 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Merlin: Enabling Machine Learning-Ready HPC Ensembles
Dec 05, 2019
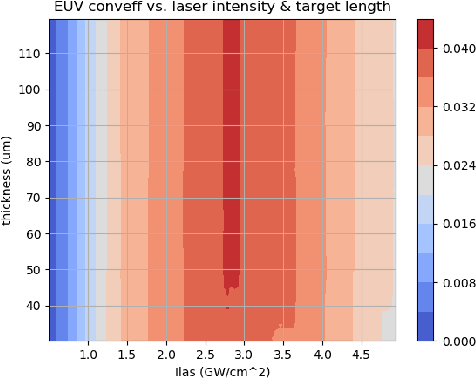
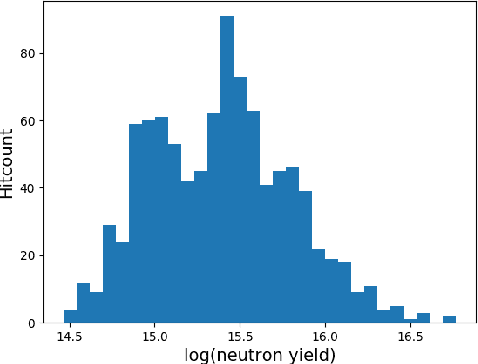
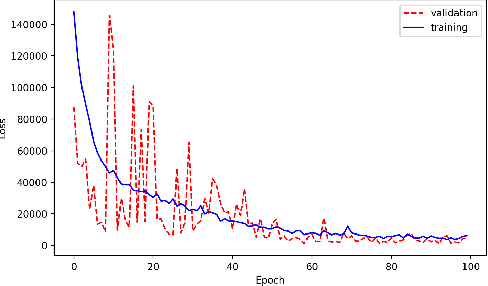
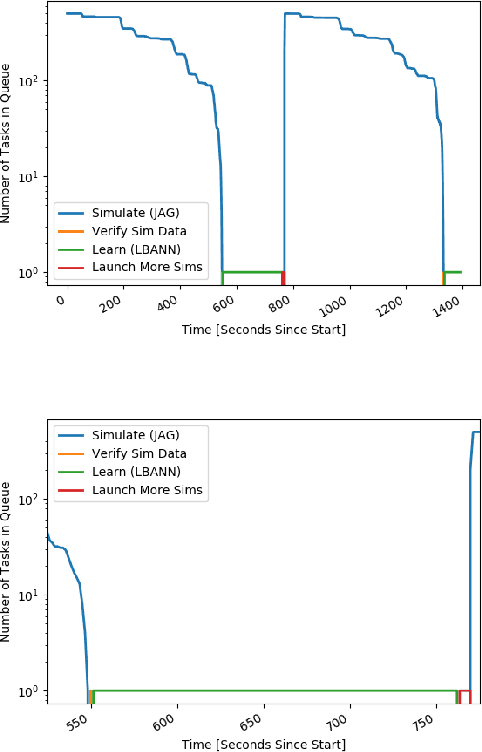
With the growing complexity of computational and experimental facilities, many scientific researchers are turning to machine learning (ML) techniques to analyze large scale ensemble data. With complexities such as multi-component workflows, heterogeneous machine architectures, parallel file systems, and batch scheduling, care must be taken to facilitate this analysis in a high performance computing (HPC) environment. In this paper, we present Merlin, a workflow framework to enable large ML-friendly ensembles of scientific HPC simulations. By augmenting traditional HPC with distributed compute technologies, Merlin aims to lower the barrier for scientific subject matter experts to incorporate ML into their analysis. In addition to its design and some examples, we describe how Merlin was deployed on the Sierra Supercomputer at Lawrence Livermore National Laboratory to create an unprecedented benchmark inertial confinement fusion dataset of approximately 100 million individual simulations and over 24 terabytes of multi-modal physics-based scalar, vector and hyperspectral image data.
BreakingNews: Article Annotation by Image and Text Processing
Mar 23, 2016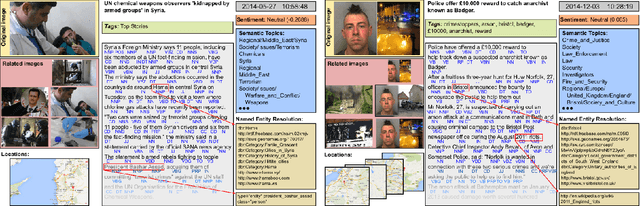
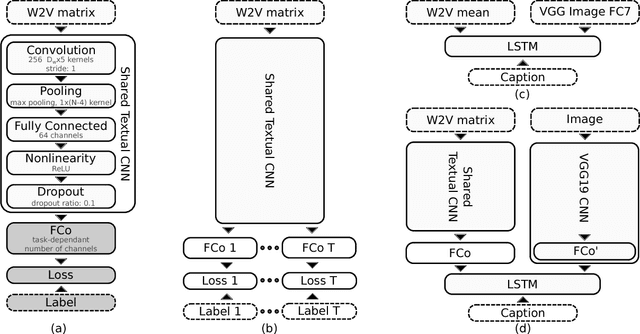
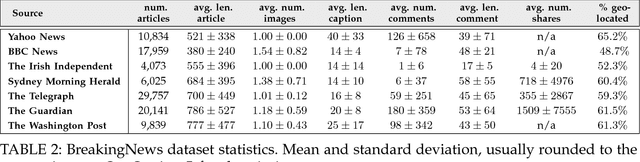
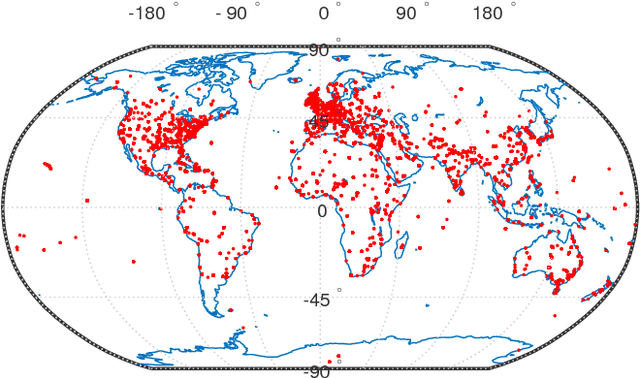
Building upon recent Deep Neural Network architectures, current approaches lying in the intersection of computer vision and natural language processing have achieved unprecedented breakthroughs in tasks like automatic captioning or image retrieval. Most of these learning methods, though, rely on large training sets of images associated with human annotations that specifically describe the visual content. In this paper we propose to go a step further and explore the more complex cases where textual descriptions are loosely related to the images. We focus on the particular domain of News articles in which the textual content often expresses connotative and ambiguous relations that are only suggested but not directly inferred from images. We introduce new deep learning methods that address source detection, popularity prediction, article illustration and geolocation of articles. An adaptive CNN architecture is proposed, that shares most of the structure for all the tasks, and is suitable for multitask and transfer learning. Deep Canonical Correlation Analysis is deployed for article illustration, and a new loss function based on Great Circle Distance is proposed for geolocation. Furthermore, we present BreakingNews, a novel dataset with approximately 100K news articles including images, text and captions, and enriched with heterogeneous meta-data (such as GPS coordinates and popularity metrics). We show this dataset to be appropriate to explore all aforementioned problems, for which we provide a baseline performance using various Deep Learning architectures, and different representations of the textual and visual features. We report very promising results and bring to light several limitations of current state-of-the-art in this kind of domain, which we hope will help spur progress in the field.
Show, Control and Tell: A Framework for Generating Controllable and Grounded Captions
Nov 26, 2018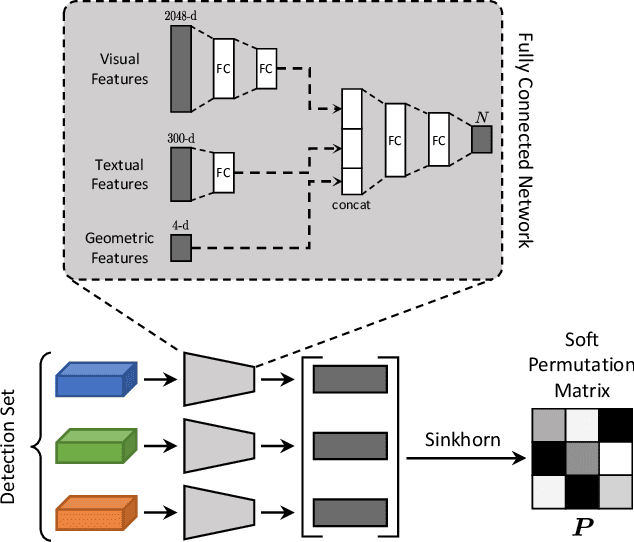
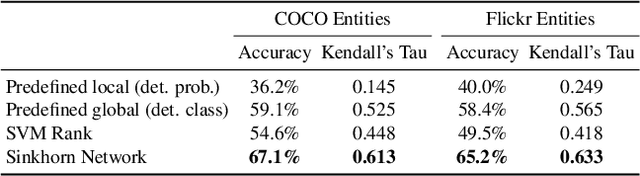
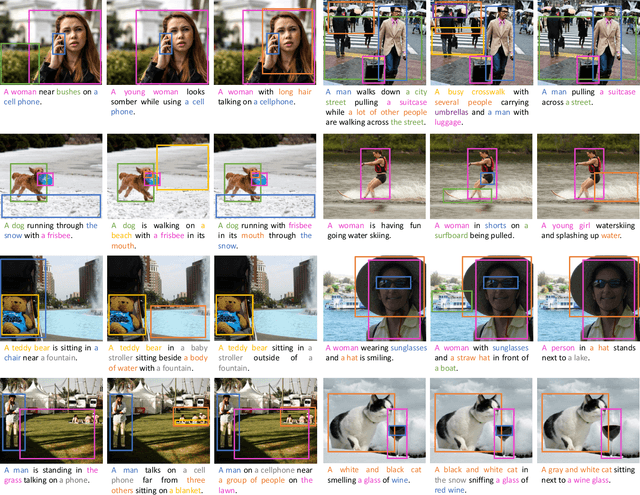
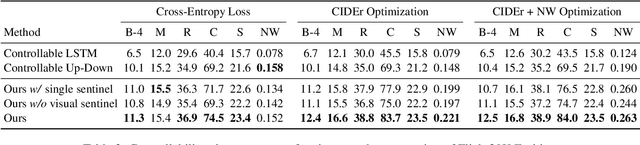
Current captioning approaches can describe images using black-box architectures whose behavior is hardly controllable and explainable from the exterior. As an image can be described in infinite ways depending on the goal and the context at hand, a higher degree of controllability is needed to apply captioning algorithms in complex scenarios. In this paper, we introduce a novel framework for image captioning which can generate diverse descriptions by allowing both grounding and controllability. Given a control signal in the form of a sequence or set of image regions, we generate the corresponding caption through a recurrent architecture which predicts textual chunks explicitly grounded on regions, following the constraints of the given control. Experiments are conducted on Flickr30k Entities and on COCO Entities, an extended version of COCO in which we add grounding annotations collected in a semi-automatic manner. Results demonstrate that our method achieves state of the art performances on controllable image captioning, in terms of caption quality and diversity. Code will be made publicly available.
Style Transfer by Relaxed Optimal Transport and Self-Similarity
Apr 29, 2019
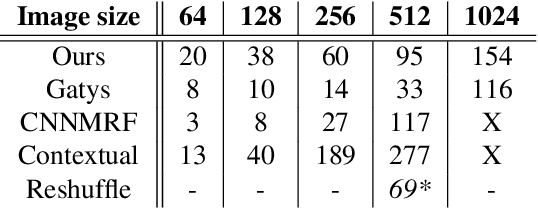


Style transfer algorithms strive to render the content of one image using the style of another. We propose Style Transfer by Relaxed Optimal Transport and Self-Similarity (STROTSS), a new optimization-based style transfer algorithm. We extend our method to allow user-specified point-to-point or region-to-region control over visual similarity between the style image and the output. Such guidance can be used to either achieve a particular visual effect or correct errors made by unconstrained style transfer. In order to quantitatively compare our method to prior work, we conduct a large-scale user study designed to assess the style-content tradeoff across settings in style transfer algorithms. Our results indicate that for any desired level of content preservation, our method provides higher quality stylization than prior work. Code is available at https://github.com/nkolkin13/STROTSS
Understanding Graph Isomorphism Network for Brain MR Functional Connectivity Analysis
Jan 10, 2020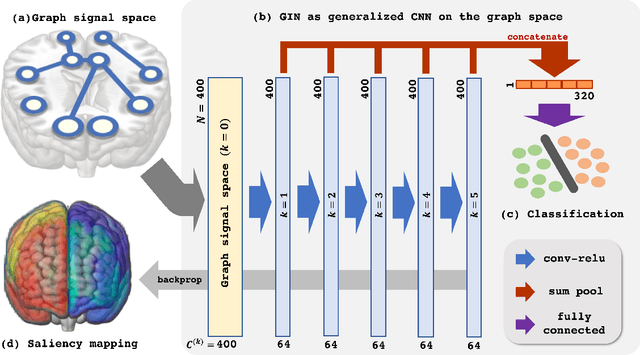
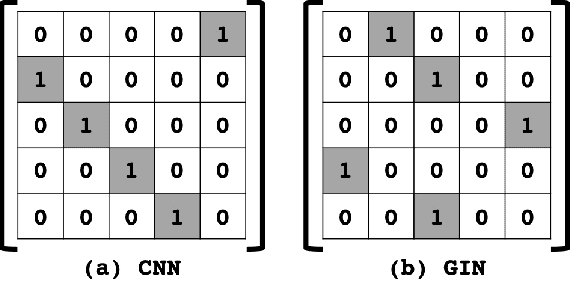

Graph neural networks (GNN) rely on graph operations that include neural network training for various graph related tasks. Recently, several attempts have been made to apply the GNNs to functional magnetic resonance image (fMRI) data. Despite the recent progress, a common limitation is its difficulty to explain the classification results in a neuroscientifically explainable way. Here, we develop a framework for analyzing the fMRI data using the Graph Isomorphism Network (GIN), which was recently proposed as a state-of-the-art GNN for graph classification. One important observation in this paper is that the GIN is a realization of convolutional neural network (CNN) with two-tab filters in the graph space where the shift operation is realized using the adjacent matrix. Based on this observation, we visualize the important regions of the brain by a saliency mapping method of the trained GIN. We validate our proposed framework using large-scale resting-state fMRI data for classifying the sex of the subject based on the graph structure of the brain. The experiment was consistent with our expectation such that the obtained saliency map show high correspondence with previous neuroimaging evidences related to sex differences.
Adversarial Defense Through Network Profiling Based Path Extraction
Apr 17, 2019



Recently, researchers have started decomposing deep neural network models according to their semantics or functions. Recent work has shown the effectiveness of decomposed functional blocks for defending adversarial attacks, which add small input perturbation to the input image to fool the DNN models. This work proposes a profiling-based method to decompose the DNN models to different functional blocks, which lead to the effective path as a new approach to exploring DNNs' internal organization. Specifically, the per-image effective path can be aggregated to the class-level effective path, through which we observe that adversarial images activate effective path different from normal images. We propose an effective path similarity-based method to detect adversarial images with an interpretable model, which achieve better accuracy and broader applicability than the state-of-the-art technique.
The Elephant in the Room
Aug 09, 2018


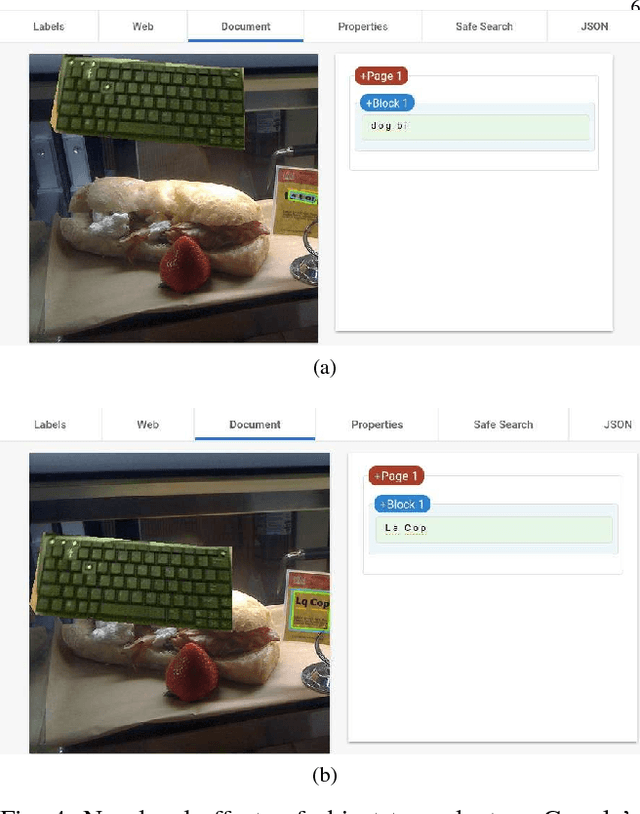
We showcase a family of common failures of state-of-the art object detectors. These are obtained by replacing image sub-regions by another sub-image that contains a trained object. We call this "object transplanting". Modifying an image in this manner is shown to have a non-local impact on object detection. Slight changes in object position can affect its identity according to an object detector as well as that of other objects in the image. We provide some analysis and suggest possible reasons for the reported phenomena.
Stopping Rules for Bag-of-Words Image Search and Its Application in Appearance-Based Localization
Dec 28, 2013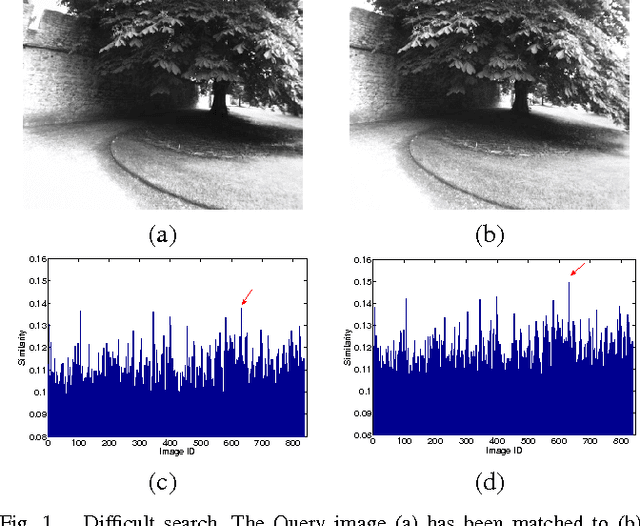
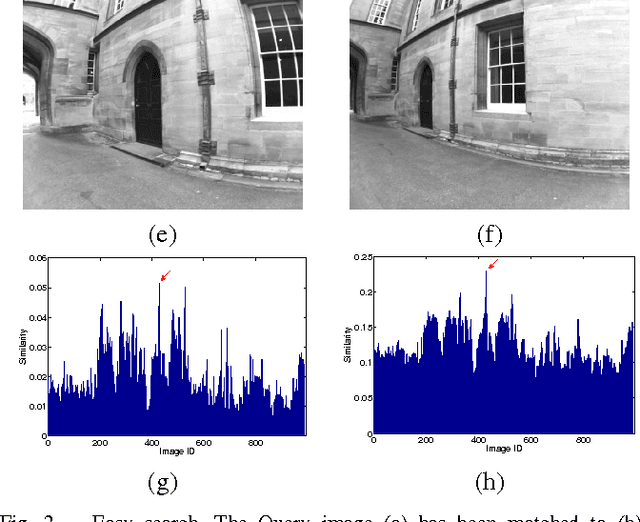

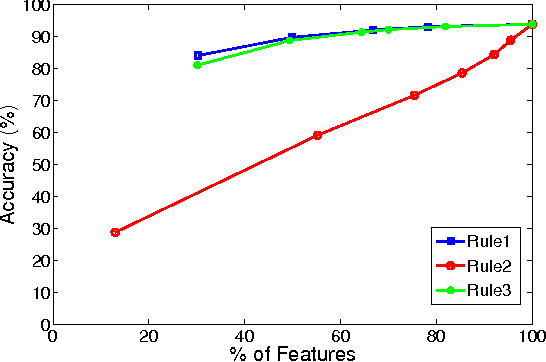
We propose a technique to improve the search efficiency of the bag-of-words (BoW) method for image retrieval. We introduce a notion of difficulty for the image matching problems and propose methods that reduce the amount of computations required for the feature vector-quantization task in BoW by exploiting the fact that easier queries need less computational resources. Measuring the difficulty of a query and stopping the search accordingly is formulated as a stopping problem. We introduce stopping rules that terminate the image search depending on the difficulty of each query, thereby significantly reducing the computational cost. Our experimental results show the effectiveness of our approach when it is applied to appearance-based localization problem.
Deep Zero-Shot Learning for Scene Sketch
May 11, 2019

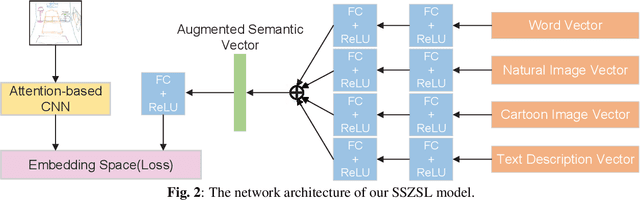
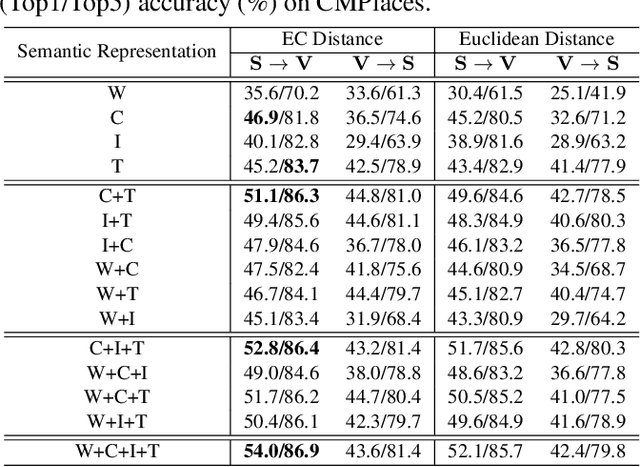
We introduce a novel problem of scene sketch zero-shot learning (SSZSL), which is a challenging task, since (i) different from photo, the gap between common semantic domain (e.g., word vector) and sketch is too huge to exploit common semantic knowledge as the bridge for knowledge transfer, and (ii) compared with single-object sketch, more expressive feature representation for scene sketch is required to accommodate its high-level of abstraction and complexity. To overcome these challenges, we propose a deep embedding model for scene sketch zero-shot learning. In particular, we propose the augmented semantic vector to conduct domain alignment by fusing multi-modal semantic knowledge (e.g., cartoon image, natural image, text description), and adopt attention-based network for scene sketch feature learning. Moreover, we propose a novel distance metric to improve the similarity measure during testing. Extensive experiments and ablation studies demonstrate the benefit of our sketch-specific design.
2D Attentional Irregular Scene Text Recognizer
Jun 13, 2019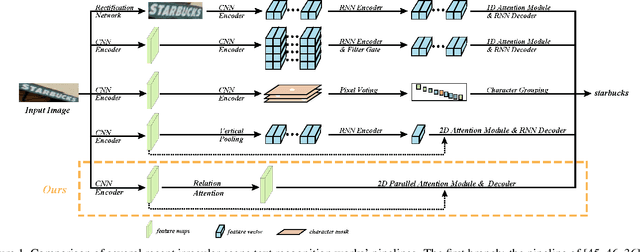
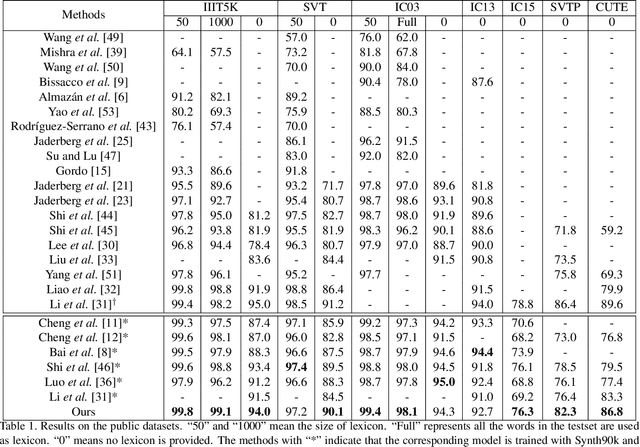
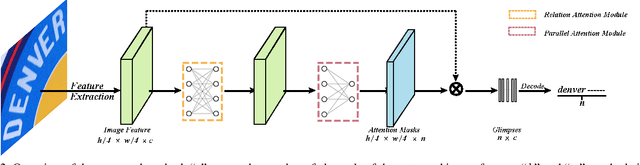
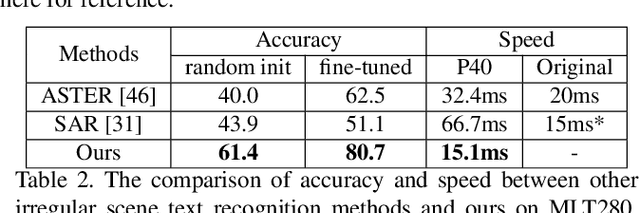
Irregular scene text, which has complex layout in 2D space, is challenging to most previous scene text recognizers. Recently, some irregular scene text recognizers either rectify the irregular text to regular text image with approximate 1D layout or transform the 2D image feature map to 1D feature sequence. Though these methods have achieved good performance, the robustness and accuracy are still limited due to the loss of spatial information in the process of 2D to 1D transformation. Different from all of previous, we in this paper propose a framework which transforms the irregular text with 2D layout to character sequence directly via 2D attentional scheme. We utilize a relation attention module to capture the dependencies of feature maps and a parallel attention module to decode all characters in parallel, which make our method more effective and efficient. Extensive experiments on several public benchmarks as well as our collected multi-line text dataset show that our approach is effective to recognize regular and irregular scene text and outperforms previous methods both in accuracy and speed.