 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Swin-Tempo: Temporal-Aware Lung Nodule Detection in CT Scans as Video Sequences Using Swin Transformer-Enhanced UNet
Oct 05, 2023
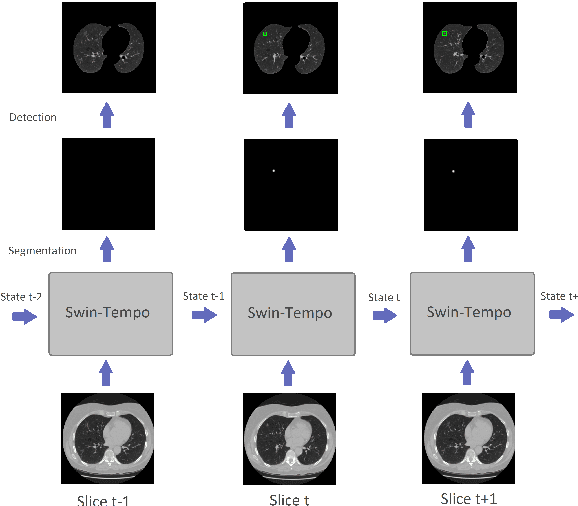

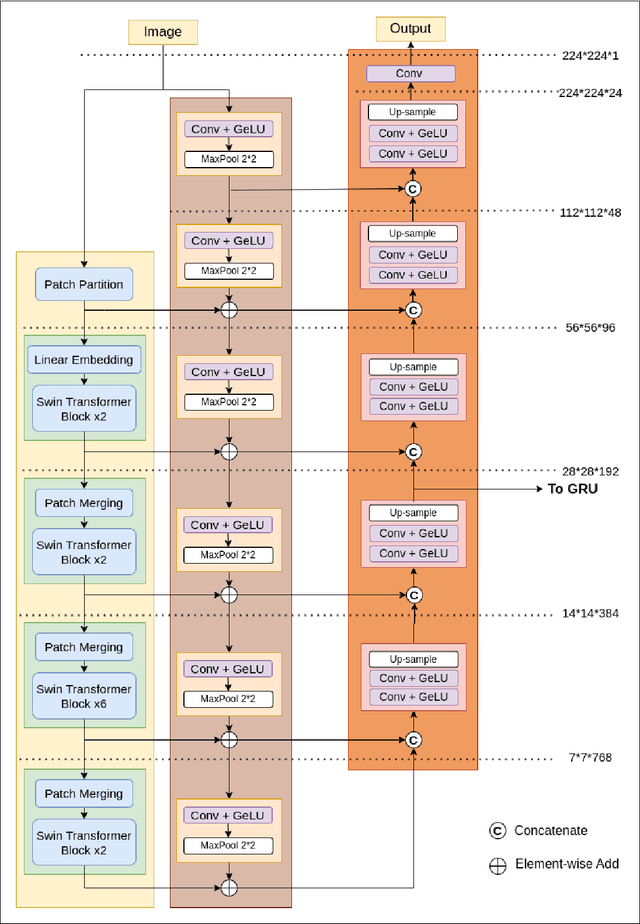
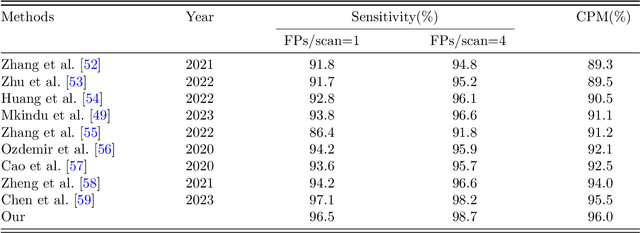
Lung cancer is highly lethal, emphasizing the critical need for early detection. However, identifying lung nodules poses significant challenges for radiologists, who rely heavily on their expertise and experience for accurate diagnosis. To address this issue, computer-aided diagnosis systems based on machine learning techniques have emerged to assist doctors in identifying lung nodules from computed tomography (CT) scans. Unfortunately, existing networks in this domain often suffer from computational complexity, leading to high rates of false negatives and false positives, limiting their effectiveness. To address these challenges, we present an innovative model that harnesses the strengths of both convolutional neural networks and vision transformers. Inspired by object detection in videos, we treat each 3D CT image as a video, individual slices as frames, and lung nodules as objects, enabling a time-series application. The primary objective of our work is to overcome hardware limitations during model training, allowing for efficient processing of 2D data while utilizing inter-slice information for accurate identification based on 3D image context. We validated the proposed network by applying a 10-fold cross-validation technique to the publicly available Lung Nodule Analysis 2016 dataset. Our proposed architecture achieves an average sensitivity criterion of 97.84% and a competition performance metrics (CPM) of 96.0% with few parameters. Comparative analysis with state-of-the-art advancements in lung nodule identification demonstrates the significant accuracy achieved by our proposed model.
Improving mitosis detection on histopathology images using large vision-language models
Oct 11, 2023In certain types of cancerous tissue, mitotic count has been shown to be associated with tumor proliferation, poor prognosis, and therapeutic resistance. Due to the high inter-rater variability of mitotic counting by pathologists, convolutional neural networks (CNNs) have been employed to reduce the subjectivity of mitosis detection in hematoxylin and eosin (H&E)-stained whole slide images. However, most existing models have performance that lags behind expert panel review and only incorporate visual information. In this work, we demonstrate that pre-trained large-scale vision-language models that leverage both visual features and natural language improve mitosis detection accuracy. We formulate the mitosis detection task as an image captioning task and a visual question answering (VQA) task by including metadata such as tumor and scanner types as context. The effectiveness of our pipeline is demonstrated via comparison with various baseline models using 9,501 mitotic figures and 11,051 hard negatives (non-mitotic figures that are difficult to characterize) from the publicly available Mitosis Domain Generalization Challenge (MIDOG22) dataset.
Don't Look into the Sun: Adversarial Solarization Attacks on Image Classifiers
Aug 24, 2023Assessing the robustness of deep neural networks against out-of-distribution inputs is crucial, especially in safety-critical domains like autonomous driving, but also in safety systems where malicious actors can digitally alter inputs to circumvent safety guards. However, designing effective out-of-distribution tests that encompass all possible scenarios while preserving accurate label information is a challenging task. Existing methodologies often entail a compromise between variety and constraint levels for attacks and sometimes even both. In a first step towards a more holistic robustness evaluation of image classification models, we introduce an attack method based on image solarization that is conceptually straightforward yet avoids jeopardizing the global structure of natural images independent of the intensity. Through comprehensive evaluations of multiple ImageNet models, we demonstrate the attack's capacity to degrade accuracy significantly, provided it is not integrated into the training augmentations. Interestingly, even then, no full immunity to accuracy deterioration is achieved. In other settings, the attack can often be simplified into a black-box attack with model-independent parameters. Defenses against other corruptions do not consistently extend to be effective against our specific attack. Project website: https://github.com/paulgavrikov/adversarial_solarization
AGG-Net: Attention Guided Gated-convolutional Network for Depth Image Completion
Sep 04, 2023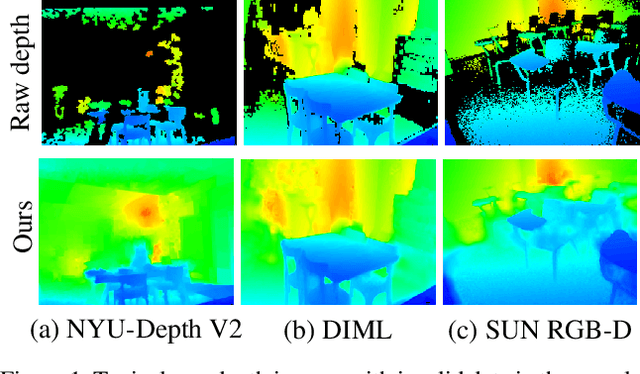

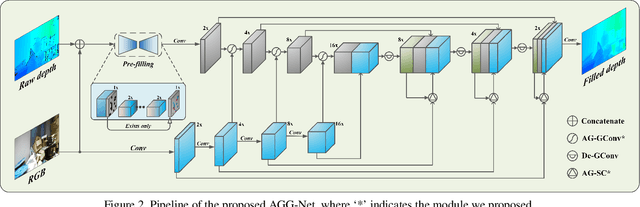
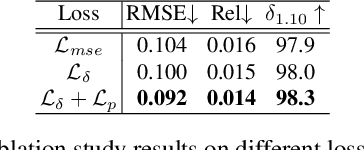
Recently, stereo vision based on lightweight RGBD cameras has been widely used in various fields. However, limited by the imaging principles, the commonly used RGB-D cameras based on TOF, structured light, or binocular vision acquire some invalid data inevitably, such as weak reflection, boundary shadows, and artifacts, which may bring adverse impacts to the follow-up work. In this paper, we propose a new model for depth image completion based on the Attention Guided Gated-convolutional Network (AGG-Net), through which more accurate and reliable depth images can be obtained from the raw depth maps and the corresponding RGB images. Our model employs a UNet-like architecture which consists of two parallel branches of depth and color features. In the encoding stage, an Attention Guided Gated-Convolution (AG-GConv) module is proposed to realize the fusion of depth and color features at different scales, which can effectively reduce the negative impacts of invalid depth data on the reconstruction. In the decoding stage, an Attention Guided Skip Connection (AG-SC) module is presented to avoid introducing too many depth-irrelevant features to the reconstruction. The experimental results demonstrate that our method outperforms the state-of-the-art methods on the popular benchmarks NYU-Depth V2, DIML, and SUN RGB-D.
Concept Bottleneck with Visual Concept Filtering for Explainable Medical Image Classification
Aug 23, 2023Interpretability is a crucial factor in building reliable models for various medical applications. Concept Bottleneck Models (CBMs) enable interpretable image classification by utilizing human-understandable concepts as intermediate targets. Unlike conventional methods that require extensive human labor to construct the concept set, recent works leveraging Large Language Models (LLMs) for generating concepts made automatic concept generation possible. However, those methods do not consider whether a concept is visually relevant or not, which is an important factor in computing meaningful concept scores. Therefore, we propose a visual activation score that measures whether the concept contains visual cues or not, which can be easily computed with unlabeled image data. Computed visual activation scores are then used to filter out the less visible concepts, thus resulting in a final concept set with visually meaningful concepts. Our experimental results show that adopting the proposed visual activation score for concept filtering consistently boosts performance compared to the baseline. Moreover, qualitative analyses also validate that visually relevant concepts are successfully selected with the visual activation score.
Learning Actions and Control of Focus of Attention with a Log-Polar-like Sensor
Sep 22, 2023

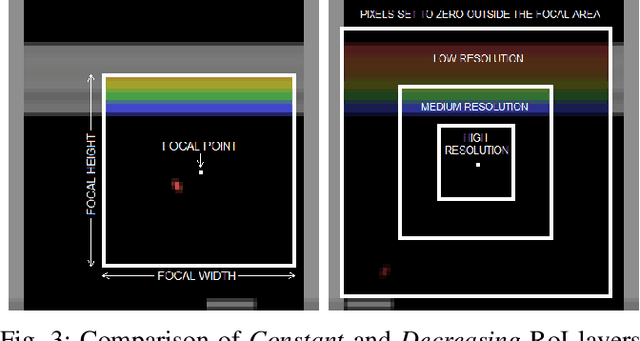

With the long-term goal of reducing the image processing time on an autonomous mobile robot in mind we explore in this paper the use of log-polar like image data with gaze control. The gaze control is not done on the Cartesian image but on the log-polar like image data. For this we start out from the classic deep reinforcement learning approach for Atari games. We extend an A3C deep RL approach with an LSTM network, and we learn the policy for playing three Atari games and a policy for gaze control. While the Atari games already use low-resolution images of 80 by 80 pixels, we are able to further reduce the amount of image pixels by a factor of 5 without losing any gaming performance.
Tackling VQA with Pretrained Foundation Models without Further Training
Sep 27, 2023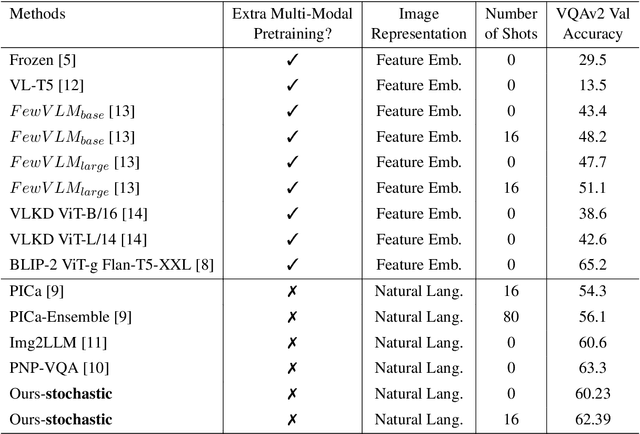
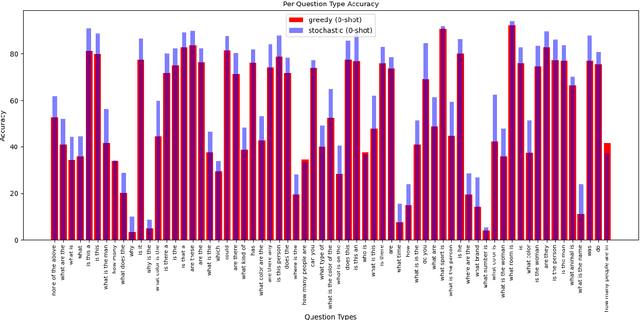
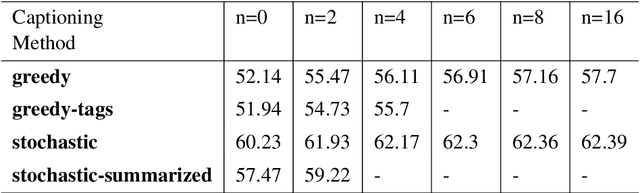
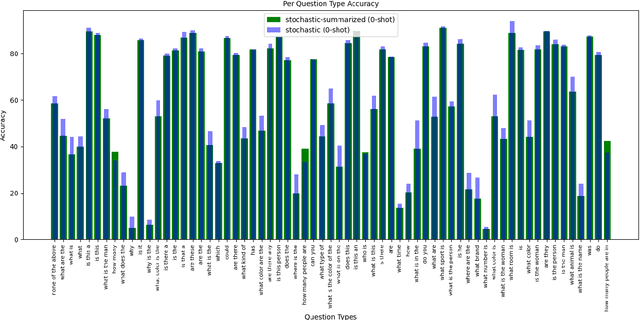
Large language models (LLMs) have achieved state-of-the-art results in many natural language processing tasks. They have also demonstrated ability to adapt well to different tasks through zero-shot or few-shot settings. With the capability of these LLMs, researchers have looked into how to adopt them for use with Visual Question Answering (VQA). Many methods require further training to align the image and text embeddings. However, these methods are computationally expensive and requires large scale image-text dataset for training. In this paper, we explore a method of combining pretrained LLMs and other foundation models without further training to solve the VQA problem. The general idea is to use natural language to represent the images such that the LLM can understand the images. We explore different decoding strategies for generating textual representation of the image and evaluate their performance on the VQAv2 dataset.
Making LLaMA SEE and Draw with SEED Tokenizer
Oct 02, 2023The great success of Large Language Models (LLMs) has expanded the potential of multimodality, contributing to the gradual evolution of General Artificial Intelligence (AGI). A true AGI agent should not only possess the capability to perform predefined multi-tasks but also exhibit emergent abilities in an open-world context. However, despite the considerable advancements made by recent multimodal LLMs, they still fall short in effectively unifying comprehension and generation tasks, let alone open-world emergent abilities. We contend that the key to overcoming the present impasse lies in enabling text and images to be represented and processed interchangeably within a unified autoregressive Transformer. To this end, we introduce SEED, an elaborate image tokenizer that empowers LLMs with the ability to SEE and Draw at the same time. We identify two crucial design principles: (1) Image tokens should be independent of 2D physical patch positions and instead be produced with a 1D causal dependency, exhibiting intrinsic interdependence that aligns with the left-to-right autoregressive prediction mechanism in LLMs. (2) Image tokens should capture high-level semantics consistent with the degree of semantic abstraction in words, and be optimized for both discriminativeness and reconstruction during the tokenizer training phase. With SEED tokens, LLM is able to perform scalable multimodal autoregression under its original training recipe, i.e., next-word prediction. SEED-LLaMA is therefore produced by large-scale pretraining and instruction tuning on the interleaved textual and visual data, demonstrating impressive performance on a broad range of multimodal comprehension and generation tasks. More importantly, SEED-LLaMA has exhibited compositional emergent abilities such as multi-turn in-context multimodal generation, acting like your AI assistant.
I2SRM: Intra- and Inter-Sample Relationship Modeling for Multimodal Information Extraction
Oct 10, 2023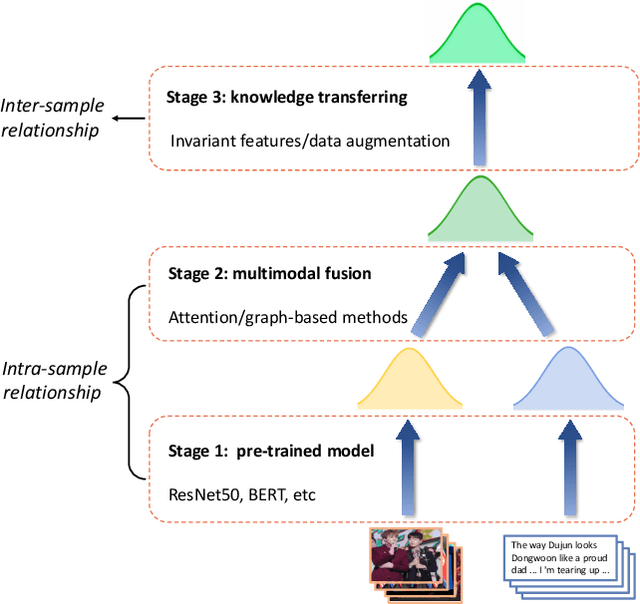
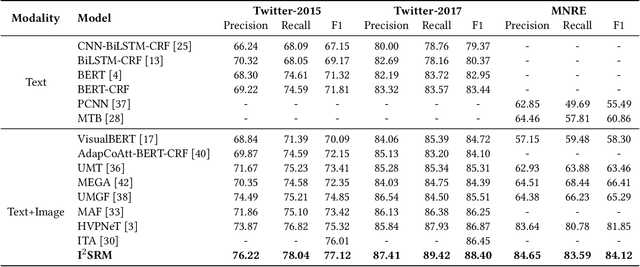
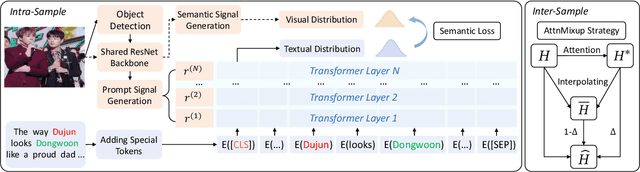
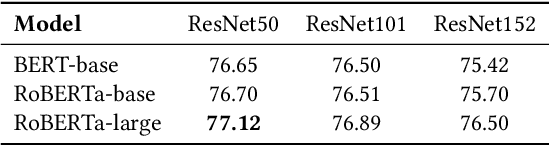
Multimodal information extraction is attracting research attention nowadays, which requires aggregating representations from different modalities. In this paper, we present the Intra- and Inter-Sample Relationship Modeling (I2SRM) method for this task, which contains two modules. Firstly, the intra-sample relationship modeling module operates on a single sample and aims to learn effective representations. Embeddings from textual and visual modalities are shifted to bridge the modality gap caused by distinct pre-trained language and image models. Secondly, the inter-sample relationship modeling module considers relationships among multiple samples and focuses on capturing the interactions. An AttnMixup strategy is proposed, which not only enables collaboration among samples but also augments data to improve generalization. We conduct extensive experiments on the multimodal named entity recognition datasets Twitter-2015 and Twitter-2017, and the multimodal relation extraction dataset MNRE. Our proposed method I2SRM achieves competitive results, 77.12% F1-score on Twitter-2015, 88.40% F1-score on Twitter-2017, and 84.12% F1-score on MNRE.
Topological RANSAC for instance verification and retrieval without fine-tuning
Oct 10, 2023This paper presents an innovative approach to enhancing explainable image retrieval, particularly in situations where a fine-tuning set is unavailable. The widely-used SPatial verification (SP) method, despite its efficacy, relies on a spatial model and the hypothesis-testing strategy for instance recognition, leading to inherent limitations, including the assumption of planar structures and neglect of topological relations among features. To address these shortcomings, we introduce a pioneering technique that replaces the spatial model with a topological one within the RANSAC process. We propose bio-inspired saccade and fovea functions to verify the topological consistency among features, effectively circumventing the issues associated with SP's spatial model. Our experimental results demonstrate that our method significantly outperforms SP, achieving state-of-the-art performance in non-fine-tuning retrieval. Furthermore, our approach can enhance performance when used in conjunction with fine-tuned features. Importantly, our method retains high explainability and is lightweight, offering a practical and adaptable solution for a variety of real-world applications.