 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Depth via Interaction
Paper and Code
Mar 02, 2020

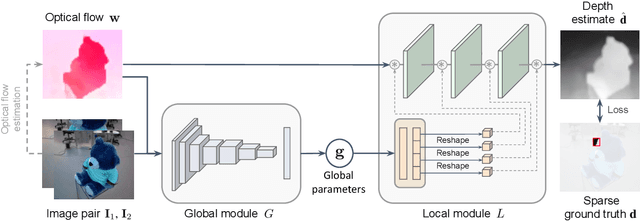

Motivated by the astonishing capabilities of natural intelligent agents and inspired by theories from psychology, this paper explores the idea that perception gets coupled to 3D properties of the world via interaction with the environment. Existing works for depth estimation require either massive amounts of annotated training data or some form of hard-coded geometrical constraint. This paper explores a new approach to learning depth perception requiring neither of those. Specifically, we train a specialized global-local network architecture with what would be available to a robot interacting with the environment: from extremely sparse depth measurements down to even a single pixel per image. From a pair of consecutive images, our proposed network outputs a latent representation of the observer's motion between the images and a dense depth map. Experiments on several datasets show that, when ground truth is available even for just one of the image pixels, the proposed network can learn monocular dense depth estimation up to 22.5% more accurately than state-of-the-art approaches. We believe that this work, despite its scientific interest, lays the foundations to learn depth from extremely sparse supervision, which can be valuable to all robotic systems acting under severe bandwidth or sensing constraints.