 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Tracking electricity losses and their perceived causes using nighttime light and social media
Oct 18, 2023
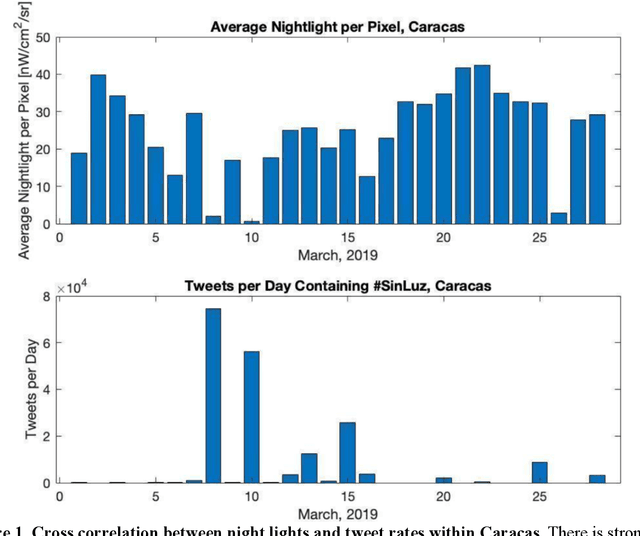
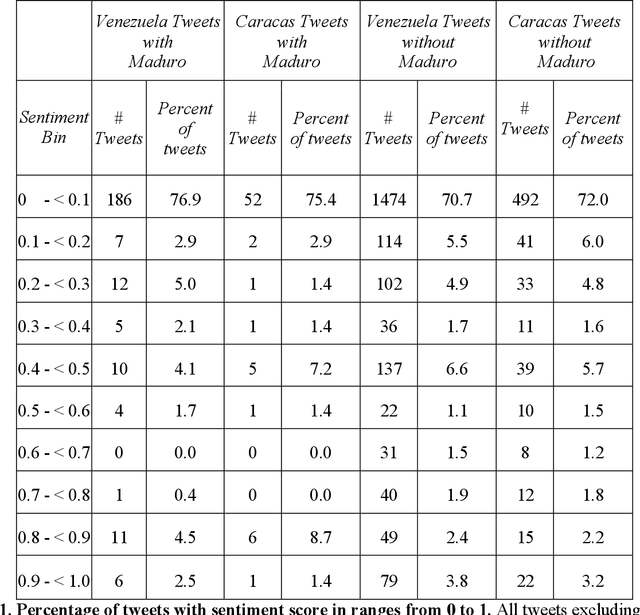

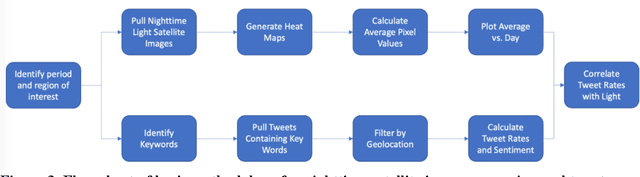
Urban environments are intricate systems where the breakdown of critical infrastructure can impact both the economic and social well-being of communities. Electricity systems hold particular significance, as they are essential for other infrastructure, and disruptions can trigger widespread consequences. Typically, assessing electricity availability requires ground-level data, a challenge in conflict zones and regions with limited access. This study shows how satellite imagery, social media, and information extraction can monitor blackouts and their perceived causes. Night-time light data (in March 2019 for Caracas, Venezuela) is used to indicate blackout regions. Twitter data is used to determine sentiment and topic trends, while statistical analysis and topic modeling delved into public perceptions regarding blackout causes. The findings show an inverse relationship between nighttime light intensity. Tweets mentioning the Venezuelan President displayed heightened negativity and a greater prevalence of blame-related terms, suggesting a perception of government accountability for the outages.
Graph Neural Networks for Recommendation: Reproducibility, Graph Topology, and Node Representation
Oct 18, 2023Graph neural networks (GNNs) have gained prominence in recommendation systems in recent years. By representing the user-item matrix as a bipartite and undirected graph, GNNs have demonstrated their potential to capture short- and long-distance user-item interactions, thereby learning more accurate preference patterns than traditional recommendation approaches. In contrast to previous tutorials on the same topic, this tutorial aims to present and examine three key aspects that characterize GNNs for recommendation: (i) the reproducibility of state-of-the-art approaches, (ii) the potential impact of graph topological characteristics on the performance of these models, and (iii) strategies for learning node representations when training features from scratch or utilizing pre-trained embeddings as additional item information (e.g., multimodal features). The goal is to provide three novel theoretical and practical perspectives on the field, currently subject to debate in graph learning but long been overlooked in the context of recommendation systems.
Enhancing Conversational Search: Large Language Model-Aided Informative Query Rewriting
Oct 18, 2023Query rewriting plays a vital role in enhancing conversational search by transforming context-dependent user queries into standalone forms. Existing approaches primarily leverage human-rewritten queries as labels to train query rewriting models. However, human rewrites may lack sufficient information for optimal retrieval performance. To overcome this limitation, we propose utilizing large language models (LLMs) as query rewriters, enabling the generation of informative query rewrites through well-designed instructions. We define four essential properties for well-formed rewrites and incorporate all of them into the instruction. In addition, we introduce the role of rewrite editors for LLMs when initial query rewrites are available, forming a "rewrite-then-edit" process. Furthermore, we propose distilling the rewriting capabilities of LLMs into smaller models to reduce rewriting latency. Our experimental evaluation on the QReCC dataset demonstrates that informative query rewrites can yield substantially improved retrieval performance compared to human rewrites, especially with sparse retrievers.
MMTF-DES: A Fusion of Multimodal Transformer Models for Desire, Emotion, and Sentiment Analysis of Social Media Data
Oct 22, 2023Desire is a set of human aspirations and wishes that comprise verbal and cognitive aspects that drive human feelings and behaviors, distinguishing humans from other animals. Understanding human desire has the potential to be one of the most fascinating and challenging research domains. It is tightly coupled with sentiment analysis and emotion recognition tasks. It is beneficial for increasing human-computer interactions, recognizing human emotional intelligence, understanding interpersonal relationships, and making decisions. However, understanding human desire is challenging and under-explored because ways of eliciting desire might be different among humans. The task gets more difficult due to the diverse cultures, countries, and languages. Prior studies overlooked the use of image-text pairwise feature representation, which is crucial for the task of human desire understanding. In this research, we have proposed a unified multimodal transformer-based framework with image-text pair settings to identify human desire, sentiment, and emotion. The core of our proposed method lies in the encoder module, which is built using two state-of-the-art multimodal transformer models. These models allow us to extract diverse features. To effectively extract visual and contextualized embedding features from social media image and text pairs, we conducted joint fine-tuning of two pre-trained multimodal transformer models: Vision-and-Language Transformer (ViLT) and Vision-and-Augmented-Language Transformer (VAuLT). Subsequently, we use an early fusion strategy on these embedding features to obtain combined diverse feature representations of the image-text pair. This consolidation incorporates diverse information about this task, enabling us to robustly perceive the context and image pair from multiple perspectives.
Towards Harmful Erotic Content Detection through Coreference-Driven Contextual Analysis
Oct 22, 2023Adult content detection still poses a great challenge for automation. Existing classifiers primarily focus on distinguishing between erotic and non-erotic texts. However, they often need more nuance in assessing the potential harm. Unfortunately, the content of this nature falls beyond the reach of generative models due to its potentially harmful nature. Ethical restrictions prohibit large language models (LLMs) from analyzing and classifying harmful erotics, let alone generating them to create synthetic datasets for other neural models. In such instances where data is scarce and challenging, a thorough analysis of the structure of such texts rather than a large model may offer a viable solution. Especially given that harmful erotic narratives, despite appearing similar to harmless ones, usually reveal their harmful nature first through contextual information hidden in the non-sexual parts of the narrative. This paper introduces a hybrid neural and rule-based context-aware system that leverages coreference resolution to identify harmful contextual cues in erotic content. Collaborating with professional moderators, we compiled a dataset and developed a classifier capable of distinguishing harmful from non-harmful erotic content. Our hybrid model, tested on Polish text, demonstrates a promising accuracy of 84% and a recall of 80%. Models based on RoBERTa and Longformer without explicit usage of coreference chains achieved significantly weaker results, underscoring the importance of coreference resolution in detecting such nuanced content as harmful erotics. This approach also offers the potential for enhanced visual explainability, supporting moderators in evaluating predictions and taking necessary actions to address harmful content.
NERetrieve: Dataset for Next Generation Named Entity Recognition and Retrieval
Oct 22, 2023Recognizing entities in texts is a central need in many information-seeking scenarios, and indeed, Named Entity Recognition (NER) is arguably one of the most successful examples of a widely adopted NLP task and corresponding NLP technology. Recent advances in large language models (LLMs) appear to provide effective solutions (also) for NER tasks that were traditionally handled with dedicated models, often matching or surpassing the abilities of the dedicated models. Should NER be considered a solved problem? We argue to the contrary: the capabilities provided by LLMs are not the end of NER research, but rather an exciting beginning. They allow taking NER to the next level, tackling increasingly more useful, and increasingly more challenging, variants. We present three variants of the NER task, together with a dataset to support them. The first is a move towards more fine-grained -- and intersectional -- entity types. The second is a move towards zero-shot recognition and extraction of these fine-grained types based on entity-type labels. The third, and most challenging, is the move from the recognition setup to a novel retrieval setup, where the query is a zero-shot entity type, and the expected result is all the sentences from a large, pre-indexed corpus that contain entities of these types, and their corresponding spans. We show that all of these are far from being solved. We provide a large, silver-annotated corpus of 4 million paragraphs covering 500 entity types, to facilitate research towards all of these three goals.
Fairness-aware Optimal Graph Filter Design
Oct 22, 2023Graphs are mathematical tools that can be used to represent complex real-world interconnected systems, such as financial markets and social networks. Hence, machine learning (ML) over graphs has attracted significant attention recently. However, it has been demonstrated that ML over graphs amplifies the already existing bias towards certain under-represented groups in various decision-making problems due to the information aggregation over biased graph structures. Faced with this challenge, here we take a fresh look at the problem of bias mitigation in graph-based learning by borrowing insights from graph signal processing. Our idea is to introduce predesigned graph filters within an ML pipeline to reduce a novel unsupervised bias measure, namely the correlation between sensitive attributes and the underlying graph connectivity. We show that the optimal design of said filters can be cast as a convex problem in the graph spectral domain. We also formulate a linear programming (LP) problem informed by a theoretical bias analysis, which attains a closed-form solution and leads to a more efficient fairness-aware graph filter. Finally, for a design whose degrees of freedom are independent of the input graph size, we minimize the bias metric over the family of polynomial graph convolutional filters. Our optimal filter designs offer complementary strengths to explore favorable fairness-utility-complexity tradeoffs. For performance evaluation, we conduct extensive and reproducible node classification experiments over real-world networks. Our results show that the proposed framework leads to better fairness measures together with similar utility compared to state-of-the-art fairness-aware baselines.
Burning the Adversarial Bridges: Robust Windows Malware Detection Against Binary-level Mutations
Oct 05, 2023Toward robust malware detection, we explore the attack surface of existing malware detection systems. We conduct root-cause analyses of the practical binary-level black-box adversarial malware examples. Additionally, we uncover the sensitivity of volatile features within the detection engines and exhibit their exploitability. Highlighting volatile information channels within the software, we introduce three software pre-processing steps to eliminate the attack surface, namely, padding removal, software stripping, and inter-section information resetting. Further, to counter the emerging section injection attacks, we propose a graph-based section-dependent information extraction scheme for software representation. The proposed scheme leverages aggregated information within various sections in the software to enable robust malware detection and mitigate adversarial settings. Our experimental results show that traditional malware detection models are ineffective against adversarial threats. However, the attack surface can be largely reduced by eliminating the volatile information. Therefore, we propose simple-yet-effective methods to mitigate the impacts of binary manipulation attacks. Overall, our graph-based malware detection scheme can accurately detect malware with an area under the curve score of 88.32\% and a score of 88.19% under a combination of binary manipulation attacks, exhibiting the efficiency of our proposed scheme.
BioT5: Enriching Cross-modal Integration in Biology with Chemical Knowledge and Natural Language Associations
Oct 11, 2023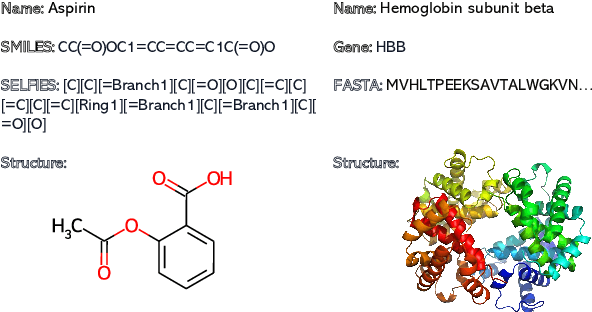
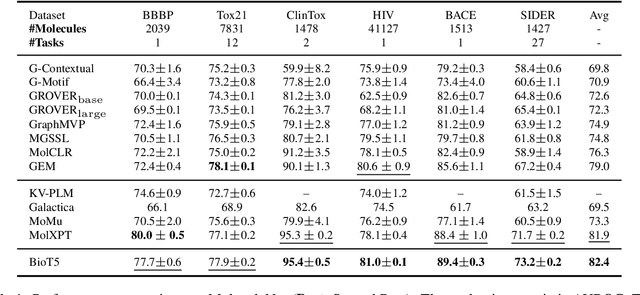
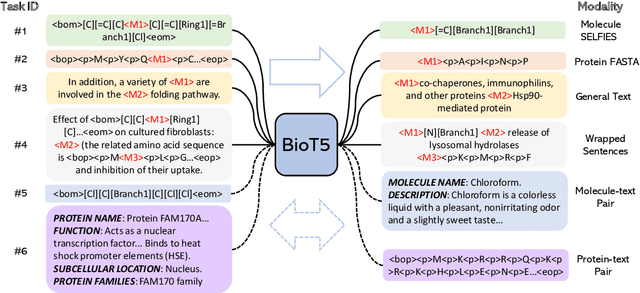
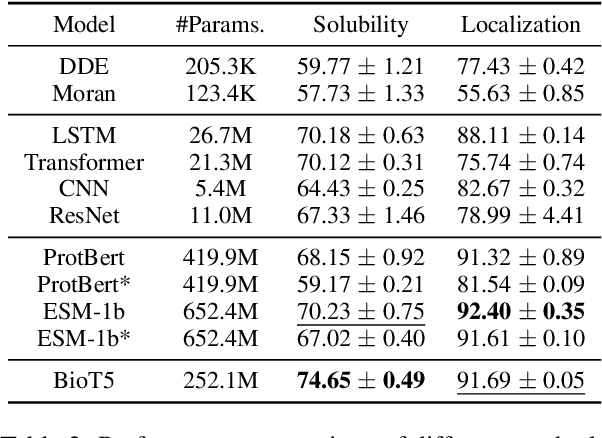
Recent advancements in biological research leverage the integration of molecules, proteins, and natural language to enhance drug discovery. However, current models exhibit several limitations, such as the generation of invalid molecular SMILES, underutilization of contextual information, and equal treatment of structured and unstructured knowledge. To address these issues, we propose $\mathbf{BioT5}$, a comprehensive pre-training framework that enriches cross-modal integration in biology with chemical knowledge and natural language associations. $\mathbf{BioT5}$ utilizes SELFIES for $100%$ robust molecular representations and extracts knowledge from the surrounding context of bio-entities in unstructured biological literature. Furthermore, $\mathbf{BioT5}$ distinguishes between structured and unstructured knowledge, leading to more effective utilization of information. After fine-tuning, BioT5 shows superior performance across a wide range of tasks, demonstrating its strong capability of capturing underlying relations and properties of bio-entities. Our code is available at $\href{https://github.com/QizhiPei/BioT5}{Github}$.
Blending gradient boosted trees and neural networks for point and probabilistic forecasting of hierarchical time series
Oct 19, 2023In this paper we tackle the problem of point and probabilistic forecasting by describing a blending methodology of machine learning models that belong to gradient boosted trees and neural networks families. These principles were successfully applied in the recent M5 Competition on both Accuracy and Uncertainty tracks. The keypoints of our methodology are: a) transform the task to regression on sales for a single day b) information rich feature engineering c) create a diverse set of state-of-the-art machine learning models and d) carefully construct validation sets for model tuning. We argue that the diversity of the machine learning models along with the careful selection of validation examples, where the most important ingredients for the effectiveness of our approach. Although forecasting data had an inherent hierarchy structure (12 levels), none of our proposed solutions exploited that hierarchical scheme. Using the proposed methodology, our team was ranked within the gold medal range in both Accuracy and the Uncertainty track. Inference code along with already trained models are available at https://github.com/IoannisNasios/M5_Uncertainty_3rd_place