 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHUSE: Hierarchical Universal Semantic Embeddings
Paper and Code
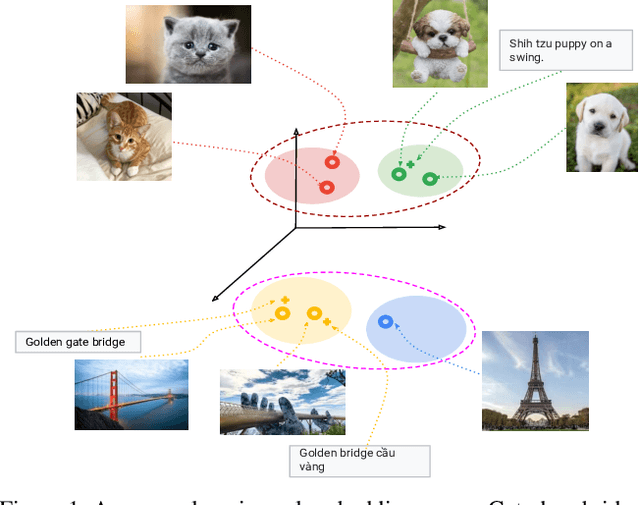
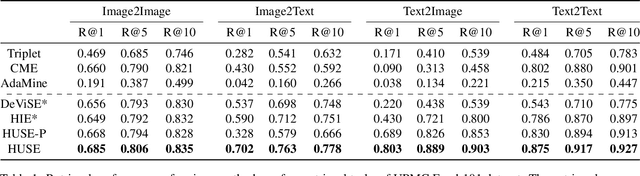
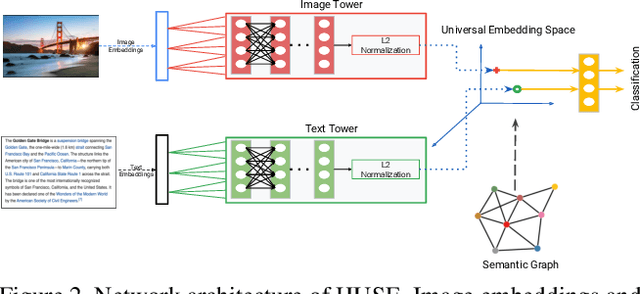
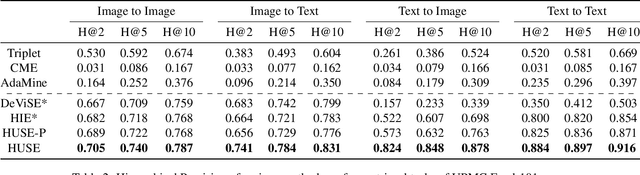
There is a recent surge of interest in cross-modal representation learning corresponding to images and text. The main challenge lies in mapping images and text to a shared latent space where the embeddings corresponding to a similar semantic concept lie closer to each other than the embeddings corresponding to different semantic concepts, irrespective of the modality. Ranking losses are commonly used to create such shared latent space -- however, they do not impose any constraints on inter-class relationships resulting in neighboring clusters to be completely unrelated. The works in the domain of visual semantic embeddings address this problem by first constructing a semantic embedding space based on some external knowledge and projecting image embeddings onto this fixed semantic embedding space. These works are confined only to image domain and constraining the embeddings to a fixed space adds additional burden on learning. This paper proposes a novel method, HUSE, to learn cross-modal representation with semantic information. HUSE learns a shared latent space where the distance between any two universal embeddings is similar to the distance between their corresponding class embeddings in the semantic embedding space. HUSE also uses a classification objective with a shared classification layer to make sure that the image and text embeddings are in the same shared latent space. Experiments on UPMC Food-101 show our method outperforms previous state-of-the-art on retrieval, hierarchical precision and classification results.