 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sparsely Grouped Input Variables for Neural Networks
Nov 29, 2019


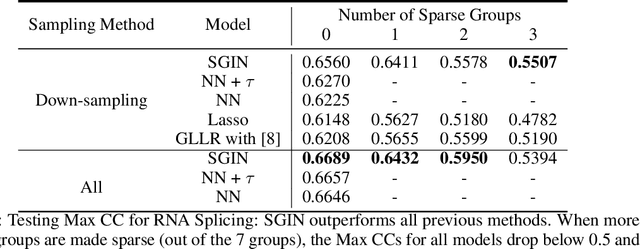
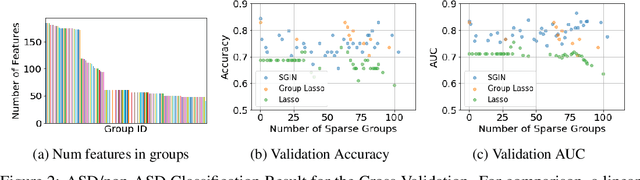
In genomic analysis, biomarker discovery, image recognition, and other systems involving machine learning, input variables can often be organized into different groups by their source or semantic category. Eliminating some groups of variables can expedite the process of data acquisition and avoid over-fitting. Researchers have used the group lasso to ensure group sparsity in linear models and have extended it to create compact neural networks in meta-learning. Different from previous studies, we use multi-layer non-linear neural networks to find sparse groups for input variables. We propose a new loss function to regularize parameters for grouped input variables, design a new optimization algorithm for this loss function, and test these methods in three real-world settings. We achieve group sparsity for three datasets, maintaining satisfying results while excluding one nucleotide position from an RNA splicing experiment, excluding 89.9% of stimuli from an eye-tracking experiment, and excluding 60% of image rows from an experiment on the MNIST dataset.
A Preliminary Study for Identification of Additive Manufactured Objects with Transmitted Images
May 25, 2020

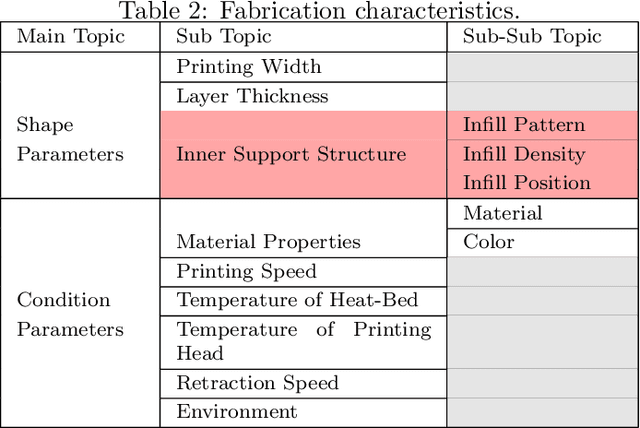

Additive manufacturing has the potential to become a standard method for manufacturing products, and product information is indispensable for the item distribution system. While most products are given barcodes to the exterior surfaces, research on embedding barcodes inside products is underway. This is because additive manufacturing makes it possible to carry out manufacturing and information adding at the same time, and embedding information inside does not impair the exterior appearance of the product. However, products that have not been embedded information can not be identified, and embedded information can not be rewritten later. In this study, we have developed a product identification system that does not require embedding barcodes inside. This system uses a transmission image of the product which contains information of each product such as different inner support structures and manufacturing errors. We have shown through experiments that if datasets of transmission images are available, objects can be identified with an accuracy of over 90%. This result suggests that our approach can be useful for identifying objects without embedded information.
r/Fakeddit: A New Multimodal Benchmark Dataset for Fine-grained Fake News Detection
Nov 10, 2019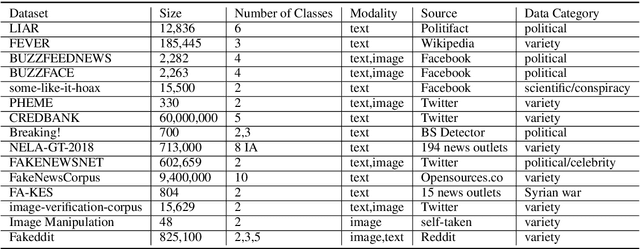

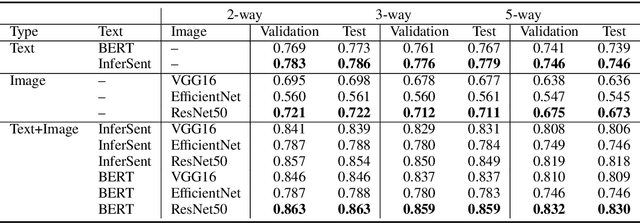
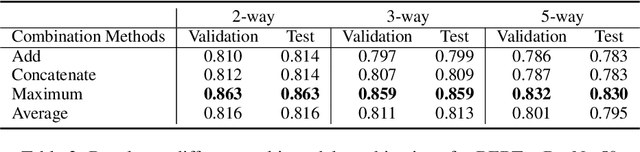
Fake news has altered society in negative ways as evidenced in politics and culture. It has adversely affected both online social network systems as well as offline communities and conversations. Using automatic fake news detection algorithms is an efficient way to combat the rampant dissemination of fake news. However, using an effective dataset has been a problem for fake news research and detection model development. In this paper, we present Fakeddit, a novel dataset consisting of about 800,000 samples from multiple categories of fake news. Each sample is labeled according to 2-way, 3-way, and 5-way classification categories. Prior fake news datasets do not provide multimodal text and image data, metadata, comment data, and fine-grained fake news categorization at this scale and breadth. We construct hybrid text+image models and perform extensive experiments for multiple variations of classification.
Unsupervised Deformable Registration for Multi-Modal Images via Disentangled Representations
Mar 22, 2019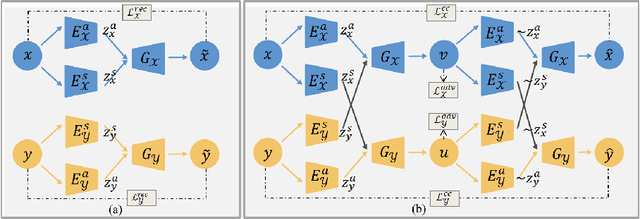
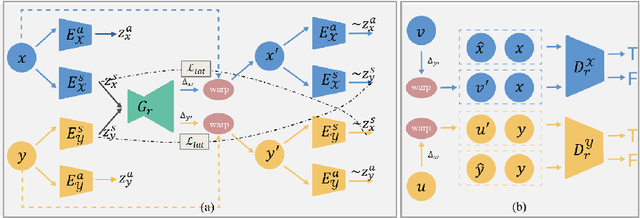
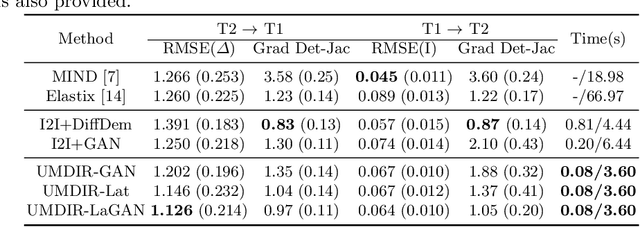
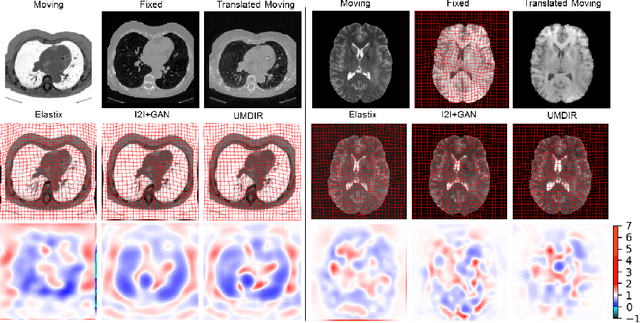
We propose a fully unsupervised multi-modal deformable image registration method (UMDIR), which does not require any ground truth deformation fields or any aligned multi-modal image pairs during training. Multi-modal registration is a key problem in many medical image analysis applications. It is very challenging due to complicated and unknown relationships between different modalities. In this paper, we propose an unsupervised learning approach to reduce the multi-modal registration problem to a mono-modal one through image disentangling. In particular, we decompose images of both modalities into a common latent shape space and separate latent appearance spaces via an unsupervised multi-modal image-to-image translation approach. The proposed registration approach is then built on the factorized latent shape code, with the assumption that the intrinsic shape deformation existing in original image domain is preserved in this latent space. Specifically, two metrics have been proposed for training the proposed network: a latent similarity metric defined in the common shape space and a learningbased image similarity metric based on an adversarial loss. We examined different variations of our proposed approach and compared them with conventional state-of-the-art multi-modal registration methods. Results show that our proposed methods achieve competitive performance against other methods at substantially reduced computation time.
Recurrent Generative Adversarial Networks for Proximal Learning and Automated Compressive Image Recovery
Nov 27, 2017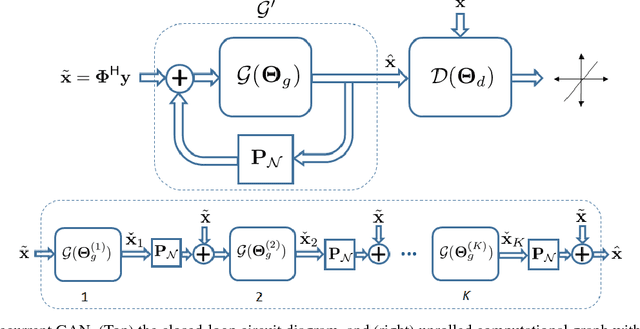

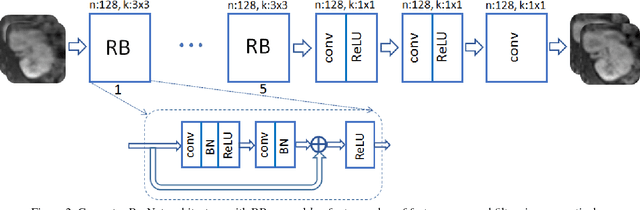
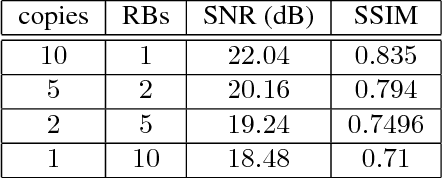
Recovering images from undersampled linear measurements typically leads to an ill-posed linear inverse problem, that asks for proper statistical priors. Building effective priors is however challenged by the low train and test overhead dictated by real-time tasks; and the need for retrieving visually "plausible" and physically "feasible" images with minimal hallucination. To cope with these challenges, we design a cascaded network architecture that unrolls the proximal gradient iterations by permeating benefits from generative residual networks (ResNet) to modeling the proximal operator. A mixture of pixel-wise and perceptual costs is then deployed to train proximals. The overall architecture resembles back-and-forth projection onto the intersection of feasible and plausible images. Extensive computational experiments are examined for a global task of reconstructing MR images of pediatric patients, and a more local task of superresolving CelebA faces, that are insightful to design efficient architectures. Our observations indicate that for MRI reconstruction, a recurrent ResNet with a single residual block effectively learns the proximal. This simple architecture appears to significantly outperform the alternative deep ResNet architecture by 2dB SNR, and the conventional compressed-sensing MRI by 4dB SNR with 100x faster inference. For image superresolution, our preliminary results indicate that modeling the denoising proximal demands deep ResNets.
Region-wise Generative Adversarial ImageInpainting for Large Missing Areas
Sep 27, 2019

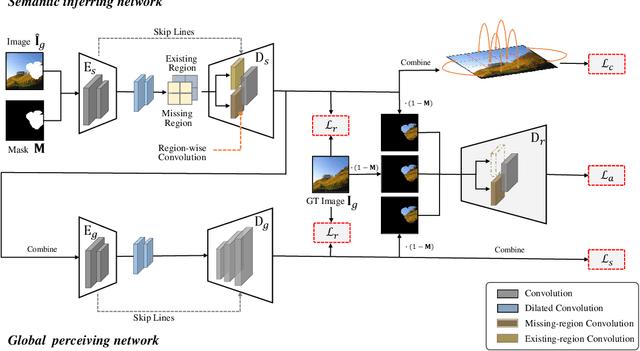
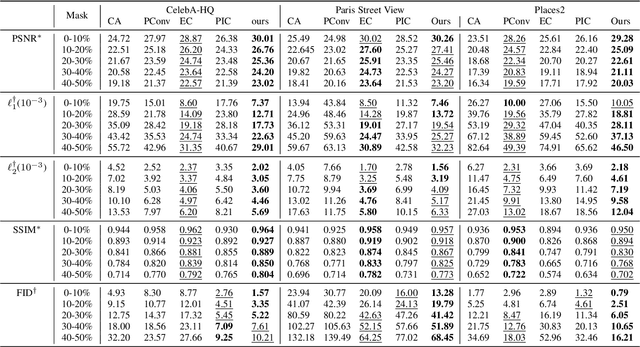
Recently deep neutral networks have achieved promising performance for filling large missing regions in image inpainting tasks. They usually adopted the standard convolutional architecture over the corrupted image, leading to meaningless contents, such as color discrepancy, blur and artifacts. Moreover, most inpainting approaches cannot well handle the large continuous missing area cases. To address these problems, we propose a generic inpainting framework capable of handling with incomplete images on both continuous and discontinuous large missing areas, in an adversarial manner. From which, region-wise convolution is deployed in both generator and discriminator to separately handle with the different regions, namely existing regions and missing ones. Moreover, a correlation loss is introduced to capture the non-local correlations between different patches, and thus guides the generator to obtain more information during inference. With the help of our proposed framework, we can restore semantically reasonable and visually realistic images. Extensive experiments on three widely-used datasets for image inpainting tasks have been conducted, and both qualitative and quantitative experimental results demonstrate that the proposed model significantly outperforms the state-of-the-art approaches, both on the large continuous and discontinuous missing areas.
Using image-extracted features to determine heart rate and blink duration for driver sleepiness detection
Dec 08, 2019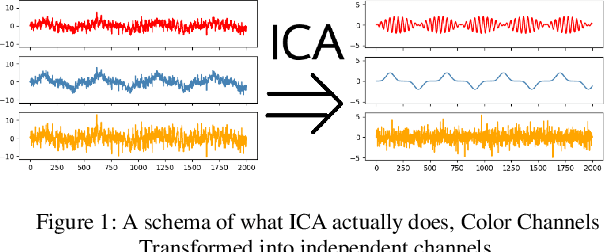
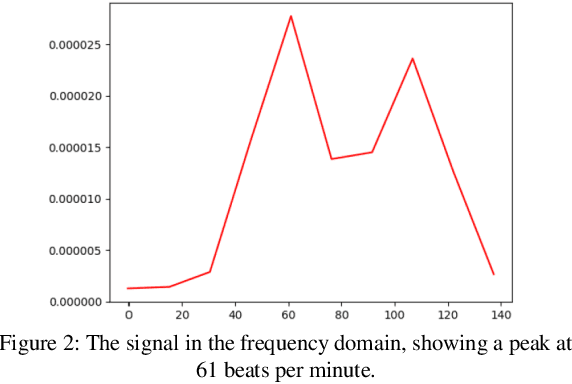


Heart rate and blink duration are two vital physiological signals which give information about cardiac activity and consciousness. Monitoring these two signals is crucial for various applications such as driver drowsiness detection. As there are several problems posed by the conventional systems to be used for continuous, long-term monitoring, a remote blink and ECG monitoring system can be used as an alternative. For estimating the blink duration, two strategies are used. In the first approach, pictures of open and closed eyes are fed into an Artificial Neural Network (ANN) to decide whether the eyes are open or close. In the second approach, they are classified and labeled using Linear Discriminant Analysis (LDA). The labeled images are then be used to determine the blink duration. For heart rate variability, two strategies are used to evaluate the passing blood volume: Independent Component Analysis (ICA); and a chrominance based method. Eye recognition yielded 78-92% accuracy in classifying open/closed eyes with ANN and 71-91% accuracy with LDA. Heart rate evaluations had a mean loss of around 16 Beats Per Minute (BPM) for the ICA strategy and 13 BPM for the chrominance based technique.
A CNN-LSTM Architecture for Detection of Intracranial Hemorrhage on CT scans
May 25, 2020We propose a novel method that combines a convolutional neural network (CNN) with a long short-term memory (LSTM) mechanism for accurate prediction of intracranial hemorrhage on computed tomography (CT) scans. The CNN plays the role of a slice-wise feature extractor while the LSTM is responsible for linking the features across slices. The whole architecture is trained end-to-end with input being an RGB-like image formed by stacking 3 different viewing windows of a single slice. We validate the method on the recent RSNA Intracranial Hemorrhage Detection challenge and on the CQ500 dataset. For the RSNA challenge, our best single model achieves a weighted log loss of 0.0522 on the leaderboard, which is comparable to the top 3% performances, almost all of which make use of ensemble learning. Importantly, our method generalizes very well: the model trained on the RSNA dataset significantly outperforms the 2D model, which does not take into account the relationship between slices, on CQ500. Our codes and models is publicly avaiable at https://github.com/nhannguyen2709/RSNA.
Importance Driven Continual Learning for Segmentation Across Domains
Apr 30, 2020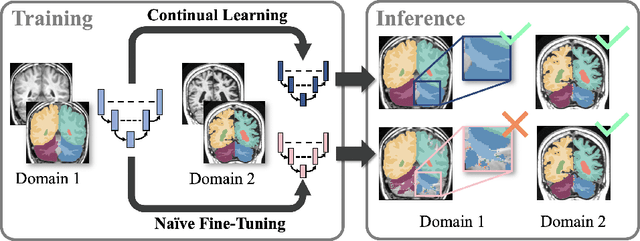
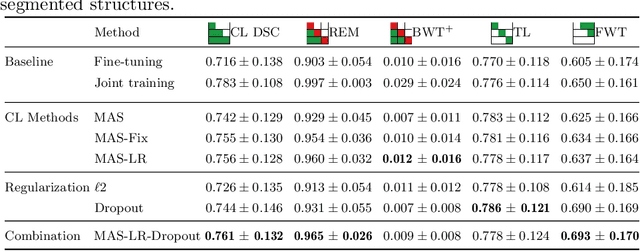
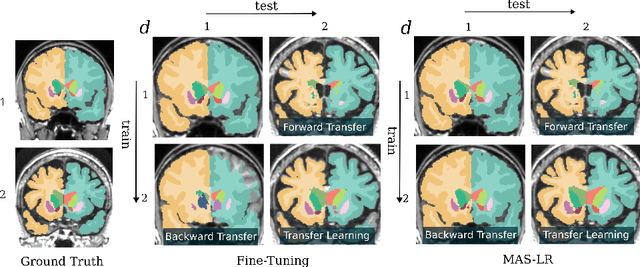
The ability of neural networks to continuously learn and adapt to new tasks while retaining prior knowledge is crucial for many applications. However, current neural networks tend to forget previously learned tasks when trained on new ones, i.e., they suffer from Catastrophic Forgetting (CF). The objective of Continual Learning (CL) is to alleviate this problem, which is particularly relevant for medical applications, where it may not be feasible to store and access previously used sensitive patient data. In this work, we propose a Continual Learning approach for brain segmentation, where a single network is consecutively trained on samples from different domains. We build upon an importance driven approach and adapt it for medical image segmentation. Particularly, we introduce learning rate regularization to prevent the loss of the network's knowledge. Our results demonstrate that directly restricting the adaptation of important network parameters clearly reduces Catastrophic Forgetting for segmentation across domains.
DuDoNet++: Encoding mask projection to reduce CT metal artifacts
Jan 02, 2020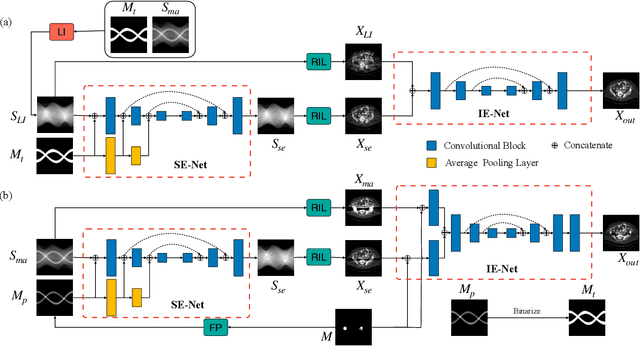

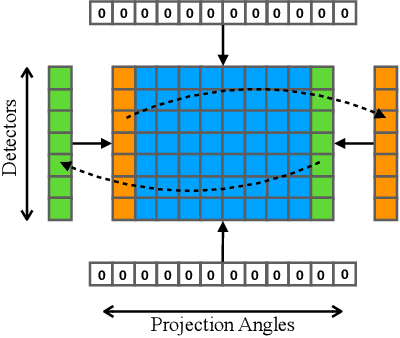

CT metal artifact reduction (MAR) is a notoriously challenging task because the artifacts are structured and non-local in the image domain. However, they are inherently local in the sinogram domain. DuDoNet is the state-of-the-art MAR algorithm which exploits the latter characteristic by learning to reduce artifacts in the sinogram and image domain jointly. By design, DuDoNet treats the metal-affected regions in sinogram as missing and replaces them with the surrogate data generated by a neural network. Since fine-grained details within the metal-affected regions are completely ignored, the artifact-reduced CT images by DuDoNet tend to be over-smoothed and distorted. In this work, we investigate the issue by theoretical derivation. We propose to address the problem by (1) retaining the metal-affected regions in sinogram and (2) replacing the binarized metal trace with the metal mask projection such that the geometry information of metal implants is encoded. Extensive experiments on simulated datasets and expert evaluations on clinical images demonstrate that our network called DuDoNet++ yields anatomically more precise artifact-reduced images than DuDoNet, especially when the metallic objects are large.