 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RBF Weighted Hyper-Involution for RGB-D Object Detection
Sep 30, 2023
A vast majority of conventional augmented reality devices are equipped with depth sensors. Depth images produced by such sensors contain complementary information for object detection when used with color images. Despite the benefits, it remains a complex task to simultaneously extract photometric and depth features in real time due to the immanent difference between depth and color images. Moreover, standard convolution operations are not sufficient to properly extract information directly from raw depth images leading to intermediate representations of depth which is inefficient. To address these issues, we propose a real-time and two stream RGBD object detection model. The proposed model consists of two new components: a depth guided hyper-involution that adapts dynamically based on the spatial interaction pattern in the raw depth map and an up-sampling based trainable fusion layer that combines the extracted depth and color image features without blocking the information transfer between them. We show that the proposed model outperforms other RGB-D based object detection models on NYU Depth v2 dataset and achieves comparable (second best) results on SUN RGB-D. Additionally, we introduce a new outdoor RGB-D object detection dataset where our proposed model outperforms other models. The performance evaluation on diverse synthetic data generated from CAD models and images shows the potential of the proposed model to be adapted to augmented reality based applications.
Rethinking Data Perturbation and Model Stabilization for Semi-supervised Medical Image Segmentation
Aug 23, 2023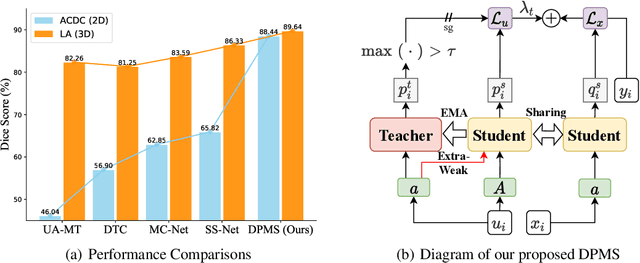

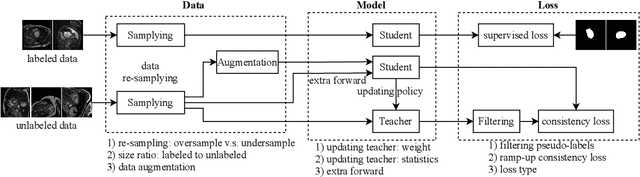
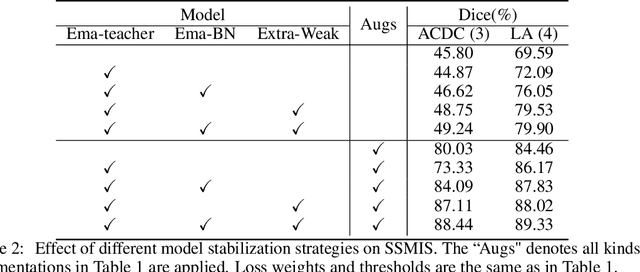
Studies on semi-supervised medical image segmentation (SSMIS) have seen fast progress recently. Due to the limited labelled data, SSMIS methods mainly focus on effectively leveraging unlabeled data to enhance the segmentation performance. However, despite their promising performance, current state-of-the-art methods often prioritize integrating complex techniques and loss terms rather than addressing the core challenges of semi-supervised scenarios directly. We argue that the key to SSMIS lies in generating substantial and appropriate prediction disagreement on unlabeled data. To this end, we emphasize the crutiality of data perturbation and model stabilization in semi-supervised segmentation, and propose a simple yet effective approach to boost SSMIS performance significantly, dubbed DPMS. Specifically, we first revisit SSMIS from three distinct perspectives: the data, the model, and the loss, and conduct a comprehensive study of corresponding strategies to examine their effectiveness. Based on these examinations, we then propose DPMS, which adopts a plain teacher-student framework with a standard supervised loss and unsupervised consistency loss. To produce appropriate prediction disagreements, DPMS perturbs the unlabeled data via strong augmentations to enlarge prediction disagreements considerably. On the other hand, using EMA teacher when strong augmentation is applied does not necessarily improve performance. DPMS further utilizes a forwarding-twice and momentum updating strategies for normalization statistics to stabilize the training on unlabeled data effectively. Despite its simplicity, DPMS can obtain new state-of-the-art performance on the public 2D ACDC and 3D LA datasets across various semi-supervised settings, e.g. obtaining a remarkable 22.62% improvement against previous SOTA on ACDC with 5% labels.
MaxSR: Image Super-Resolution Using Improved MaxViT
Jul 14, 2023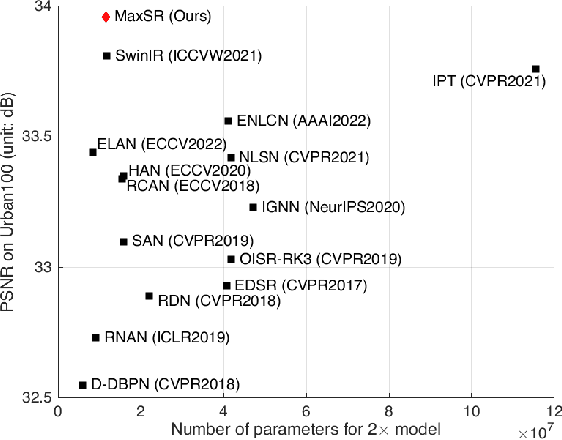

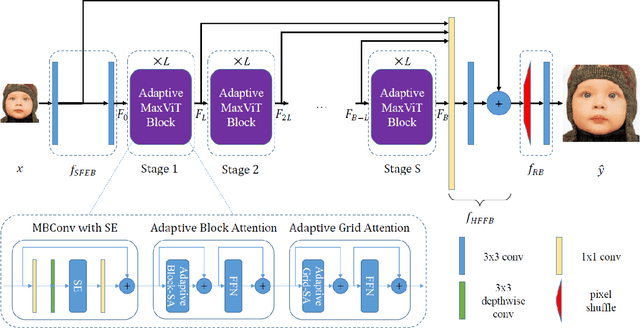
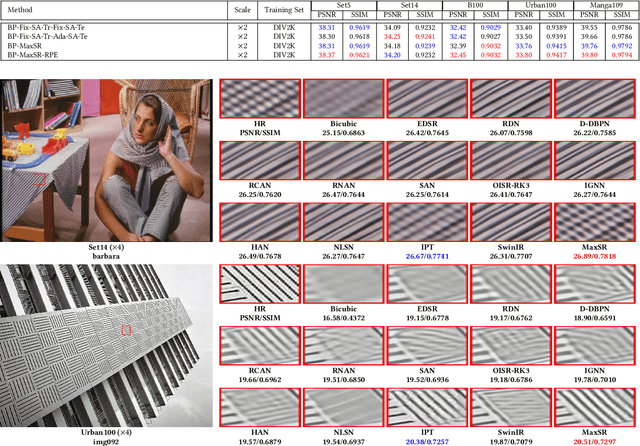
While transformer models have been demonstrated to be effective for natural language processing tasks and high-level vision tasks, only a few attempts have been made to use powerful transformer models for single image super-resolution. Because transformer models have powerful representation capacity and the in-built self-attention mechanisms in transformer models help to leverage self-similarity prior in input low-resolution image to improve performance for single image super-resolution, we present a single image super-resolution model based on recent hybrid vision transformer of MaxViT, named as MaxSR. MaxSR consists of four parts, a shallow feature extraction block, multiple cascaded adaptive MaxViT blocks to extract deep hierarchical features and model global self-similarity from low-level features efficiently, a hierarchical feature fusion block, and finally a reconstruction block. The key component of MaxSR, i.e., adaptive MaxViT block, is based on MaxViT block which mixes MBConv with squeeze-and-excitation, block attention and grid attention. In order to achieve better global modelling of self-similarity in input low-resolution image, we improve block attention and grid attention in MaxViT block to adaptive block attention and adaptive grid attention which do self-attention inside each window across all grids and each grid across all windows respectively in the most efficient way. We instantiate proposed model for classical single image super-resolution (MaxSR) and lightweight single image super-resolution (MaxSR-light). Experiments show that our MaxSR and MaxSR-light establish new state-of-the-art performance efficiently.
Temporal compressive edge imaging enabled by a lensless diffuser camera
Sep 13, 2023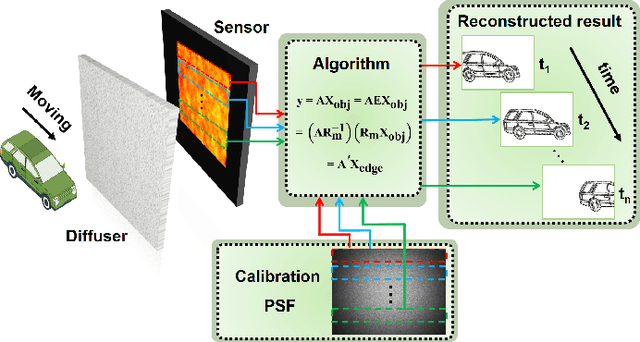

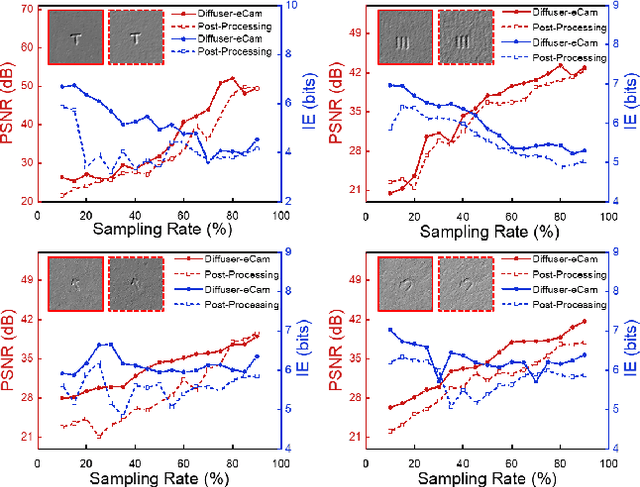

Lensless imagers based on diffusers or encoding masks enable high-dimensional imaging from a single shot measurement and have been applied in various applications. However, to further extract image information such as edge detection, conventional post-processing filtering operations are needed after the reconstruction of the original object images in the diffuser imaging systems. Here, we present the concept of a temporal compressive edge detection method based on a lensless diffuser camera, which can directly recover a time sequence of edge images of a moving object from a single-shot measurement, without further post-processing steps. Our approach provides higher image quality during edge detection, compared with the conventional post-processing method. We demonstrate the effectiveness of this approach by both numerical simulation and experiments. The proof-of-concept approach can be further developed with other image post-process operations or versatile computer vision assignments toward task-oriented intelligent lensless imaging systems.
More complex encoder is not all you need
Sep 21, 2023U-Net and its variants have been widely used in medical image segmentation. However, most current U-Net variants confine their improvement strategies to building more complex encoder, while leaving the decoder unchanged or adopting a simple symmetric structure. These approaches overlook the true functionality of the decoder: receiving low-resolution feature maps from the encoder and restoring feature map resolution and lost information through upsampling. As a result, the decoder, especially its upsampling component, plays a crucial role in enhancing segmentation outcomes. However, in 3D medical image segmentation, the commonly used transposed convolution can result in visual artifacts. This issue stems from the absence of direct relationship between adjacent pixels in the output feature map. Furthermore, plain encoder has already possessed sufficient feature extraction capability because downsampling operation leads to the gradual expansion of the receptive field, but the loss of information during downsampling process is unignorable. To address the gap in relevant research, we extend our focus beyond the encoder and introduce neU-Net (i.e., not complex encoder U-Net), which incorporates a novel Sub-pixel Convolution for upsampling to construct a powerful decoder. Additionally, we introduce multi-scale wavelet inputs module on the encoder side to provide additional information. Our model design achieves excellent results, surpassing other state-of-the-art methods on both the Synapse and ACDC datasets.
Generating Visual Scenes from Touch
Sep 26, 2023An emerging line of work has sought to generate plausible imagery from touch. Existing approaches, however, tackle only narrow aspects of the visuo-tactile synthesis problem, and lag significantly behind the quality of cross-modal synthesis methods in other domains. We draw on recent advances in latent diffusion to create a model for synthesizing images from tactile signals (and vice versa) and apply it to a number of visuo-tactile synthesis tasks. Using this model, we significantly outperform prior work on the tactile-driven stylization problem, i.e., manipulating an image to match a touch signal, and we are the first to successfully generate images from touch without additional sources of information about the scene. We also successfully use our model to address two novel synthesis problems: generating images that do not contain the touch sensor or the hand holding it, and estimating an image's shading from its reflectance and touch.
TF-ICON: Diffusion-Based Training-Free Cross-Domain Image Composition
Jul 25, 2023Text-driven diffusion models have exhibited impressive generative capabilities, enabling various image editing tasks. In this paper, we propose TF-ICON, a novel Training-Free Image COmpositioN framework that harnesses the power of text-driven diffusion models for cross-domain image-guided composition. This task aims to seamlessly integrate user-provided objects into a specific visual context. Current diffusion-based methods often involve costly instance-based optimization or finetuning of pretrained models on customized datasets, which can potentially undermine their rich prior. In contrast, TF-ICON can leverage off-the-shelf diffusion models to perform cross-domain image-guided composition without requiring additional training, finetuning, or optimization. Moreover, we introduce the exceptional prompt, which contains no information, to facilitate text-driven diffusion models in accurately inverting real images into latent representations, forming the basis for compositing. Our experiments show that equipping Stable Diffusion with the exceptional prompt outperforms state-of-the-art inversion methods on various datasets (CelebA-HQ, COCO, and ImageNet), and that TF-ICON surpasses prior baselines in versatile visual domains. Code is available at https://github.com/Shilin-LU/TF-ICON
AI4Food-NutritionFW: A Novel Framework for the Automatic Synthesis and Analysis of Eating Behaviours
Sep 12, 2023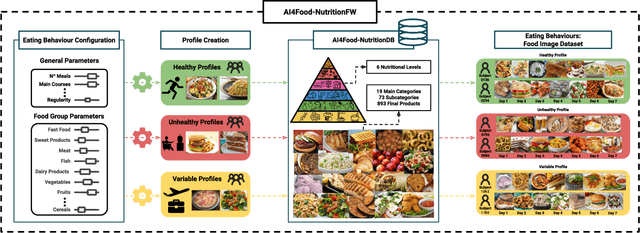
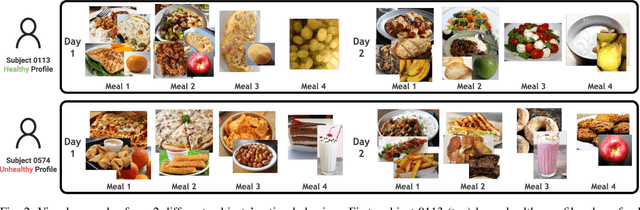
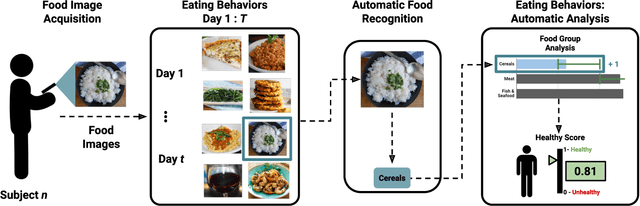
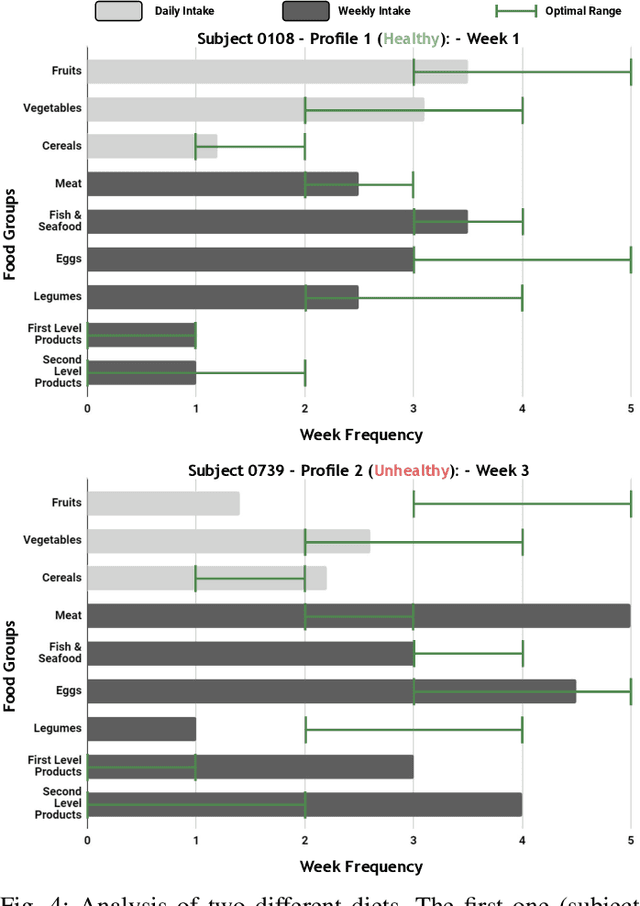
Nowadays millions of images are shared on social media and web platforms. In particular, many of them are food images taken from a smartphone over time, providing information related to the individual's diet. On the other hand, eating behaviours are directly related to some of the most prevalent diseases in the world. Exploiting recent advances in image processing and Artificial Intelligence (AI), this scenario represents an excellent opportunity to: i) create new methods that analyse the individuals' health from what they eat, and ii) develop personalised recommendations to improve nutrition and diet under specific circumstances (e.g., obesity or COVID). Having tunable tools for creating food image datasets that facilitate research in both lines is very much needed. This paper proposes AI4Food-NutritionFW, a framework for the creation of food image datasets according to configurable eating behaviours. AI4Food-NutritionFW simulates a user-friendly and widespread scenario where images are taken using a smartphone. In addition to the framework, we also provide and describe a unique food image dataset that includes 4,800 different weekly eating behaviours from 15 different profiles and 1,200 subjects. Specifically, we consider profiles that comply with actual lifestyles from healthy eating behaviours (according to established knowledge), variable profiles (e.g., eating out, holidays), to unhealthy ones (e.g., excess of fast food or sweets). Finally, we automatically evaluate a healthy index of the subject's eating behaviours using multidimensional metrics based on guidelines for healthy diets proposed by international organisations, achieving promising results (99.53% and 99.60% accuracy and sensitivity, respectively). We also release to the research community a software implementation of our proposed AI4Food-NutritionFW and the mentioned food image dataset created with it.
Physics-driven universal twin-image removal network for digital in-line holographic microscopy
Aug 08, 2023Digital in-line holographic microscopy (DIHM) enables efficient and cost-effective computational quantitative phase imaging with a large field of view, making it valuable for studying cell motility, migration, and bio-microfluidics. However, the quality of DIHM reconstructions is compromised by twin-image noise, posing a significant challenge. Conventional methods for mitigating this noise involve complex hardware setups or time-consuming algorithms with often limited effectiveness. In this work, we propose UTIRnet, a deep learning solution for fast, robust, and universally applicable twin-image suppression, trained exclusively on numerically generated datasets. The availability of open-source UTIRnet codes facilitates its implementation in various DIHM systems without the need for extensive experimental training data. Notably, our network ensures the consistency of reconstruction results with input holograms, imparting a physics-based foundation and enhancing reliability compared to conventional deep learning approaches. Experimental verification was conducted among others on live neural glial cell culture migration sensing, which is crucial for neurodegenerative disease research.
CNN-based automatic segmentation of Lumen & Media boundaries in IVUS images using closed polygonal chains
Sep 29, 2023We propose an automatic segmentation method for lumen and media with irregular contours in IntraVascular ultra-sound (IVUS) images. In contrast to most approaches that broadly label each pixel as either lumen, media, or background, we propose to approximate the lumen and media contours by closed polygonal chains. The chain vertices are placed at fixed angles obtained by dividing the entire 360\degree~angular space into equally spaced angles, and we predict their radius using an adaptive-subband-decomposition CNN. We consider two loss functions during training. The first is a novel loss function using the Jaccard Measure (JM) to quantify the similarities between the predicted lumen and media segments and the corresponding ground-truth image segments. The second loss function is the traditional Mean Squared Error. The proposed architecture significantly reduces computational costs by replacing the popular auto-encoder structure with a simple CNN as the encoder and the decoder is reduced to simply joining the consecutive predicted points. We evaluated our network on the publicly available IVUS-Challenge-2011 dataset using two performance metrics, namely JM and Hausdorff Distance (HD). The evaluation results show that our proposed network mostly outperforms the state-of-the-art lumen and media segmentation methods.