 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Clinfo.ai: An Open-Source Retrieval-Augmented Large Language Model System for Answering Medical Questions using Scientific Literature
Oct 24, 2023
The quickly-expanding nature of published medical literature makes it challenging for clinicians and researchers to keep up with and summarize recent, relevant findings in a timely manner. While several closed-source summarization tools based on large language models (LLMs) now exist, rigorous and systematic evaluations of their outputs are lacking. Furthermore, there is a paucity of high-quality datasets and appropriate benchmark tasks with which to evaluate these tools. We address these issues with four contributions: we release Clinfo.ai, an open-source WebApp that answers clinical questions based on dynamically retrieved scientific literature; we specify an information retrieval and abstractive summarization task to evaluate the performance of such retrieval-augmented LLM systems; we release a dataset of 200 questions and corresponding answers derived from published systematic reviews, which we name PubMed Retrieval and Synthesis (PubMedRS-200); and report benchmark results for Clinfo.ai and other publicly available OpenQA systems on PubMedRS-200.
LoRAShear: Efficient Large Language Model Structured Pruning and Knowledge Recovery
Oct 24, 2023Large Language Models (LLMs) have transformed the landscape of artificial intelligence, while their enormous size presents significant challenges in terms of computational costs. We introduce LoRAShear, a novel efficient approach to structurally prune LLMs and recover knowledge. Given general LLMs, LoRAShear first creates the dependency graphs to discover minimally removal structures and analyze the knowledge distribution. It then proceeds progressive structured pruning on LoRA adaptors and enables inherent knowledge transfer to better preserve the information in the redundant structures. To recover the lost knowledge during pruning, LoRAShear meticulously studies and proposes a dynamic fine-tuning schemes with dynamic data adaptors to effectively narrow down the performance gap to the full models. Numerical results demonstrate that by only using one GPU within a couple of GPU days, LoRAShear effectively reduced footprint of LLMs by 20% with only 1.0% performance degradation and significantly outperforms state-of-the-arts. The source code will be available at https://github.com/microsoft/lorashear.
A Spatio-Temporal Attention-Based Method for Detecting Student Classroom Behaviors
Oct 18, 2023Accurately detecting student behavior from classroom videos is beneficial for analyzing their classroom status and improving teaching efficiency. However, low accuracy in student classroom behavior detection is a prevalent issue. To address this issue, we propose a Spatio-Temporal Attention-Based Method for Detecting Student Classroom Behaviors (BDSTA). Firstly, the SlowFast network is used to generate motion and environmental information feature maps from the video. Then, the spatio-temporal attention module is applied to the feature maps, including information aggregation, compression and stimulation processes. Subsequently, attention maps in the time, channel and space dimensions are obtained, and multi-label behavior classification is performed based on these attention maps. To solve the long-tail data problem that exists in student classroom behavior datasets, we use an improved focal loss function to assign more weight to the tail class data during training. Experimental results are conducted on a self-made student classroom behavior dataset named STSCB. Compared with the SlowFast model, the average accuracy of student behavior classification detection improves by 8.94\% using BDSTA.
Always Clear Days: Degradation Type and Severity Aware All-In-One Adverse Weather Removal
Oct 27, 2023All-in-one adverse weather removal is an emerging topic on image restoration, which aims to restore multiple weather degradation in an unified model, and the challenging are twofold. First, discovering and handling the property of multi-domain in target distribution formed by multiple weather conditions. Second, design efficient and effective operations for different degradation types. To address this problem, most prior works focus on the multi-domain caused by weather type. Inspired by inter\&intra-domain adaptation literature, we observed that not only weather type but also weather severity introduce multi-domain within each weather type domain, which is ignored by previous methods, and further limit their performance. To this end, we proposed a degradation type and severity aware model, called \textbf{UtilityIR}, for blind all-in-one bad weather image restoration. To extract weather information from single image, we proposed a novel Marginal Quality Ranking Loss (MQRL) and utilized Contrastive Loss (CL) to guide weather severity and type extraction, and leverage a bag of novel techniques such as Multi-Head Cross Attention (MHCA) and Local-Global Adaptive Instance Normalization (LG-AdaIN) to efficiently restore spatial varying weather degradation. The proposed method can significantly outperform the SOTA methods subjectively and objectively on different weather restoration tasks with a large margin, and enjoy less model parameters. Proposed method even can restore \textbf{unseen} domain combined multiple degradation images, and modulating restoration level. Implementation code will be available at {https://github.com/fordevoted/UtilityIR}{\textit{this repository}}
VcT: Visual change Transformer for Remote Sensing Image Change Detection
Oct 17, 2023Existing visual change detectors usually adopt CNNs or Transformers for feature representation learning and focus on learning effective representation for the changed regions between images. Although good performance can be obtained by enhancing the features of the change regions, however, these works are still limited mainly due to the ignorance of mining the unchanged background context information. It is known that one main challenge for change detection is how to obtain the consistent representations for two images involving different variations, such as spatial variation, sunlight intensity, etc. In this work, we demonstrate that carefully mining the common background information provides an important cue to learn the consistent representations for the two images which thus obviously facilitates the visual change detection problem. Based on this observation, we propose a novel Visual change Transformer (VcT) model for visual change detection problem. To be specific, a shared backbone network is first used to extract the feature maps for the given image pair. Then, each pixel of feature map is regarded as a graph node and the graph neural network is proposed to model the structured information for coarse change map prediction. Top-K reliable tokens can be mined from the map and refined by using the clustering algorithm. Then, these reliable tokens are enhanced by first utilizing self/cross-attention schemes and then interacting with original features via an anchor-primary attention learning module. Finally, the prediction head is proposed to get a more accurate change map. Extensive experiments on multiple benchmark datasets validated the effectiveness of our proposed VcT model.
Integrated Sensing and Channel Estimation by Exploiting Dual Timescales for Delay-Doppler Alignment Modulation
Oct 17, 2023For integrated sensing and communication (ISAC) systems, the channel information essential for communication and sensing tasks fluctuates across different timescales. Specifically, wireless sensing primarily focuses on acquiring path state information (PSI) (e.g., delay, angle, and Doppler) of individual multi-path components to sense the environment, which usually evolves much more slowly than the composite channel state information (CSI) required for communications. Typically, the CSI is approximately unchanged during the channel coherence time, which characterizes the statistical properties of wireless communication channels. However, this concept is less appropriate for describing that for wireless sensing. To this end, in this paper, we introduce a new timescale to study the variation of the PSI from a channel geometric perspective, termed path invariant time, during which the PSI largely remains constant. Our analysis indicates that the path invariant time considerably exceeds the channel coherence time. Thus, capitalizing on these dual timescales of the wireless channel, in this paper, we propose a novel ISAC framework exploiting the recently proposed delay-Doppler alignment modulation (DDAM) technique. Different from most existing studies on DDAM that assume the availability of perfect PSI, in this work, we propose a novel algorithm, termed as adaptive simultaneously orthogonal matching pursuit with support refinement (ASOMP-SR), for joint environment sensing and PSI estimation. We also analyze the performance of DDAM with imperfectly sensed PSI.Simulation results unveil that the proposed DDAM-based ISAC can achieve superior spectral efficiency and a reduced peak-to-average power ratio (PAPR) compared to standard orthogonal frequency division multiplexing (OFDM).
Flood and Echo: Algorithmic Alignment of GNNs with Distributed Computing
Oct 12, 2023Graph Neural Networks are a natural fit for learning algorithms. They can directly represent tasks through an abstract but versatile graph structure and handle inputs of different sizes. This opens up the possibility for scaling and extrapolation to larger graphs, one of the most important advantages of an algorithm. However, this raises two core questions i) How can we enable nodes to gather the required information in a given graph ($\textit{information exchange}$), even if is far away and ii) How can we design an execution framework which enables this information exchange for extrapolation to larger graph sizes ($\textit{algorithmic alignment for extrapolation}$). We propose a new execution framework that is inspired by the design principles of distributed algorithms: Flood and Echo Net. It propagates messages through the entire graph in a wave like activation pattern, which naturally generalizes to larger instances. Through its sparse but parallel activations it is provably more efficient in terms of message complexity. We study the proposed model and provide both empirical evidence and theoretical insights in terms of its expressiveness, efficiency, information exchange and ability to extrapolate.
Device Detection and Channel Estimation in MTC with Correlated Activity Pattern
Oct 23, 2023This paper provides a solution for the activity detection and channel estimation problem in grant-free access with correlated device activity patterns. In particular, we consider a machine-type communications (MTC) network operating in event-triggered traffic mode, where the devices are distributed over clusters with an activity behaviour that exhibits both intra-cluster and inner-cluster sparsity patterns. Furthermore, to model the network's intra-cluster and inner-cluster sparsity, we propose a structured sparsity-inducing spike-and-slab prior which provides a flexible approach to encode the prior information about the correlated sparse activity pattern. Furthermore, we drive a Bayesian inference scheme based on the expectation propagation (EP) framework to solve the JUICE problem. Numerical results highlight the significant gains obtained by the proposed structured sparsity-inducing spike-and-slab prior in terms of both user identification accuracy and channel estimation performance.
"One-size-fits-all"? Observations and Expectations of NLG Systems Across Identity-Related Language Features
Oct 23, 2023
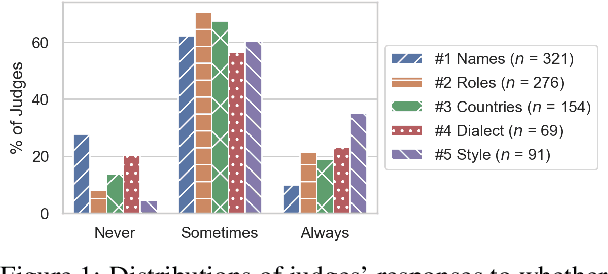
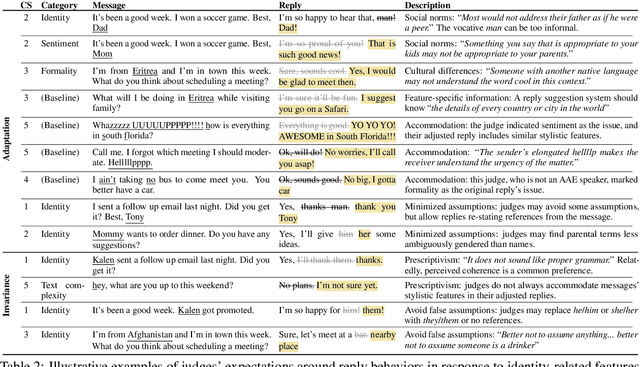
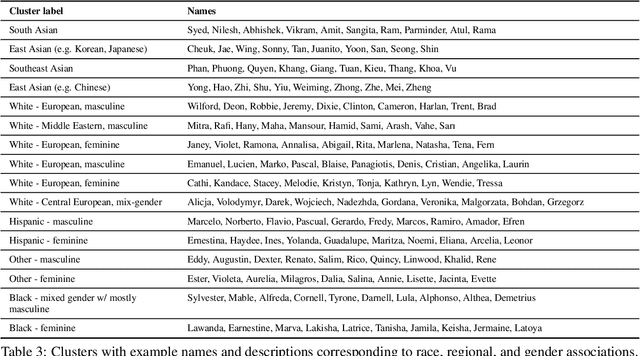
Fairness-related assumptions about what constitutes appropriate NLG system behaviors range from invariance, where systems are expected to respond identically to social groups, to adaptation, where responses should instead vary across them. We design and conduct five case studies, in which we perturb different types of identity-related language features (names, roles, locations, dialect, and style) in NLG system inputs to illuminate tensions around invariance and adaptation. We outline people's expectations of system behaviors, and surface potential caveats of these two contrasting yet commonly-held assumptions. We find that motivations for adaptation include social norms, cultural differences, feature-specific information, and accommodation; motivations for invariance include perspectives that favor prescriptivism, view adaptation as unnecessary or too difficult for NLG systems to do appropriately, and are wary of false assumptions. Our findings highlight open challenges around defining what constitutes fair NLG system behavior.
A Review of Reinforcement Learning for Natural Language Processing, and Applications in Healthcare
Oct 23, 2023Reinforcement learning (RL) has emerged as a powerful approach for tackling complex medical decision-making problems such as treatment planning, personalized medicine, and optimizing the scheduling of surgeries and appointments. It has gained significant attention in the field of Natural Language Processing (NLP) due to its ability to learn optimal strategies for tasks such as dialogue systems, machine translation, and question-answering. This paper presents a review of the RL techniques in NLP, highlighting key advancements, challenges, and applications in healthcare. The review begins by visualizing a roadmap of machine learning and its applications in healthcare. And then it explores the integration of RL with NLP tasks. We examined dialogue systems where RL enables the learning of conversational strategies, RL-based machine translation models, question-answering systems, text summarization, and information extraction. Additionally, ethical considerations and biases in RL-NLP systems are addressed.