 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LXMERT: Learning Cross-Modality Encoder Representations from Transformers
Aug 22, 2019
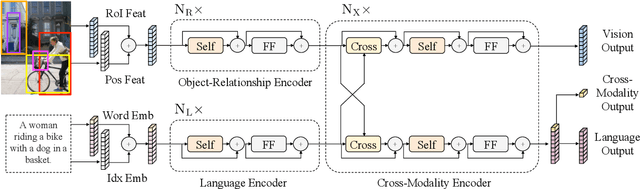
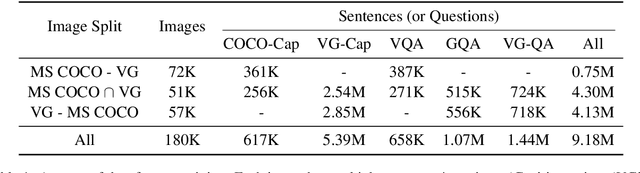
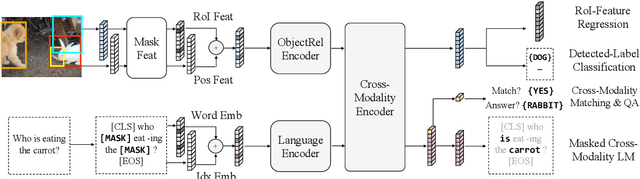
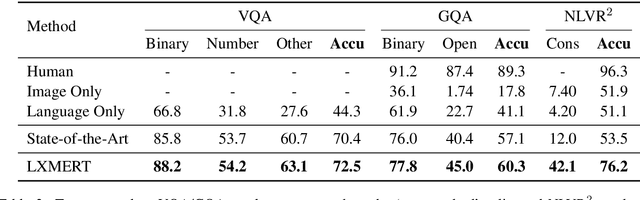
Vision-and-language reasoning requires an understanding of visual concepts, language semantics, and, most importantly, the alignment and relationships between these two modalities. We thus propose the LXMERT (Learning Cross-Modality Encoder Representations from Transformers) framework to learn these vision-and-language connections. In LXMERT, we build a large-scale Transformer model that consists of three encoders: an object relationship encoder, a language encoder, and a cross-modality encoder. Next, to endow our model with the capability of connecting vision and language semantics, we pre-train the model with large amounts of image-and-sentence pairs, via five diverse representative pre-training tasks: masked language modeling, masked object prediction (feature regression and label classification), cross-modality matching, and image question answering. These tasks help in learning both intra-modality and cross-modality relationships. After fine-tuning from our pre-trained parameters, our model achieves the state-of-the-art results on two visual question answering datasets (i.e., VQA and GQA). We also show the generalizability of our pre-trained cross-modality model by adapting it to a challenging visual-reasoning task, NLVR2, and improve the previous best result by 22% absolute (54% to 76%). Lastly, we demonstrate detailed ablation studies to prove that both our novel model components and pre-training strategies significantly contribute to our strong results. Code and pre-trained models publicly available at: https://github.com/airsplay/lxmert
Compressed MRI Reconstruction Exploiting a Rotation-Invariant Total Variation Discretization
Nov 26, 2019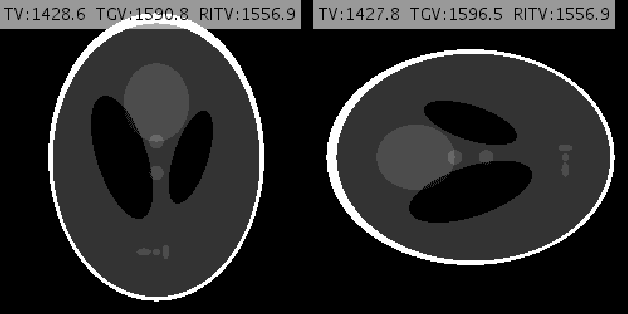
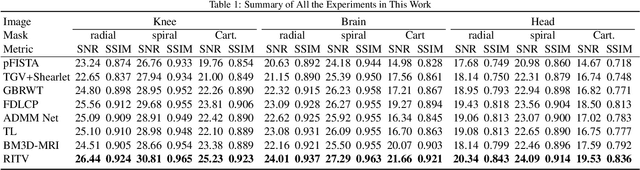
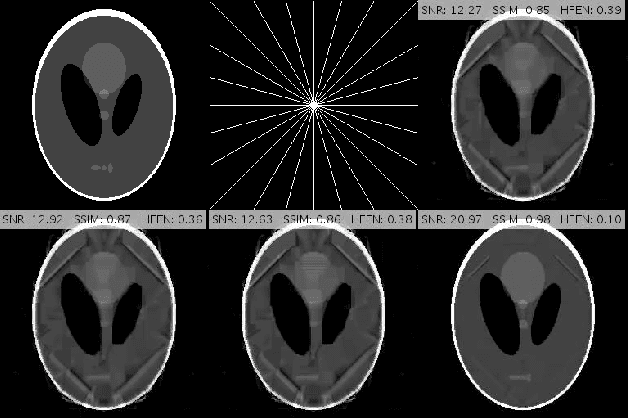
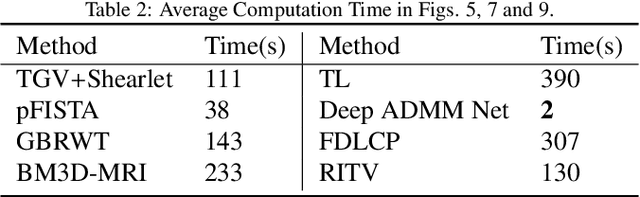
Inspired by the first-order method of Malitsky and Pock, we propose a novel variational framework for compressed MR image reconstruction which introduces the application of a rotation-invariant discretization of total variation functional into MR imaging while exploiting BM3D frame as a sparsifying transform. The proposed model is presented as a constrained optimization problem, however, we do not use conventional ADMM-type algorithms designed for constrained problems to obtain a solution, but rather we tailor the linesearch-equipped method of Malitsky and Pock to our model, which was originally proposed for unconstrained problems. As attested by numerical experiments, this framework significantly outperforms various state-of-the-art algorithms from variational methods to adaptive and learning approaches and in particular, it eliminates the stagnating behavior of a previous work on BM3D-MRI which compromised the solution beyond a certain iteration.
Advanced Super-Resolution using Lossless Pooling Convolutional Networks
Dec 14, 2018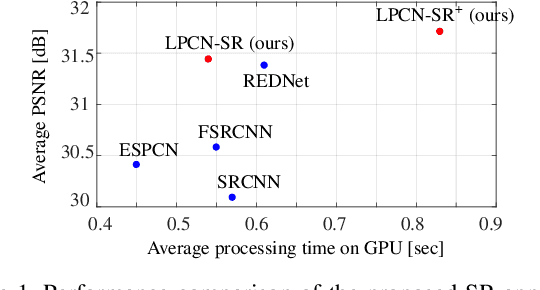
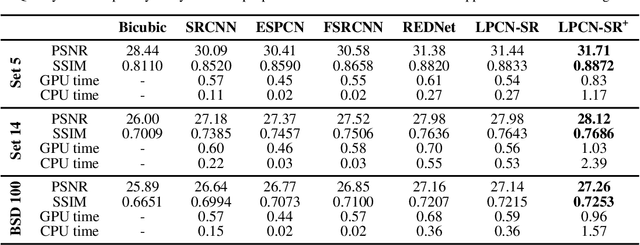
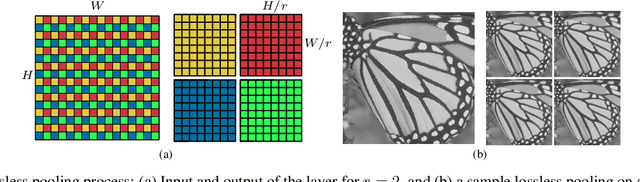
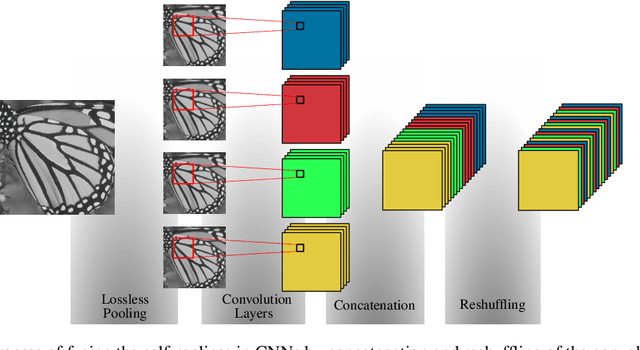
In this paper, we present a novel deep learning-based approach for still image super-resolution, that unlike the mainstream models does not rely solely on the input low resolution image for high quality upsampling, and takes advantage of a set of artificially created auxiliary self-replicas of the input image that are incorporated in the neural network to create an enhanced and accurate upscaling scheme. Inclusion of the proposed lossless pooling layers, and the fusion of the input self-replicas enable the model to exploit the high correlation between multiple instances of the same content, and eventually result in significant improvements in the quality of the super-resolution, which is confirmed by extensive evaluations.
Neural Networks as Explicit Word-Based Rules
Jul 10, 2019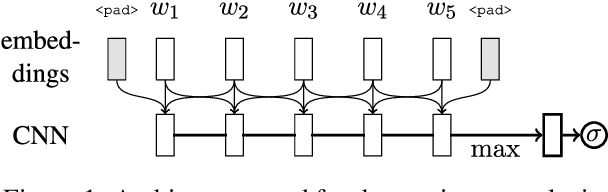

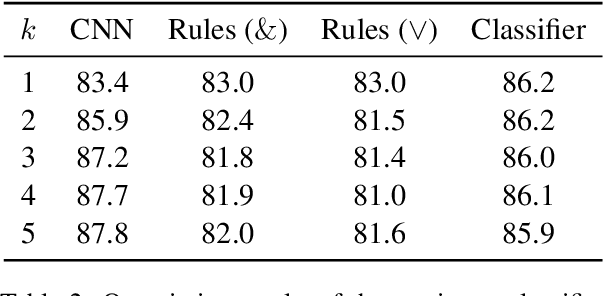
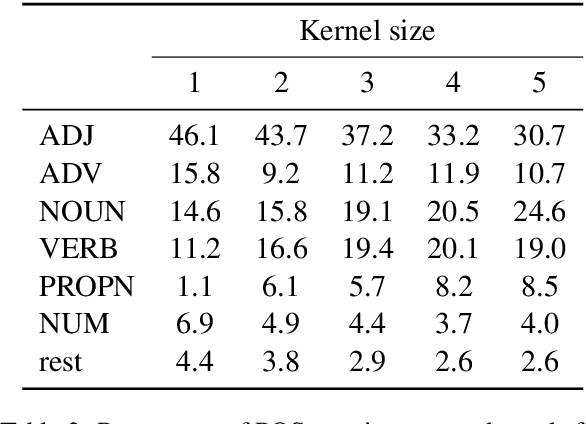
Filters of convolutional networks used in computer vision are often visualized as image patches that maximize the response of the filter. We use the same approach to interpret weight matrices in simple architectures for natural language processing tasks. We interpret a convolutional network for sentiment classification as word-based rules. Using the rule, we recover the performance of the original model.
SuperGlue: Learning Feature Matching with Graph Neural Networks
Nov 26, 2019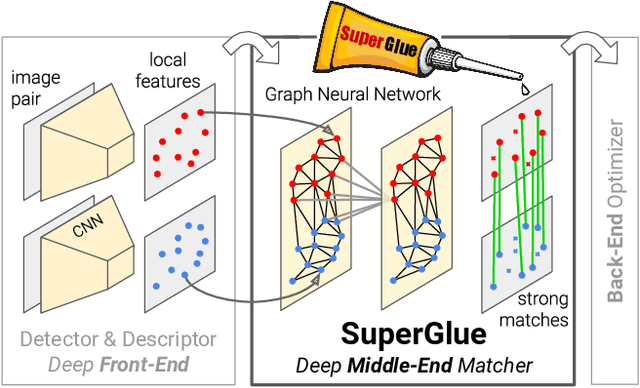
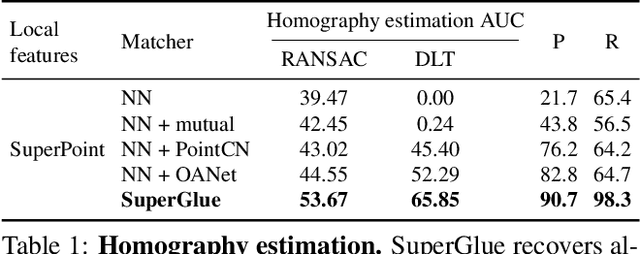

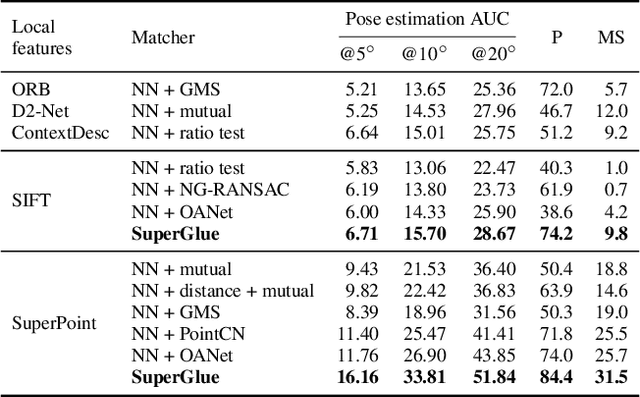
This paper introduces SuperGlue, a neural network that matches two sets of local features by jointly finding correspondences and rejecting non-matchable points. Assignments are estimated by solving a differentiable optimal transport problem, whose costs are predicted by a graph neural network. We introduce a flexible context aggregation mechanism based on attention, enabling SuperGlue to reason about the underlying 3D scene and feature assignments jointly. Compared to traditional, hand-designed heuristics, our technique learns priors over geometric transformations and regularities of the 3D world through end-to-end training from image pairs. SuperGlue outperforms other learned approaches and achieves state-of-the-art results on the task of pose estimation in challenging real-world indoor and outdoor environments. The proposed method performs matching in real-time on a modern GPU and can be readily integrated into modern SfM or SLAM systems.
Extreme Channel Prior Embedded Network for Dynamic Scene Deblurring
Mar 02, 2019

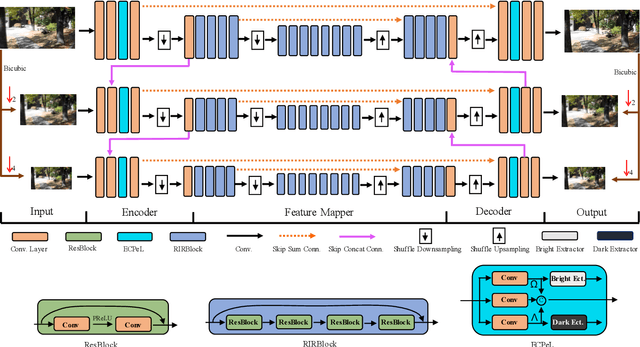
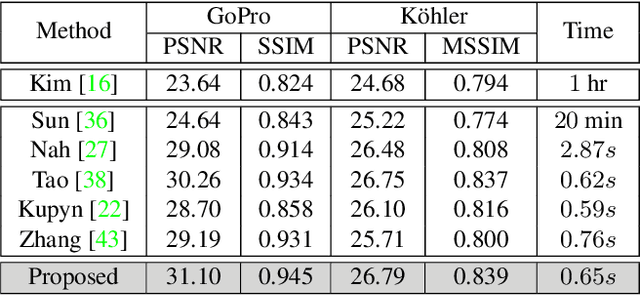
Recent years have witnessed the significant progress on convolutional neural networks (CNNs) in dynamic scene deblurring. While CNN models are generally learned by the reconstruction loss defined on training data, incorporating suitable image priors as well as regularization terms into the network architecture could boost the deblurring performance. In this work, we propose an Extreme Channel Prior embedded Network (ECPeNet) to plug the extreme channel priors (i.e., priors on dark and bright channels) into a network architecture for effective dynamic scene deblurring. A novel trainable extreme channel prior embedded layer (ECPeL) is developed to aggregate both extreme channel and blurry image representations, and sparse regularization is introduced to regularize the ECPeNet model learning. Furthermore, we present an effective multi-scale network architecture that works in both coarse-to-fine and fine-to-coarse manners for better exploiting information flow across scales. Experimental results on GoPro and Kohler datasets show that our proposed ECPeNet performs favorably against state-of-the-art deep image deblurring methods in terms of both quantitative metrics and visual quality.
Neural Bayes: A Generic Parameterization Method for Unsupervised Representation Learning
Feb 20, 2020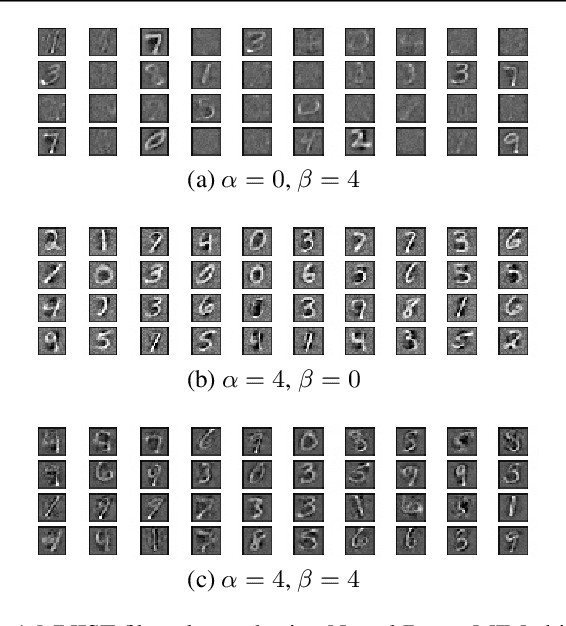
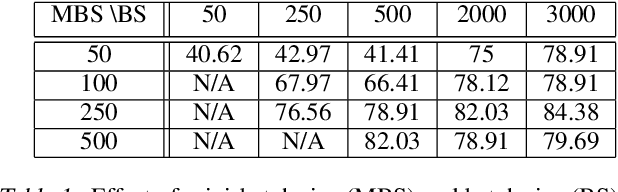
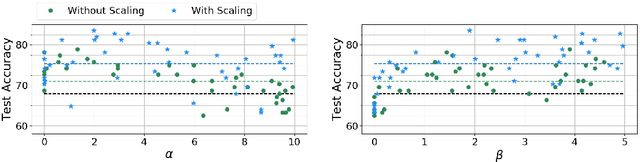
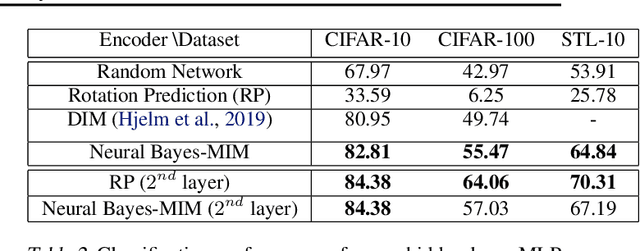
We introduce a parameterization method called Neural Bayes which allows computing statistical quantities that are in general difficult to compute and opens avenues for formulating new objectives for unsupervised representation learning. Specifically, given an observed random variable $\mathbf{x}$ and a latent discrete variable $z$, we can express $p(\mathbf{x}|z)$, $p(z|\mathbf{x})$ and $p(z)$ in closed form in terms of a sufficiently expressive function (Eg. neural network) using our parameterization without restricting the class of these distributions. To demonstrate its usefulness, we develop two independent use cases for this parameterization: 1. Mutual Information Maximization (MIM): MIM has become a popular means for self-supervised representation learning. Neural Bayes allows us to compute mutual information between observed random variables $\mathbf{x}$ and latent discrete random variables $z$ in closed form. We use this for learning image representations and show its usefulness on downstream classification tasks. 2. Disjoint Manifold Labeling: Neural Bayes allows us to formulate an objective which can optimally label samples from disjoint manifolds present in the support of a continuous distribution. This can be seen as a specific form of clustering where each disjoint manifold in the support is a separate cluster. We design clustering tasks that obey this formulation and empirically show that the model optimally labels the disjoint manifolds. Our code is available at \url{https://github.com/salesforce/NeuralBayes}
M^2 Deep-ID: A Novel Model for Multi-View Face Identification Using Convolutional Deep Neural Networks
Jan 22, 2020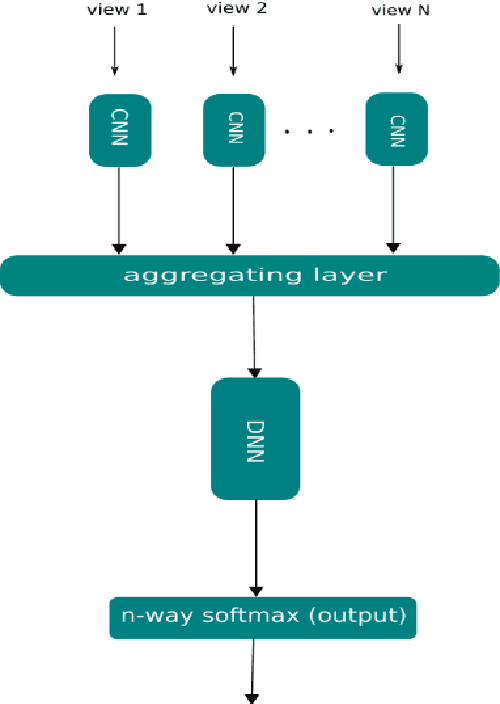
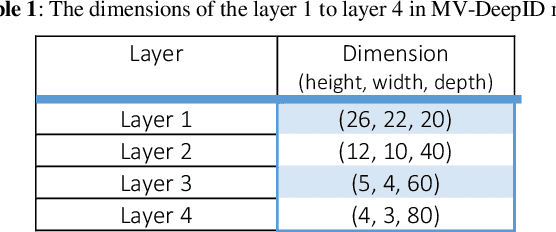
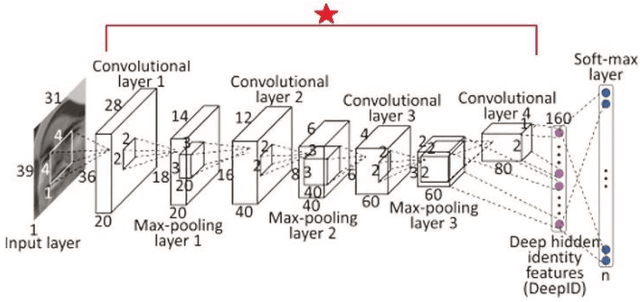

Despite significant advances in Deep Face Recognition (DFR) systems, introducing new DFRs under specific constraints such as varying pose still remains a big challenge. Most particularly, due to the 3D nature of a human head, facial appearance of the same subject introduces a high intra-class variability when projected to the camera image plane. In this paper, we propose a new multi-view Deep Face Recognition (MVDFR) system to address the mentioned challenge. In this context, multiple 2D images of each subject under different views are fed into the proposed deep neural network with a unique design to re-express the facial features in a single and more compact face descriptor, which in turn, produces a more informative and abstract way for face identification using convolutional neural networks. To extend the functionality of our proposed system to multi-view facial images, the golden standard Deep-ID model is modified in our proposed model. The experimental results indicate that our proposed method yields a 99.8% accuracy, while the state-of-the-art method achieves a 97% accuracy. We also gathered the Iran University of Science and Technology (IUST) face database with 6552 images of 504 subjects to accomplish our experiments.
Panoramic Annular Localizer: Tackling the Variation Challenges of Outdoor Localization Using Panoramic Annular Images and Active Deep Descriptors
May 14, 2019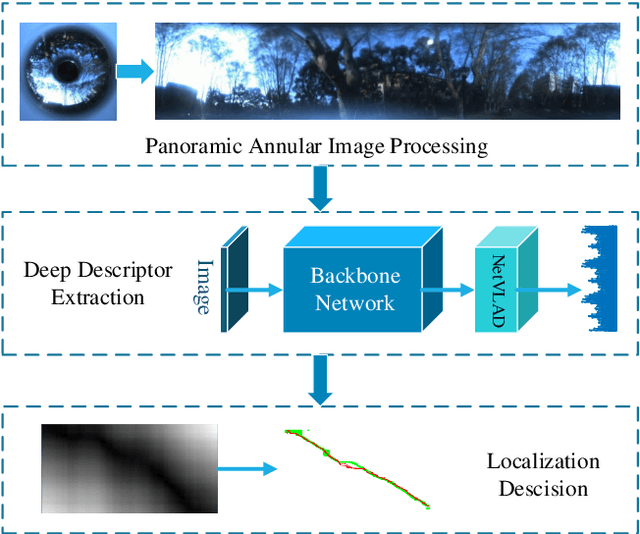
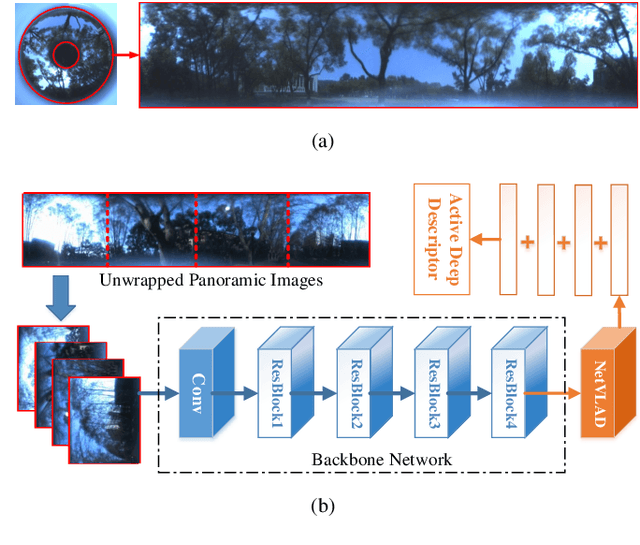
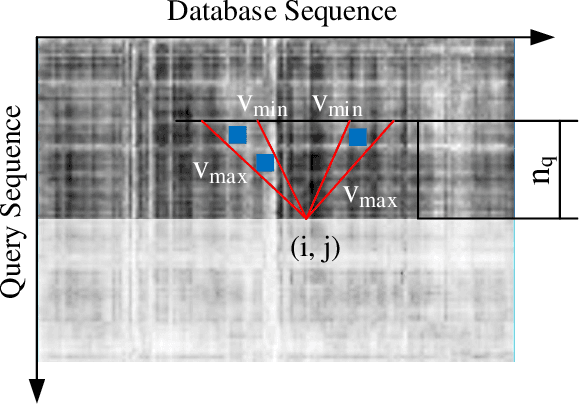
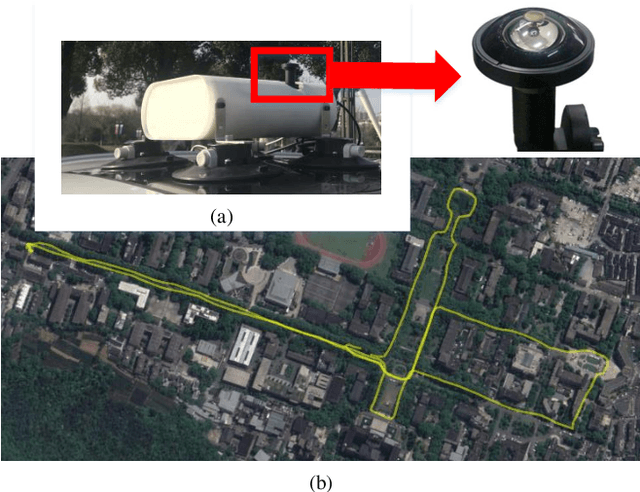
Visual localization is an attractive problem that estimates the camera localization from database images based on the query image. It is a crucial task for various applications, such as autonomous vehicles, assistive navigation and augmented reality. The challenging issues of the task lie in various appearance variations between query and database images, including illumination variations, season variations, dynamic object variations and viewpoint variations. In order to tackle those challenges, Panoramic Annular Localizer into which panoramic annular lens and robust deep image descriptors are incorporated is proposed in this paper. The panoramic annular images captured by the single camera are processed and fed into the NetVLAD network to form the active deep descriptor, and sequential matching is utilized to generate the localization result. The experiments carried on the public datasets and in the field illustrate the validation of the proposed system.
Self-labelling via simultaneous clustering and representation learning
Nov 26, 2019
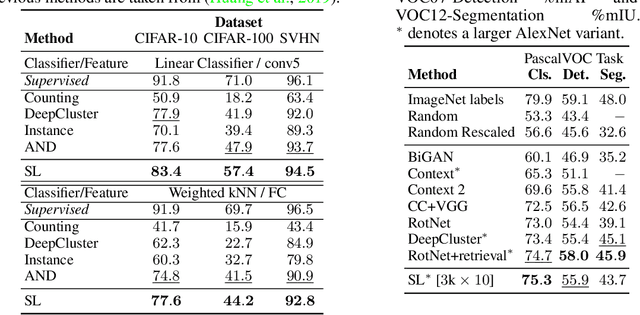
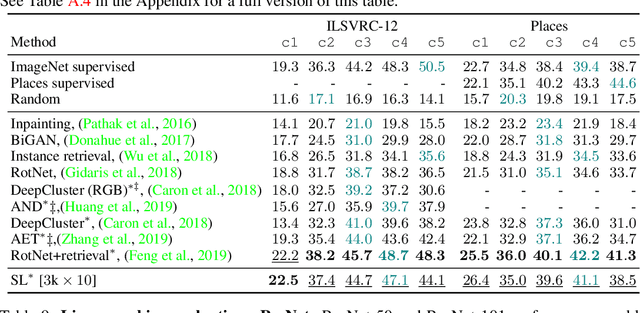
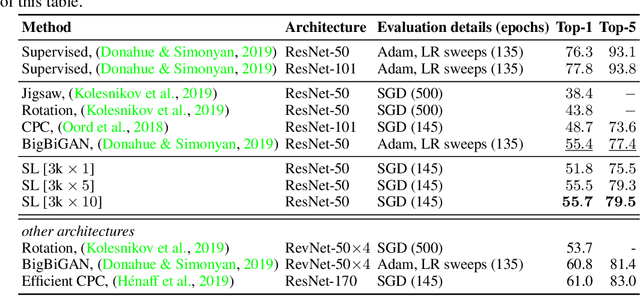
Combining clustering and representation learning is one of the most promising approaches for unsupervised learning of deep neural networks. However, doing so naively leads to ill posed learning problems with degenerate solutions. In this paper, we propose a novel and principled learning formulation that addresses these issues. The method is obtained by maximizing the information between labels and input data indices. We show that this criterion extends standard cross-entropy minimization to an optimal transport problem, which we solve efficiently for millions of input images and thousands of labels using a fast variant of the Sinkhorn-Knopp algorithm. The resulting method is able to self-label visual data so as to train highly competitive image representations without manual labels. Our method achieves state of the art representation learning performance for AlexNet and ResNet-50 on SVHN, CIFAR-10, CIFAR-100 and ImageNet.