 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Y-Net for Chest X-Ray Preprocessing: Simultaneous Classification of Geometry and Segmentation of Annotations
May 08, 2020
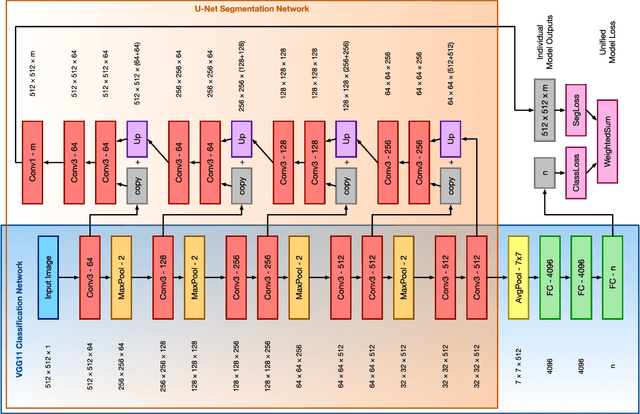
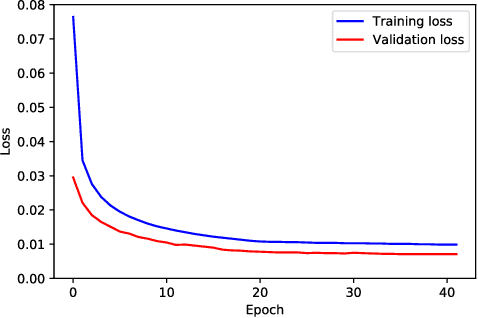
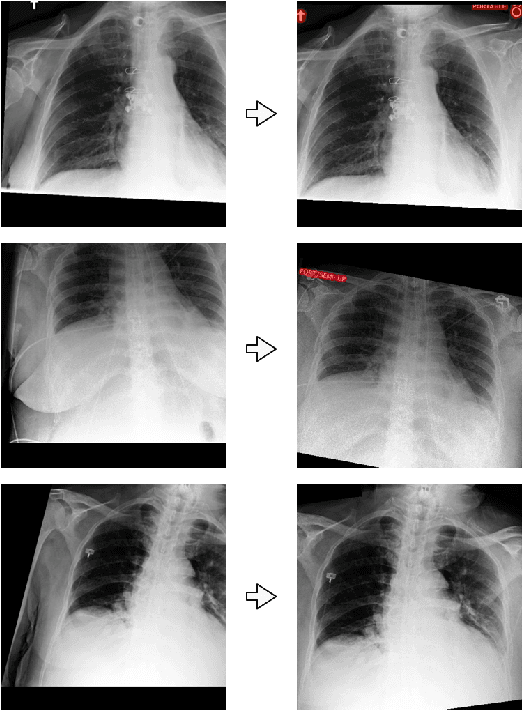
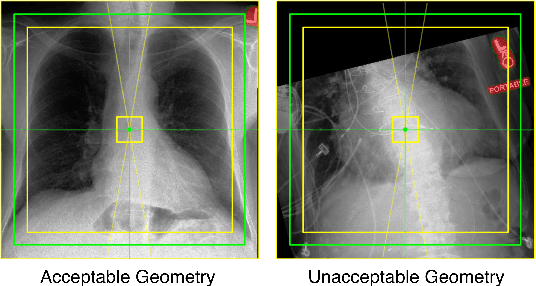
Over the last decade, convolutional neural networks (CNNs) have emerged as the leading algorithms in image classification and segmentation. Recent publication of large medical imaging databases have accelerated their use in the biomedical arena. While training data for photograph classification benefits from aggressive geometric augmentation, medical diagnosis -- especially in chest radiographs -- depends more strongly on feature location. Diagnosis classification results may be artificially enhanced by reliance on radiographic annotations. This work introduces a general pre-processing step for chest x-ray input into machine learning algorithms. A modified Y-Net architecture based on the VGG11 encoder is used to simultaneously learn geometric orientation (similarity transform parameters) of the chest and segmentation of radiographic annotations. Chest x-rays were obtained from published databases. The algorithm was trained with 1000 manually labeled images with augmentation. Results were evaluated by expert clinicians, with acceptable geometry in 95.8% and annotation mask in 96.2% (n=500), compared to 27.0% and 34.9% respectively in control images (n=241). We hypothesize that this pre-processing step will improve robustness in future diagnostic algorithms.
UC-Net: Uncertainty Inspired RGB-D Saliency Detection via Conditional Variational Autoencoders
Apr 13, 2020
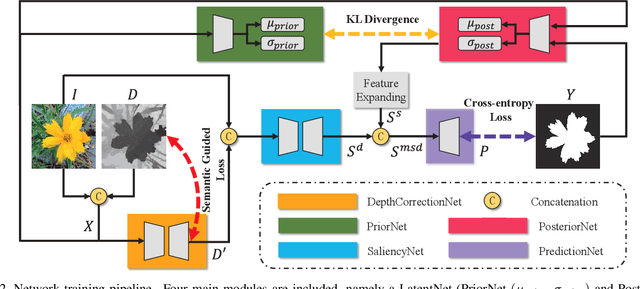
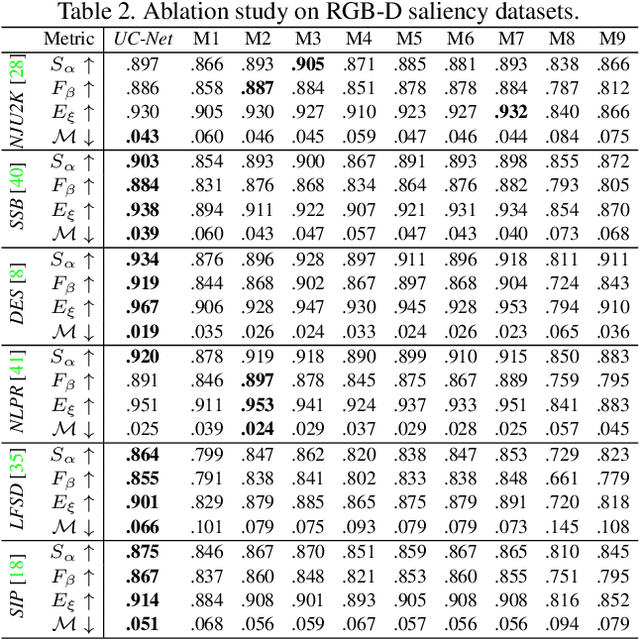
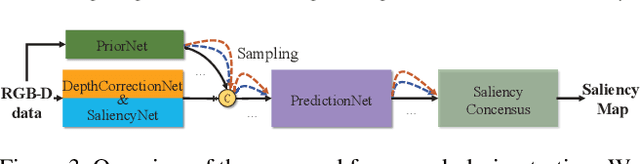
In this paper, we propose the first framework (UCNet) to employ uncertainty for RGB-D saliency detection by learning from the data labeling process. Existing RGB-D saliency detection methods treat the saliency detection task as a point estimation problem, and produce a single saliency map following a deterministic learning pipeline. Inspired by the saliency data labeling process, we propose probabilistic RGB-D saliency detection network via conditional variational autoencoders to model human annotation uncertainty and generate multiple saliency maps for each input image by sampling in the latent space. With the proposed saliency consensus process, we are able to generate an accurate saliency map based on these multiple predictions. Quantitative and qualitative evaluations on six challenging benchmark datasets against 18 competing algorithms demonstrate the effectiveness of our approach in learning the distribution of saliency maps, leading to a new state-of-the-art in RGB-D saliency detection.
Risk of Training Diagnostic Algorithms on Data with Demographic Bias
Jun 17, 2020
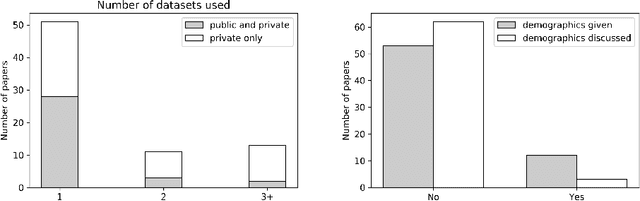
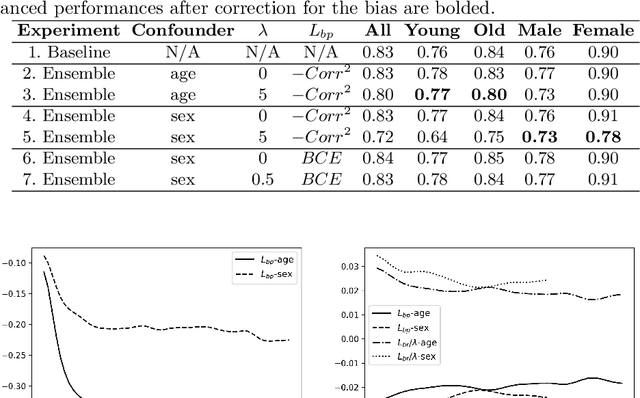
One of the critical challenges in machine learning applications is to have fair predictions. There are numerous recent examples in various domains that convincingly show that algorithms trained with biased datasets can easily lead to erroneous or discriminatory conclusions. This is even more crucial in clinical applications where the predictive algorithms are designed mainly based on a limited or given set of medical images and demographic variables such as age, sex and race are not taken into account. In this work, we conduct a survey of the MICCAI 2018 proceedings to investigate the common practice in medical image analysis applications. Surprisingly, we found that papers focusing on diagnosis rarely describe the demographics of the datasets used, and the diagnosis is purely based on images. In order to highlight the importance of considering the demographics in diagnosis tasks, we used a publicly available dataset of skin lesions. We then demonstrate that a classifier with an overall area under the curve (AUC) of 0.83 has variable performance between 0.76 and 0.91 on subgroups based on age and sex, even though the training set was relatively balanced. Moreover, we show that it is possible to learn unbiased features by explicitly using demographic variables in an adversarial training setup, which leads to balanced scores per subgroups. Finally, we discuss the implications of these results and provide recommendations for further research.
Unsupervised Domain Adaptation in the Dissimilarity Space for Person Re-identification
Jul 27, 2020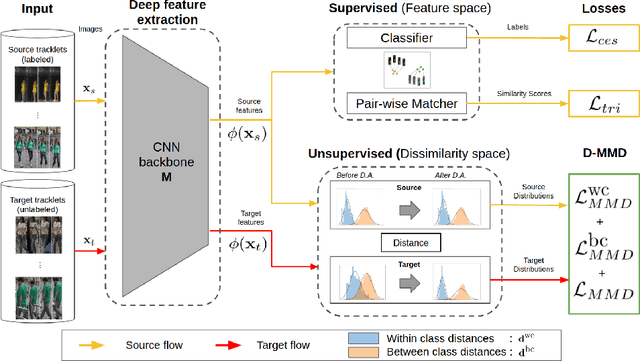
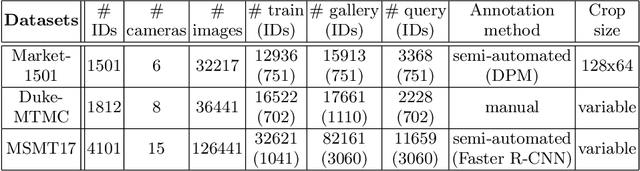
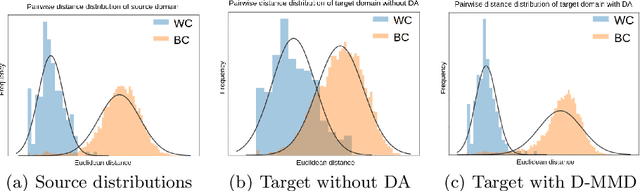
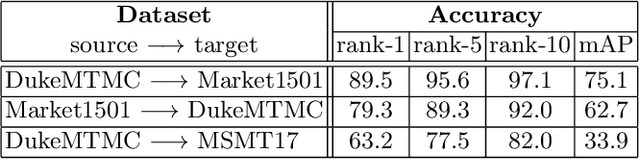
Person re-identification (ReID) remains a challenging task in many real-word video analytics and surveillance applications, even though state-of-the-art accuracy has improved considerably with the advent of deep learning (DL) models trained on large image datasets. Given the shift in distributions that typically occurs between video data captured from the source and target domains, and absence of labeled data from the target domain, it is difficult to adapt a DL model for accurate recognition of target data. We argue that for pair-wise matchers that rely on metric learning, e.g., Siamese networks for person ReID, the unsupervised domain adaptation (UDA) objective should consist in aligning pair-wise dissimilarity between domains, rather than aligning feature representations. Moreover, dissimilarity representations are more suitable for designing open-set ReID systems, where identities differ in the source and target domains. In this paper, we propose a novel Dissimilarity-based Maximum Mean Discrepancy (D-MMD) loss for aligning pair-wise distances that can be optimized via gradient descent. From a person ReID perspective, the evaluation of D-MMD loss is straightforward since the tracklet information allows to label a distance vector as being either within-class or between-class. This allows approximating the underlying distribution of target pair-wise distances for D-MMD loss optimization, and accordingly align source and target distance distributions. Empirical results with three challenging benchmark datasets show that the proposed D-MMD loss decreases as source and domain distributions become more similar. Extensive experimental evaluation also indicates that UDA methods that rely on the D-MMD loss can significantly outperform baseline and state-of-the-art UDA methods for person ReID without the common requirement for data augmentation and/or complex networks.
A Deep learning Approach to Generate Contrast-Enhanced Computerised Tomography Angiography without the Use of Intravenous Contrast Agents
Mar 02, 2020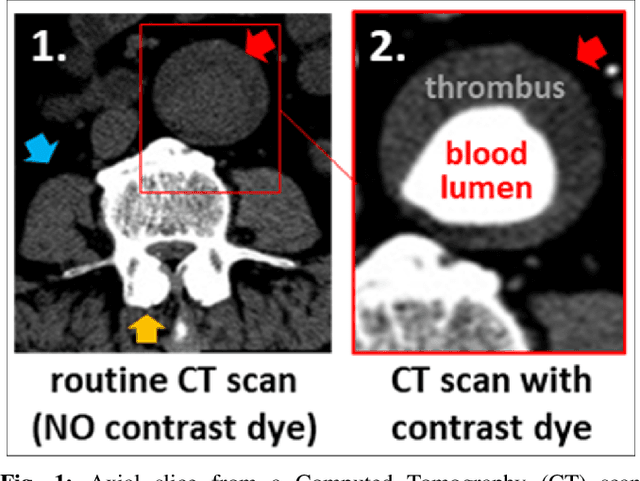
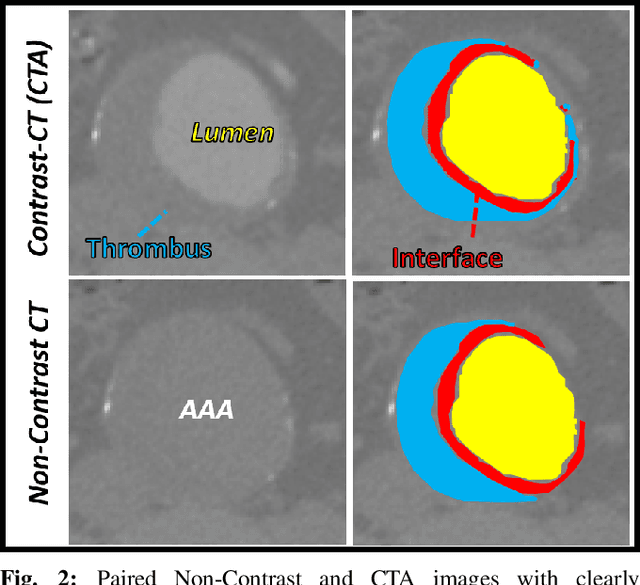
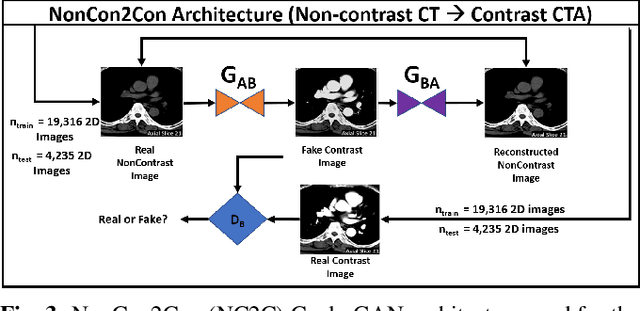
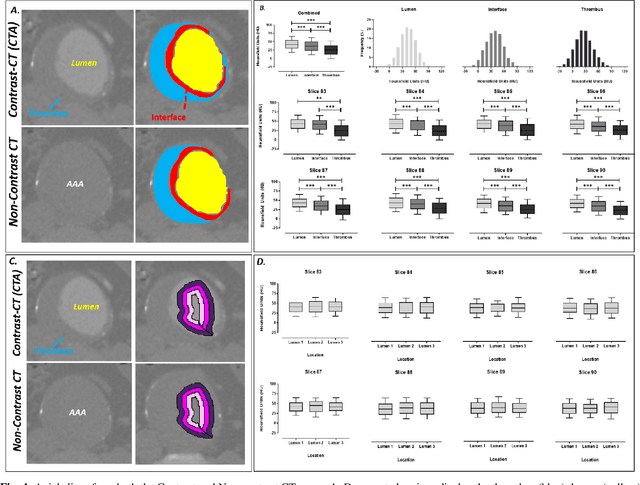
Contrast-enhanced computed tomography angiograms (CTAs) are widely used in cardiovascular imaging to obtain a non-invasive view of arterial structures. However, contrast agents are associated with complications at the injection site as well as renal toxicity leading to contrast-induced nephropathy (CIN) and renal failure. We hypothesised that the raw data acquired from a non-contrast CT contains sufficient information to differentiate blood and other soft tissue components. We utilised deep learning methods to define the subtleties between soft tissue components in order to simulate contrast enhanced CTAs without contrast agents. Twenty-six patients with paired non-contrast and CTA images were randomly selected from an approved clinical study. Non-contrast axial slices within the AAA from 10 patients (n = 100) were sampled for the underlying Hounsfield unit (HU) distribution at the lumen, intra-luminal thrombus and interface locations. Sampling of HUs in these regions revealed significant differences between all regions (p<0.001 for all comparisons), confirming the intrinsic differences in the radiomic signatures between these regions. To generate a large training dataset, paired axial slices from the training set (n=13) were augmented to produce a total of 23,551 2-D images. We trained a 2-D Cycle Generative Adversarial Network (cycleGAN) for this non-contrast to contrast (NC2C) transformation task. The accuracy of the cycleGAN output was assessed by comparison to the contrast image. This pipeline is able to differentiate between visually incoherent soft tissue regions in non-contrast CT images. The CTAs generated from the non-contrast images bear strong resemblance to the ground truth. Here we describe a novel application of Generative Adversarial Network for CT image processing. This is poised to disrupt clinical pathways requiring contrast enhanced CT imaging.
Breast Ultrasound Computer-Aided Diagnosis Using Structure-Aware Triplet Path Networks
Aug 09, 2019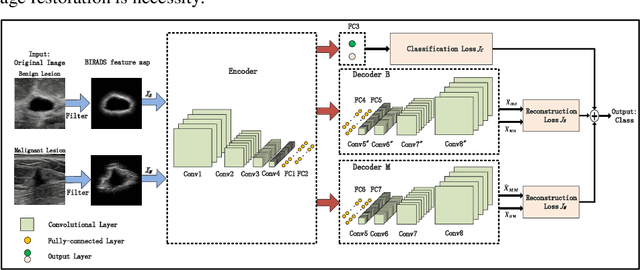
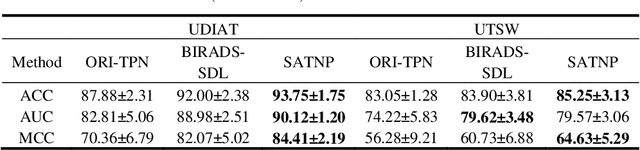
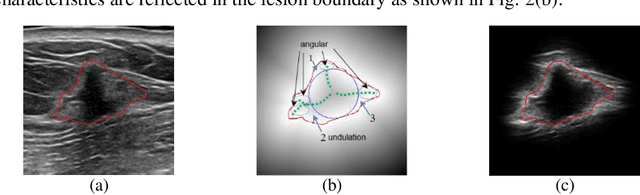
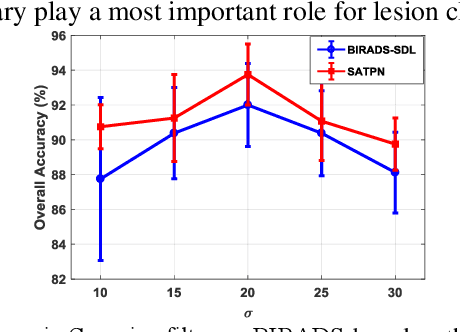
Breast ultrasound (US) is an effective imaging modality for breast cancer detec-tion and diagnosis. The structural characteristics of breast lesion play an im-portant role in Computer-Aided Diagnosis (CAD). In this paper, a novel struc-ture-aware triplet path networks (SATPN) was designed to integrate classifica-tion and two image reconstruction tasks to achieve accurate diagnosis on US im-ages with small training dataset. Specifically, we enhance clinically-approved breast lesion structure characteristics though converting original breast US imag-es to BIRADS-oriented feature maps (BFMs) with a distance-transformation coupled Gaussian filter. Then, the converted BFMs were used as the inputs of SATPN, which performed lesion classification task and two unsupervised stacked convolutional Auto-Encoder (SCAE) networks for benign and malignant image reconstruction tasks, independently. We trained the SATPN with an alter-native learning strategy by balancing image reconstruction error and classification label prediction error. At the test stage, the lesion label was determined by the weighted voting with reconstruction error and label prediction error. We com-pared the performance of the SATPN with TPN using original image as input and our previous developed semi-supervised deep learning methods using BFMs as inputs. Experimental results on two breast US datasets showed that SATPN ranked the best among the three networks, with classification accuracy around 93.5%. These findings indicated that SATPN is promising for effective breast US lesion CAD using small datasets.
DeepFuse: An IMU-Aware Network for Real-Time 3D Human Pose Estimation from Multi-View Image
Dec 09, 2019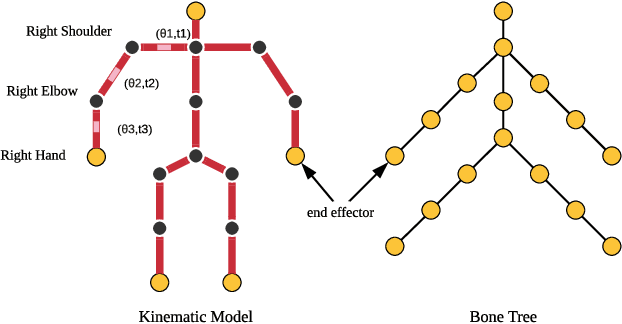

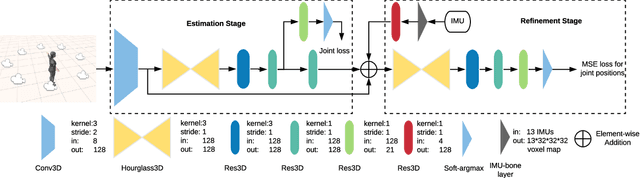
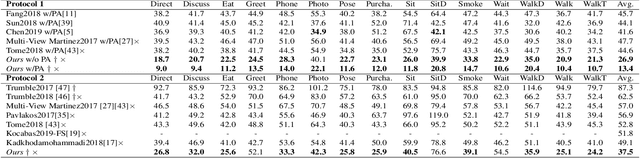
In this paper, we propose a two-stage fully 3D network, namely \textbf{DeepFuse}, to estimate human pose in 3D space by fusing body-worn Inertial Measurement Unit (IMU) data and multi-view images deeply. The first stage is designed for pure vision estimation. To preserve data primitiveness of multi-view inputs, the vision stage uses multi-channel volume as data representation and 3D soft-argmax as activation layer. The second one is the IMU refinement stage which introduces an IMU-bone layer to fuse the IMU and vision data earlier at data level. without requiring a given skeleton model a priori, we can achieve a mean joint error of $28.9$mm on TotalCapture dataset and $13.4$mm on Human3.6M dataset under protocol 1, improving the SOTA result by a large margin. Finally, we discuss the effectiveness of a fully 3D network for 3D pose estimation experimentally which may benefit future research.
Polarimetric Hierarchical Semantic Model and Scattering Mechanism Based PolSAR Image Classification
Jul 01, 2015

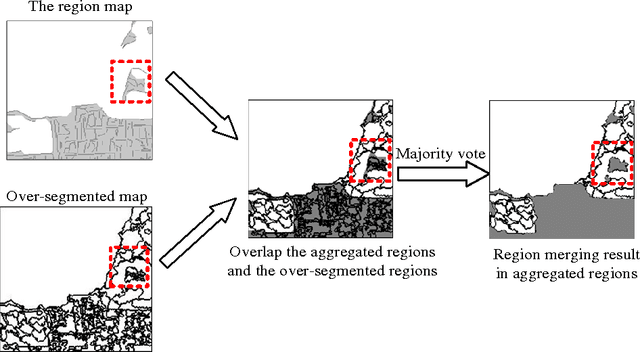
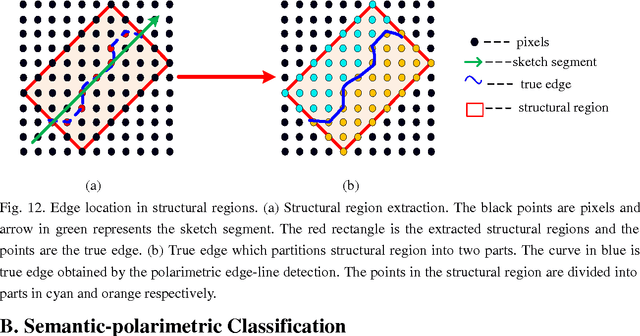
For polarimetric SAR (PolSAR) image classification, it is a challenge to classify the aggregated terrain types, such as the urban area, into semantic homogenous regions due to sharp bright-dark variations in intensity. The aggregated terrain type is formulated by the similar ground objects aggregated together. In this paper, a polarimetric hierarchical semantic model (PHSM) is firstly proposed to overcome this disadvantage based on the constructions of a primal-level and a middle-level semantic. The primal-level semantic is a polarimetric sketch map which consists of sketch segments as the sparse representation of a PolSAR image. The middle-level semantic is a region map which can extract semantic homogenous regions from the sketch map by exploiting the topological structure of sketch segments. Mapping the region map to the PolSAR image, a complex PolSAR scene is partitioned into aggregated, structural and homogenous pixel-level subspaces with the characteristics of relatively coherent terrain types in each subspace. Then, according to the characteristics of three subspaces above, three specific methods are adopted, and furthermore polarimetric information is exploited to improve the segmentation result. Experimental results on PolSAR data sets with different bands and sensors demonstrate that the proposed method is superior to the state-of-the-art methods in region homogeneity and edge preservation for terrain classification.
Stable image reconstruction using total variation minimization
Mar 12, 2013
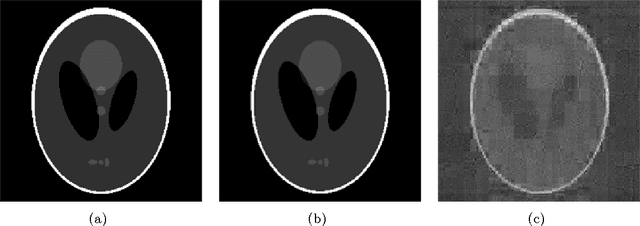


This article presents near-optimal guarantees for accurate and robust image recovery from under-sampled noisy measurements using total variation minimization. In particular, we show that from O(slog(N)) nonadaptive linear measurements, an image can be reconstructed to within the best s-term approximation of its gradient up to a logarithmic factor, and this factor can be removed by taking slightly more measurements. Along the way, we prove a strengthened Sobolev inequality for functions lying in the null space of suitably incoherent matrices.
The Six Fronts of the Generative Adversarial Networks
Oct 29, 2019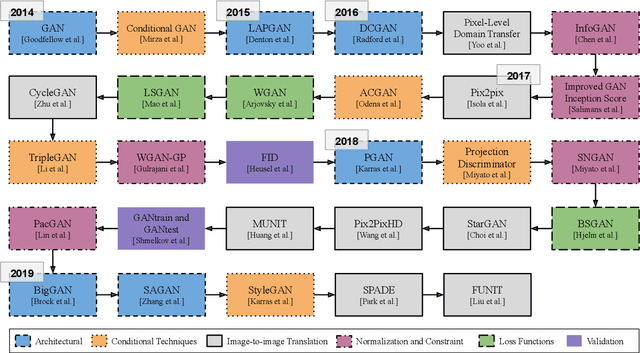
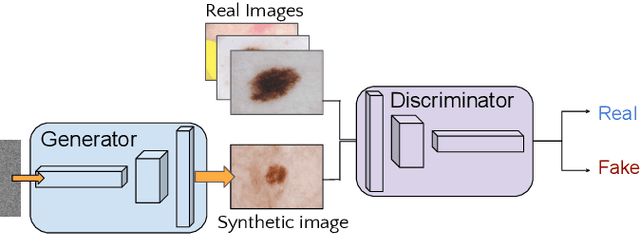
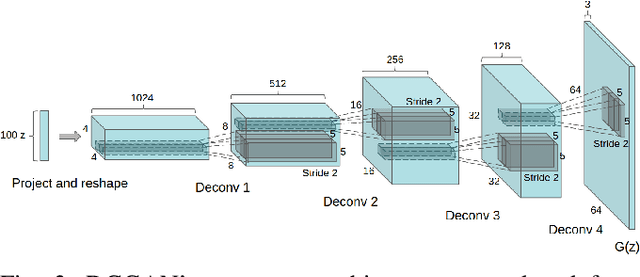
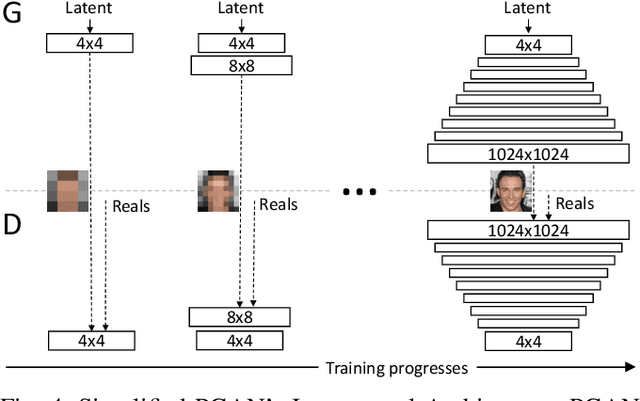
Generative Adversarial Networks fostered a newfound interest in generative models, resulting in a swelling wave of new works that new-coming researchers may find formidable to surf. In this paper, we intend to help those researchers, by splitting that incoming wave into six "fronts": Architectural Contributions, Conditional Techniques, Normalization and Constraint Contributions, Loss Functions, Image-to-image Translations, and Validation Metrics. The division in fronts organizes literature into approachable blocks, ultimately communicating to the reader how the area is evolving. Previous surveys in the area, which this works also tabulates, focus on a few of those fronts, leaving a gap that we propose to fill with a more integrated, comprehensive overview. Here, instead of an exhaustive survey, we opt for a straightforward review: our target is to be an entry point to this vast literature, and also to be able to update experienced researchers to the newest techniques.