 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Understanding image representations by measuring their equivariance and equivalence
Jun 20, 2015
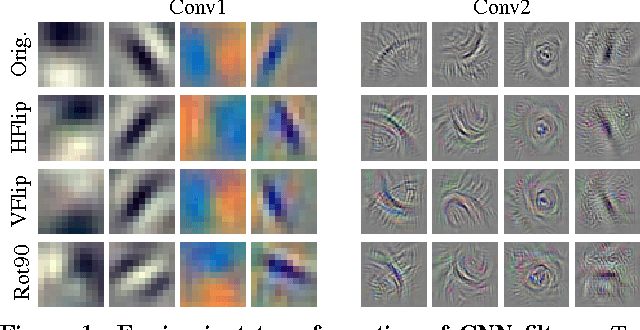
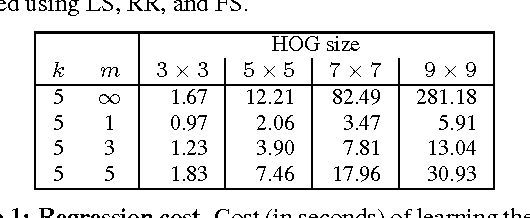
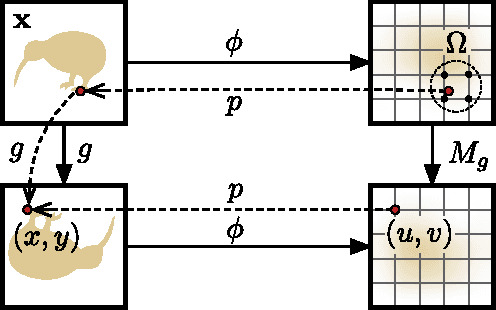
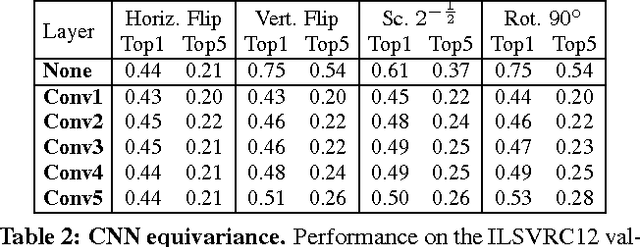
Despite the importance of image representations such as histograms of oriented gradients and deep Convolutional Neural Networks (CNN), our theoretical understanding of them remains limited. Aiming at filling this gap, we investigate three key mathematical properties of representations: equivariance, invariance, and equivalence. Equivariance studies how transformations of the input image are encoded by the representation, invariance being a special case where a transformation has no effect. Equivalence studies whether two representations, for example two different parametrisations of a CNN, capture the same visual information or not. A number of methods to establish these properties empirically are proposed, including introducing transformation and stitching layers in CNNs. These methods are then applied to popular representations to reveal insightful aspects of their structure, including clarifying at which layers in a CNN certain geometric invariances are achieved. While the focus of the paper is theoretical, direct applications to structured-output regression are demonstrated too.
Deep Joint Transmission-Recognition for Power-Constrained IoT Devices
Mar 04, 2020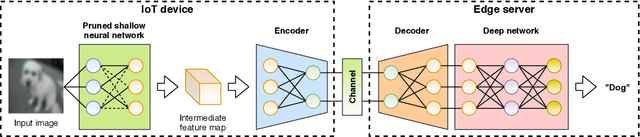
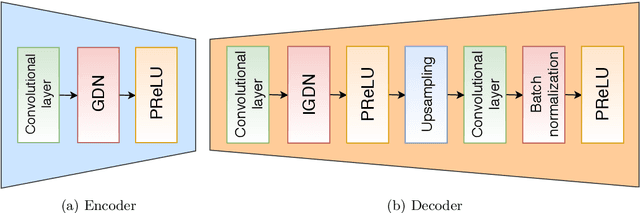
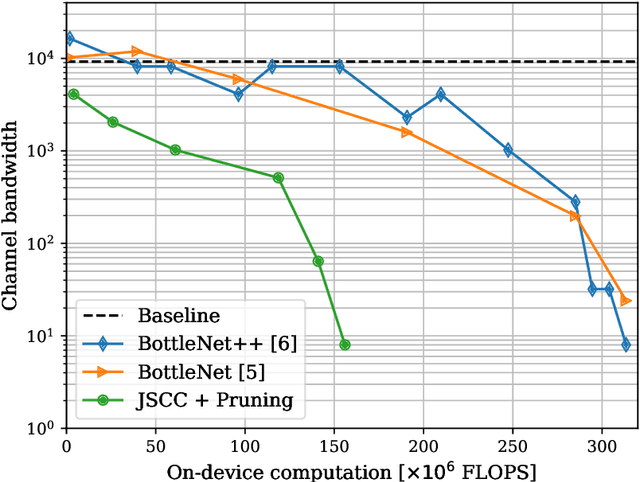
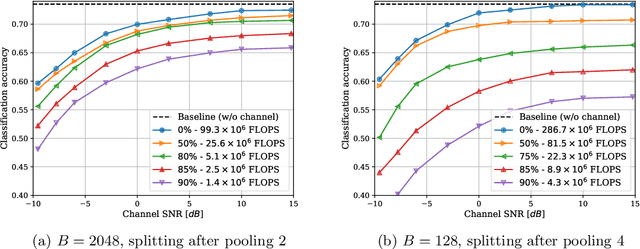
We propose a joint transmission-recognition scheme for efficient inference at the wireless network edge. Our scheme allows for reliable image recognition over wireless channels with significant computational load reduction at the sender side. We incorporate recently proposed deep joint source-channel coding (JSCC) scheme, and combine it with novel filter pruning strategies aimed at reducing the redundant complexity from neural networks. We evaluate our approach on a classification task, and show satisfactory results in both transmission reliability and workload reduction. This is the first work that combines deep JSCC with network pruning and applies it to images classification over wireless network.
BI-MAML: Balanced Incremental Approach for Meta Learning
Jun 12, 2020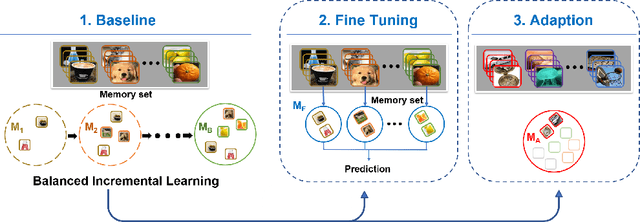

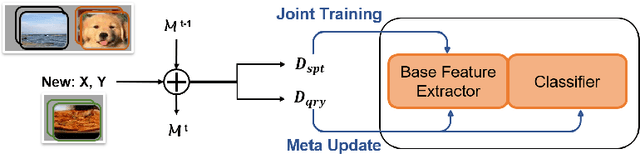

We present a novel Balanced Incremental Model Agnostic Meta Learning system (BI-MAML) for learning multiple tasks. Our method implements a meta-update rule to incrementally adapt its model to new tasks without forgetting old tasks. Such a capability is not possible in current state-of-the-art MAML approaches. These methods effectively adapt to new tasks, however, suffer from 'catastrophic forgetting' phenomena, in which new tasks that are streamed into the model degrade the performance of the model on previously learned tasks. Our system performs the meta-updates with only a few-shots and can successfully accomplish them. Our key idea for achieving this is the design of balanced learning strategy for the baseline model. The strategy sets the baseline model to perform equally well on various tasks and incorporates time efficiency. The balanced learning strategy enables BI-MAML to both outperform other state-of-the-art models in terms of classification accuracy for existing tasks and also accomplish efficient adaption to similar new tasks with less required shots. We evaluate BI-MAML by conducting comparisons on two common benchmark datasets with multiple number of image classification tasks. BI-MAML performance demonstrates advantages in both accuracy and efficiency.
Towards segmentation and spatial alignment of the human embryonic brain using deep learning for atlas-based registration
May 13, 2020



We propose an unsupervised deep learning method for atlas based registration to achieve segmentation and spatial alignment of the embryonic brain in a single framework. Our approach consists of two sequential networks with a specifically designed loss function to address the challenges in 3D first trimester ultrasound. The first part learns the affine transformation and the second part learns the voxelwise nonrigid deformation between the target image and the atlas. We trained this network end-to-end and validated it against a ground truth on synthetic datasets designed to resemble the challenges present in 3D first trimester ultrasound. The method was tested on a dataset of human embryonic ultrasound volumes acquired at 9 weeks gestational age, which showed alignment of the brain in some cases and gave insight in open challenges for the proposed method. We conclude that our method is a promising approach towards fully automated spatial alignment and segmentation of embryonic brains in 3D ultrasound.
Learning To Pay Attention To Mistakes
Aug 07, 2020
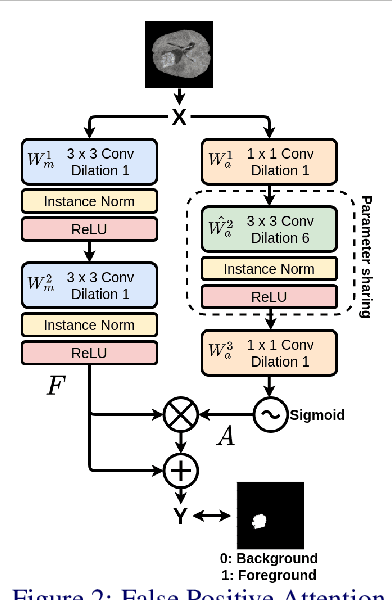
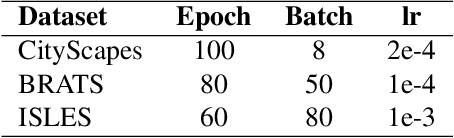
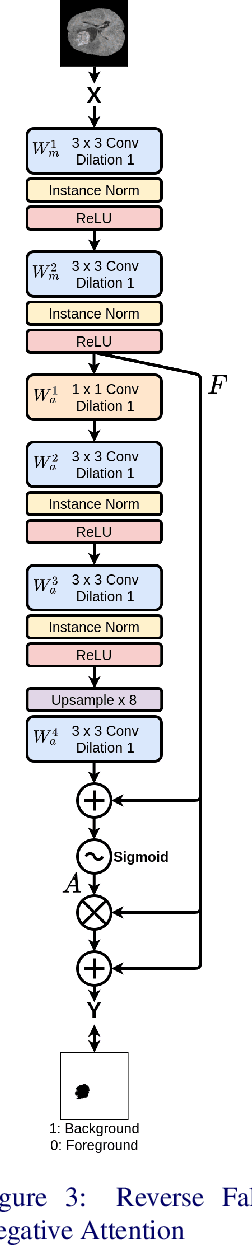
In convolutional neural network based medical image segmentation, the periphery of foreground regions representing malignant tissues may be disproportionately assigned as belonging to the background class of healthy tissues \cite{attenUnet}\cite{AttenUnet2018}\cite{InterSeg}\cite{UnetFrontNeuro}\cite{LearnActiveContour}. This leads to high false negative detection rates. In this paper, we propose a novel attention mechanism to directly address such high false negative rates, called Paying Attention to Mistakes. Our attention mechanism steers the models towards false positive identification, which counters the existing bias towards false negatives. The proposed mechanism has two complementary implementations: (a) "explicit" steering of the model to attend to a larger Effective Receptive Field on the foreground areas; (b) "implicit" steering towards false positives, by attending to a smaller Effective Receptive Field on the background areas. We validated our methods on three tasks: 1) binary dense prediction between vehicles and the background using CityScapes; 2) Enhanced Tumour Core segmentation with multi-modal MRI scans in BRATS2018; 3) segmenting stroke lesions using ultrasound images in ISLES2018. We compared our methods with state-of-the-art attention mechanisms in medical imaging, including self-attention, spatial-attention and spatial-channel mixed attention. Across all of the three different tasks, our models consistently outperform the baseline models in Intersection over Union (IoU) and/or Hausdorff Distance (HD). For instance, in the second task, the "explicit" implementation of our mechanism reduces the HD of the best baseline by more than $26\%$, whilst improving the IoU by more than $3\%$. We believe our proposed attention mechanism can benefit a wide range of medical and computer vision tasks, which suffer from over-detection of background.
HUSE: Hierarchical Universal Semantic Embeddings
Nov 14, 2019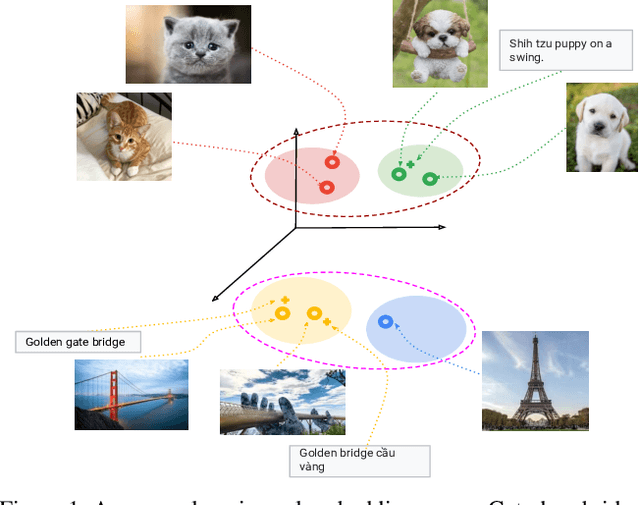
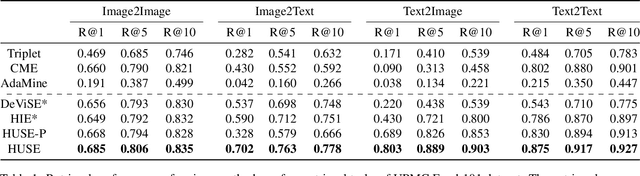
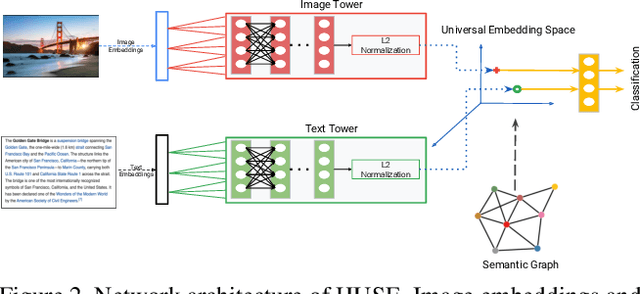
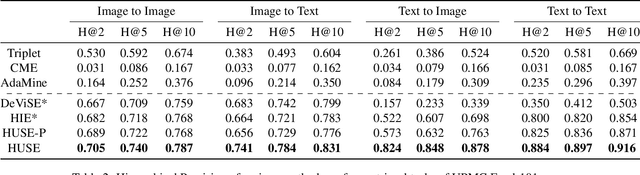
There is a recent surge of interest in cross-modal representation learning corresponding to images and text. The main challenge lies in mapping images and text to a shared latent space where the embeddings corresponding to a similar semantic concept lie closer to each other than the embeddings corresponding to different semantic concepts, irrespective of the modality. Ranking losses are commonly used to create such shared latent space -- however, they do not impose any constraints on inter-class relationships resulting in neighboring clusters to be completely unrelated. The works in the domain of visual semantic embeddings address this problem by first constructing a semantic embedding space based on some external knowledge and projecting image embeddings onto this fixed semantic embedding space. These works are confined only to image domain and constraining the embeddings to a fixed space adds additional burden on learning. This paper proposes a novel method, HUSE, to learn cross-modal representation with semantic information. HUSE learns a shared latent space where the distance between any two universal embeddings is similar to the distance between their corresponding class embeddings in the semantic embedding space. HUSE also uses a classification objective with a shared classification layer to make sure that the image and text embeddings are in the same shared latent space. Experiments on UPMC Food-101 show our method outperforms previous state-of-the-art on retrieval, hierarchical precision and classification results.
Single Shot Video Object Detector
Jul 07, 2020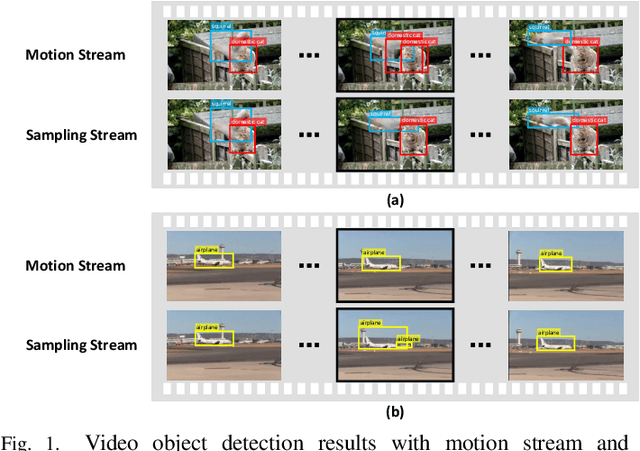
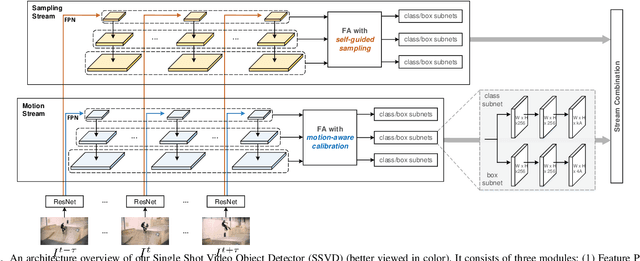
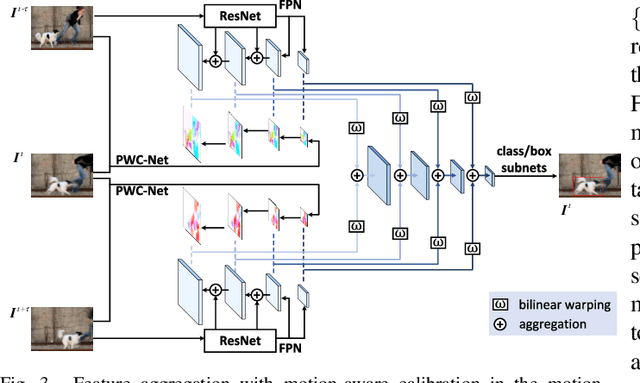
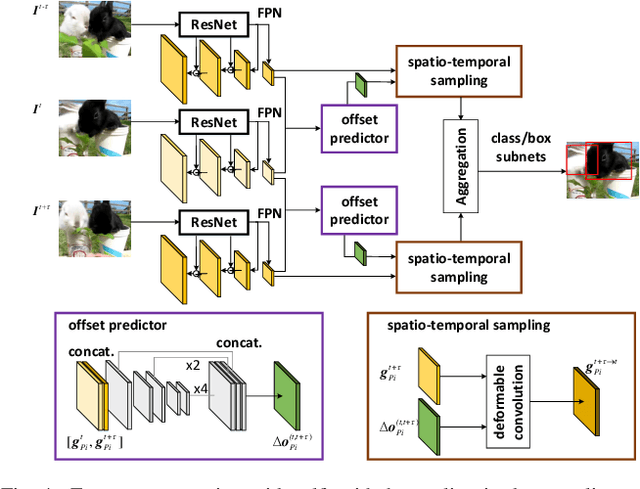
Single shot detectors that are potentially faster and simpler than two-stage detectors tend to be more applicable to object detection in videos. Nevertheless, the extension of such object detectors from image to video is not trivial especially when appearance deterioration exists in videos, \emph{e.g.}, motion blur or occlusion. A valid question is how to explore temporal coherence across frames for boosting detection. In this paper, we propose to address the problem by enhancing per-frame features through aggregation of neighboring frames. Specifically, we present Single Shot Video Object Detector (SSVD) -- a new architecture that novelly integrates feature aggregation into a one-stage detector for object detection in videos. Technically, SSVD takes Feature Pyramid Network (FPN) as backbone network to produce multi-scale features. Unlike the existing feature aggregation methods, SSVD, on one hand, estimates the motion and aggregates the nearby features along the motion path, and on the other, hallucinates features by directly sampling features from the adjacent frames in a two-stream structure. Extensive experiments are conducted on ImageNet VID dataset, and competitive results are reported when comparing to state-of-the-art approaches. More remarkably, for $448 \times 448$ input, SSVD achieves 79.2% mAP on ImageNet VID, by processing one frame in 85 ms on an Nvidia Titan X Pascal GPU. The code is available at \url{https://github.com/ddjiajun/SSVD}.
NAS-Bench-NLP: Neural Architecture Search Benchmark for Natural Language Processing
Jun 12, 2020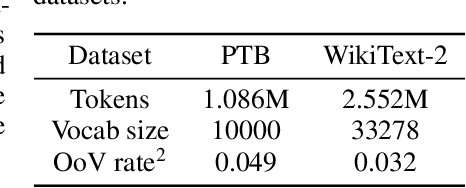

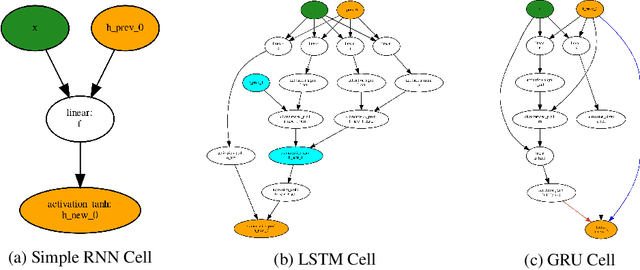
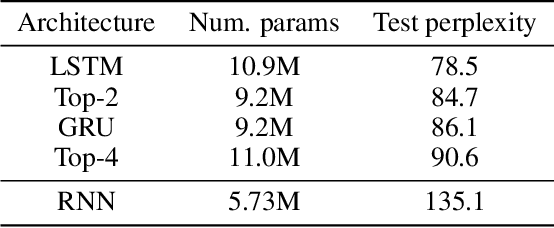
Neural Architecture Search (NAS) is a promising and rapidly evolving research area. Training a large number of neural networks requires an exceptional amount of computational power, which makes NAS unreachable for those researchers who have limited or no access to high-performance clusters and supercomputers. A few benchmarks with precomputed neural architectures performances have been recently introduced to overcome this problem and ensure more reproducible experiments. However, these benchmarks are only for the computer vision domain and, thus, are built from the image datasets and convolution-derived architectures. In this work, we step outside the computer vision domain by leveraging the language modeling task, which is the core of natural language processing (NLP). Our main contribution is as follows: we have provided search space of recurrent neural networks on the text datasets and trained 14k architectures within it; we have conducted both intrinsic and extrinsic evaluation of the trained models using datasets for semantic relatedness and language understanding evaluation; finally, we have tested several NAS algorithms to demonstrate how the precomputed results can be utilized. We believe that our results have high potential of usage for both NAS and NLP communities.
Direct high-order edge-preserving regularization for tomographic image reconstruction
Sep 15, 2015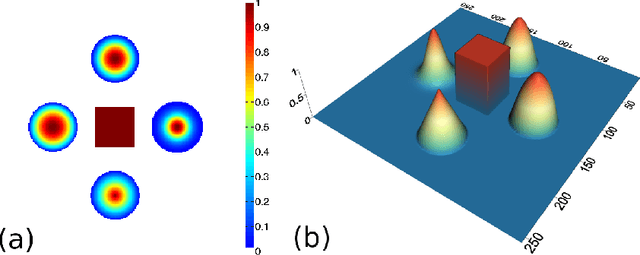

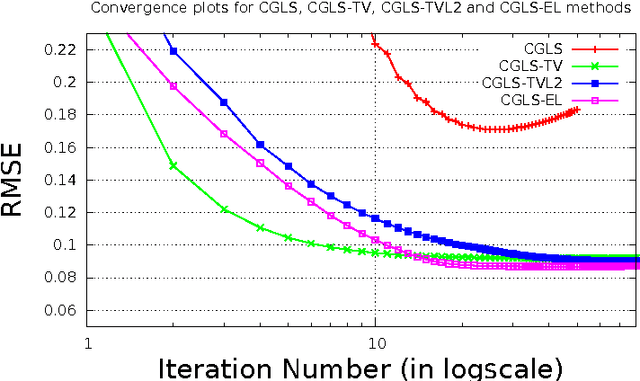
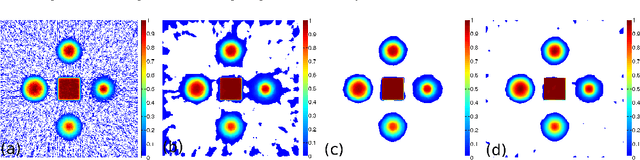
In this paper we present a new two-level iterative algorithm for tomographic image reconstruction. The algorithm uses a regularization technique, which we call edge-preserving Laplacian, that preserves sharp edges between objects while damping spurious oscillations in the areas where the reconstructed image is smooth. Our numerical simulations demonstrate that the proposed method outperforms total variation (TV) regularization and it is competitive with the combined TV-L2 penalty. Obtained reconstructed images show increased signal-to-noise ratio and visually appealing structural features. Computer implementation and parameter control of the proposed technique is straightforward, which increases the feasibility of it across many tomographic applications. In this paper, we applied our method to the under-sampled computed tomography (CT) projection data and also considered a case of reconstruction in emission tomography The MATLAB code is provided to support obtained results.
Deep Learning based Switching Filter for Impulsive Noise Removal in Color Images
Dec 03, 2019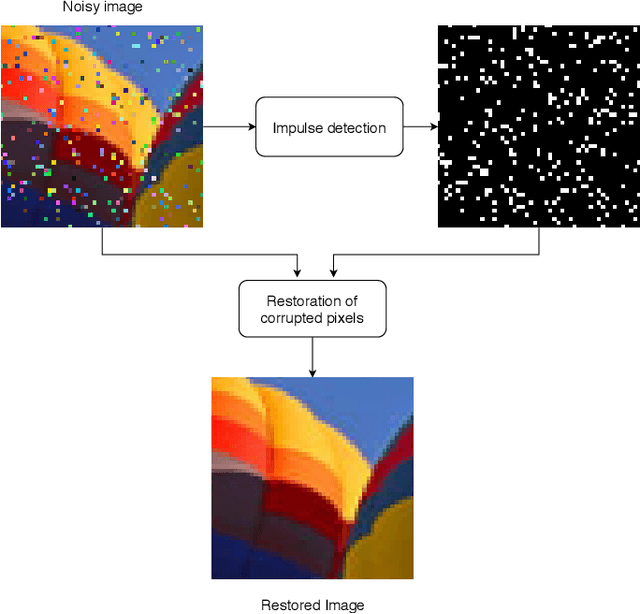


Noise reduction is one the most important and still active research topic in low-level image processing due to its high impact on object detection and scene understanding for computer vision systems. Recently, we can observe a substantial increase of interest in the application of deep learning algorithms in many computer vision problems due to its impressive capability of automatic feature extraction and classification. These methods have been also successfully applied in image denoising, significantly improving the performance, but most of the proposed approaches were designed for Gaussian noise suppression. In this paper, we present a switching filtering design intended for impulsive noise removal using deep learning. In the proposed method, the impulses are identified using a novel deep neural network architecture and noisy pixels are restored using the fast adaptive mean filter. The performed experiments show that the proposed approach is superior to the state-of-the-art filters designed for impulsive noise removal in digital color images.