. Seeking new insights from work in related fields, here we survey literature in the field of model merging, a field that aims to combine the abilities of various neural networks by merging their parameters and identifying task-specific model components in the process. We analyze the model merging literature through the lens of loss landscape geometry, an approach that enables us to connect observations from empirical studies on interpretability, security, model merging, and loss landscape analysis to phenomena that govern neural network training and the emergence of their inner representations. To systematize knowledge in this area, we present a novel taxonomy of model merging techniques organized by their core algorithmic principles. Additionally, we distill repeated empirical observations from the literature in these fields into characterizations of four major aspects of loss landscape geometry: mode convexity, determinism, directedness, and connectivity. We argue that by improving our understanding of the principles underlying model merging and loss landscape geometry, this work contributes to the goal of ensuring secure and trustworthy machine learning in practice.
Mitigating Memorization In Language Models
Oct 03, 2024



Language models (LMs) can "memorize" information, i.e., encode training data in their weights in such a way that inference-time queries can lead to verbatim regurgitation of that data. This ability to extract training data can be problematic, for example, when data are private or sensitive. In this work, we investigate methods to mitigate memorization: three regularizer-based, three finetuning-based, and eleven machine unlearning-based methods, with five of the latter being new methods that we introduce. We also introduce TinyMem, a suite of small, computationally-efficient LMs for the rapid development and evaluation of memorization-mitigation methods. We demonstrate that the mitigation methods that we develop using TinyMem can successfully be applied to production-grade LMs, and we determine via experiment that: regularizer-based mitigation methods are slow and ineffective at curbing memorization; fine-tuning-based methods are effective at curbing memorization, but overly expensive, especially for retaining higher accuracies; and unlearning-based methods are faster and more effective, allowing for the precise localization and removal of memorized information from LM weights prior to inference. We show, in particular, that our proposed unlearning method BalancedSubnet outperforms other mitigation methods at removing memorized information while preserving performance on target tasks.
SciQAG: A Framework for Auto-Generated Scientific Question Answering Dataset with Fine-grained Evaluation
May 16, 2024



The use of question-answer (QA) pairs for training and evaluating large language models (LLMs) has attracted considerable attention. Yet few available QA datasets are based on knowledge from the scientific literature. Here we bridge this gap by presenting Automatic Generation of Scientific Question Answers (SciQAG), a framework for automatic generation and evaluation of scientific QA pairs sourced from published scientific literature. We fine-tune an open-source LLM to generate \num{960000} scientific QA pairs from full-text scientific papers and propose a five-dimensional metric to evaluate the quality of the generated QA pairs. We show via LLM-based evaluation that the generated QA pairs consistently achieve an average score of 2.5 out of 3 across five dimensions, indicating that our framework can distill key knowledge from papers into high-quality QA pairs at scale. We make the dataset, models, and evaluation codes publicly available.
Attention Lens: A Tool for Mechanistically Interpreting the Attention Head Information Retrieval Mechanism
Oct 25, 2023

Transformer-based Large Language Models (LLMs) are the state-of-the-art for natural language tasks. Recent work has attempted to decode, by reverse engineering the role of linear layers, the internal mechanisms by which LLMs arrive at their final predictions for text completion tasks. Yet little is known about the specific role of attention heads in producing the final token prediction. We propose Attention Lens, a tool that enables researchers to translate the outputs of attention heads into vocabulary tokens via learned attention-head-specific transformations called lenses. Preliminary findings from our trained lenses indicate that attention heads play highly specialized roles in language models. The code for Attention Lens is available at github.com/msakarvadia/AttentionLens.
Memory Injections: Correcting Multi-Hop Reasoning Failures during Inference in Transformer-Based Language Models
Sep 12, 2023



Answering multi-hop reasoning questions requires retrieving and synthesizing information from diverse sources. Large Language Models (LLMs) struggle to perform such reasoning consistently. Here we propose an approach to pinpoint and rectify multi-hop reasoning failures through targeted memory injections on LLM attention heads. First, we analyze the per-layer activations of GPT-2 models in response to single and multi-hop prompts. We then propose a mechanism that allows users to inject pertinent prompt-specific information, which we refer to as "memories," at critical LLM locations during inference. By thus enabling the LLM to incorporate additional relevant information during inference, we enhance the quality of multi-hop prompt completions. We show empirically that a simple, efficient, and targeted memory injection into a key attention layer can often increase the probability of the desired next token in multi-hop tasks, by up to 424%.
ScholarBERT: Bigger is Not Always Better
May 23, 2022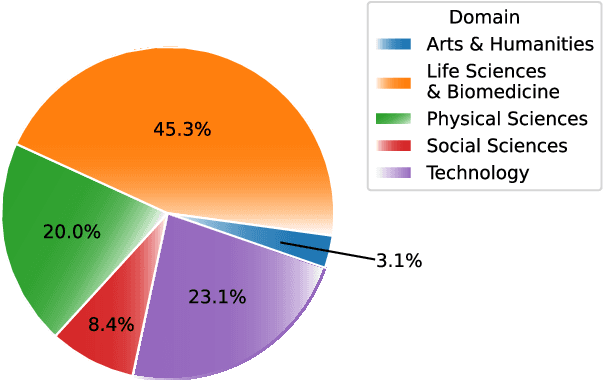
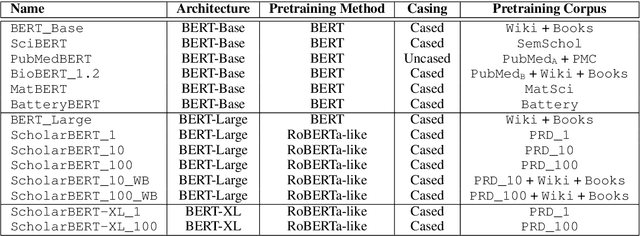

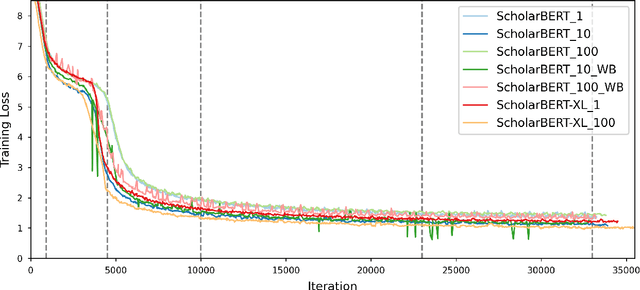
Transformer-based masked language models trained on general corpora, such as BERT and RoBERTa, have shown impressive performance on various downstream tasks. Increasingly, researchers are "finetuning" these models to improve performance on domain-specific tasks. Here, we report a broad study in which we applied 14 transformer-based models to 11 scientific tasks in order to evaluate how downstream performance is affected by changes along various dimensions (e.g., training data, model size, pretraining time, finetuning length). In this process, we created the largest and most diverse scientific language model to date, ScholarBERT, by training a 770M-parameter BERT model on an 221B token scientific literature dataset spanning many disciplines. Counterintuitively, our evaluation of the 14 BERT-based models (seven versions of ScholarBERT, five science-specific large language models from the literature, BERT-Base, and BERT-Large) reveals little difference in performance across the 11 science-focused tasks, despite major differences in model size and training data. We argue that our results establish an upper bound for the performance achievable with BERT-based architectures on tasks from the scientific domain.