 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diversity-Sensitive Conditional Generative Adversarial Networks
Jan 25, 2019
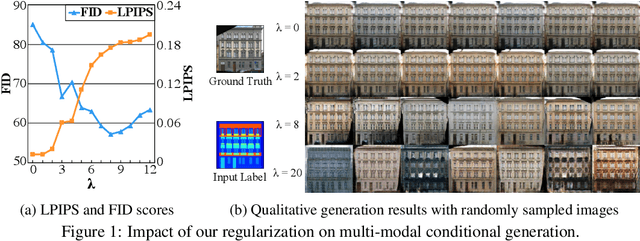
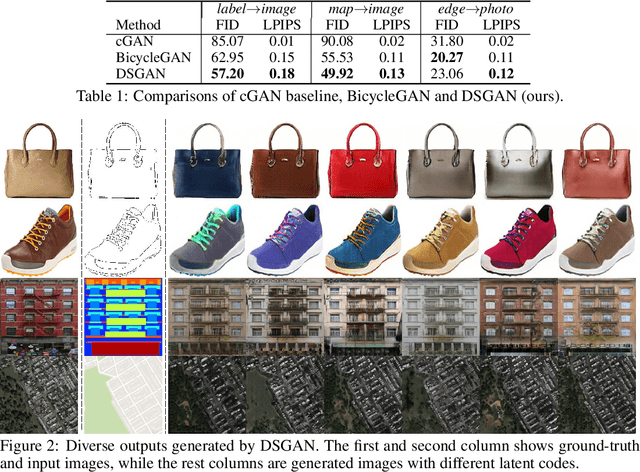
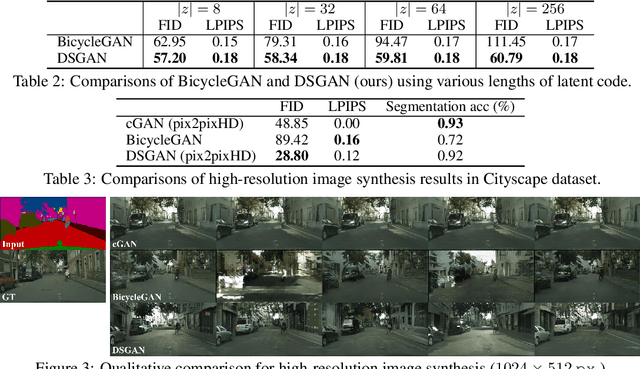

We propose a simple yet highly effective method that addresses the mode-collapse problem in the Conditional Generative Adversarial Network (cGAN). Although conditional distributions are multi-modal (i.e., having many modes) in practice, most cGAN approaches tend to learn an overly simplified distribution where an input is always mapped to a single output regardless of variations in latent code. To address such issue, we propose to explicitly regularize the generator to produce diverse outputs depending on latent codes. The proposed regularization is simple, general, and can be easily integrated into most conditional GAN objectives. Additionally, explicit regularization on generator allows our method to control a balance between visual quality and diversity. We demonstrate the effectiveness of our method on three conditional generation tasks: image-to-image translation, image inpainting, and future video prediction. We show that simple addition of our regularization to existing models leads to surprisingly diverse generations, substantially outperforming the previous approaches for multi-modal conditional generation specifically designed in each individual task.
Optimal Mini-Batch Size Selection for Fast Gradient Descent
Nov 15, 2019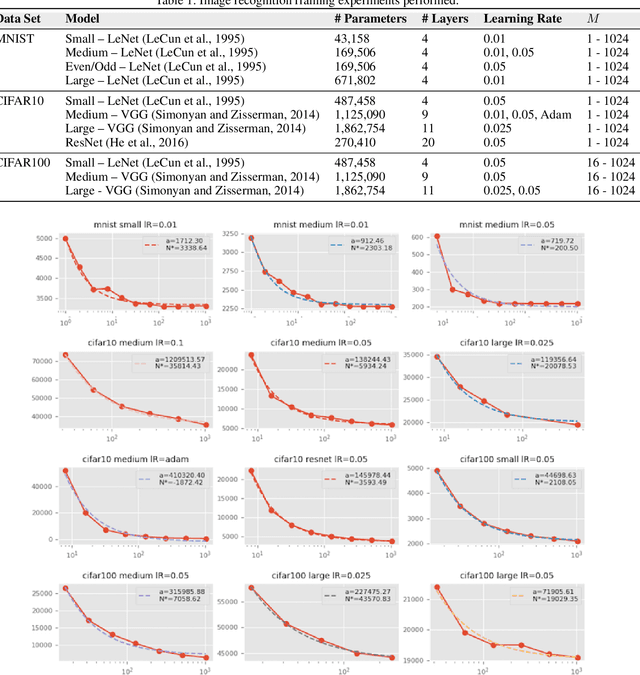
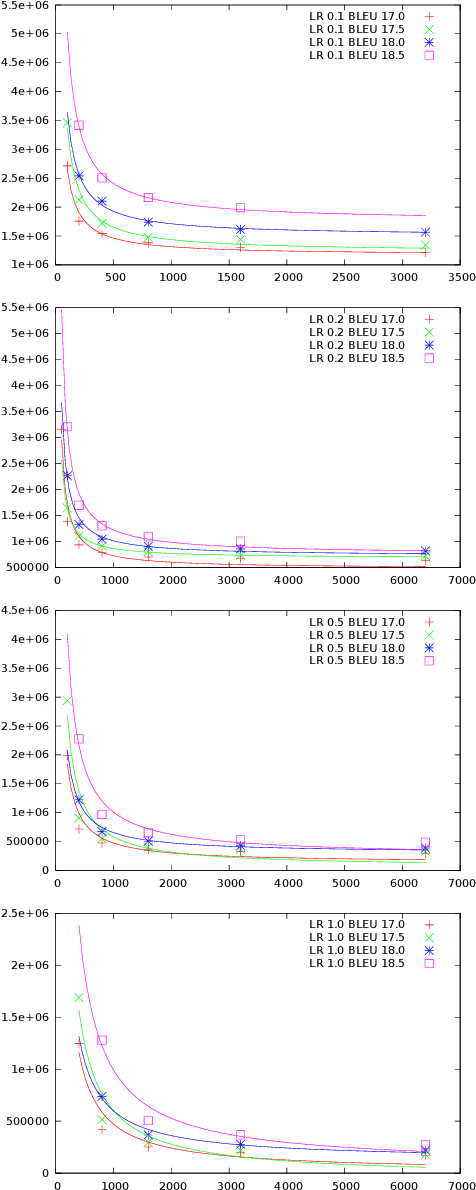
This paper presents a methodology for selecting the mini-batch size that minimizes Stochastic Gradient Descent (SGD) learning time for single and multiple learner problems. By decoupling algorithmic analysis issues from hardware and software implementation details, we reveal a robust empirical inverse law between mini-batch size and the average number of SGD updates required to converge to a specified error threshold. Combining this empirical inverse law with measured system performance, we create an accurate, closed-form model of average training time and show how this model can be used to identify quantifiable implications for both algorithmic and hardware aspects of machine learning. We demonstrate the inverse law empirically, on both image recognition (MNIST, CIFAR10 and CIFAR100) and machine translation (Europarl) tasks, and provide a theoretic justification via proving a novel bound on mini-batch SGD training.
Crowd Scene Analysis by Output Encoding
Jan 27, 2020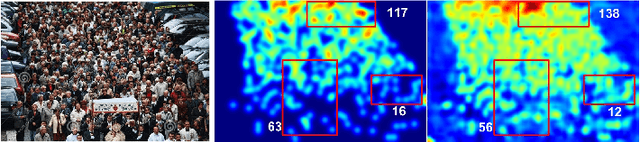
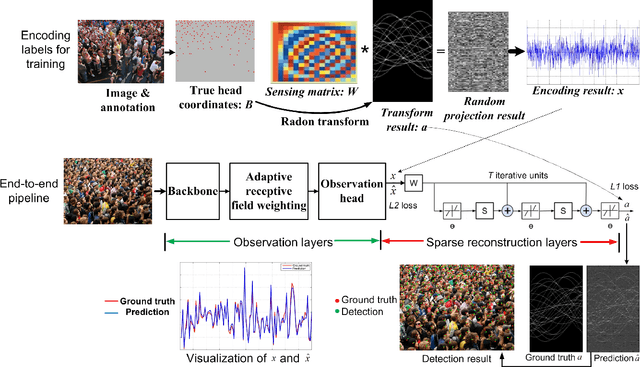
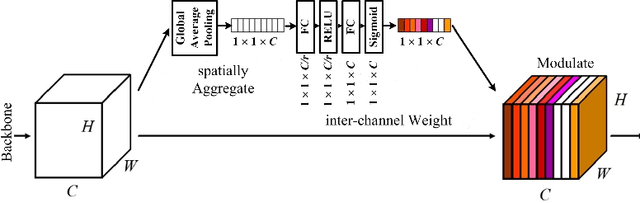

Crowd scene analysis receives growing attention due to its wide applications. Grasping the accurate crowd location (rather than merely crowd count) is important for spatially identifying high-risk regions in congested scenes. In this paper, we propose a Compressed Sensing based Output Encoding (CSOE) scheme, which casts detecting pixel coordinates of small objects into a task of signal regression in encoding signal space. CSOE helps to boost localization performance in circumstances where targets are highly crowded without huge scale variation. In addition, proper receptive field sizes are crucial for crowd analysis due to human size variations. We create Multiple Dilated Convolution Branches (MDCB) that offers a set of different receptive field sizes, to improve localization accuracy when objects sizes change drastically in an image. Also, we develop an Adaptive Receptive Field Weighting (ARFW) module, which further deals with scale variation issue by adaptively emphasizing informative channels that have proper receptive field size. Experiments demonstrate the effectiveness of the proposed method, which achieves state-of-the-art performance across four mainstream datasets, especially achieves excellent results in highly crowded scenes. More importantly, experiments support our insights that it is crucial to tackle target size variation issue in crowd analysis task, and casting crowd localization as regression in encoding signal space is quite effective for crowd analysis.
Arbitrary Style Transfer with Style-Attentional Networks
Jan 03, 2019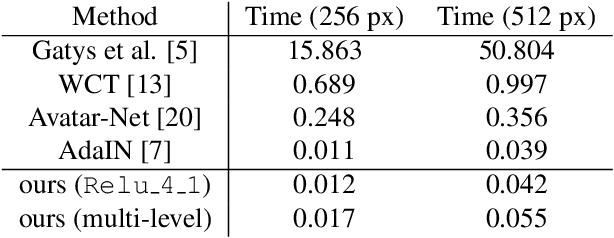
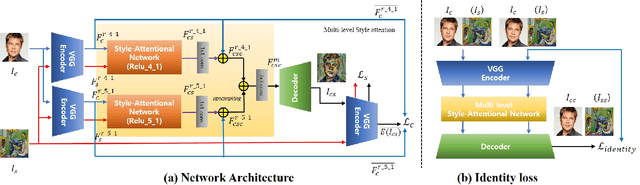
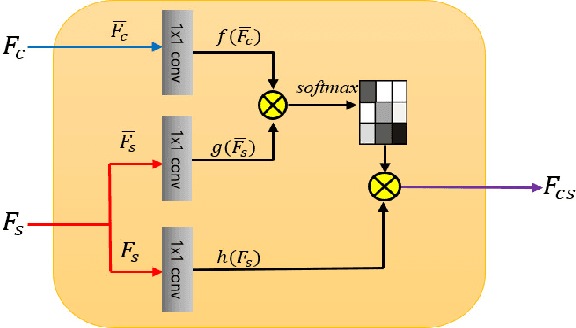
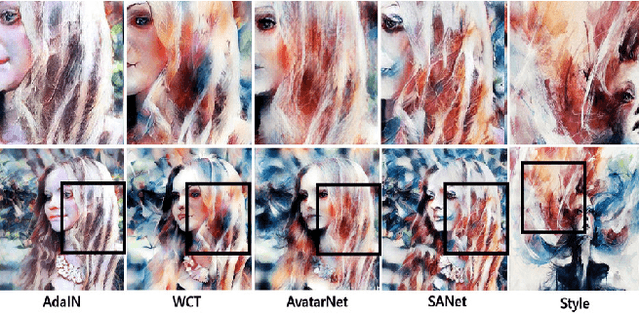
Arbitrary style transfer aims to synthesize a content image with style of an image that has never been seen before. Recent arbitrary style transfer algorithms have trade-off between the content structure and the style patterns, or maintaining the global and local style patterns at the same time is difficult due to the patch-based mechanism. In this paper, we introduce a novel style-attentional network (SANet), which efficiently and flexibly decorates the local style patterns according to the semantic spatial distribution of the content image. A new identity loss function and a multi-level features embedding also make our SANet and decoder preserve the content structure as much as possible while enriching the style patterns. Experimental results demonstrate that our algorithm synthesizes higher-quality stylized images in real-time than the state-of-the-art-algorithms.
ChemGrapher: Optical Graph Recognition of Chemical Compounds by Deep Learning
Feb 23, 2020
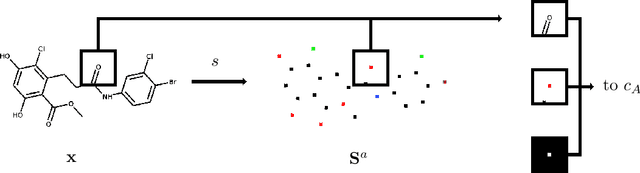
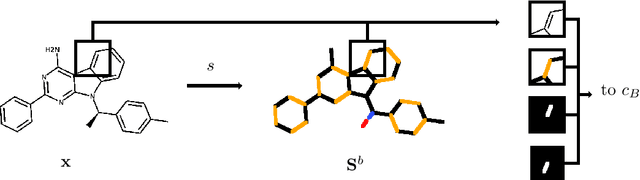

In drug discovery, knowledge of the graph structure of chemical compounds is essential. Many thousands of scientific articles in chemistry and pharmaceutical sciences have investigated chemical compounds, but in cases the details of the structure of these chemical compounds is published only as an images. A tool to analyze these images automatically and convert them into a chemical graph structure would be useful for many applications, such drug discovery. A few such tools are available and they are mostly derived from optical character recognition. However, our evaluation of the performance of those tools reveals that they make often mistakes in detecting the correct bond multiplicity and stereochemical information. In addition, errors sometimes even lead to missing atoms in the resulting graph. In our work, we address these issues by developing a compound recognition method based on machine learning. More specifically, we develop a deep neural network model for optical compound recognition. The deep learning solution presented here consists of a segmentation model, followed by three classification models that predict atom locations, bonds and charges. Furthermore, this model not only predicts the graph structure of the molecule but also produces all information necessary to relate each component of the resulting graph to the source image. This solution is scalable and could rapidly process thousands of images. Finally, we compare empirically the proposed method to a well-established tool and observe significant error reductions.
End-to-end Training of CNN-CRF via Differentiable Dual-Decomposition
Dec 06, 2019
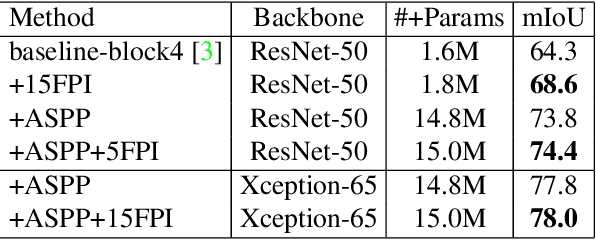

Modern computer vision (CV) is often based on convolutional neural networks (CNNs) that excel at hierarchical feature extraction. The previous generation of CV approaches was often based on conditional random fields (CRFs) that excel at modeling flexible higher order interactions. As their benefits are complementary they are often combined. However, these approaches generally use mean-field approximations and thus, arguably, did not directly optimize the real problem. Here we revisit dual-decomposition-based approaches to CRF optimization, an alternative to the mean-field approximation. These algorithms can efficiently and exactly solve sub-problems and directly optimize a convex upper bound of the real problem, providing optimality certificates on the way. Our approach uses a novel fixed-point iteration algorithm which enjoys dual-monotonicity, dual-differentiability and high parallelism. The whole system, CRF and CNN can thus be efficiently trained using back-propagation. We demonstrate the effectiveness of our system on semantic image segmentation, showing consistent improvement over baseline models.
Abnormal Client Behavior Detection in Federated Learning
Oct 22, 2019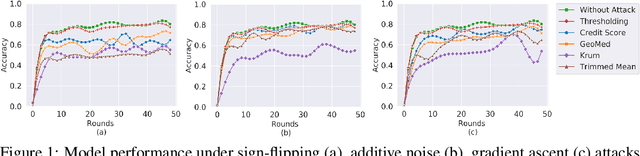
In federated learning systems, clients are autonomous in that their behaviors are not fully governed by the server. Consequently, a client may intentionally or unintentionally deviate from the prescribed course of federated model training, resulting in abnormal behaviors, such as turning into a malicious attacker or a malfunctioning client. Timely detecting those anomalous clients is therefore critical to minimize their adverse impacts. In this work, we propose to detect anomalous clients at the server side. In particular, we generate low-dimensional surrogates of model weight vectors and use them to perform anomaly detection. We evaluate our solution through experiments on image classification model training over the FEMNIST dataset. Experimental results show that the proposed detection-based approach significantly outperforms the conventional defense-based methods.
Markov-Chain Monte Carlo Approximation of the Ideal Observer using Generative Adversarial Networks
Jan 26, 2020
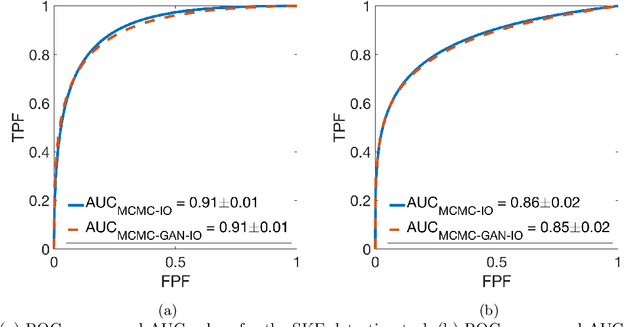
The Ideal Observer (IO) performance has been advocated when optimizing medical imaging systems for signal detection tasks. However, analytical computation of the IO test statistic is generally intractable. To approximate the IO test statistic, sampling-based methods that employ Markov-Chain Monte Carlo (MCMC) techniques have been developed. However, current applications of MCMC techniques have been limited to several object models such as a lumpy object model and a binary texture model, and it remains unclear how MCMC methods can be implemented with other more sophisticated object models. Deep learning methods that employ generative adversarial networks (GANs) hold great promise to learn stochastic object models (SOMs) from image data. In this study, we described a method to approximate the IO by applying MCMC techniques to SOMs learned by use of GANs. The proposed method can be employed with arbitrary object models that can be learned by use of GANs, thereby the domain of applicability of MCMC techniques for approximating the IO performance is extended. In this study, both signal-known-exactly (SKE) and signal-known-statistically (SKS) binary signal detection tasks are considered. The IO performance computed by the proposed method is compared to that computed by the conventional MCMC method. The advantages of the proposed method are discussed.
Generating Natural Language Explanations for Visual Question Answering using Scene Graphs and Visual Attention
Feb 15, 2019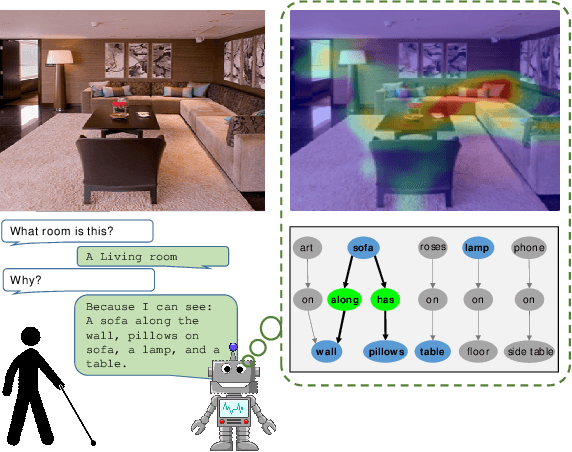
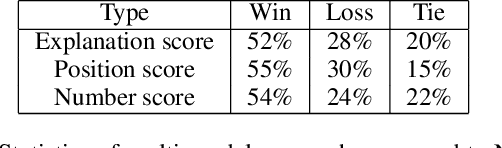

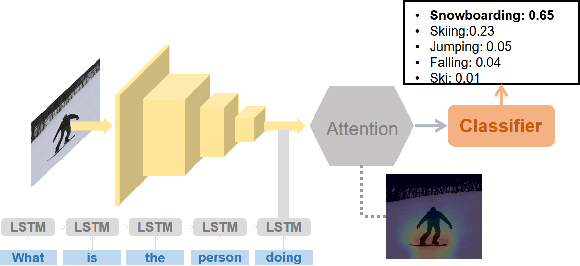
In this paper, we present a novel approach for the task of eXplainable Question Answering (XQA), i.e., generating natural language (NL) explanations for the Visual Question Answering (VQA) problem. We generate NL explanations comprising of the evidence to support the answer to a question asked to an image using two sources of information: (a) annotations of entities in an image (e.g., object labels, region descriptions, relation phrases) generated from the scene graph of the image, and (b) the attention map generated by a VQA model when answering the question. We show how combining the visual attention map with the NL representation of relevant scene graph entities, carefully selected using a language model, can give reasonable textual explanations without the need of any additional collected data (explanation captions, etc). We run our algorithms on the Visual Genome (VG) dataset and conduct internal user-studies to demonstrate the efficacy of our approach over a strong baseline. We have also released a live web demo showcasing our VQA and textual explanation generation using scene graphs and visual attention.
Merlin: Enabling Machine Learning-Ready HPC Ensembles
Dec 05, 2019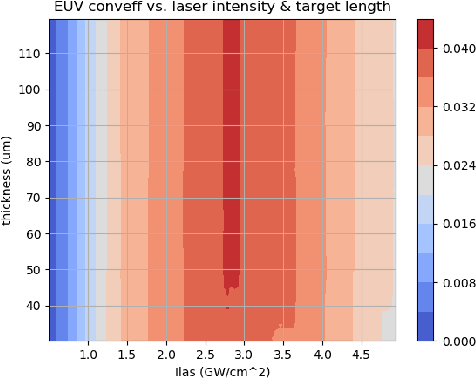
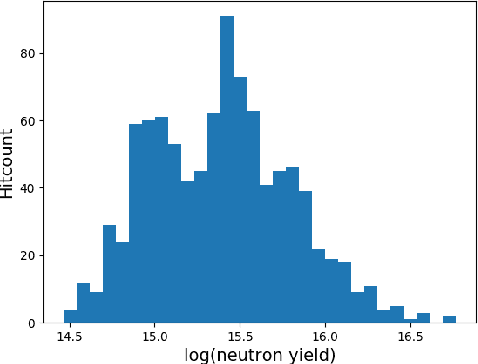
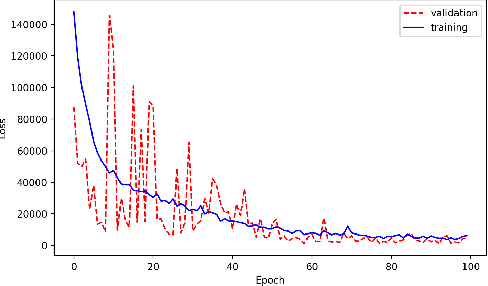
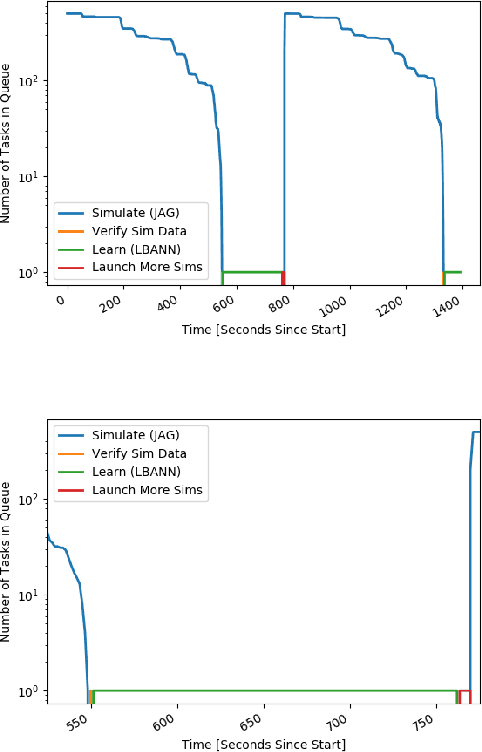
With the growing complexity of computational and experimental facilities, many scientific researchers are turning to machine learning (ML) techniques to analyze large scale ensemble data. With complexities such as multi-component workflows, heterogeneous machine architectures, parallel file systems, and batch scheduling, care must be taken to facilitate this analysis in a high performance computing (HPC) environment. In this paper, we present Merlin, a workflow framework to enable large ML-friendly ensembles of scientific HPC simulations. By augmenting traditional HPC with distributed compute technologies, Merlin aims to lower the barrier for scientific subject matter experts to incorporate ML into their analysis. In addition to its design and some examples, we describe how Merlin was deployed on the Sierra Supercomputer at Lawrence Livermore National Laboratory to create an unprecedented benchmark inertial confinement fusion dataset of approximately 100 million individual simulations and over 24 terabytes of multi-modal physics-based scalar, vector and hyperspectral image data.