 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Logits of API-Protected LLMs Leak Proprietary Information
Mar 15, 2024
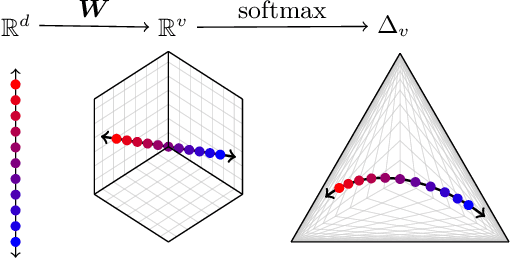

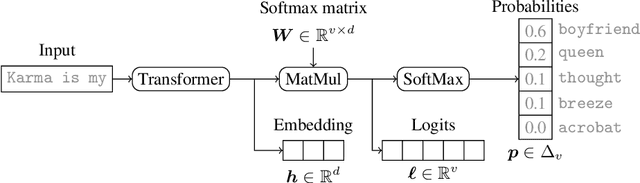

The commercialization of large language models (LLMs) has led to the common practice of high-level API-only access to proprietary models. In this work, we show that even with a conservative assumption about the model architecture, it is possible to learn a surprisingly large amount of non-public information about an API-protected LLM from a relatively small number of API queries (e.g., costing under $1,000 for OpenAI's gpt-3.5-turbo). Our findings are centered on one key observation: most modern LLMs suffer from a softmax bottleneck, which restricts the model outputs to a linear subspace of the full output space. We show that this lends itself to a model image or a model signature which unlocks several capabilities with affordable cost: efficiently discovering the LLM's hidden size, obtaining full-vocabulary outputs, detecting and disambiguating different model updates, identifying the source LLM given a single full LLM output, and even estimating the output layer parameters. Our empirical investigations show the effectiveness of our methods, which allow us to estimate the embedding size of OpenAI's gpt-3.5-turbo to be about 4,096. Lastly, we discuss ways that LLM providers can guard against these attacks, as well as how these capabilities can be viewed as a feature (rather than a bug) by allowing for greater transparency and accountability.
From "um" to "yeah": Producing, predicting, and regulating information flow in human conversation
Mar 13, 2024
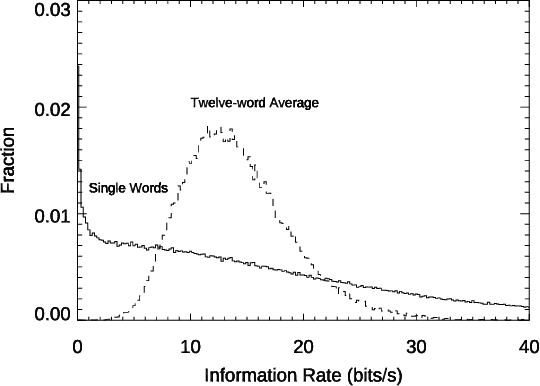
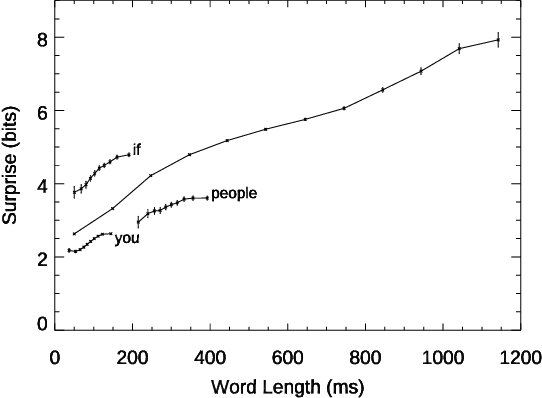
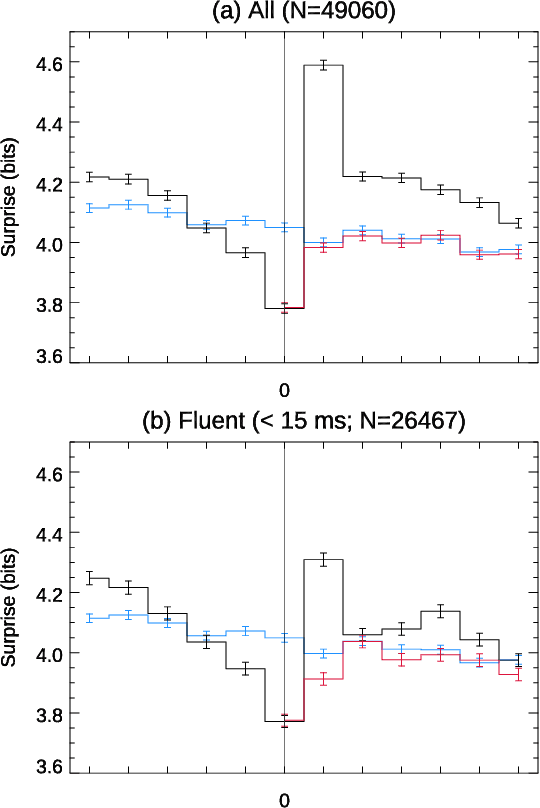
Conversation demands attention. Speakers must call words to mind, listeners must make sense of them, and both together must negotiate this flow of information, all in fractions of a second. We used large language models to study how this works in a large-scale dataset of English-language conversation, the CANDOR corpus. We provide a new estimate of the information density of unstructured conversation, of approximately 13 bits/second, and find significant effects associated with the cognitive load of both retrieving, and presenting, that information. We also reveal a role for backchannels -- the brief yeahs, uh-huhs, and mhmms that listeners provide -- in regulating the production of novelty: the lead-up to a backchannel is associated with declining information rate, while speech downstream rebounds to previous rates. Our results provide new insights into long-standing theories of how we respond to fluctuating demands on cognitive resources, and how we negotiate those demands in partnership with others.
Asymptotics of Language Model Alignment
Apr 02, 2024Let $p$ denote a generative language model. Let $r$ denote a reward model that returns a scalar that captures the degree at which a draw from $p$ is preferred. The goal of language model alignment is to alter $p$ to a new distribution $\phi$ that results in a higher expected reward while keeping $\phi$ close to $p.$ A popular alignment method is the KL-constrained reinforcement learning (RL), which chooses a distribution $\phi_\Delta$ that maximizes $E_{\phi_{\Delta}} r(y)$ subject to a relative entropy constraint $KL(\phi_\Delta || p) \leq \Delta.$ Another simple alignment method is best-of-$N$, where $N$ samples are drawn from $p$ and one with highest reward is selected. In this paper, we offer a closed-form characterization of the optimal KL-constrained RL solution. We demonstrate that any alignment method that achieves a comparable trade-off between KL divergence and reward must approximate the optimal KL-constrained RL solution in terms of relative entropy. To further analyze the properties of alignment methods, we introduce two simplifying assumptions: we let the language model be memoryless, and the reward model be linear. Although these assumptions may not reflect complex real-world scenarios, they enable a precise characterization of the asymptotic behavior of both the best-of-$N$ alignment, and the KL-constrained RL method, in terms of information-theoretic quantities. We prove that the reward of the optimal KL-constrained RL solution satisfies a large deviation principle, and we fully characterize its rate function. We also show that the rate of growth of the scaled cumulants of the reward is characterized by a proper Renyi cross entropy. Finally, we show that best-of-$N$ is asymptotically equivalent to KL-constrained RL solution by proving that their expected rewards are asymptotically equal, and concluding that the two distributions must be close in KL divergence.
Intelligent Classification and Personalized Recommendation of E-commerce Products Based on Machine Learning
Mar 28, 2024With the rapid evolution of the Internet and the exponential proliferation of information, users encounter information overload and the conundrum of choice. Personalized recommendation systems play a pivotal role in alleviating this burden by aiding users in filtering and selecting information tailored to their preferences and requirements. Such systems not only enhance user experience and satisfaction but also furnish opportunities for businesses and platforms to augment user engagement, sales, and advertising efficacy.This paper undertakes a comparative analysis between the operational mechanisms of traditional e-commerce commodity classification systems and personalized recommendation systems. It delineates the significance and application of personalized recommendation systems across e-commerce, content information, and media domains. Furthermore, it delves into the challenges confronting personalized recommendation systems in e-commerce, including data privacy, algorithmic bias, scalability, and the cold start problem. Strategies to address these challenges are elucidated.Subsequently, the paper outlines a personalized recommendation system leveraging the BERT model and nearest neighbor algorithm, specifically tailored to address the exigencies of the eBay e-commerce platform. The efficacy of this recommendation system is substantiated through manual evaluation, and a practical application operational guide and structured output recommendation results are furnished to ensure the system's operability and scalability.
Flickr30K-CFQ: A Compact and Fragmented Query Dataset for Text-image Retrieval
Apr 01, 2024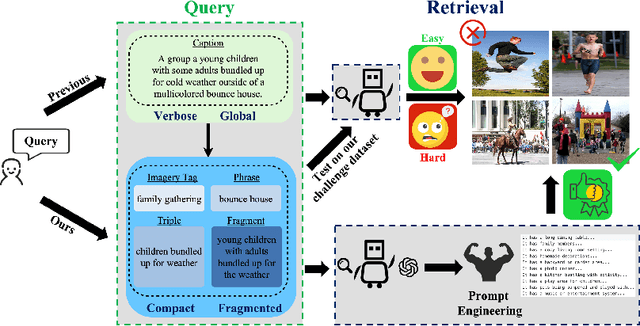

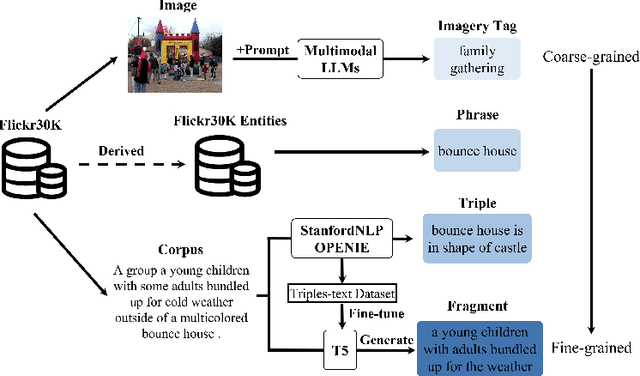

With the explosive growth of multi-modal information on the Internet, unimodal search cannot satisfy the requirement of Internet applications. Text-image retrieval research is needed to realize high-quality and efficient retrieval between different modalities. Existing text-image retrieval research is mostly based on general vision-language datasets (e.g. MS-COCO, Flickr30K), in which the query utterance is rigid and unnatural (i.e. verbosity and formality). To overcome the shortcoming, we construct a new Compact and Fragmented Query challenge dataset (named Flickr30K-CFQ) to model text-image retrieval task considering multiple query content and style, including compact and fine-grained entity-relation corpus. We propose a novel query-enhanced text-image retrieval method using prompt engineering based on LLM. Experiments show that our proposed Flickr30-CFQ reveals the insufficiency of existing vision-language datasets in realistic text-image tasks. Our LLM-based Query-enhanced method applied on different existing text-image retrieval models improves query understanding performance both on public dataset and our challenge set Flickr30-CFQ with over 0.9% and 2.4% respectively. Our project can be available anonymously in https://sites.google.com/view/Flickr30K-cfq.
Vision-language models for decoding provider attention during neonatal resuscitation
Apr 01, 2024Neonatal resuscitations demand an exceptional level of attentiveness from providers, who must process multiple streams of information simultaneously. Gaze strongly influences decision making; thus, understanding where a provider is looking during neonatal resuscitations could inform provider training, enhance real-time decision support, and improve the design of delivery rooms and neonatal intensive care units (NICUs). Current approaches to quantifying neonatal providers' gaze rely on manual coding or simulations, which limit scalability and utility. Here, we introduce an automated, real-time, deep learning approach capable of decoding provider gaze into semantic classes directly from first-person point-of-view videos recorded during live resuscitations. Combining state-of-the-art, real-time segmentation with vision-language models (CLIP), our low-shot pipeline attains 91\% classification accuracy in identifying gaze targets without training. Upon fine-tuning, the performance of our gaze-guided vision transformer exceeds 98\% accuracy in gaze classification, approaching human-level precision. This system, capable of real-time inference, enables objective quantification of provider attention dynamics during live neonatal resuscitation. Our approach offers a scalable solution that seamlessly integrates with existing infrastructure for data-scarce gaze analysis, thereby offering new opportunities for understanding and refining clinical decision making.
Enhanced Precision in Rainfall Forecasting for Mumbai: Utilizing Physics Informed ConvLSTM2D Models for Finer Spatial and Temporal Resolution
Apr 01, 2024Forecasting rainfall in tropical areas is challenging due to complex atmospheric behaviour, elevated humidity levels, and the common presence of convective rain events. In the Indian context, the difficulty is further exacerbated because of the monsoon intra seasonal oscillations, which introduce significant variability in rainfall patterns over short periods. Earlier investigations into rainfall prediction leveraged numerical weather prediction methods, along with statistical and deep learning approaches. This study introduces deep learning spatial model aimed at enhancing rainfall prediction accuracy on a finer scale. In this study, we hypothesize that integrating physical understanding improves the precipitation prediction skill of deep learning models with high precision for finer spatial scales, such as cities. To test this hypothesis, we introduce a physics informed ConvLSTM2D model to predict precipitation 6hr and 12hr ahead for Mumbai, India. We utilize ERA5 reanalysis data select predictor variables, across various geopotential levels. The ConvLSTM2D model was trained on the target variable precipitation for 4 different grids representing different spatial grid locations of Mumbai. Thus, the use of the ConvLSTM2D model for rainfall prediction, utilizing physics informed data from specific grids with limited spatial information, reflects current advancements in meteorological research that emphasize both efficiency and localized precision.
Prompt Learning for Oriented Power Transmission Tower Detection in High-Resolution SAR Images
Apr 01, 2024Detecting transmission towers from synthetic aperture radar (SAR) images remains a challenging task due to the comparatively small size and side-looking geometry, with background clutter interference frequently hindering tower identification. A large number of interfering signals superimposes the return signal from the tower. We found that localizing or prompting positions of power transmission towers is beneficial to address this obstacle. Based on this revelation, this paper introduces prompt learning into the oriented object detector (P2Det) for multimodal information learning. P2Det contains the sparse prompt coding and cross-attention between the multimodal data. Specifically, the sparse prompt encoder (SPE) is proposed to represent point locations, converting prompts into sparse embeddings. The image embeddings are generated through the Transformer layers. Then a two-way fusion module (TWFM) is proposed to calculate the cross-attention of the two different embeddings. The interaction of image-level and prompt-level features is utilized to address the clutter interference. A shape-adaptive refinement module (SARM) is proposed to reduce the effect of aspect ratio. Extensive experiments demonstrated the effectiveness of the proposed model on high-resolution SAR images. P2Det provides a novel insight for multimodal object detection due to its competitive performance.
Harnessing The Power of Attention For Patch-Based Biomedical Image Classification
Apr 01, 2024Biomedical image analysis can be facilitated by an innovative architecture rooted in self-attention mechanisms. The traditional convolutional neural network (CNN), characterized by fixed-sized windows, needs help capturing intricate spatial and temporal relations at the pixel level. The immutability of CNN filter weights post-training further restricts input fluctuations. Recognizing these limitations, we propose a new paradigm of attention-based models instead of convolutions. As an alternative to traditional CNNs, these models demonstrate robust modelling capabilities and the ability to grasp comprehensive long-range contextual information efficiently. Providing a solution to critical challenges faced by attention-based vision models such as inductive bias, weight sharing, receptive field limitations, and data handling in high resolution, our work combines non-overlapping (vanilla patching) with novel overlapped Shifted Patching Techniques (S.P.T.s) to induce local context that enhances model generalization. Moreover, we examine the novel Lancoz5 interpolation technique, which adapts variable image sizes to higher resolutions. Experimental evidence validates our model's generalization effectiveness, comparing favourably with existing approaches. Attention-based methods are particularly effective with ample data, especially when advanced data augmentation methodologies are integrated to strengthen their robustness.
Explainable AI Integrated Feature Engineering for Wildfire Prediction
Apr 01, 2024Wildfires present intricate challenges for prediction, necessitating the use of sophisticated machine learning techniques for effective modeling\cite{jain2020review}. In our research, we conducted a thorough assessment of various machine learning algorithms for both classification and regression tasks relevant to predicting wildfires. We found that for classifying different types or stages of wildfires, the XGBoost model outperformed others in terms of accuracy and robustness. Meanwhile, the Random Forest regression model showed superior results in predicting the extent of wildfire-affected areas, excelling in both prediction error and explained variance. Additionally, we developed a hybrid neural network model that integrates numerical data and image information for simultaneous classification and regression. To gain deeper insights into the decision-making processes of these models and identify key contributing features, we utilized eXplainable Artificial Intelligence (XAI) techniques, including TreeSHAP, LIME, Partial Dependence Plots (PDP), and Gradient-weighted Class Activation Mapping (Grad-CAM). These interpretability tools shed light on the significance and interplay of various features, highlighting the complex factors influencing wildfire predictions. Our study not only demonstrates the effectiveness of specific machine learning models in wildfire-related tasks but also underscores the critical role of model transparency and interpretability in environmental science applications.