 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Generic Framework for Assessing the Performance Bounds of Image Feature Detectors
May 19, 2016


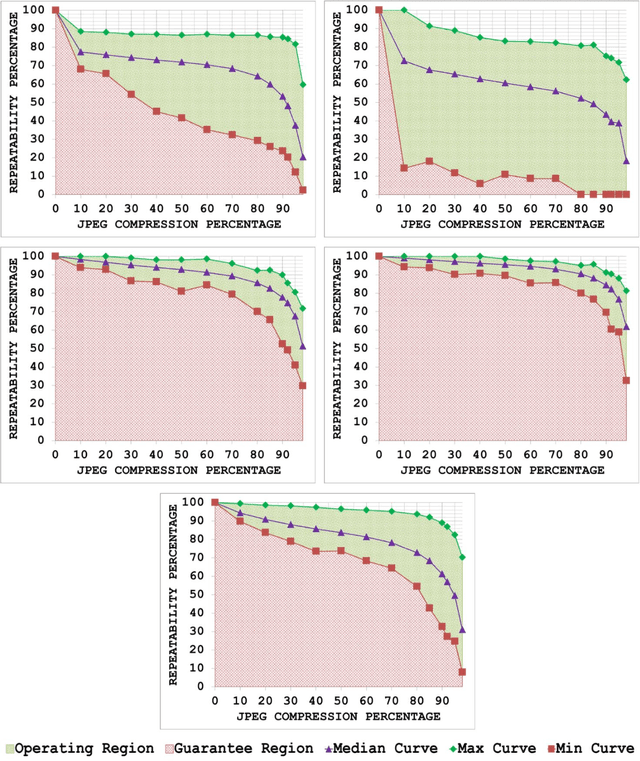
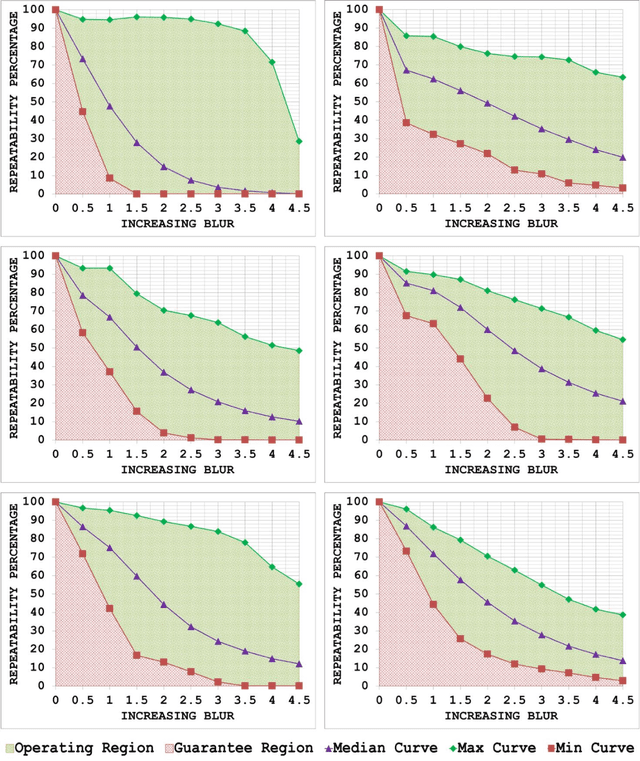
Since local feature detection has been one of the most active research areas in computer vision during the last decade, a large number of detectors have been proposed. The interest in feature-based applications continues to grow and has thus rendered the task of characterizing the performance of various feature detection methods an important issue in vision research. Inspired by the good practices of electronic system design, a generic framework based on the repeatability measure is presented in this paper that allows assessment of the upper and lower bounds of detector performance and finds statistically significant performance differences between detectors as a function of image transformation amount by introducing a new variant of McNemars test in an effort to design more reliable and effective vision systems. The proposed framework is then employed to establish operating and guarantee regions for several state-of-the-art detectors and to identify their statistical performance differences for three specific image transformations: JPEG compression, uniform light changes and blurring. The results are obtained using a newly acquired, large image database (20482) images with 539 different scenes. These results provide new insights into the behaviour of detectors and are also useful from the vision systems design perspective.
Self-Supervised Unconstrained Illumination Invariant Representation
Nov 28, 2019
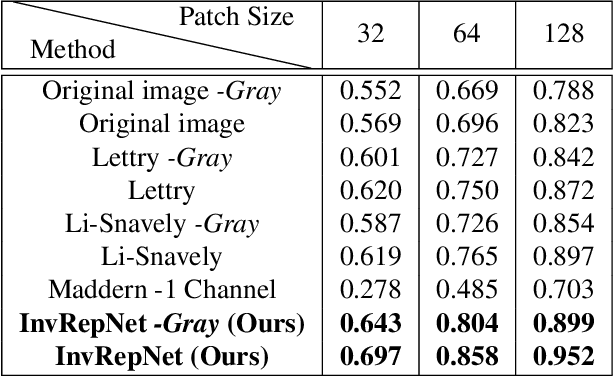

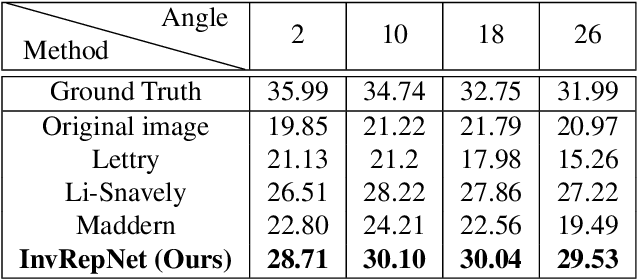
We propose a new and completely data-driven approach for generating an unconstrained illumination invariant representation of images. Our method trains a neural network with a specialized triplet loss designed to emphasize actual scene changes while downplaying changes in illumination. For this purpose we use the BigTime image dataset, which contains static scenes acquired at different times. We analyze the attributes of our representation, and show that it improves patch matching and rigid registration over state-of-the-art illumination invariant representations. We point out that the utility of our method is not restricted to handling illumination invariance, and that it may be applied for generating representations which are invariant to general types of nuisance, undesired, image variants.
Deep Convolutional Features for Image Based Retrieval and Scene Categorization
Sep 20, 2015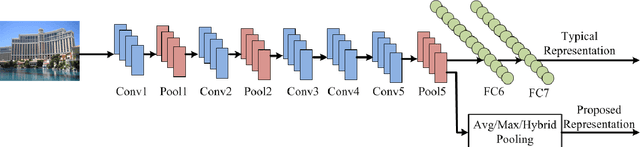
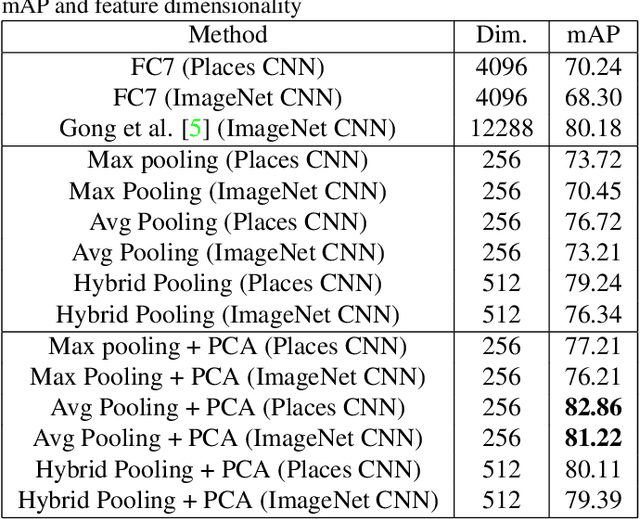


Several recent approaches showed how the representations learned by Convolutional Neural Networks can be repurposed for novel tasks. Most commonly it has been shown that the activation features of the last fully connected layers (fc7 or fc6) of the network, followed by a linear classifier outperform the state-of-the-art on several recognition challenge datasets. Instead of recognition, this paper focuses on the image retrieval problem and proposes a examines alternative pooling strategies derived for CNN features. The presented scheme uses the features maps from an earlier layer 5 of the CNN architecture, which has been shown to preserve coarse spatial information and is semantically meaningful. We examine several pooling strategies and demonstrate superior performance on the image retrieval task (INRIA Holidays) at the fraction of the computational cost, while using a relatively small memory requirements. In addition to retrieval, we see similar efficiency gains on the SUN397 scene categorization dataset, demonstrating wide applicability of this simple strategy. We also introduce and evaluate a novel GeoPlaces5K dataset from different geographical locations in the world for image retrieval that stresses more dramatic changes in appearance and viewpoint.
Learning Depth via Interaction
Mar 02, 2020

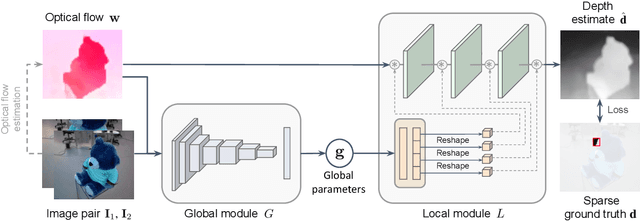

Motivated by the astonishing capabilities of natural intelligent agents and inspired by theories from psychology, this paper explores the idea that perception gets coupled to 3D properties of the world via interaction with the environment. Existing works for depth estimation require either massive amounts of annotated training data or some form of hard-coded geometrical constraint. This paper explores a new approach to learning depth perception requiring neither of those. Specifically, we train a specialized global-local network architecture with what would be available to a robot interacting with the environment: from extremely sparse depth measurements down to even a single pixel per image. From a pair of consecutive images, our proposed network outputs a latent representation of the observer's motion between the images and a dense depth map. Experiments on several datasets show that, when ground truth is available even for just one of the image pixels, the proposed network can learn monocular dense depth estimation up to 22.5% more accurately than state-of-the-art approaches. We believe that this work, despite its scientific interest, lays the foundations to learn depth from extremely sparse supervision, which can be valuable to all robotic systems acting under severe bandwidth or sensing constraints.
Color-complexity enabled exhaustive color-dots identification and spatial patterns testing in images
Jul 28, 2020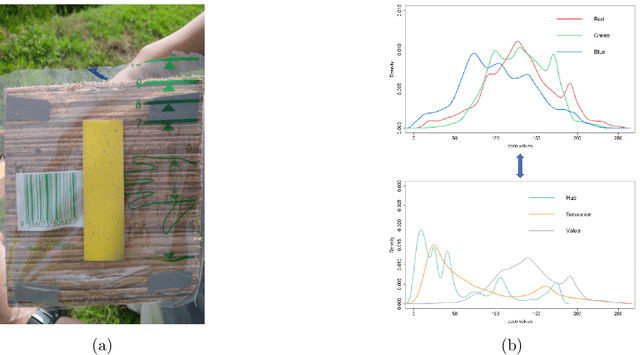

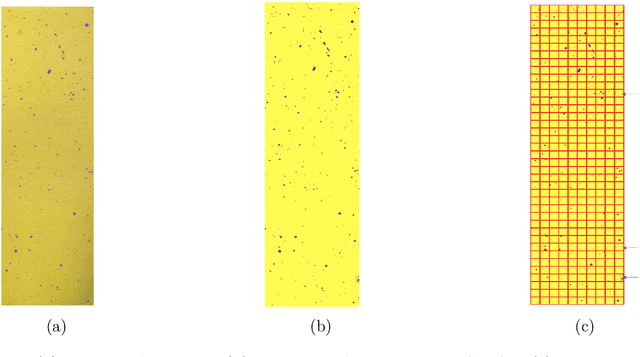

Targeted color-dots with varying shapes and sizes in images are first exhaustively identified, and then their multiscale 2D geometric patterns are extracted for testing spatial uniformness in a progressive fashion. Based on color theory in physics, we develop a new color-identification algorithm relying on highly associative relations among the three color-coordinates: RGB or HSV. Such high associations critically imply low color-complexity of a color image, and renders potentials of exhaustive identification of targeted color-dots of all shapes and sizes. Via heterogeneous shaded regions and lighting conditions, our algorithm is shown being robust, practical and efficient comparing with the popular Contour and OpenCV approaches. Upon all identified color-pixels, we form color-dots as individually connected networks with shapes and sizes. We construct minimum spanning trees (MST) as spatial geometries of dot-collectives of various size-scales. Given a size-scale, the distribution of distances between immediate neighbors in the observed MST is extracted, so do many simulated MSTs under the spatial uniformness assumption. We devise a new algorithm for testing 2D spatial uniformness based on a Hierarchical clustering tree upon all involving MSTs. Our developments are illustrated on images obtained by mimicking chemical spraying via drone in Precision Agriculture.
Adversarial Defense by Latent Style Transformations
Jun 17, 2020

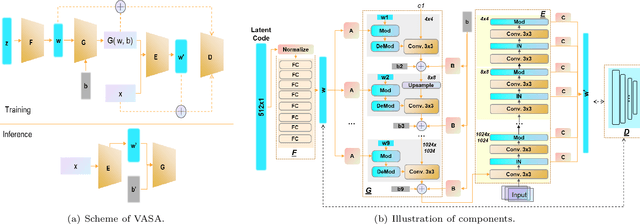
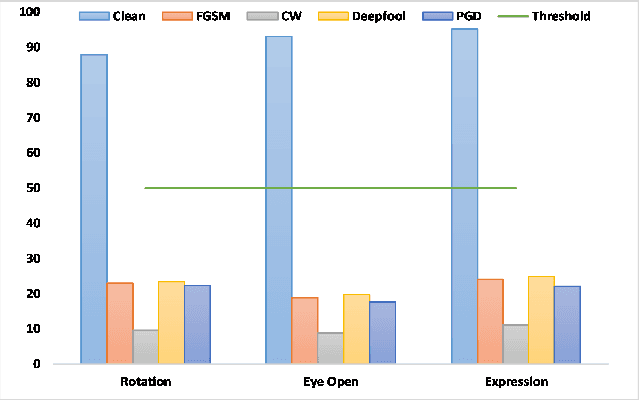
Machine learning models have demonstrated vulnerability to adversarial attacks, more specifically misclassification of adversarial examples. In this paper, we investigate an attack-agnostic defense against adversarial attacks on high-resolution images by detecting suspicious inputs. The intuition behind our approach is that the essential characteristics of a normal image are generally consistent with non-essential style transformations, e.g., slightly changing the facial expression of human portraits. In contrast, adversarial examples are generally sensitive to such transformations. In our approach to detect adversarial instances, we propose an in\underline{V}ertible \underline{A}utoencoder based on the \underline{S}tyleGAN2 generator via \underline{A}dversarial training (VASA) to inverse images to disentangled latent codes that reveal hierarchical styles. We then build a set of edited copies with non-essential style transformations by performing latent shifting and reconstruction, based on the correspondences between latent codes and style transformations. The classification-based consistency of these edited copies is used to distinguish adversarial instances.
Can Synthetic Data Improve Object Detection Results for Remote Sensing Images?
Jun 09, 2020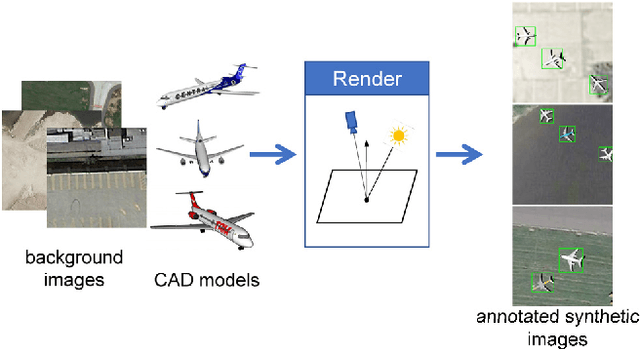
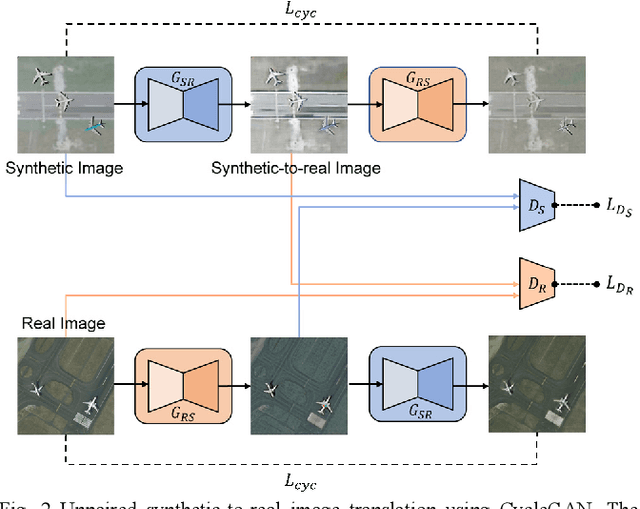

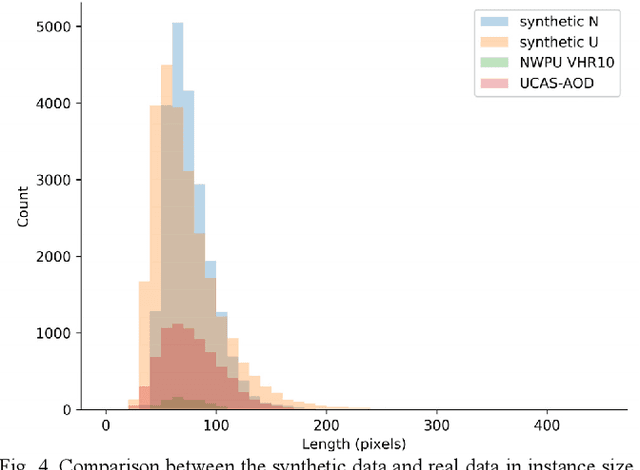
Deep learning approaches require enough training samples to perform well, but it is a challenge to collect enough real training data and label them manually. In this letter, we propose the use of realistic synthetic data with a wide distribution to improve the performance of remote sensing image aircraft detection. Specifically, to increase the variability of synthetic data, we randomly set the parameters during rendering, such as the size of the instance and the class of background images. In order to make the synthetic images more realistic, we then refine the synthetic images at the pixel level using CycleGAN with real unlabeled images. We also fine-tune the model with a small amount of real data, to obtain a higher accuracy. Experiments on NWPU VHR-10, UCAS-AOD and DIOR datasets demonstrate that the proposed method can be applied for augmenting insufficient real data.
Learning to Recognise Words using Visually Grounded Speech
May 31, 2020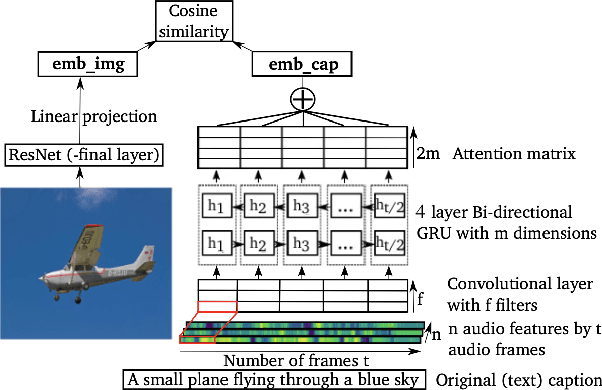
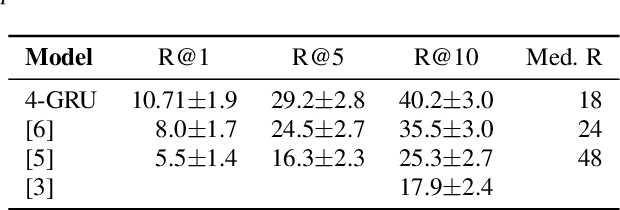
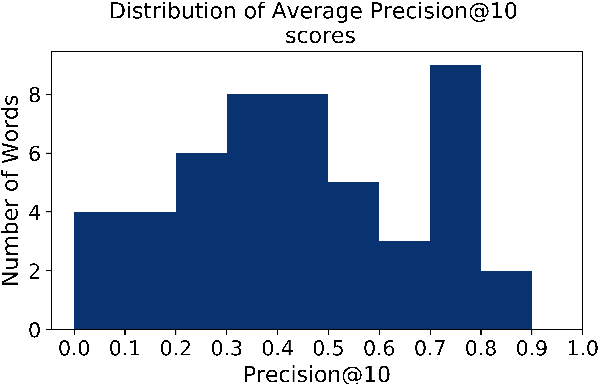

We investigated word recognition in a Visually Grounded Speech model. The model has been trained on pairs of images and spoken captions to create visually grounded embeddings which can be used for speech to image retrieval and vice versa. We investigate whether such a model can be used to recognise words by embedding isolated words and using them to retrieve images of their visual referents. We investigate the time-course of word recognition using a gating paradigm and perform a statistical analysis to see whether well known word competition effects in human speech processing influence word recognition. Our experiments show that the model is able to recognise words, and the gating paradigm reveals that words can be recognised from partial input as well and that recognition is negatively influenced by word competition from the word initial cohort.
From Words to Sentences: A Progressive Learning Approach for Zero-resource Machine Translation with Visual Pivots
Jun 03, 2019
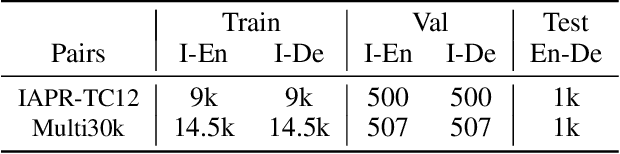
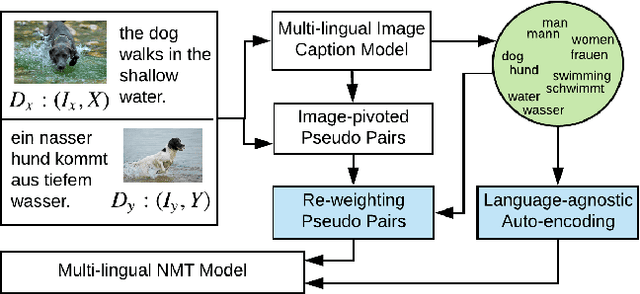
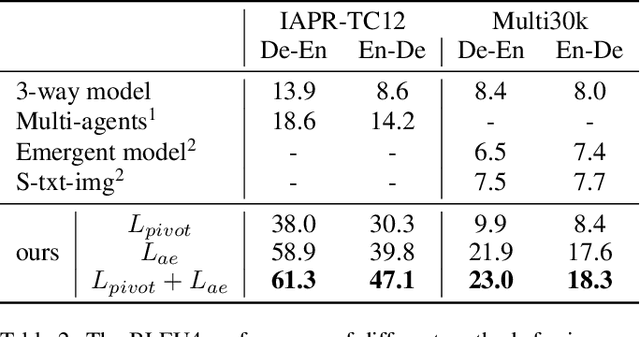
The neural machine translation model has suffered from the lack of large-scale parallel corpora. In contrast, we humans can learn multi-lingual translations even without parallel texts by referring our languages to the external world. To mimic such human learning behavior, we employ images as pivots to enable zero-resource translation learning. However, a picture tells a thousand words, which makes multi-lingual sentences pivoted by the same image noisy as mutual translations and thus hinders the translation model learning. In this work, we propose a progressive learning approach for image-pivoted zero-resource machine translation. Since words are less diverse when grounded in the image, we first learn word-level translation with image pivots, and then progress to learn the sentence-level translation by utilizing the learned word translation to suppress noises in image-pivoted multi-lingual sentences. Experimental results on two widely used image-pivot translation datasets, IAPR-TC12 and Multi30k, show that the proposed approach significantly outperforms other state-of-the-art methods.
Correcting Data Imbalance for Semi-Supervised Covid-19 Detection Using X-ray Chest Images
Aug 19, 2020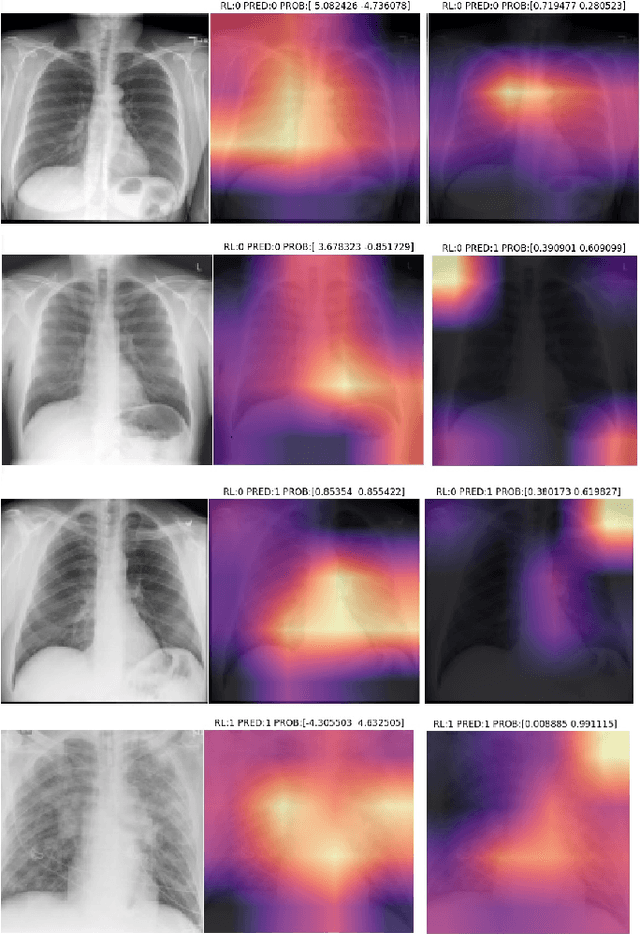
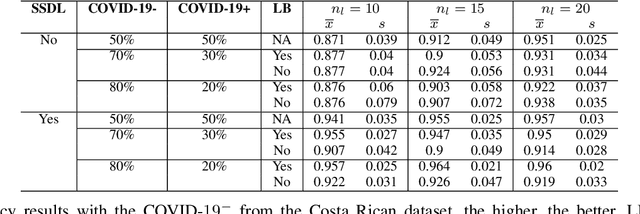
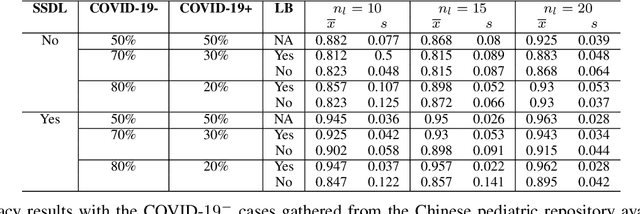
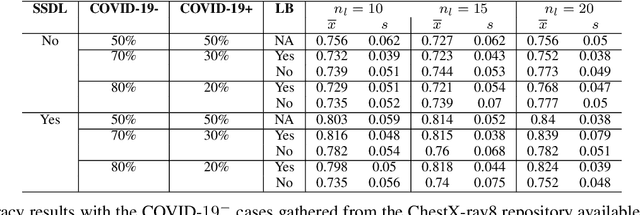
The Corona Virus (COVID-19) is an internationalpandemic that has quickly propagated throughout the world. The application of deep learning for image classification of chest X-ray images of Covid-19 patients, could become a novel pre-diagnostic detection methodology. However, deep learning architectures require large labelled datasets. This is often a limitation when the subject of research is relatively new as in the case of the virus outbreak, where dealing with small labelled datasets is a challenge. Moreover, in the context of a new highly infectious disease, the datasets are also highly imbalanced,with few observations from positive cases of the new disease. In this work we evaluate the performance of the semi-supervised deep learning architecture known as MixMatch using a very limited number of labelled observations and highly imbalanced labelled dataset. We propose a simple approach for correcting data imbalance, re-weight each observationin the loss function, giving a higher weight to the observationscorresponding to the under-represented class. For unlabelled observations, we propose the usage of the pseudo and augmentedlabels calculated by MixMatch to choose the appropriate weight. The MixMatch method combined with the proposed pseudo-label based balance correction improved classification accuracy by up to 10%, with respect to the non balanced MixMatch algorithm, with statistical significance. We tested our proposed approach with several available datasets using 10, 15 and 20 labelledobservations. Additionally, a new dataset is included among thetested datasets, composed of chest X-ray images of Costa Rican adult patients