 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSCAR: Orchestrated Self-verification and Cross-path Refinement
Apr 02, 2026Diffusion language models (DLMs) expose their denoising trajectories, offering a natural handle for inference-time control; accordingly, an ideal hallucination mitigation framework should intervene during generation using this model-native signal rather than relying on an externally trained hallucination classifier. Toward this, we formulate commitment uncertainty localization: given a denoising trajectory, identify token positions whose cross-chain entropy exceeds an unsupervised threshold before factually unreliable commitments propagate into self-consistent but incorrect outputs. We introduce a suite of trajectory-level assessments, including a cross-chain divergence-at-hallucination (CDH) metric, for principled comparison of localization methods. We also introduce OSCAR, a training-free inference-time framework operationalizing this formulation. OSCAR runs N parallel denoising chains with randomized reveal orders, computes cross-chain Shannon entropy to detect high-uncertainty positions, and then performs targeted remasking conditioned on retrieved evidence. Ablations confirm that localization and correction contribute complementary gains, robust across N in {4, 8, 16}. On TriviaQA, HotpotQA, RAGTruth, and CommonsenseQA using LLaDA-8B and Dream-7B, OSCAR enhances generation quality by significantly reducing hallucinated content and improving factual accuracy through uncertainty-guided remasking, which also facilitates more effective integration of retrieved evidence. Its native entropy-based uncertainty signal surpasses that of specialized trained detectors, highlighting an inherent capacity of diffusion language models to identify factual uncertainty that is not present in the sequential token commitment structure of autoregressive models. We are releasing the codebase1 to support future research on localization and uncertainty-aware generation in DLMs.
End-to-end Training of CNN-CRF via Differentiable Dual-Decomposition
Dec 06, 2019
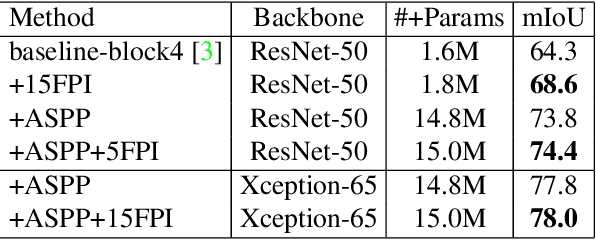

Modern computer vision (CV) is often based on convolutional neural networks (CNNs) that excel at hierarchical feature extraction. The previous generation of CV approaches was often based on conditional random fields (CRFs) that excel at modeling flexible higher order interactions. As their benefits are complementary they are often combined. However, these approaches generally use mean-field approximations and thus, arguably, did not directly optimize the real problem. Here we revisit dual-decomposition-based approaches to CRF optimization, an alternative to the mean-field approximation. These algorithms can efficiently and exactly solve sub-problems and directly optimize a convex upper bound of the real problem, providing optimality certificates on the way. Our approach uses a novel fixed-point iteration algorithm which enjoys dual-monotonicity, dual-differentiability and high parallelism. The whole system, CRF and CNN can thus be efficiently trained using back-propagation. We demonstrate the effectiveness of our system on semantic image segmentation, showing consistent improvement over baseline models.