 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhancing Lithological Mapping with Spatially Constrained Bayesian Network (SCB-Net): An Approach for Field Data-Constrained Predictions with Uncertainty Evaluation
Mar 29, 2024
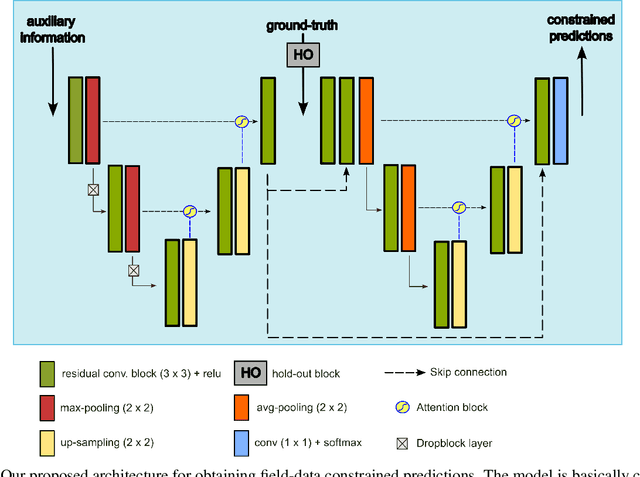
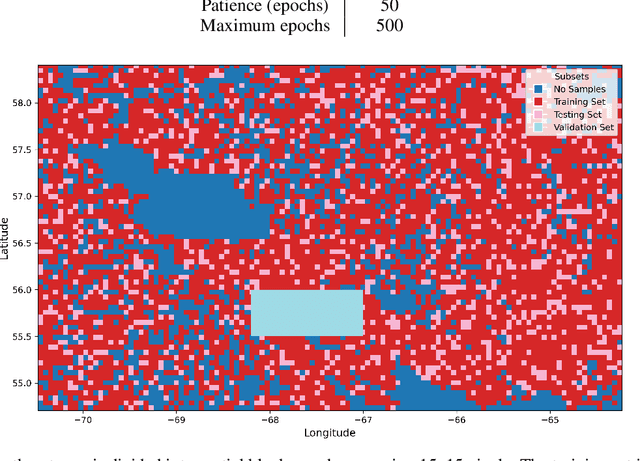

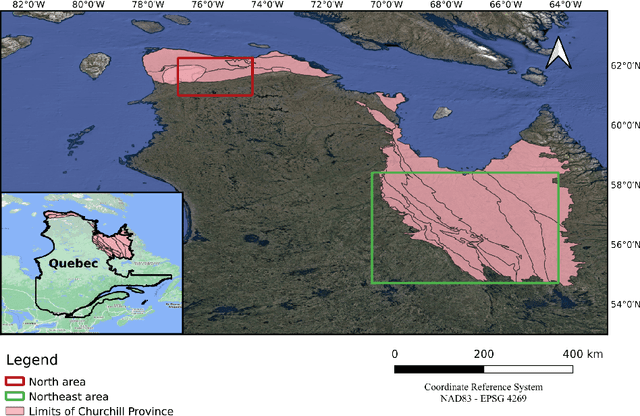
Geological maps are an extremely valuable source of information for the Earth sciences. They provide insights into mineral exploration, vulnerability to natural hazards, and many other applications. These maps are created using numerical or conceptual models that use geological observations to extrapolate data. Geostatistical techniques have traditionally been used to generate reliable predictions that take into account the spatial patterns inherent in the data. However, as the number of auxiliary variables increases, these methods become more labor-intensive. Additionally, traditional machine learning methods often struggle with spatially correlated data and extracting valuable non-linear information from geoscientific datasets. To address these limitations, a new architecture called the Spatially Constrained Bayesian Network (SCB-Net) has been developed. The SCB-Net aims to effectively exploit the information from auxiliary variables while producing spatially constrained predictions. It is made up of two parts, the first part focuses on learning underlying patterns in the auxiliary variables while the second part integrates ground-truth data and the learned embeddings from the first part. Moreover, to assess model uncertainty, a technique called Monte Carlo dropout is used as a Bayesian approximation. The SCB-Net has been applied to two selected areas in northern Quebec, Canada, and has demonstrated its potential in generating field-data-constrained lithological maps while allowing assessment of prediction uncertainty for decision-making. This study highlights the promising advancements of deep neural networks in geostatistics, particularly in handling complex spatial feature learning tasks, leading to improved spatial information techniques.
APEX: Ambidextrous Dual-Arm Robotic Manipulation Using Collision-Free Generative Diffusion Models
Apr 02, 2024Dexterous manipulation, particularly adept coordinating and grasping, constitutes a fundamental and indispensable capability for robots, facilitating the emulation of human-like behaviors. Integrating this capability into robots empowers them to supplement and even supplant humans in undertaking increasingly intricate tasks in both daily life and industrial settings. Unfortunately, contemporary methodologies encounter serious challenges in devising manipulation trajectories owing to the intricacies of tasks, the expansive robotic manipulation space, and dynamic obstacles. We propose a novel approach, APEX, to address all these difficulties by introducing a collision-free latent diffusion model for both robotic motion planning and manipulation. Firstly, we simplify the complexity of real-life ambidextrous dual-arm robotic manipulation tasks by abstracting them as aligning two vectors. Secondly, we devise latent diffusion models to produce a variety of robotic manipulation trajectories. Furthermore, we integrate obstacle information utilizing a classifier-guidance technique, thereby guaranteeing both the feasibility and safety of the generated manipulation trajectories. Lastly, we validate our proposed algorithm through extensive experiments conducted on the hardware platform of ambidextrous dual-arm robots. Our algorithm consistently generates successful and seamless trajectories across diverse tasks, surpassing conventional robotic motion planning algorithms. These results carry significant implications for the future design of diffusion robots, enhancing their capability to tackle more intricate robotic manipulation tasks with increased efficiency and safety. Complete video demonstrations of our experiments can be found in https://sites.google.com/view/apex-dual-arm/home.
Where to Move Next: Zero-shot Generalization of LLMs for Next POI Recommendation
Apr 02, 2024Next Point-of-interest (POI) recommendation provides valuable suggestions for users to explore their surrounding environment. Existing studies rely on building recommendation models from large-scale users' check-in data, which is task-specific and needs extensive computational resources. Recently, the pretrained large language models (LLMs) have achieved significant advancements in various NLP tasks and have also been investigated for recommendation scenarios. However, the generalization abilities of LLMs still are unexplored to address the next POI recommendations, where users' geographical movement patterns should be extracted. Although there are studies that leverage LLMs for next-item recommendations, they fail to consider the geographical influence and sequential transitions. Hence, they cannot effectively solve the next POI recommendation task. To this end, we design novel prompting strategies and conduct empirical studies to assess the capability of LLMs, e.g., ChatGPT, for predicting a user's next check-in. Specifically, we consider several essential factors in human movement behaviors, including user geographical preference, spatial distance, and sequential transitions, and formulate the recommendation task as a ranking problem. Through extensive experiments on two widely used real-world datasets, we derive several key findings. Empirical evaluations demonstrate that LLMs have promising zero-shot recommendation abilities and can provide accurate and reasonable predictions. We also reveal that LLMs cannot accurately comprehend geographical context information and are sensitive to the order of presentation of candidate POIs, which shows the limitations of LLMs and necessitates further research on robust human mobility reasoning mechanisms.
Plaintext-Free Deep Learning for Privacy-Preserving Medical Image Analysis via Frequency Information Embedding
Mar 25, 2024In the fast-evolving field of medical image analysis, Deep Learning (DL)-based methods have achieved tremendous success. However, these methods require plaintext data for training and inference stages, raising privacy concerns, especially in the sensitive area of medical data. To tackle these concerns, this paper proposes a novel framework that uses surrogate images for analysis, eliminating the need for plaintext images. This approach is called Frequency-domain Exchange Style Fusion (FESF). The framework includes two main components: Image Hidden Module (IHM) and Image Quality Enhancement Module~(IQEM). The~IHM performs in the frequency domain, blending the features of plaintext medical images into host medical images, and then combines this with IQEM to improve and create surrogate images effectively. During the diagnostic model training process, only surrogate images are used, enabling anonymous analysis without any plaintext data during both training and inference stages. Extensive evaluations demonstrate that our framework effectively preserves the privacy of medical images and maintains diagnostic accuracy of DL models at a relatively high level, proving its effectiveness across various datasets and DL-based models.
SpikeMba: Multi-Modal Spiking Saliency Mamba for Temporal Video Grounding
Apr 01, 2024Temporal video grounding (TVG) is a critical task in video content understanding. Despite significant advancements, existing methods often limit in capturing the fine-grained relationships between multimodal inputs and the high computational costs with processing long video sequences. To address these limitations, we introduce a novel SpikeMba: multi-modal spiking saliency mamba for temporal video grounding. In our work, we integrate the Spiking Neural Networks (SNNs) and state space models (SSMs) to capture the fine-grained relationships of multimodal features effectively. Specifically, we introduce the relevant slots to enhance the model's memory capabilities, enabling a deeper contextual understanding of video sequences. The contextual moment reasoner leverages these slots to maintain a balance between contextual information preservation and semantic relevance exploration. Simultaneously, the spiking saliency detector capitalizes on the unique properties of SNNs to accurately locate salient proposals. Our experiments demonstrate the effectiveness of SpikeMba, which consistently outperforms state-of-the-art methods across mainstream benchmarks.
STAR-RIS Aided Secure MIMO Communication Systems
Apr 01, 2024This paper investigates simultaneous transmission and reflection reconfigurable intelligent surface (STAR-RIS) aided physical layer security (PLS) in multiple-input multiple-output (MIMO) systems, where the base station (BS) transmits secrecy information with the aid of STAR-RIS against multiple eavesdroppers equipped with multiple antennas. We aim to maximize the secrecy rate by jointly optimizing the active beamforming at the BS and passive beamforming at the STAR-RIS, subject to the hardware constraint for STAR-RIS. To handle the coupling variables, a minimum mean-square error (MMSE) based alternating optimization (AO) algorithm is applied. In particular, the amplitudes and phases of STAR-RIS are divided into two blocks to simplify the algorithm design. Besides, by applying the Majorization-Minimization (MM) method, we derive a closed-form expression of the STAR-RIS's phase shifts. Numerical results show that the proposed scheme significantly outperforms various benchmark schemes, especially as the number of STAR-RIS elements increases.
NVINS: Robust Visual Inertial Navigation Fused with NeRF-augmented Camera Pose Regressor and Uncertainty Quantification
Apr 01, 2024In recent years, Neural Radiance Fields (NeRF) have emerged as a powerful tool for 3D reconstruction and novel view synthesis. However, the computational cost of NeRF rendering and degradation in quality due to the presence of artifacts pose significant challenges for its application in real-time and robust robotic tasks, especially on embedded systems. This paper introduces a novel framework that integrates NeRF-derived localization information with Visual-Inertial Odometry(VIO) to provide a robust solution for robotic navigation in a real-time. By training an absolute pose regression network with augmented image data rendered from a NeRF and quantifying its uncertainty, our approach effectively counters positional drift and enhances system reliability. We also establish a mathematically sound foundation for combining visual inertial navigation with camera localization neural networks, considering uncertainty under a Bayesian framework. Experimental validation in the photorealistic simulation environment demonstrates significant improvements in accuracy compared to a conventional VIO approach.
Statistical Inference For Noisy Matrix Completion Incorporating Auxiliary Information
Mar 22, 2024This paper investigates statistical inference for noisy matrix completion in a semi-supervised model when auxiliary covariates are available. The model consists of two parts. One part is a low-rank matrix induced by unobserved latent factors; the other part models the effects of the observed covariates through a coefficient matrix which is composed of high-dimensional column vectors. We model the observational pattern of the responses through a logistic regression of the covariates, and allow its probability to go to zero as the sample size increases. We apply an iterative least squares (LS) estimation approach in our considered context. The iterative LS methods in general enjoy a low computational cost, but deriving the statistical properties of the resulting estimators is a challenging task. We show that our method only needs a few iterations, and the resulting entry-wise estimators of the low-rank matrix and the coefficient matrix are guaranteed to have asymptotic normal distributions. As a result, individual inference can be conducted for each entry of the unknown matrices. We also propose a simultaneous testing procedure with multiplier bootstrap for the high-dimensional coefficient matrix. This simultaneous inferential tool can help us further investigate the effects of covariates for the prediction of missing entries.
DOCMASTER: A Unified Platform for Annotation, Training, & Inference in Document Question-Answering
Mar 30, 2024The application of natural language processing models to PDF documents is pivotal for various business applications yet the challenge of training models for this purpose persists in businesses due to specific hurdles. These include the complexity of working with PDF formats that necessitate parsing text and layout information for curating training data and the lack of privacy-preserving annotation tools. This paper introduces DOCMASTER, a unified platform designed for annotating PDF documents, model training, and inference, tailored to document question-answering. The annotation interface enables users to input questions and highlight text spans within the PDF file as answers, saving layout information and text spans accordingly. Furthermore, DOCMASTER supports both state-of-the-art layout-aware and text models for comprehensive training purposes. Importantly, as annotations, training, and inference occur on-device, it also safeguards privacy. The platform has been instrumental in driving several research prototypes concerning document analysis such as the AI assistant utilized by University of California San Diego's (UCSD) International Services and Engagement Office (ISEO) for processing a substantial volume of PDF documents.
Generate then Retrieve: Conversational Response Retrieval Using LLMs as Answer and Query Generators
Mar 28, 2024CIS is a prominent area in IR that focuses on developing interactive knowledge assistants. These systems must adeptly comprehend the user's information requirements within the conversational context and retrieve the relevant information. To this aim, the existing approaches model the user's information needs with one query called rewritten query and use this query for passage retrieval. In this paper, we propose three different methods for generating multiple queries to enhance the retrieval. In these methods, we leverage the capabilities of large language models (LLMs) in understanding the user's information need and generating an appropriate response, to generate multiple queries. We implement and evaluate the proposed models utilizing various LLMs including GPT-4 and Llama-2 chat in zero-shot and few-shot settings. In addition, we propose a new benchmark for TREC iKAT based on gpt 3.5 judgments. Our experiments reveal the effectiveness of our proposed models on the TREC iKAT dataset.