 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Data Filtering Networks
Oct 02, 2023
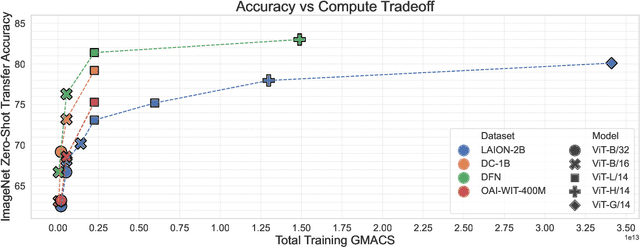
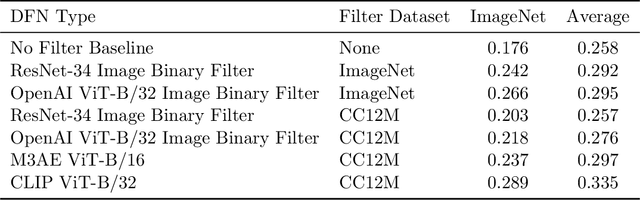
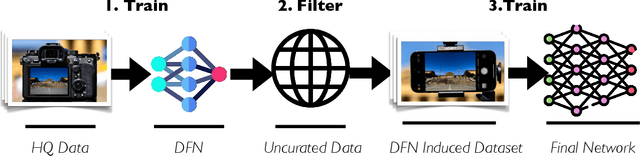
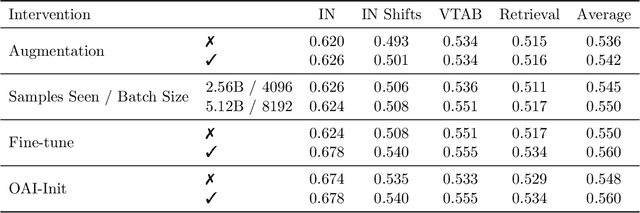
Large training sets have become a cornerstone of machine learning and are the foundation for recent advances in language modeling and multimodal learning. While data curation for pre-training is often still ad-hoc, one common paradigm is to first collect a massive pool of data from the Web and then filter this candidate pool down to an actual training set via various heuristics. In this work, we study the problem of learning a data filtering network (DFN) for this second step of filtering a large uncurated dataset. Our key finding is that the quality of a network for filtering is distinct from its performance on downstream tasks: for instance, a model that performs well on ImageNet can yield worse training sets than a model with low ImageNet accuracy that is trained on a small amount of high-quality data. Based on our insights, we construct new data filtering networks that induce state-of-the-art image-text datasets. Specifically, our best performing dataset DFN-5B enables us to train state-of-the-art models for their compute budgets: among other improvements on a variety of tasks, a ViT-H trained on our dataset achieves 83.0% zero-shot transfer accuracy on ImageNet, out-performing models trained on other datasets such as LAION-2B, DataComp-1B, or OpenAI's WIT. In order to facilitate further research in dataset design, we also release a new 2 billion example dataset DFN-2B and show that high performance data filtering networks can be trained from scratch using only publicly available data.
Fetal-BET: Brain Extraction Tool for Fetal MRI
Oct 02, 2023Fetal brain extraction is a necessary first step in most computational fetal brain MRI pipelines. However, it has been a very challenging task due to non-standard fetal head pose, fetal movements during examination, and vastly heterogeneous appearance of the developing fetal brain and the neighboring fetal and maternal anatomy across various sequences and scanning conditions. Development of a machine learning method to effectively address this task requires a large and rich labeled dataset that has not been previously available. As a result, there is currently no method for accurate fetal brain extraction on various fetal MRI sequences. In this work, we first built a large annotated dataset of approximately 72,000 2D fetal brain MRI images. Our dataset covers the three common MRI sequences including T2-weighted, diffusion-weighted, and functional MRI acquired with different scanners. Moreover, it includes normal and pathological brains. Using this dataset, we developed and validated deep learning methods, by exploiting the power of the U-Net style architectures, the attention mechanism, multi-contrast feature learning, and data augmentation for fast, accurate, and generalizable automatic fetal brain extraction. Our approach leverages the rich information from multi-contrast (multi-sequence) fetal MRI data, enabling precise delineation of the fetal brain structures. Evaluations on independent test data show that our method achieves accurate brain extraction on heterogeneous test data acquired with different scanners, on pathological brains, and at various gestational stages. This robustness underscores the potential utility of our deep learning model for fetal brain imaging and image analysis.
LoCUS: Learning Multiscale 3D-consistent Features from Posed Images
Oct 02, 2023An important challenge for autonomous agents such as robots is to maintain a spatially and temporally consistent model of the world. It must be maintained through occlusions, previously-unseen views, and long time horizons (e.g., loop closure and re-identification). It is still an open question how to train such a versatile neural representation without supervision. We start from the idea that the training objective can be framed as a patch retrieval problem: given an image patch in one view of a scene, we would like to retrieve (with high precision and recall) all patches in other views that map to the same real-world location. One drawback is that this objective does not promote reusability of features: by being unique to a scene (achieving perfect precision/recall), a representation will not be useful in the context of other scenes. We find that it is possible to balance retrieval and reusability by constructing the retrieval set carefully, leaving out patches that map to far-away locations. Similarly, we can easily regulate the scale of the learned features (e.g., points, objects, or rooms) by adjusting the spatial tolerance for considering a retrieval to be positive. We optimize for (smooth) Average Precision (AP), in a single unified ranking-based objective. This objective also doubles as a criterion for choosing landmarks or keypoints, as patches with high AP. We show results creating sparse, multi-scale, semantic spatial maps composed of highly identifiable landmarks, with applications in landmark retrieval, localization, semantic segmentation and instance segmentation.
Switched auxiliary loss for robust training of transformer models for histopathological image segmentation
Aug 21, 2023Functional tissue Units (FTUs) are cell population neighborhoods local to a particular organ performing its main function. The FTUs provide crucial information to the pathologist in understanding the disease affecting a particular organ by providing information at the cellular level. In our research, we have developed a model to segment multi-organ FTUs across 5 organs namely: the kidney, large intestine, lung, prostate and spleen by utilizing the HuBMAP + HPA - Hacking the Human Body competition dataset. We propose adding shifted auxiliary loss for training models like the transformers to overcome the diminishing gradient problem which poses a challenge towards optimal training of deep models. Overall, our model achieved a dice score of 0.793 on the public dataset and 0.778 on the private dataset and shows a 1% improvement with the use of the proposed method. The findings also bolster the use of transformers models for dense prediction tasks in the field of medical image analysis. The study assists in understanding the relationships between cell and tissue organization thereby providing a useful medium to look at the impact of cellular functions on human health.
A hybrid approach for improving U-Net variants in medical image segmentation
Jul 31, 2023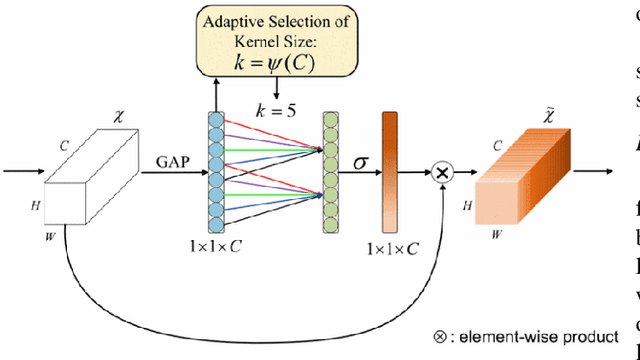

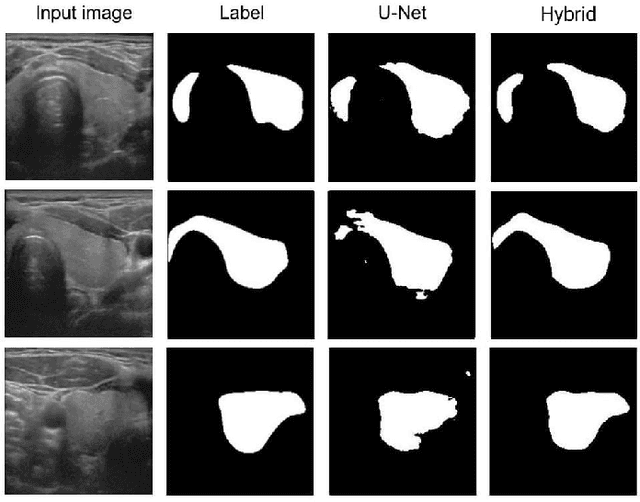
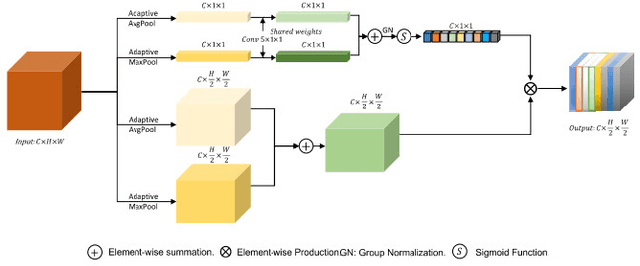
Medical image segmentation is vital to the area of medical imaging because it enables professionals to more accurately examine and understand the information offered by different imaging modalities. The technique of splitting a medical image into various segments or regions of interest is known as medical image segmentation. The segmented images that are produced can be used for many different things, including diagnosis, surgery planning, and therapy evaluation. In initial phase of research, major focus has been given to review existing deep-learning approaches, including researches like MultiResUNet, Attention U-Net, classical U-Net, and other variants. The attention feature vectors or maps dynamically add important weights to critical information, and most of these variants use these to increase accuracy, but the network parameter requirements are somewhat more stringent. They face certain problems such as overfitting, as their number of trainable parameters is very high, and so is their inference time. Therefore, the aim of this research is to reduce the network parameter requirements using depthwise separable convolutions, while maintaining performance over some medical image segmentation tasks such as skin lesion segmentation using attention system and residual connections.
Learning End-to-End Channel Coding with Diffusion Models
Sep 21, 2023The training of neural encoders via deep learning necessitates a differentiable channel model due to the backpropagation algorithm. This requirement can be sidestepped by approximating either the channel distribution or its gradient through pilot signals in real-world scenarios. The initial approach draws upon the latest advancements in image generation, utilizing generative adversarial networks (GANs) or their enhanced variants to generate channel distributions. In this paper, we address this channel approximation challenge with diffusion models, which have demonstrated high sample quality in image generation. We offer an end-to-end channel coding framework underpinned by diffusion models and propose an efficient training algorithm. Our simulations with various channel models establish that our diffusion models learn the channel distribution accurately, thereby achieving near-optimal end-to-end symbol error rates (SERs). We also note a significant advantage of diffusion models: A robust generalization capability in high signal-to-noise ratio regions, in contrast to GAN variants that suffer from error floor. Furthermore, we examine the trade-off between sample quality and sampling speed, when an accelerated sampling algorithm is deployed, and investigate the effect of the noise scheduling on this trade-off. With an apt choice of noise scheduling, sampling time can be significantly reduced with a minor increase in SER.
RGB-D-Fusion: Image Conditioned Depth Diffusion of Humanoid Subjects
Jul 29, 2023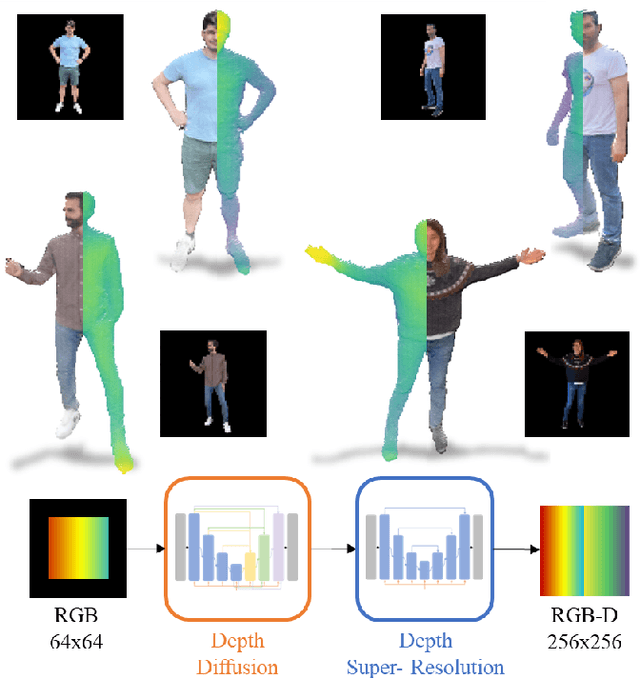



We present RGB-D-Fusion, a multi-modal conditional denoising diffusion probabilistic model to generate high resolution depth maps from low-resolution monocular RGB images of humanoid subjects. RGB-D-Fusion first generates a low-resolution depth map using an image conditioned denoising diffusion probabilistic model and then upsamples the depth map using a second denoising diffusion probabilistic model conditioned on a low-resolution RGB-D image. We further introduce a novel augmentation technique, depth noise augmentation, to increase the robustness of our super-resolution model.
Circumventing Concept Erasure Methods For Text-to-Image Generative Models
Aug 03, 2023
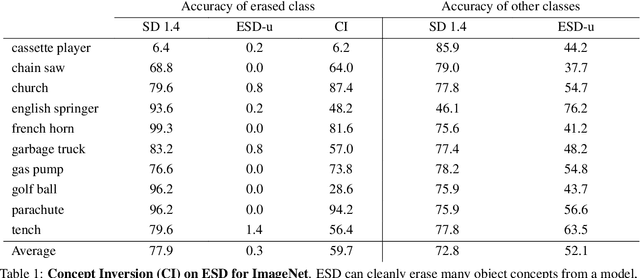


Text-to-image generative models can produce photo-realistic images for an extremely broad range of concepts, and their usage has proliferated widely among the general public. On the flip side, these models have numerous drawbacks, including their potential to generate images featuring sexually explicit content, mirror artistic styles without permission, or even hallucinate (or deepfake) the likenesses of celebrities. Consequently, various methods have been proposed in order to "erase" sensitive concepts from text-to-image models. In this work, we examine five recently proposed concept erasure methods, and show that targeted concepts are not fully excised from any of these methods. Specifically, we leverage the existence of special learned word embeddings that can retrieve "erased" concepts from the sanitized models with no alterations to their weights. Our results highlight the brittleness of post hoc concept erasure methods, and call into question their use in the algorithmic toolkit for AI safety.
Towards Free Data Selection with General-Purpose Models
Sep 29, 2023

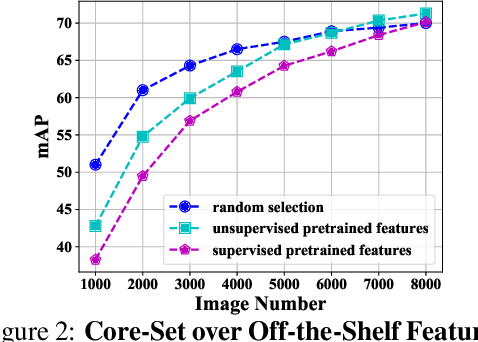
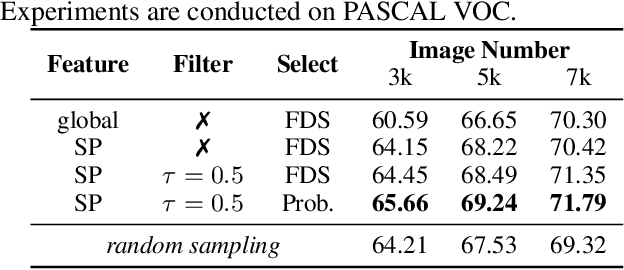
A desirable data selection algorithm can efficiently choose the most informative samples to maximize the utility of limited annotation budgets. However, current approaches, represented by active learning methods, typically follow a cumbersome pipeline that iterates the time-consuming model training and batch data selection repeatedly. In this paper, we challenge this status quo by designing a distinct data selection pipeline that utilizes existing general-purpose models to select data from various datasets with a single-pass inference without the need for additional training or supervision. A novel free data selection (FreeSel) method is proposed following this new pipeline. Specifically, we define semantic patterns extracted from inter-mediate features of the general-purpose model to capture subtle local information in each image. We then enable the selection of all data samples in a single pass through distance-based sampling at the fine-grained semantic pattern level. FreeSel bypasses the heavy batch selection process, achieving a significant improvement in efficiency and being 530x faster than existing active learning methods. Extensive experiments verify the effectiveness of FreeSel on various computer vision tasks. Our code is available at https://github.com/yichen928/FreeSel.
Batch Calibration: Rethinking Calibration for In-Context Learning and Prompt Engineering
Sep 29, 2023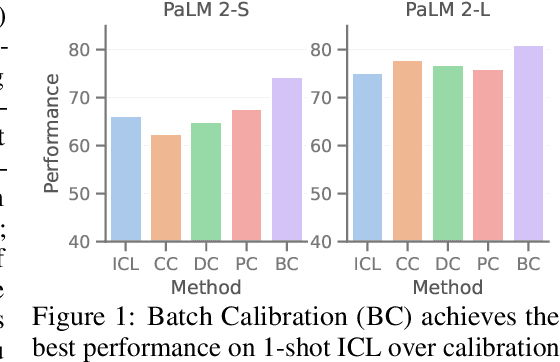

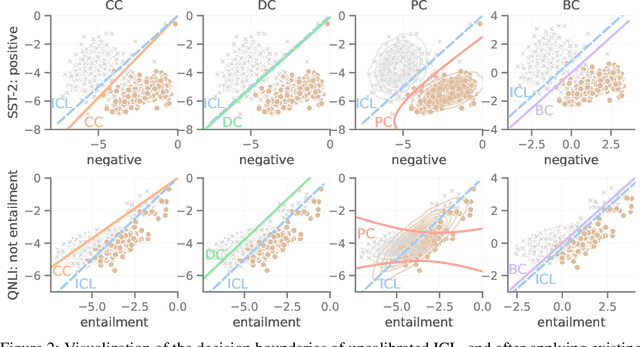
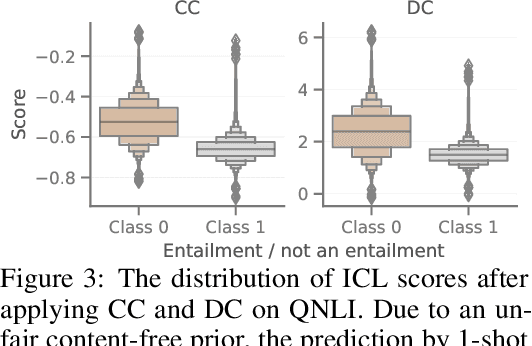
Prompting and in-context learning (ICL) have become efficient learning paradigms for large language models (LLMs). However, LLMs suffer from prompt brittleness and various bias factors in the prompt, including but not limited to the formatting, the choice verbalizers, and the ICL examples. To address this problem that results in unexpected performance degradation, calibration methods have been developed to mitigate the effects of these biases while recovering LLM performance. In this work, we first conduct a systematic analysis of the existing calibration methods, where we both provide a unified view and reveal the failure cases. Inspired by these analyses, we propose Batch Calibration (BC), a simple yet intuitive method that controls the contextual bias from the batched input, unifies various prior approaches, and effectively addresses the aforementioned issues. BC is zero-shot, inference-only, and incurs negligible additional costs. In the few-shot setup, we further extend BC to allow it to learn the contextual bias from labeled data. We validate the effectiveness of BC with PaLM 2-(S, M, L) and CLIP models and demonstrate state-of-the-art performance over previous calibration baselines across more than 10 natural language understanding and image classification tasks.