 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semi-Bagging Based Deep Neural Architecture to Extract Text from High Entropy Images
Jul 02, 2019
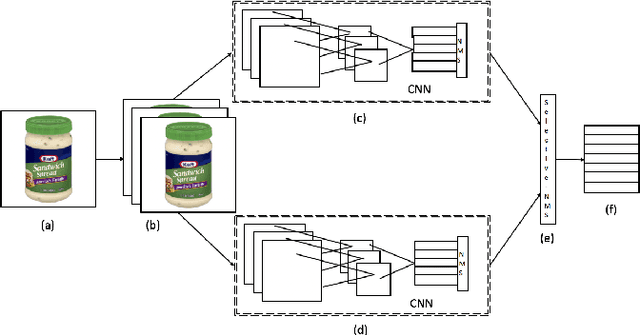
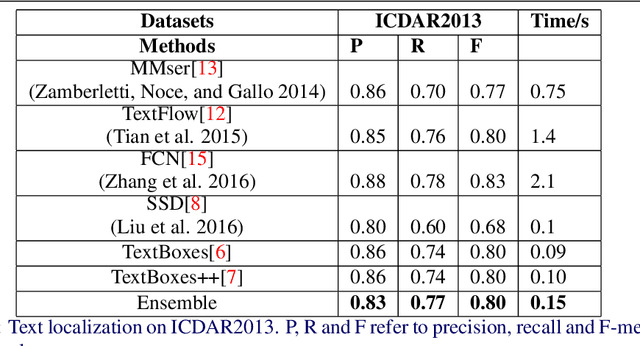

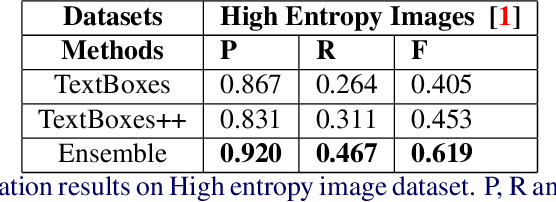
Extracting texts of various size and shape from images containing multiple objects is an important problem in many contexts, especially, in connection to e-commerce, augmented reality assistance system in natural scene, etc. The existing works (based on only CNN) often perform sub-optimally when the image contains regions of high entropy having multiple objects. This paper presents an end-to-end text detection strategy combining a segmentation algorithm and an ensemble of multiple text detectors of different types to detect text in every individual image segments independently. The proposed strategy involves a super-pixel based image segmenter which splits an image into multiple regions. A convolutional deep neural architecture is developed which works on each of the segments and detects texts of multiple shapes, sizes, and structures. It outperforms the competing methods in terms of coverage in detecting texts in images especially the ones where the text of various types and sizes are compacted in a small region along with various other objects. Furthermore, the proposed text detection method along with a text recognizer outperforms the existing state-of-the-art approaches in extracting text from high entropy images. We validate the results on a dataset consisting of product images on an e-commerce website.
Sketch-based Image Retrieval from Millions of Images under Rotation, Translation and Scale Variations
Oct 31, 2015
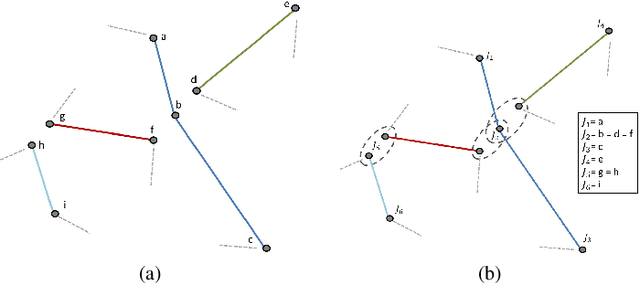
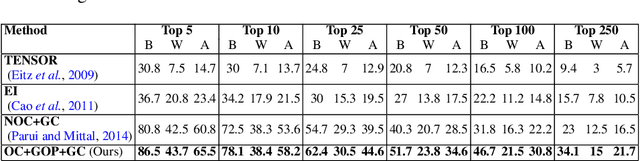
Proliferation of touch-based devices has made sketch-based image retrieval practical. While many methods exist for sketch-based object detection/image retrieval on small datasets, relatively less work has been done on large (web)-scale image retrieval. In this paper, we present an efficient approach for image retrieval from millions of images based on user-drawn sketches. Unlike existing methods for this problem which are sensitive to even translation or scale variations, our method handles rotation, translation, scale (i.e. a similarity transformation) and small deformations. The object boundaries are represented as chains of connected segments and the database images are pre-processed to obtain such chains that have a high chance of containing the object. This is accomplished using two approaches in this work: a) extracting long chains in contour segment networks and b) extracting boundaries of segmented object proposals. These chains are then represented by similarity-invariant variable length descriptors. Descriptor similarities are computed by a fast Dynamic Programming-based partial matching algorithm. This matching mechanism is used to generate a hierarchical k-medoids based indexing structure for the extracted chains of all database images in an offline process which is used to efficiently retrieve a small set of possible matched images for query chains. Finally, a geometric verification step is employed to test geometric consistency of multiple chain matches to improve results. Qualitative and quantitative results clearly demonstrate superiority of the approach over existing methods.
SID4VAM: A Benchmark Dataset with Synthetic Images for Visual Attention Modeling
Oct 29, 2019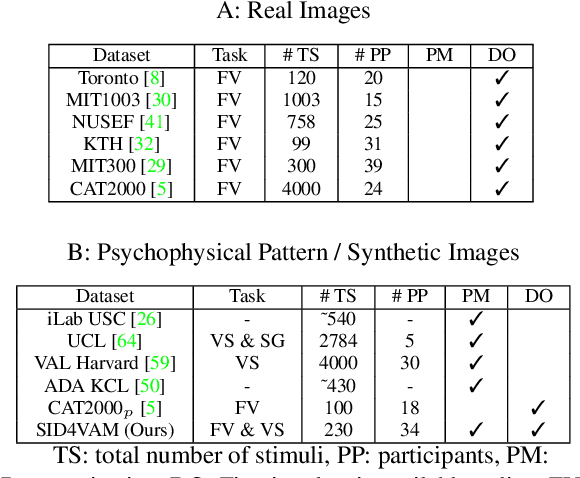
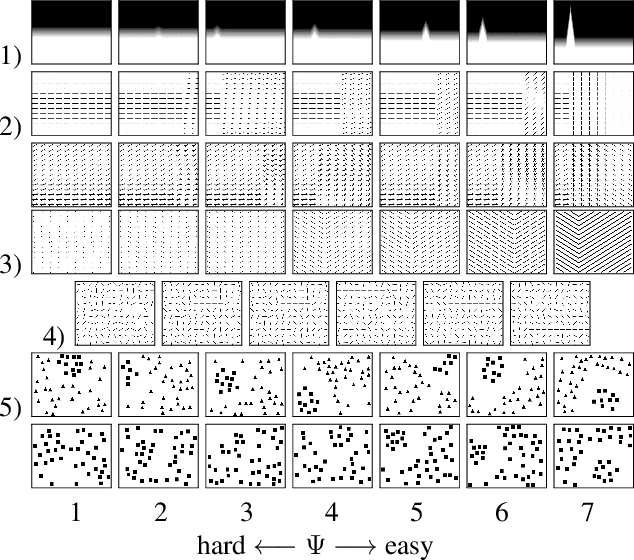
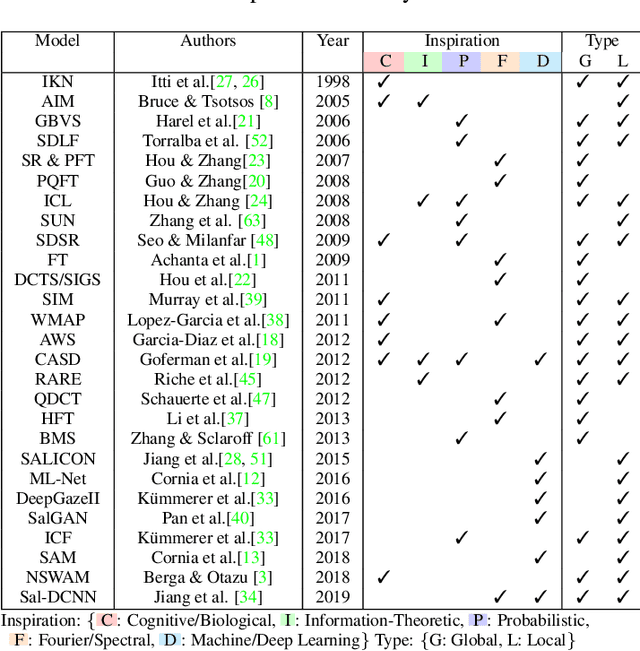
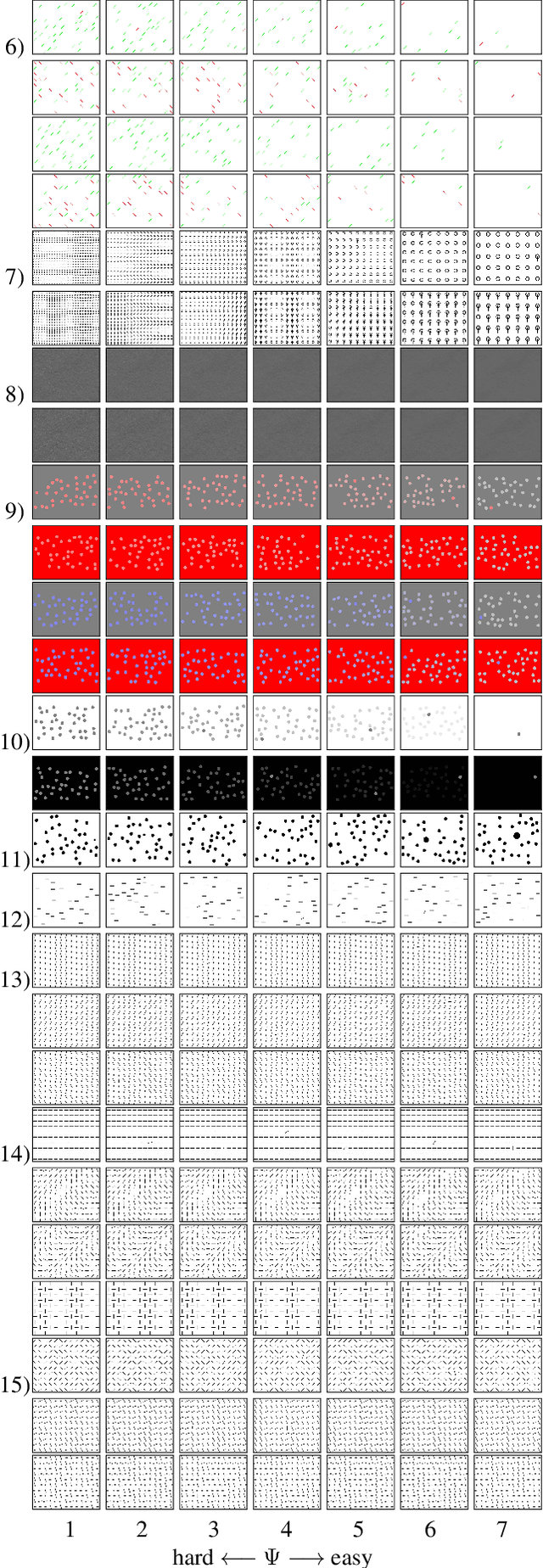
A benchmark of saliency models performance with a synthetic image dataset is provided. Model performance is evaluated through saliency metrics as well as the influence of model inspiration and consistency with human psychophysics. SID4VAM is composed of 230 synthetic images, with known salient regions. Images were generated with 15 distinct types of low-level features (e.g. orientation, brightness, color, size...) with a target-distractor pop-out type of synthetic patterns. We have used Free-Viewing and Visual Search task instructions and 7 feature contrasts for each feature category. Our study reveals that state-of-the-art Deep Learning saliency models do not perform well with synthetic pattern images, instead, models with Spectral/Fourier inspiration outperform others in saliency metrics and are more consistent with human psychophysical experimentation. This study proposes a new way to evaluate saliency models in the forthcoming literature, accounting for synthetic images with uniquely low-level feature contexts, distinct from previous eye tracking image datasets.
* 10 pages, 8 figures, 3 tables, conference paper (ICCV 2019), http://openaccess.thecvf.com/content_ICCV_2019/papers/Berga_SID4VAM_A_Benchmark_Dataset_With_Synthetic_Images_for_Visual_Attention_ICCV_2019_paper.pdf
Knowledge-Driven Learning via Experts Consult for Thyroid Nodule Classification
May 28, 2020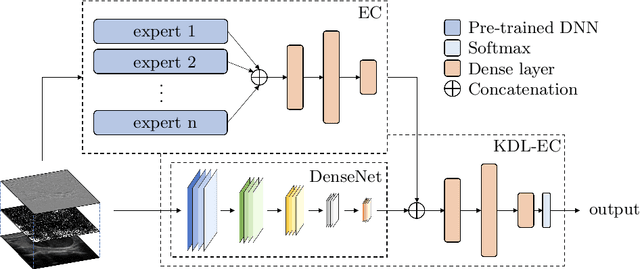
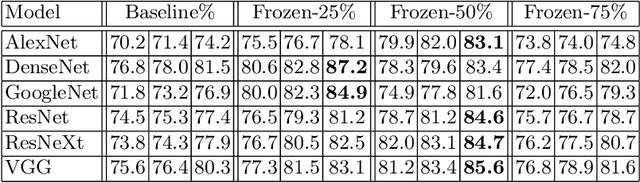

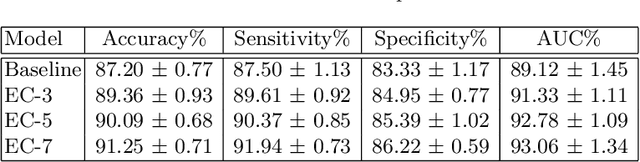
Computer-aided diagnosis (CAD) is becoming a prominent approach to assist clinicians spanning across multiple fields. These automated systems take advantage of various computer vision (CV) procedures, as well as artificial intelligence (AI) techniques, so that a diagnosis of a given image (e.g., computed tomography and ultrasound) can be formulated. Advances in both areas (CV and AI) are enabling ever increasing performances of CAD systems, which can ultimately avoid performing invasive procedures such as fine-needle aspiration. In this study, we focus on thyroid ultrasonography to present a novel knowledge-driven classification framework. The proposed system leverages cues provided by an ensemble of experts, in order to guide the learning phase of a densely connected convolutional network (DenseNet). The ensemble is composed by various networks pretrained on ImageNet, including AlexNet, ResNet, VGG, and others, so that previously computed feature parameters could be used to create ultrasonography domain experts via transfer learning, decreasing, moreover, the number of samples required for training. To validate the proposed method, extensive experiments were performed, providing detailed performances for both the experts ensemble and the knowledge-driven DenseNet. The obtained results, show how the the proposed system can become a great asset when formulating a diagnosis, by leveraging previous knowledge derived from a consult.
CA-RefineNet:A Dual Input WSI Image Segmentation Algorithm Based on Attention
Jul 15, 2019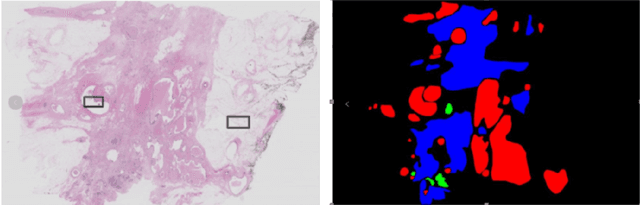
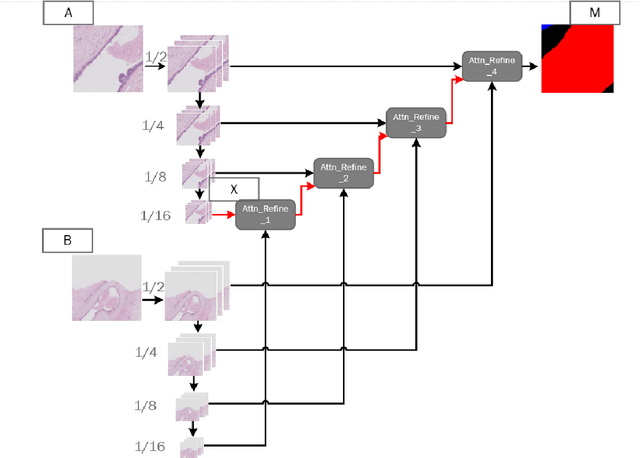
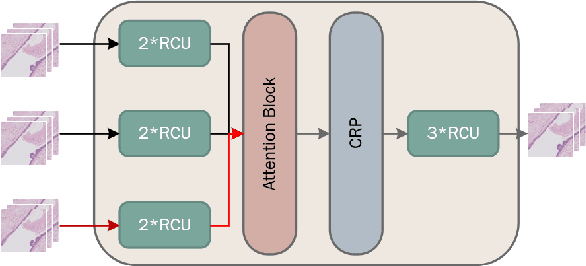
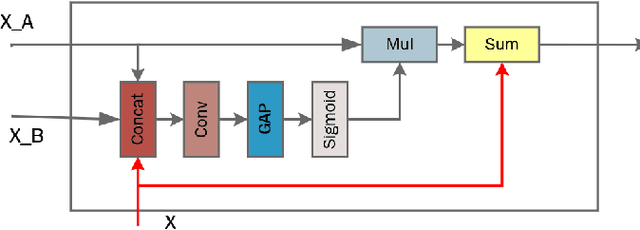
Due to the high resolution of pathological images, the automated semantic segmentation in the medical pathological images has shown greater challenges than that in natural images. Sliding Window method has shown its effect on solving problem caused by the high resolution of whole slide images (WSI). However, owing to its localization, Sliding Window method also suffers from being lack of global information. In this paper, a dual input semantic segmentation network based on attention is proposed, in which, one input provides small-scale fine information, the other input provides large-scale coarse information. Compared with single input methods, our method CA-RefineNet exhibits a dramatic performance improvement on ICIAR2018 breast cancer segmentation task.
Learning a No-Reference Quality Assessment Model of Enhanced Images With Big Data
Apr 18, 2019
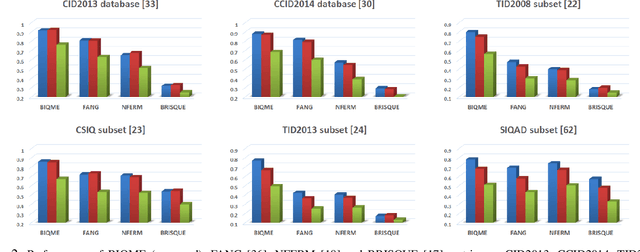
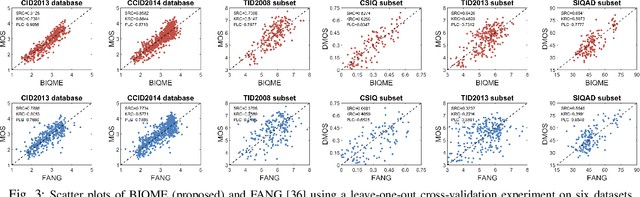
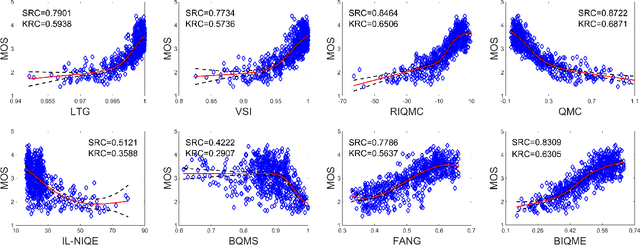
In this paper we investigate into the problem of image quality assessment (IQA) and enhancement via machine learning. This issue has long attracted a wide range of attention in computational intelligence and image processing communities, since, for many practical applications, e.g. object detection and recognition, raw images are usually needed to be appropriately enhanced to raise the visual quality (e.g. visibility and contrast). In fact, proper enhancement can noticeably improve the quality of input images, even better than originally captured images which are generally thought to be of the best quality. In this work, we present two most important contributions. The first contribution is to develop a new no-reference (NR) IQA model. Given an image, our quality measure first extracts 17 features through analysis of contrast, sharpness, brightness and more, and then yields a measre of visual quality using a regression module, which is learned with big-data training samples that are much bigger than the size of relevant image datasets. Results of experiments on nine datasets validate the superiority and efficiency of our blind metric compared with typical state-of-the-art full-, reduced- and no-reference IQA methods. The second contribution is that a robust image enhancement framework is established based on quality optimization. For an input image, by the guidance of the proposed NR-IQA measure, we conduct histogram modification to successively rectify image brightness and contrast to a proper level. Thorough tests demonstrate that our framework can well enhance natural images, low-contrast images, low-light images and dehazed images. The source code will be released at https://sites.google.com/site/guke198701/publications.
Hindi Visual Genome: A Dataset for Multimodal English-to-Hindi Machine Translation
Jul 21, 2019
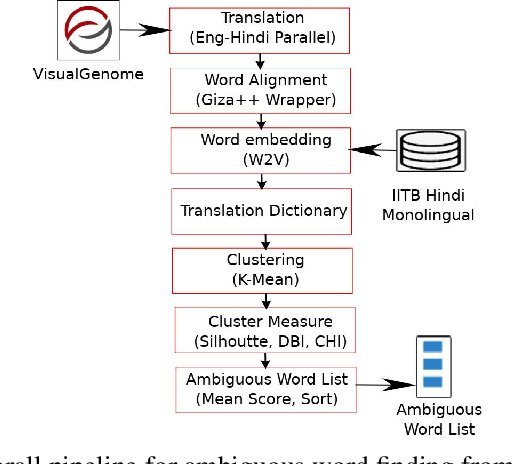
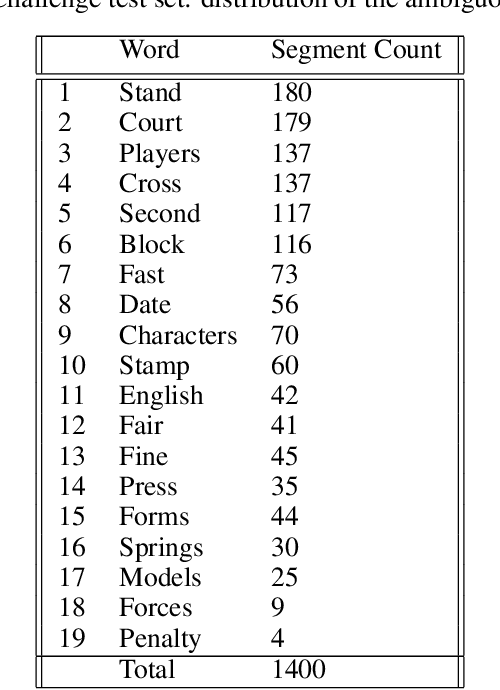

Visual Genome is a dataset connecting structured image information with English language. We present ``Hindi Visual Genome'', a multimodal dataset consisting of text and images suitable for English-Hindi multimodal machine translation task and multimodal research. We have selected short English segments (captions) from Visual Genome along with associated images and automatically translated them to Hindi with manual post-editing which took the associated images into account. We prepared a set of 31525 segments, accompanied by a challenge test set of 1400 segments. This challenge test set was created by searching for (particularly) ambiguous English words based on the embedding similarity and manually selecting those where the image helps to resolve the ambiguity. Our dataset is the first for multimodal English-Hindi machine translation, freely available for non-commercial research purposes. Our Hindi version of Visual Genome also allows to create Hindi image labelers or other practical tools. Hindi Visual Genome also serves in Workshop on Asian Translation (WAT) 2019 Multi-Modal Translation Task.
FNA++: Fast Network Adaptation via Parameter Remapping and Architecture Search
Jun 21, 2020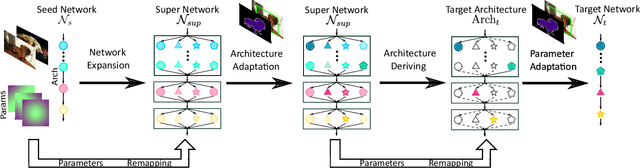
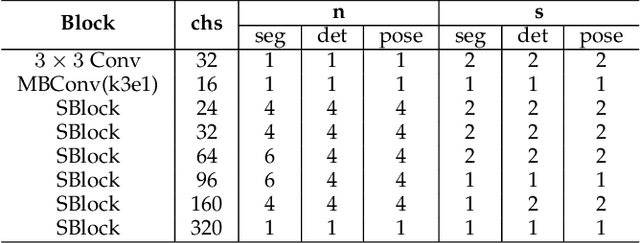
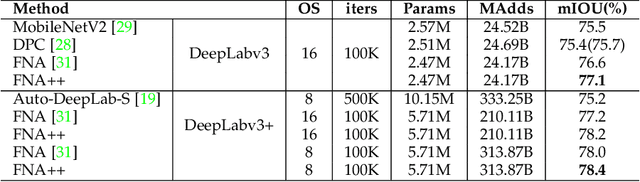
Deep neural networks achieve remarkable performance in many computer vision tasks. Most state-of-the-art (SOTA) semantic segmentation and object detection approaches reuse neural network architectures designed for image classification as the backbone, commonly pre-trained on ImageNet. However, performance gains can be achieved by designing network architectures specifically for detection and segmentation, as shown by recent neural architecture search (NAS) research for detection and segmentation. One major challenge though is that ImageNet pre-training of the search space representation (a.k.a. super network) or the searched networks incurs huge computational cost. In this paper, we propose a Fast Network Adaptation (FNA++) method, which can adapt both the architecture and parameters of a seed network (e.g. an ImageNet pre-trained network) to become a network with different depths, widths, or kernel sizes via a parameter remapping technique, making it possible to use NAS for segmentation/detection tasks a lot more efficiently. In our experiments, we conduct FNA++ on MobileNetV2 to obtain new networks for semantic segmentation, object detection, and human pose estimation that clearly outperform existing networks designed both manually and by NAS. We also implement FNA++ on ResNets and NAS networks, which demonstrates a great generalization ability. The total computation cost of FNA++ is significantly less than SOTA segmentation/detection NAS approaches: 1737x less than DPC, 6.8x less than Auto-DeepLab, and 8.0x less than DetNAS. The code will be released at https://github.com/JaminFong/FNA.
Long Range 3D with Quadocular Thermal (LWIR) Camera
Nov 16, 2019
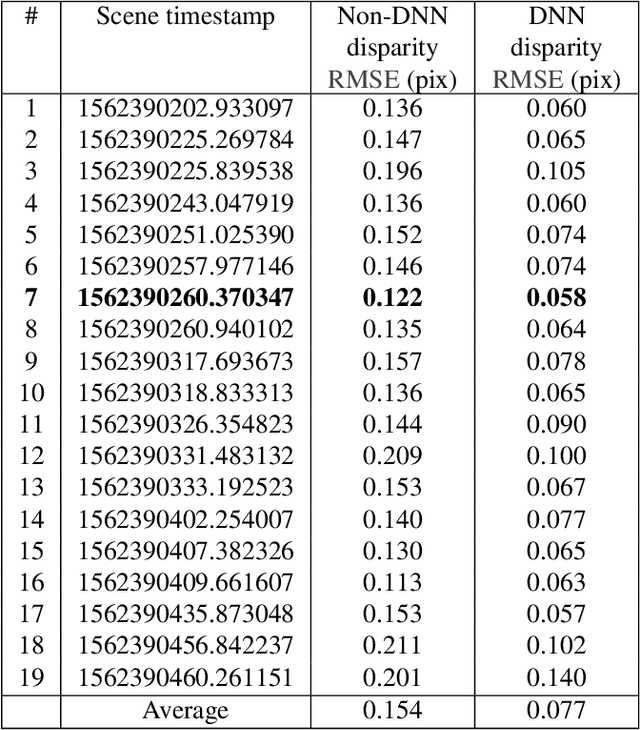


Long Wave Infrared (LWIR) cameras provide images regardles of the ambient illumination, they tolerate fog and are not blinded by the incoming car headlights. These features make LWIR cameras attractive for autonomous navigation, security and military applications. Thermal images can be used similarly to the visible range ones, including 3D scene reconstruction with two or more such cameras mounted on a rigid frame. There are two additional challenges for this spectral range: lower image resolution and lower contrast of the textures. In this work, we demonstrate quadocular LWIR camera setup, calibration, image capturing and processing that result in long range 3D perception with 0.077 pix disparity error over 90% of the depth map. With low resolution (160 x 120) LWIR sensors we achieved 10% range accuracy at 28 m with 56 degrees horizontal field of view (HFoV) and 150 mm baseline. Scaled to the now-standard 640 x 512 resolution and 200 mm baseline suitable for head-mounted application the result would be 10% accuracy at 130 m.
When Differential Privacy Meets Graph Neural Networks
Jun 09, 2020
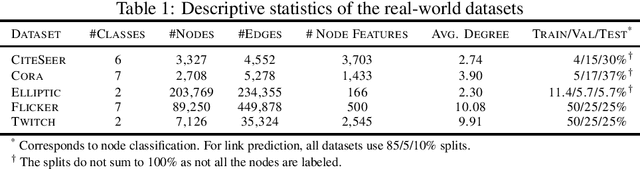
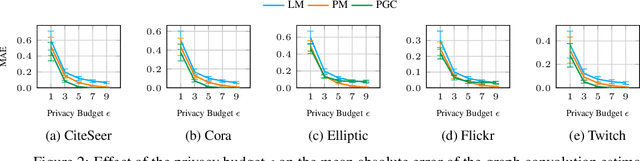
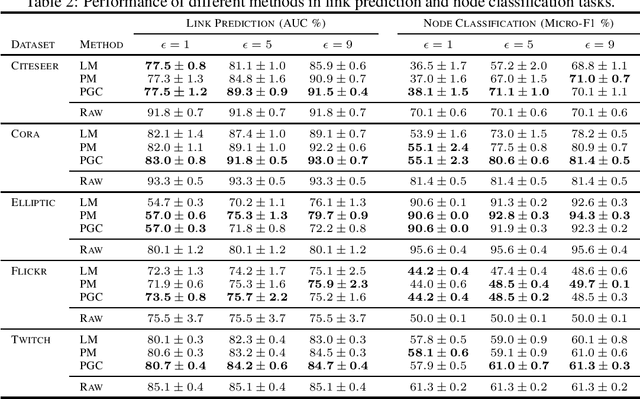
Graph Neural Networks have demonstrated superior performance in learning graph representations for several subsequent downstream inference tasks. However, learning over graph data types can raise privacy concerns when nodes represent people or human-related variables that involve personal information about individuals. Previous works have presented various techniques for privacy-preserving deep learning over non-relational data, such as image, audio, video, and text, but there is less work addressing the privacy issues involved in applying deep learning algorithms on graphs. As a result and for the first time, in this paper, we develop a privacy-preserving learning algorithm with formal privacy guarantees for Graph Convolutional Networks (GCNs) based on Local Differential Privacy (LDP) to tackle the problem of node-level privacy, where graph nodes have potentially sensitive features that need to be kept private, but they could be beneficial for learning rich node representations in a centralized learning setting. Specifically, we propose an LDP algorithm in which a central server can communicate with graph nodes to privately collect their data and estimate the graph convolution layer of a GCN. We then analyze the theoretical characteristics of the method and compare it with state-of-the-art mechanisms. Experimental results over real-world graph datasets demonstrate the effectiveness of the proposed method for both privacy-preserving node classification and link prediction tasks and verify our theoretical findings.