 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Robust Fidelity for Evaluating Explainability of Graph Neural Networks
Oct 03, 2023
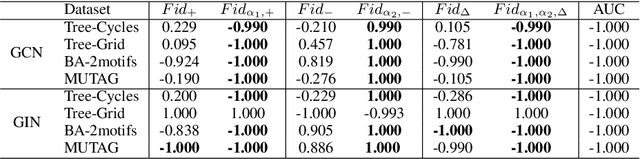
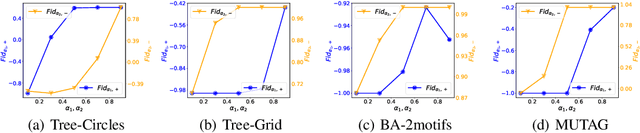
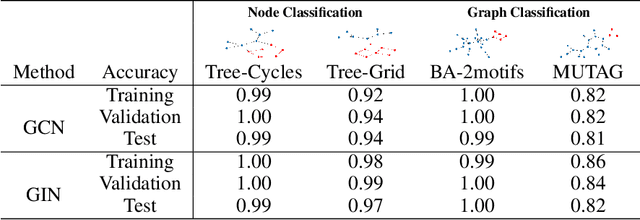
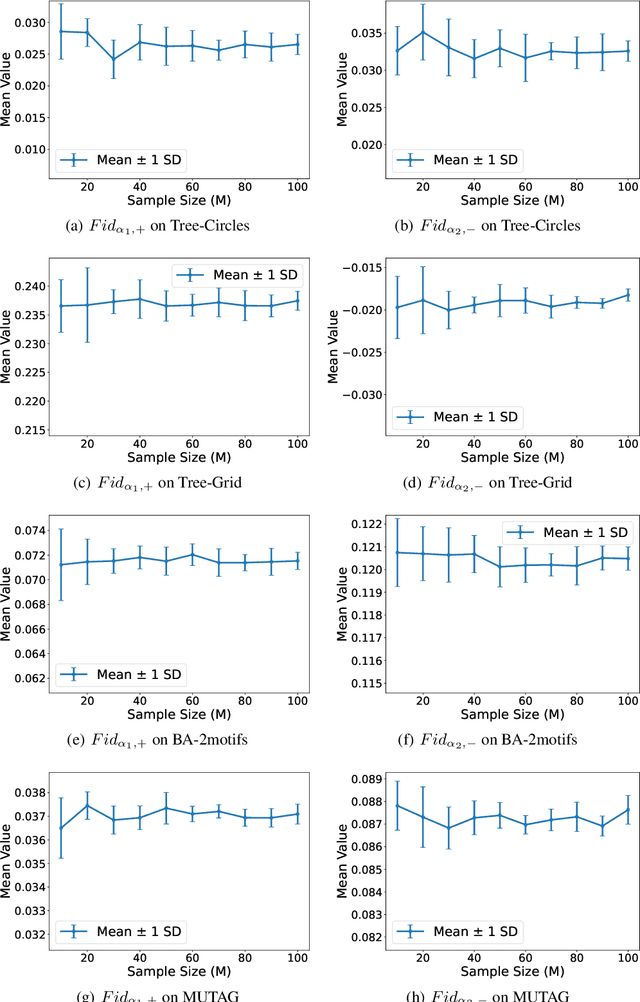
Graph Neural Networks (GNNs) are neural models that leverage the dependency structure in graphical data via message passing among the graph nodes. GNNs have emerged as pivotal architectures in analyzing graph-structured data, and their expansive application in sensitive domains requires a comprehensive understanding of their decision-making processes -- necessitating a framework for GNN explainability. An explanation function for GNNs takes a pre-trained GNN along with a graph as input, to produce a `sufficient statistic' subgraph with respect to the graph label. A main challenge in studying GNN explainability is to provide fidelity measures that evaluate the performance of these explanation functions. This paper studies this foundational challenge, spotlighting the inherent limitations of prevailing fidelity metrics, including $Fid_+$, $Fid_-$, and $Fid_\Delta$. Specifically, a formal, information-theoretic definition of explainability is introduced and it is shown that existing metrics often fail to align with this definition across various statistical scenarios. The reason is due to potential distribution shifts when subgraphs are removed in computing these fidelity measures. Subsequently, a robust class of fidelity measures are introduced, and it is shown analytically that they are resilient to distribution shift issues and are applicable in a wide range of scenarios. Extensive empirical analysis on both synthetic and real datasets are provided to illustrate that the proposed metrics are more coherent with gold standard metrics.
Realtime Motion Generation with Active Perception Using Attention Mechanism for Cooking Robot
Sep 26, 2023To support humans in their daily lives, robots are required to autonomously learn, adapt to objects and environments, and perform the appropriate actions. We tackled on the task of cooking scrambled eggs using real ingredients, in which the robot needs to perceive the states of the egg and adjust stirring movement in real time, while the egg is heated and the state changes continuously. In previous works, handling changing objects was found to be challenging because sensory information includes dynamical, both important or noisy information, and the modality which should be focused on changes every time, making it difficult to realize both perception and motion generation in real time. We propose a predictive recurrent neural network with an attention mechanism that can weigh the sensor input, distinguishing how important and reliable each modality is, that realize quick and efficient perception and motion generation. The model is trained with learning from the demonstration, and allows the robot to acquire human-like skills. We validated the proposed technique using the robot, Dry-AIREC, and with our learning model, it could perform cooking eggs with unknown ingredients. The robot could change the method of stirring and direction depending on the status of the egg, as in the beginning it stirs in the whole pot, then subsequently, after the egg started being heated, it starts flipping and splitting motion targeting specific areas, although we did not explicitly indicate them.
Multivariate Prototype Representation for Domain-Generalized Incremental Learning
Sep 24, 2023Deep learning models suffer from catastrophic forgetting when being fine-tuned with samples of new classes. This issue becomes even more pronounced when faced with the domain shift between training and testing data. In this paper, we study the critical and less explored Domain-Generalized Class-Incremental Learning (DGCIL). We design a DGCIL approach that remembers old classes, adapts to new classes, and can classify reliably objects from unseen domains. Specifically, our loss formulation maintains classification boundaries and suppresses the domain-specific information of each class. With no old exemplars stored, we use knowledge distillation and estimate old class prototype drift as incremental training advances. Our prototype representations are based on multivariate Normal distributions whose means and covariances are constantly adapted to changing model features to represent old classes well by adapting to the feature space drift. For old classes, we sample pseudo-features from the adapted Normal distributions with the help of Cholesky decomposition. In contrast to previous pseudo-feature sampling strategies that rely solely on average mean prototypes, our method excels at capturing varying semantic information. Experiments on several benchmarks validate our claims.
More complex encoder is not all you need
Sep 21, 2023U-Net and its variants have been widely used in medical image segmentation. However, most current U-Net variants confine their improvement strategies to building more complex encoder, while leaving the decoder unchanged or adopting a simple symmetric structure. These approaches overlook the true functionality of the decoder: receiving low-resolution feature maps from the encoder and restoring feature map resolution and lost information through upsampling. As a result, the decoder, especially its upsampling component, plays a crucial role in enhancing segmentation outcomes. However, in 3D medical image segmentation, the commonly used transposed convolution can result in visual artifacts. This issue stems from the absence of direct relationship between adjacent pixels in the output feature map. Furthermore, plain encoder has already possessed sufficient feature extraction capability because downsampling operation leads to the gradual expansion of the receptive field, but the loss of information during downsampling process is unignorable. To address the gap in relevant research, we extend our focus beyond the encoder and introduce neU-Net (i.e., not complex encoder U-Net), which incorporates a novel Sub-pixel Convolution for upsampling to construct a powerful decoder. Additionally, we introduce multi-scale wavelet inputs module on the encoder side to provide additional information. Our model design achieves excellent results, surpassing other state-of-the-art methods on both the Synapse and ACDC datasets.
Skip-Connected Neural Networks with Layout Graphs for Floor Plan Auto-Generation
Sep 26, 2023With the advent of AI and computer vision techniques, the quest for automated and efficient floor plan designs has gained momentum. This paper presents a novel approach using skip-connected neural networks integrated with layout graphs. The skip-connected layers capture multi-scale floor plan information, and the encoder-decoder networks with GNN facilitate pixel-level probability-based generation. Validated on the MSD dataset, our approach achieved a 93.9 mIoU score in the 1st CVAAD workshop challenge. Code and pre-trained models are publicly available at https://github.com/yuntaeJ/SkipNet-FloorPlanGe.
Hierarchy Builder: Organizing Textual Spans into a Hierarchy to Facilitate Navigation
Sep 18, 2023
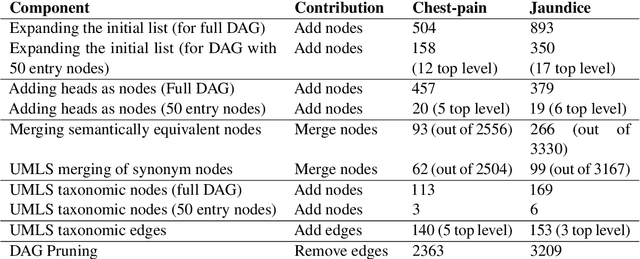
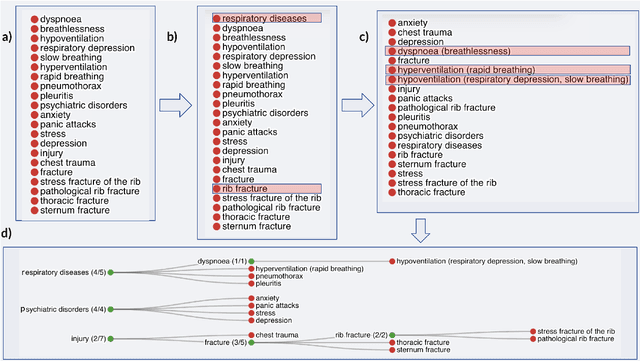
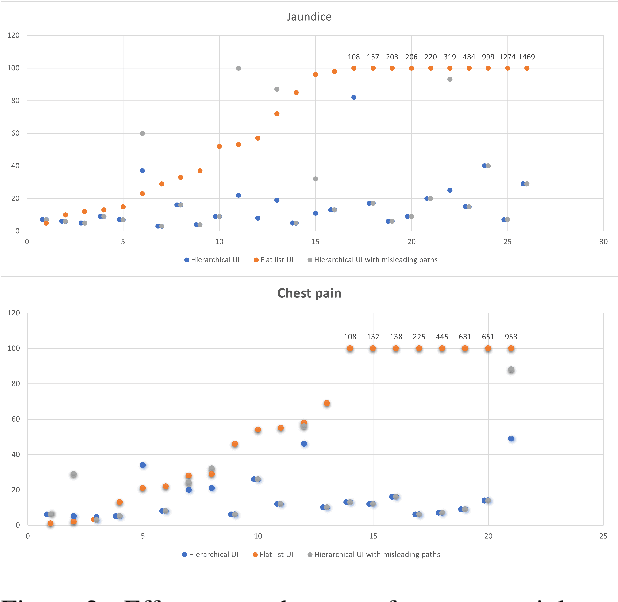
Information extraction systems often produce hundreds to thousands of strings on a specific topic. We present a method that facilitates better consumption of these strings, in an exploratory setting in which a user wants to both get a broad overview of what's available, and a chance to dive deeper on some aspects. The system works by grouping similar items together and arranging the remaining items into a hierarchical navigable DAG structure. We apply the method to medical information extraction.
* 9 pages including citations; Presented at the ACL 2023 DEMO track, pages 282-290
UWA360CAM: A 360$^{\circ}$ 24/7 Real-Time Streaming Camera System for Underwater Applications
Sep 30, 2023


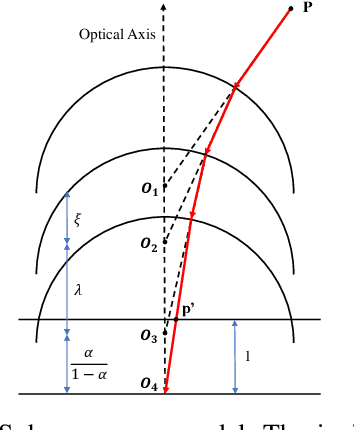
Omnidirectional camera is a cost-effective and information-rich sensor highly suitable for many marine applications and the ocean scientific community, encompassing several domains such as augmented reality, mapping, motion estimation, visual surveillance, and simultaneous localization and mapping. However, designing and constructing such a high-quality 360$^{\circ}$ real-time streaming camera system for underwater applications is a challenging problem due to the technical complexity in several aspects including sensor resolution, wide field of view, power supply, optical design, system calibration, and overheating management. This paper presents a novel and comprehensive system that addresses the complexities associated with the design, construction, and implementation of a fully functional 360$^{\circ}$ real-time streaming camera system specifically tailored for underwater environments. Our proposed system, UWA360CAM, can stream video in real time, operate in 24/7, and capture 360$^{\circ}$ underwater panorama images. Notably, our work is the pioneering effort in providing a detailed and replicable account of this system. The experiments provide a comprehensive analysis of our proposed system.
Black-box Attacks on Image Activity Prediction and its Natural Language Explanations
Sep 30, 2023Explainable AI (XAI) methods aim to describe the decision process of deep neural networks. Early XAI methods produced visual explanations, whereas more recent techniques generate multimodal explanations that include textual information and visual representations. Visual XAI methods have been shown to be vulnerable to white-box and gray-box adversarial attacks, with an attacker having full or partial knowledge of and access to the target system. As the vulnerabilities of multimodal XAI models have not been examined, in this paper we assess for the first time the robustness to black-box attacks of the natural language explanations generated by a self-rationalizing image-based activity recognition model. We generate unrestricted, spatially variant perturbations that disrupt the association between the predictions and the corresponding explanations to mislead the model into generating unfaithful explanations. We show that we can create adversarial images that manipulate the explanations of an activity recognition model by having access only to its final output.
UPAR: A Kantian-Inspired Prompting Framework for Enhancing Large Language Model Capabilities
Sep 30, 2023Large Language Models (LLMs) have demonstrated impressive inferential capabilities, with numerous research endeavors devoted to enhancing this capacity through prompting. Despite these efforts, a unified epistemological foundation is still conspicuously absent. Drawing inspiration from Kant's a priori philosophy, we propose the UPAR prompting framework, designed to emulate the structure of human cognition within LLMs. The UPAR framework is delineated into four phases: "Understand", "Plan", "Act", and "Reflect", enabling the extraction of structured information from complex contexts, prior planning of solutions, execution according to plan, and self-reflection. This structure significantly augments the explainability and accuracy of LLM inference, producing a human-understandable and inspectable inferential trajectory. Furthermore, our work offers an epistemological foundation for existing prompting techniques, allowing for a possible systematic integration of these methods. With GPT-4, our approach elevates the accuracy from COT baseline of 22.92% to 58.33% in a challenging subset of GSM8K, and from 67.91% to 75.40% in the causal judgment task.
Dual-Augmented Transformer Network for Weakly Supervised Semantic Segmentation
Sep 30, 2023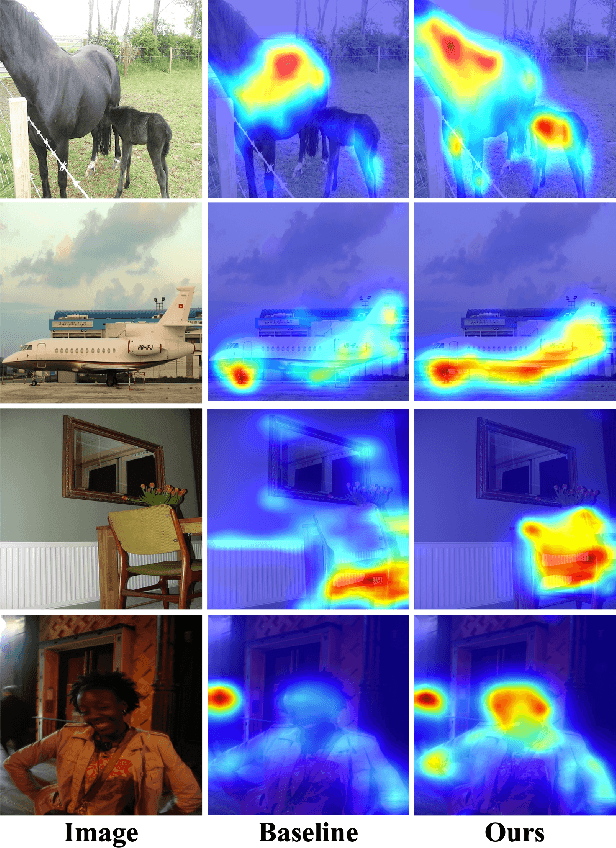
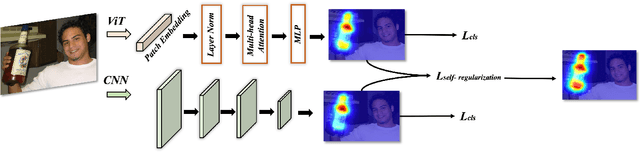

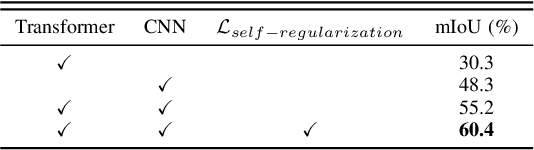
Weakly supervised semantic segmentation (WSSS), a fundamental computer vision task, which aims to segment out the object within only class-level labels. The traditional methods adopt the CNN-based network and utilize the class activation map (CAM) strategy to discover the object regions. However, such methods only focus on the most discriminative region of the object, resulting in incomplete segmentation. An alternative is to explore vision transformers (ViT) to encode the image to acquire the global semantic information. Yet, the lack of transductive bias to objects is a flaw of ViT. In this paper, we explore the dual-augmented transformer network with self-regularization constraints for WSSS. Specifically, we propose a dual network with both CNN-based and transformer networks for mutually complementary learning, where both networks augment the final output for enhancement. Massive systemic evaluations on the challenging PASCAL VOC 2012 benchmark demonstrate the effectiveness of our method, outperforming previous state-of-the-art methods.