 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Range 3D with Quadocular Thermal Camera
Nov 20, 2019
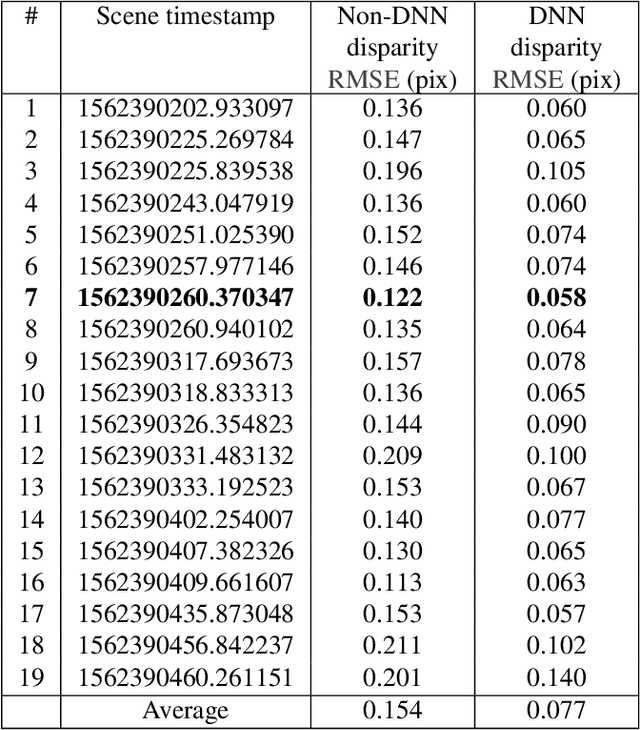


Long Wave Infrared (LWIR) cameras provide images regardles of the ambient illumination, they tolerate fog and are not blinded by the incoming car headlights. These features make LWIR cameras attractive for autonomous navigation, security and military applications. Thermal images can be used similarly to the visible range ones, including 3D scene reconstruction with two or more such cameras mounted on a rigid frame. There are two additional challenges for this spectral range: lower image resolution and lower contrast of the textures. In this work, we demonstrate quadocular LWIR camera setup, calibration, image capturing and processing that result in long range 3D perception with 0.077 pix disparity error over 90% of the depth map. With low resolution (160 x 120) LWIR sensors we achieved 10% range accuracy at 28 m with 56 degrees horizontal field of view (HFoV) and 150 mm baseline. Scaled to the now-standard 640 x 512 resolution and 200 mm baseline suitable for head-mounted application the result would be 10% accuracy at 130 m.
See far with TPNET: a Tile Processor and a CNN Symbiosis
Nov 20, 2018
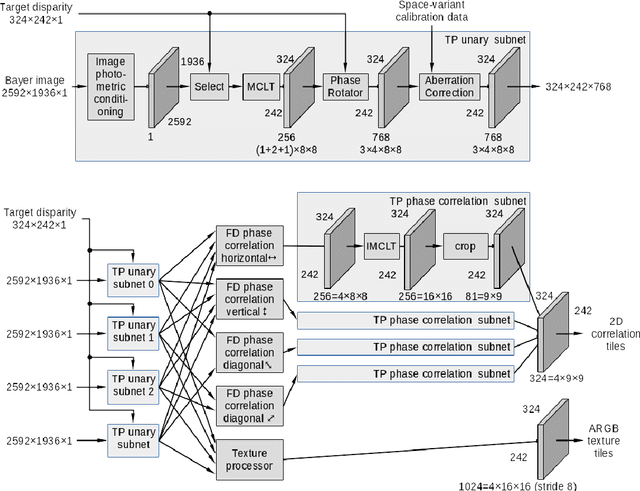
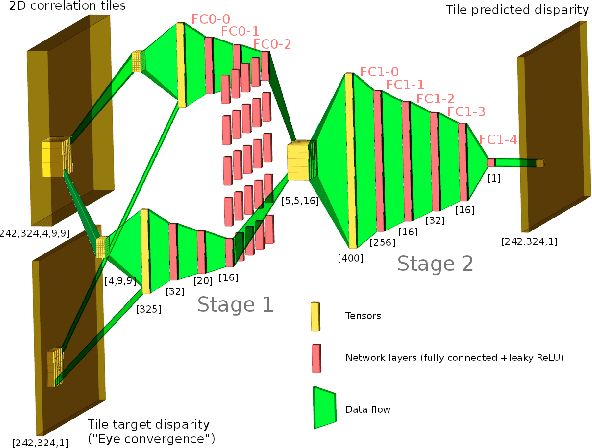
Throughout the evolution of the neural networks more specialized cells were added to the set of basic building blocks. These cells aim to improve training convergence, increase the overall performance, and reduce the number of required labels, all while preserving the expressive power of the universal network. Inspired by the partitioning of the human visual perception system between the eyes and the cerebral cortex, we present TPNET, which offloads universal and application-specific CNN from the bulk processing of the high resolution pixel data and performs the translation-variant image correction while delegating all non-linear decision making to the network. In this work, we explore application of TPNET to 3D perception with a narrow-baseline (0.0001-0.0025) quad stereo camera and prove that a trained network provides a disparity prediction from the 2D phase correlation output by the Tile Processor (TP) that is twice as accurate as the prediction from a carefully hand-crafted algorithm. The TP in turn reduces the dimensions of the input features of the network and provides instrument-invariant and translation-invariant data, making real-time high resolution stereo 3D perception feasible and easing the requirement to have a complete end-to-end network.