 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attend to the Difference: Cross-Modality Person Re-identification via Contrastive Correlation
Oct 25, 2019
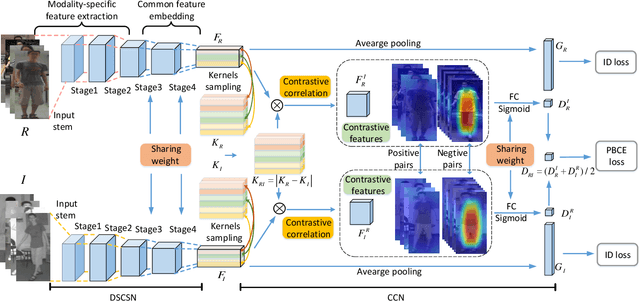

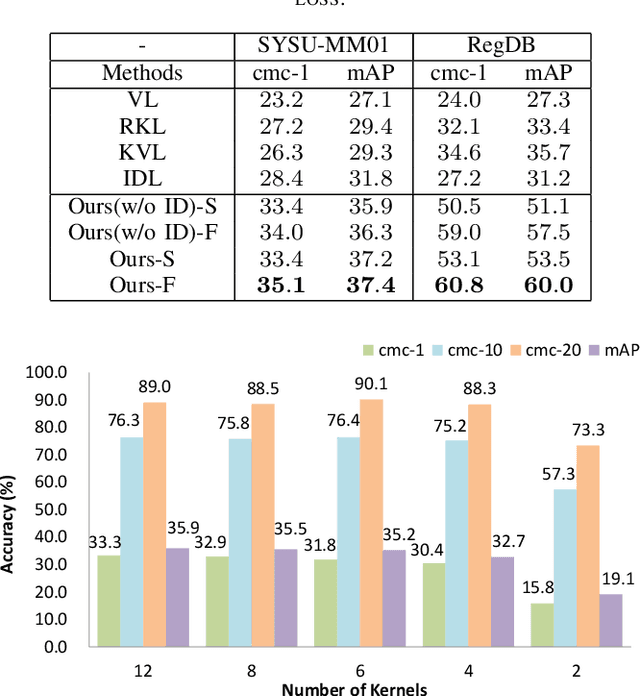
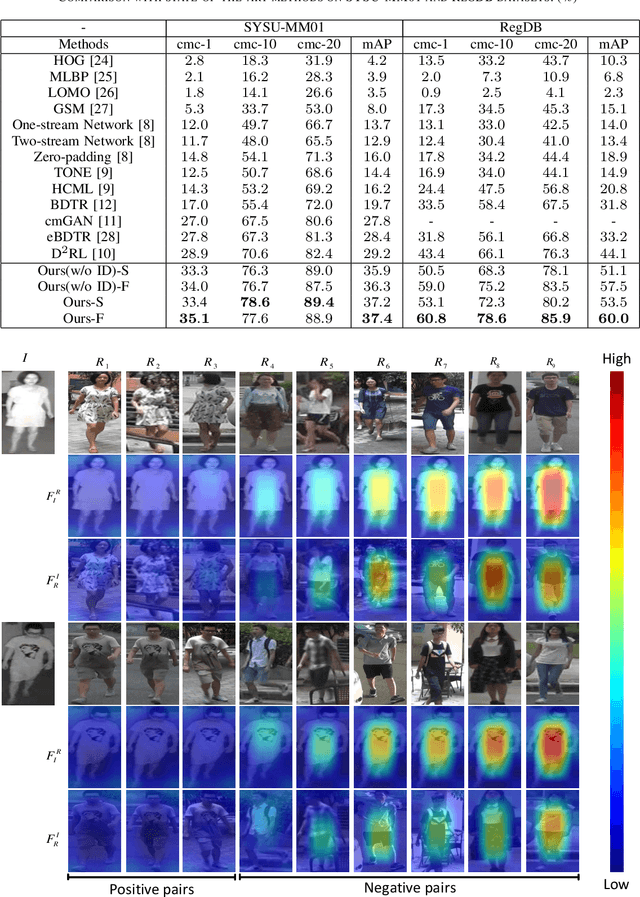
The problem of cross-modality person re-identification has been receiving increasing attention recently, due to its practical significance. Motivated by the fact that human usually attend to the difference when they compare two similar objects, we propose a dual-path cross-modality feature learning framework which preserves intrinsic spatial strictures and attends to the difference of input cross-modality image pairs. Our framework is composed by two main components: a Dual-path Spatial-structure-preserving Common Space Network (DSCSN) and a Contrastive Correlation Network (CCN). The former embeds cross-modality images into a common 3D tensor space without losing spatial structures, while the latter extracts contrastive features by dynamically comparing input image pairs. Note that the representations generated for the input RGB and Infrared images are mutually dependant to each other. We conduct extensive experiments on two public available RGB-IR ReID datasets, SYSU-MM01 and RegDB, and our proposed method outperforms state-of-the-art algorithms by a large margin with both full and simplified evaluation modes.
Embedding Compression with Isotropic Iterative Quantization
Jan 11, 2020
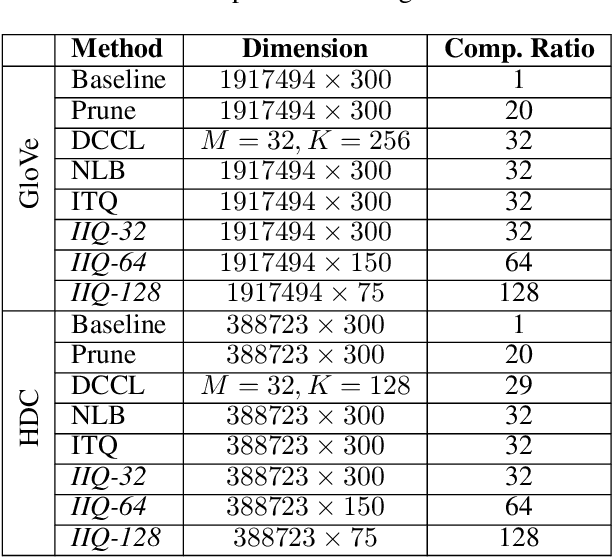
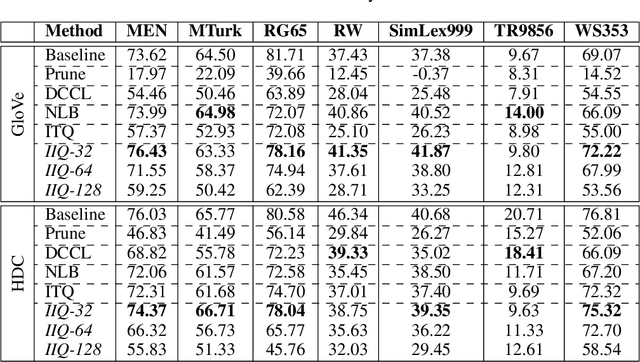
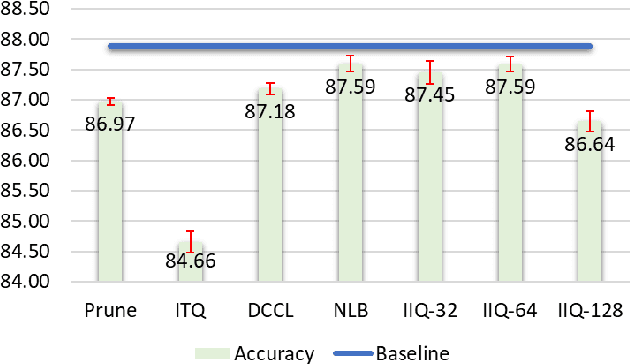
Continuous representation of words is a standard component in deep learning-based NLP models. However, representing a large vocabulary requires significant memory, which can cause problems, particularly on resource-constrained platforms. Therefore, in this paper we propose an isotropic iterative quantization (IIQ) approach for compressing embedding vectors into binary ones, leveraging the iterative quantization technique well established for image retrieval, while satisfying the desired isotropic property of PMI based models. Experiments with pre-trained embeddings (i.e., GloVe and HDC) demonstrate a more than thirty-fold compression ratio with comparable and sometimes even improved performance over the original real-valued embedding vectors.
One-Shot Object Detection with Co-Attention and Co-Excitation
Nov 28, 2019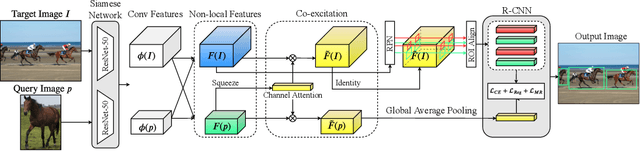

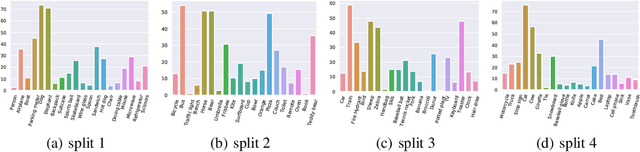
This paper aims to tackle the challenging problem of one-shot object detection. Given a query image patch whose class label is not included in the training data, the goal of the task is to detect all instances of the same class in a target image. To this end, we develop a novel {\em co-attention and co-excitation} (CoAE) framework that makes contributions in three key technical aspects. First, we propose to use the non-local operation to explore the co-attention embodied in each query-target pair and yield region proposals accounting for the one-shot situation. Second, we formulate a squeeze-and-co-excitation scheme that can adaptively emphasize correlated feature channels to help uncover relevant proposals and eventually the target objects. Third, we design a margin-based ranking loss for implicitly learning a metric to predict the similarity of a region proposal to the underlying query, no matter its class label is seen or unseen in training. The resulting model is therefore a two-stage detector that yields a strong baseline on both VOC and MS-COCO under one-shot setting of detecting objects from both seen and never-seen classes. Codes are available at https://github.com/timy90022/One-Shot-Object-Detection.
Automatic vocal tract landmark localization from midsagittal MRI data
Jul 18, 2019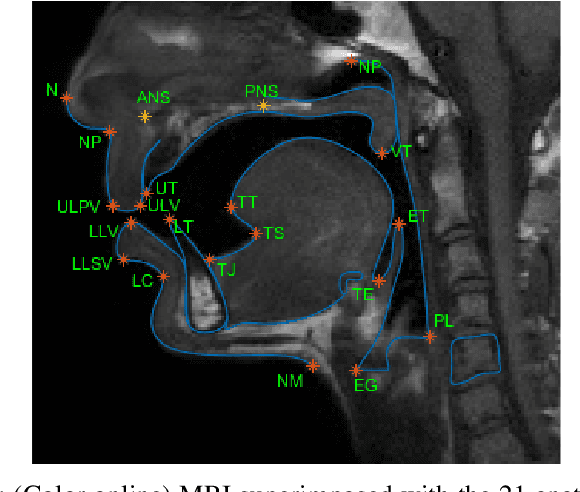
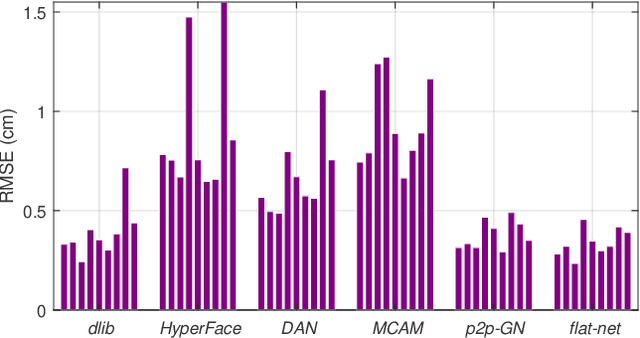
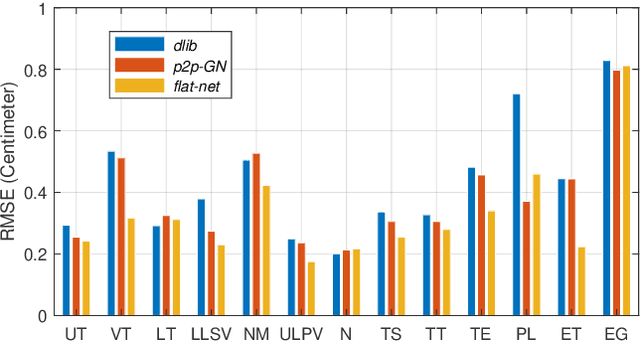
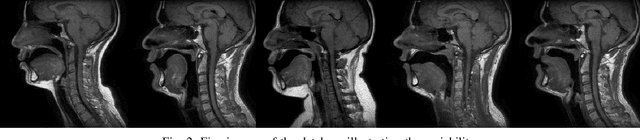
The various speech sounds of a language are obtained by varying the shape and position of the articulators surrounding the vocal tract. Analyzing their variability is crucial for understanding speech production, diagnosing speech and swallowing disorders and building intuitive applications for rehabilitation. Magnetic Resonance Imaging (MRI) is currently the most harmless powerful imaging modality used for this purpose. Identifying key anatomical landmarks on it is a pre-requisite for further analyses. This is a challenging task considering the high inter- and intra-speaker variability and the mutual interaction between the articulators. This study intends to solve this issue automatically for the first time. For this purpose, midsagittal anatomical MRI for 9 speakers sustaining 62 articulations and annotated with the location of 21 key anatomical landmarks are considered. Four state-of-the-art methods, including deep learning methods, are adapted from the literature for facial landmark localization and human pose estimation and evaluated. Furthermore, an approach based on the description of each landmark location as a heat-map image stored in a channel of a single multi-channel image embedding all landmarks is proposed. The generation of such a multi-channel image from an input MRI image is tested through two deep learning networks, one taken from the literature and one designed on purpose in this study, the flat-net. Results show that the flat-net approach outperforms the other methods, leading to an overall Root Mean Square Error of 3.4~pixels/0.34~cm obtained in a leave-one-out procedure over the speakers. All of the codes are publicly available on GitHub.
Needles in Haystacks: On Classifying Tiny Objects in Large Images
Aug 16, 2019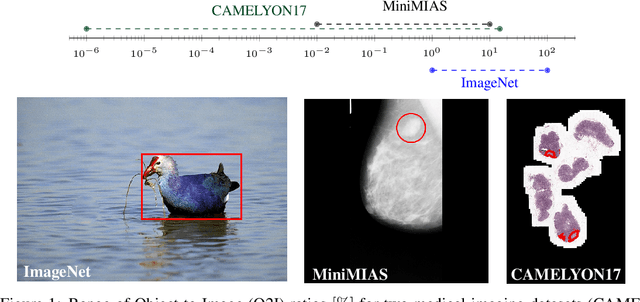
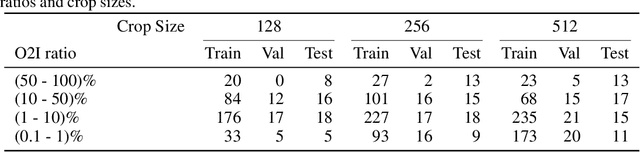
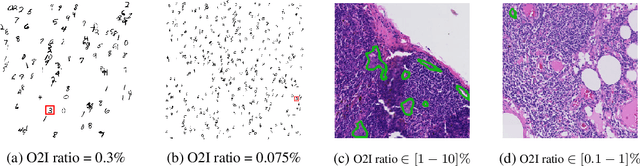
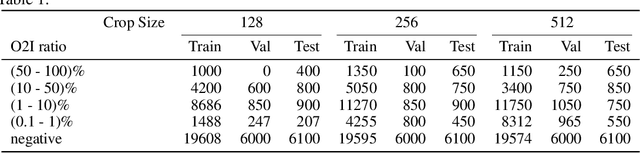
In some computer vision domains, such as medical or hyperspectral imaging, we care about the classification of tiny objects in large images. However, most Convolutional Neural Networks (CNNs) for image classification were developed and analyzed using biased datasets that contain large objects, most often, in central image positions. To assess whether classical CNN architectures work well for tiny object classification we build a comprehensive testbed containing two datasets: one derived from MNIST digits and other from histopathology images. This testbed allows us to perform controlled experiments to stress-test CNN architectures using a broad spectrum of signal-to-noise ratios. Our observations suggest that: (1) There exists a limit to signal-to-noise below which CNNs fail to generalize and that this limit is affected by dataset size - more data leading to better performances; however, the amount of training data required for the model to generalize scales rapidly with the inverse of the object-to-image ratio (2) in general, higher capacity models exhibit better generalization; (3) when knowing the approximate object sizes, adapting receptive field is beneficial; and (4) for very small signal-to-noise ratio the choice of global pooling operation affects optimization, whereas for relatively large signal-to-noise values, all tested global pooling operations exhibit similar performance.
Joint Color-Spatial-Directional clustering and Region Merging (JCSD-RM) for unsupervised RGB-D image segmentation
Sep 06, 2015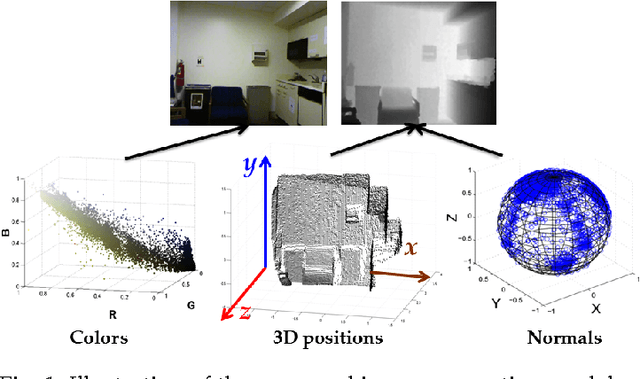
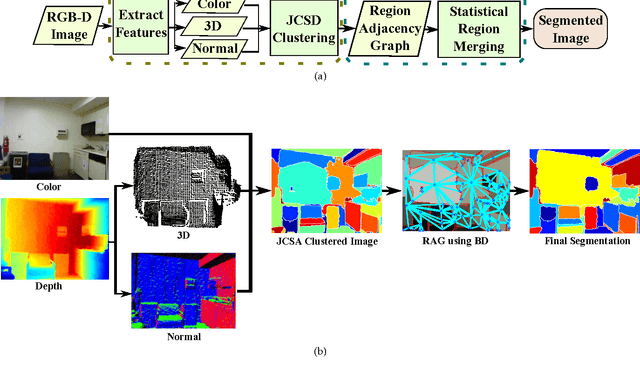
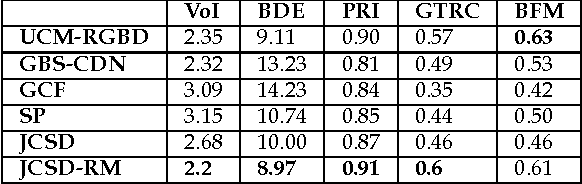
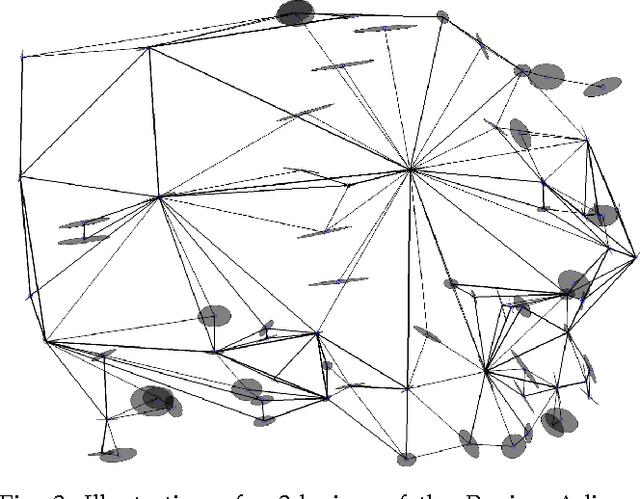
Recent advances in depth imaging sensors provide easy access to the synchronized depth with color, called RGB-D image. In this paper, we propose an unsupervised method for indoor RGB-D image segmentation and analysis. We consider a statistical image generation model based on the color and geometry of the scene. Our method consists of a joint color-spatial-directional clustering method followed by a statistical planar region merging method. We evaluate our method on the NYU depth database and compare it with existing unsupervised RGB-D segmentation methods. Results show that, it is comparable with the state of the art methods and it needs less computation time. Moreover, it opens interesting perspectives to fuse color and geometry in an unsupervised manner.
The Visual Social Distancing Problem
May 11, 2020
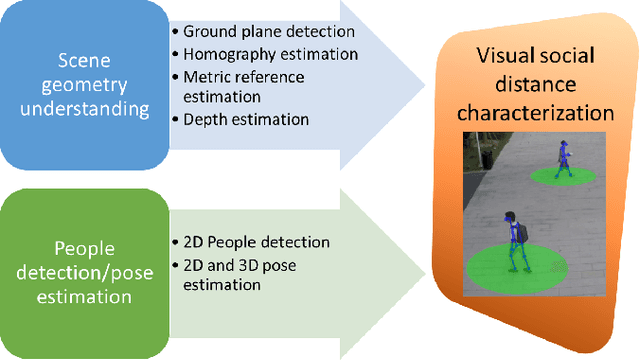
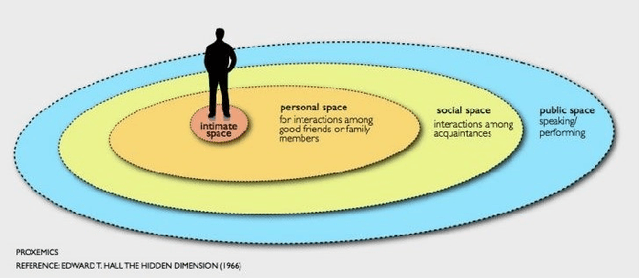
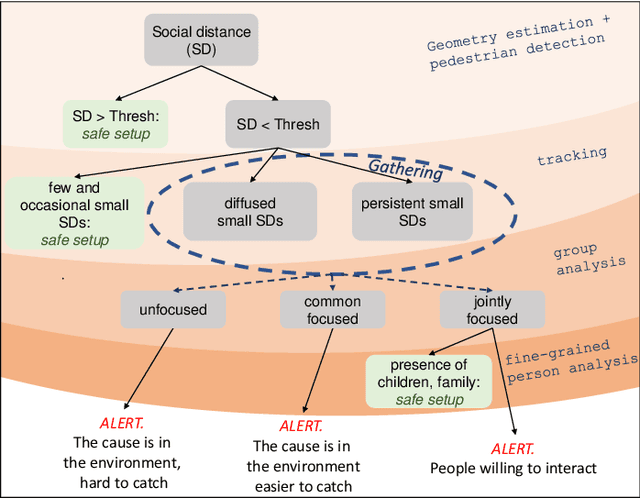
One of the main and most effective measures to contain the recent viral outbreak is the maintenance of the so-called Social Distancing (SD). To comply with this constraint, workplaces, public institutions, transports and schools will likely adopt restrictions over the minimum inter-personal distance between people. Given this actual scenario, it is crucial to massively measure the compliance to such physical constraint in our life, in order to figure out the reasons of the possible breaks of such distance limitations, and understand if this implies a possible threat given the scene context. All of this, complying with privacy policies and making the measurement acceptable. To this end, we introduce the Visual Social Distancing (VSD) problem, defined as the automatic estimation of the inter-personal distance from an image, and the characterization of the related people aggregations. VSD is pivotal for a non-invasive analysis to whether people comply with the SD restriction, and to provide statistics about the level of safety of specific areas whenever this constraint is violated. We then discuss how VSD relates with previous literature in Social Signal Processing and indicate which existing Computer Vision methods can be used to manage such problem. We conclude with future challenges related to the effectiveness of VSD systems, ethical implications and future application scenarios.
HoughNet: neural network architecture for vanishing points detection
Oct 06, 2019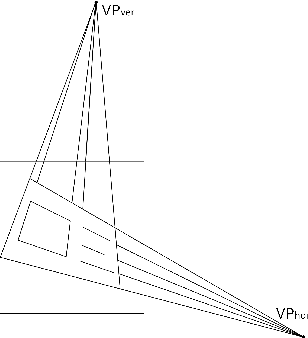



In this paper we introduce a novel neural network architecture based on Fast Hough Transform layer. The layer of this type allows our neural network to accumulate features from linear areas across the entire image instead of local areas. We demonstrate its potential by solving the problem of vanishing points detection in the images of documents. Such problem occurs when dealing with camera shots of the documents in uncontrolled conditions. In this case, the document image can suffer several specific distortions including projective transform. To train our model, we use MIDV-500 dataset and provide testing results. The strong generalization ability of the suggested method is proven with its applying to a completely different ICDAR 2011 dewarping contest. In previously published papers considering these dataset authors measured the quality of vanishing point detection by counting correctly recognized words with open OCR engine Tesseract. To compare with them, we reproduce this experiment and show that our method outperforms the state-of-the-art result.
* 6 pages, 6 figures, 2 tables, 28 references, conference
Measurement-driven Analysis of an Edge-Assisted Object Recognition System
Mar 07, 2020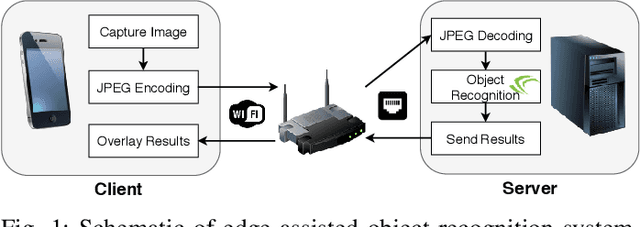
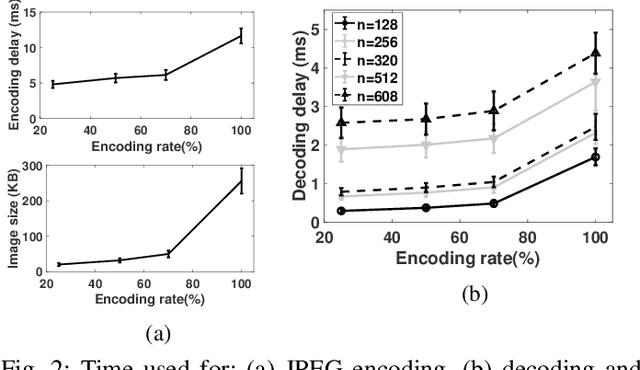
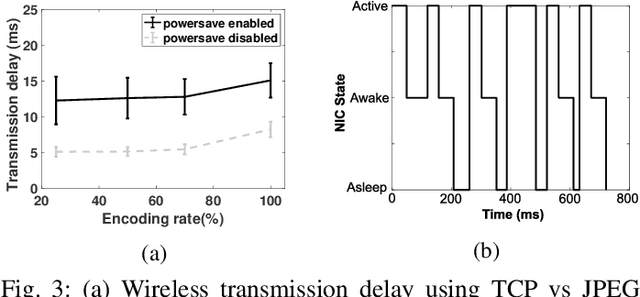
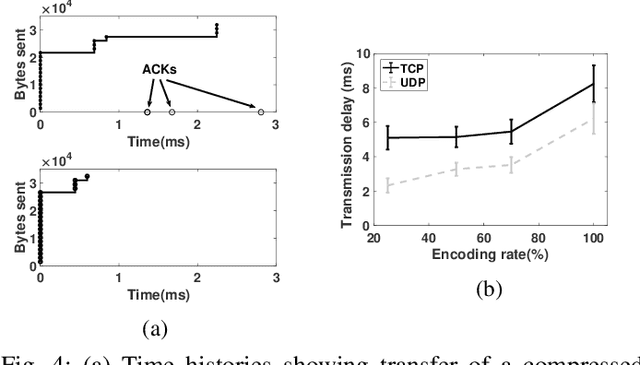
We develop an edge-assisted object recognition system with the aim of studying the system-level trade-offs between end-to-end latency and object recognition accuracy. We focus on developing techniques that optimize the transmission delay of the system and demonstrate the effect of image encoding rate and neural network size on these two performance metrics. We explore optimal trade-offs between these metrics by measuring the performance of our real time object recognition application. Our measurements reveal hitherto unknown parameter effects and sharp trade-offs, hence paving the road for optimizing this key service. Finally, we formulate two optimization problems using our measurement-based models and following a Pareto analysis we find that careful tuning of the system operation yields at least 33% better performance for real time conditions, over the standard transmission method.
Sequential Interpretability: Methods, Applications, and Future Direction for Understanding Deep Learning Models in the Context of Sequential Data
Apr 27, 2020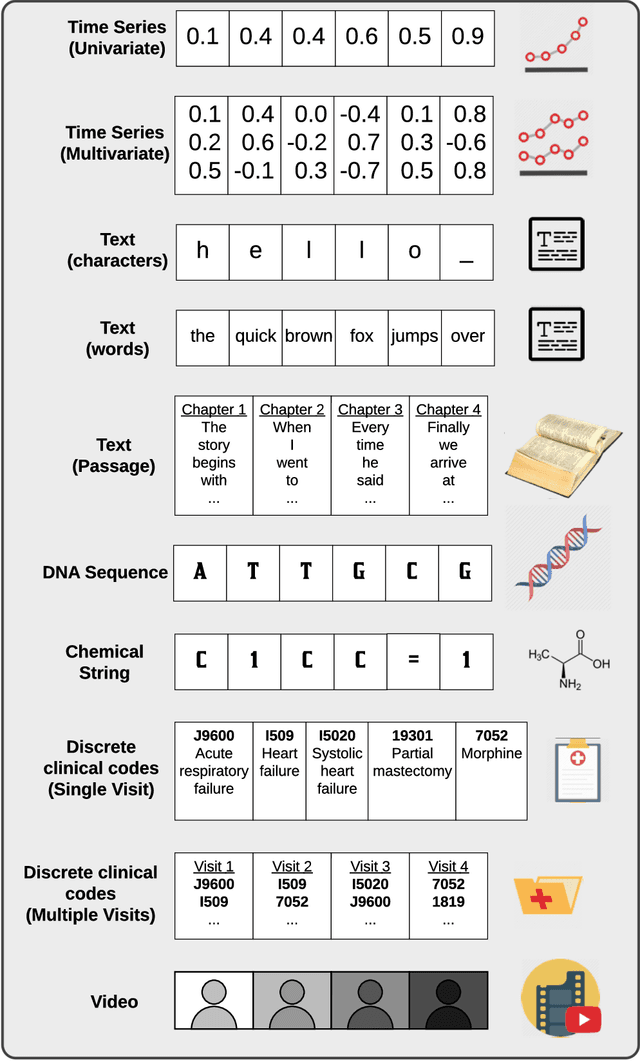
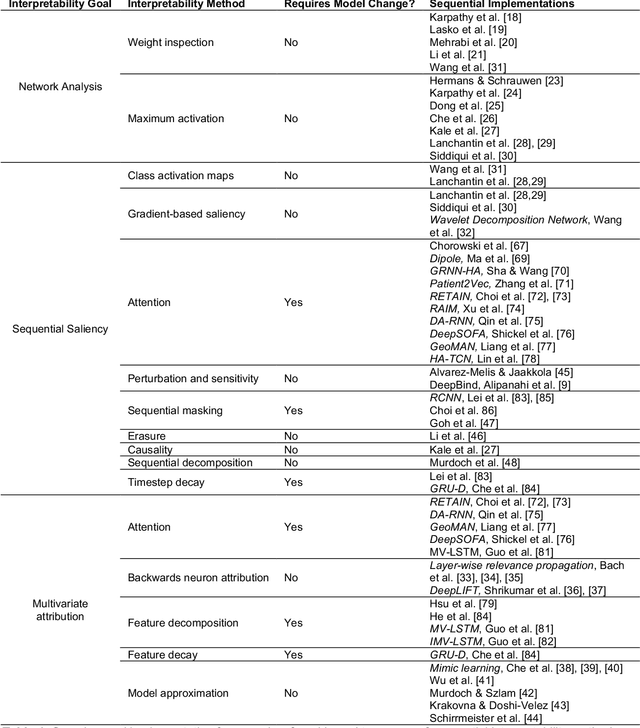
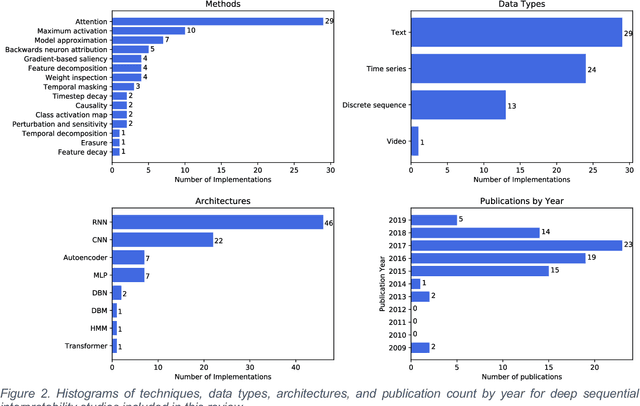
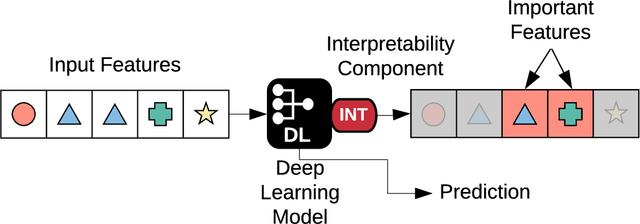
Deep learning continues to revolutionize an ever-growing number of critical application areas including healthcare, transportation, finance, and basic sciences. Despite their increased predictive power, model transparency and human explainability remain a significant challenge due to the "black box" nature of modern deep learning models. In many cases the desired balance between interpretability and performance is predominately task specific. Human-centric domains such as healthcare necessitate a renewed focus on understanding how and why these frameworks are arriving at critical and potentially life-or-death decisions. Given the quantity of research and empirical successes of deep learning for computer vision, most of the existing interpretability research has focused on image processing techniques. Comparatively, less attention has been paid to interpreting deep learning frameworks using sequential data. Given recent deep learning advancements in highly sequential domains such as natural language processing and physiological signal processing, the need for deep sequential explanations is at an all-time high. In this paper, we review current techniques for interpreting deep learning techniques involving sequential data, identify similarities to non-sequential methods, and discuss current limitations and future avenues of sequential interpretability research.