 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocPrune:Efficient Document Question Answering via Background, Question, and Comprehension-aware Token Pruning
Apr 24, 2026Recent advances in vision-language models have demonstrated remarkable performance across diverse multi-modal tasks, including document question answering that leverages structured visual cues from text, tables, and figures. However, unlike natural images, document images contain large backgrounds and only sparse supporting evidence, leading to the inefficient consumption of substantial computational resources, especially for long documents. We observe that existing token-reduction methods for natural images and videos fall short in utilizing the structural sparsity unique to documents. To address this, we propose DocPrune, a training-free and progressive document token pruning framework designed for efficient long-document understanding. The proposed method preserves only the essential tokens for the task while removing unnecessary ones, such as background or question-irrelevant tokens. Moreover, it automatically selects the appropriate layers to initiate token pruning based on the model's level of comprehension. Our experiments on the M3DocRAG show that DocPrune improves throughput by 3.0x and 3.3x in the encoder and decoder, respectively, while boosting the F1 score by +1.0, achieving both higher accuracy and efficiency without any additional training.
TabFlash: Efficient Table Understanding with Progressive Question Conditioning and Token Focusing
Nov 17, 2025Table images present unique challenges for effective and efficient understanding due to the need for question-specific focus and the presence of redundant background regions. Existing Multimodal Large Language Model (MLLM) approaches often overlook these characteristics, resulting in uninformative and redundant visual representations. To address these issues, we aim to generate visual features that are both informative and compact to improve table understanding. We first propose progressive question conditioning, which injects the question into Vision Transformer layers with gradually increasing frequency, considering each layer's capacity to handle additional information, to generate question-aware visual features. To reduce redundancy, we introduce a pruning strategy that discards background tokens, thereby improving efficiency. To mitigate information loss from pruning, we further propose token focusing, a training strategy that encourages the model to concentrate essential information in the retained tokens. By combining these approaches, we present TabFlash, an efficient and effective MLLM for table understanding. TabFlash achieves state-of-the-art performance, outperforming both open-source and proprietary MLLMs, while requiring 27% less FLOPs and 30% less memory usage compared to the second-best MLLM.
VidChain: Chain-of-Tasks with Metric-based Direct Preference Optimization for Dense Video Captioning
Jan 12, 2025



Despite the advancements of Video Large Language Models (VideoLLMs) in various tasks, they struggle with fine-grained temporal understanding, such as Dense Video Captioning (DVC). DVC is a complicated task of describing all events within a video while also temporally localizing them, which integrates multiple fine-grained tasks, including video segmentation, video captioning, and temporal video grounding. Previous VideoLLMs attempt to solve DVC in a single step, failing to utilize their reasoning capability. Moreover, previous training objectives for VideoLLMs do not fully reflect the evaluation metrics, therefore not providing supervision directly aligned to target tasks. To address such a problem, we propose a novel framework named VidChain comprised of Chain-of-Tasks (CoTasks) and Metric-based Direct Preference Optimization (M-DPO). CoTasks decompose a complex task into a sequence of sub-tasks, allowing VideoLLMs to leverage their reasoning capabilities more effectively. M-DPO aligns a VideoLLM with evaluation metrics, providing fine-grained supervision to each task that is well-aligned with metrics. Applied to two different VideoLLMs, VidChain consistently improves their fine-grained video understanding, thereby outperforming previous VideoLLMs on two different DVC benchmarks and also on the temporal video grounding task. Code is available at \url{https://github.com/mlvlab/VidChain}.
Groupwise Query Specialization and Quality-Aware Multi-Assignment for Transformer-based Visual Relationship Detection
Mar 26, 2024Visual Relationship Detection (VRD) has seen significant advancements with Transformer-based architectures recently. However, we identify two key limitations in a conventional label assignment for training Transformer-based VRD models, which is a process of mapping a ground-truth (GT) to a prediction. Under the conventional assignment, an unspecialized query is trained since a query is expected to detect every relation, which makes it difficult for a query to specialize in specific relations. Furthermore, a query is also insufficiently trained since a GT is assigned only to a single prediction, therefore near-correct or even correct predictions are suppressed by being assigned no relation as a GT. To address these issues, we propose Groupwise Query Specialization and Quality-Aware Multi-Assignment (SpeaQ). Groupwise Query Specialization trains a specialized query by dividing queries and relations into disjoint groups and directing a query in a specific query group solely toward relations in the corresponding relation group. Quality-Aware Multi-Assignment further facilitates the training by assigning a GT to multiple predictions that are significantly close to a GT in terms of a subject, an object, and the relation in between. Experimental results and analyses show that SpeaQ effectively trains specialized queries, which better utilize the capacity of a model, resulting in consistent performance gains with zero additional inference cost across multiple VRD models and benchmarks. Code is available at https://github.com/mlvlab/SpeaQ.
Concept Bottleneck with Visual Concept Filtering for Explainable Medical Image Classification
Aug 23, 2023



Interpretability is a crucial factor in building reliable models for various medical applications. Concept Bottleneck Models (CBMs) enable interpretable image classification by utilizing human-understandable concepts as intermediate targets. Unlike conventional methods that require extensive human labor to construct the concept set, recent works leveraging Large Language Models (LLMs) for generating concepts made automatic concept generation possible. However, those methods do not consider whether a concept is visually relevant or not, which is an important factor in computing meaningful concept scores. Therefore, we propose a visual activation score that measures whether the concept contains visual cues or not, which can be easily computed with unlabeled image data. Computed visual activation scores are then used to filter out the less visible concepts, thus resulting in a final concept set with visually meaningful concepts. Our experimental results show that adopting the proposed visual activation score for concept filtering consistently boosts performance compared to the baseline. Moreover, qualitative analyses also validate that visually relevant concepts are successfully selected with the visual activation score.
Object Detection in Aerial Images with Uncertainty-Aware Graph Network
Aug 24, 2022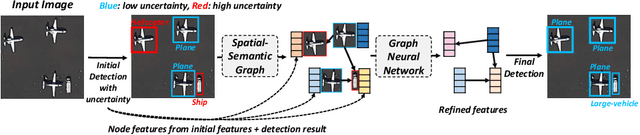
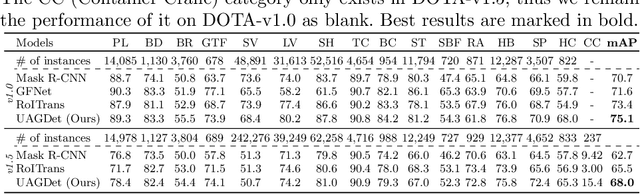


In this work, we propose a novel uncertainty-aware object detection framework with a structured-graph, where nodes and edges are denoted by objects and their spatial-semantic similarities, respectively. Specifically, we aim to consider relationships among objects for effectively contextualizing them. To achieve this, we first detect objects and then measure their semantic and spatial distances to construct an object graph, which is then represented by a graph neural network (GNN) for refining visual CNN features for objects. However, refining CNN features and detection results of every object are inefficient and may not be necessary, as that include correct predictions with low uncertainties. Therefore, we propose to handle uncertain objects by not only transferring the representation from certain objects (sources) to uncertain objects (targets) over the directed graph, but also improving CNN features only on objects regarded as uncertain with their representational outputs from the GNN. Furthermore, we calculate a training loss by giving larger weights on uncertain objects, to concentrate on improving uncertain object predictions while maintaining high performances on certain objects. We refer to our model as Uncertainty-Aware Graph network for object DETection (UAGDet). We then experimentally validate ours on the challenging large-scale aerial image dataset, namely DOTA, that consists of lots of objects with small to large sizes in an image, on which ours improves the performance of the existing object detection network.