 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unlabeled Data Deployment for Classification of Diabetic Retinopathy Images Using Knowledge Transfer
Feb 09, 2020
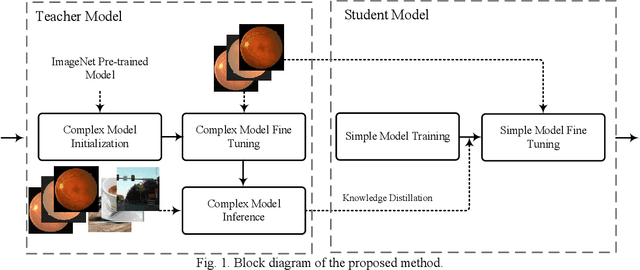
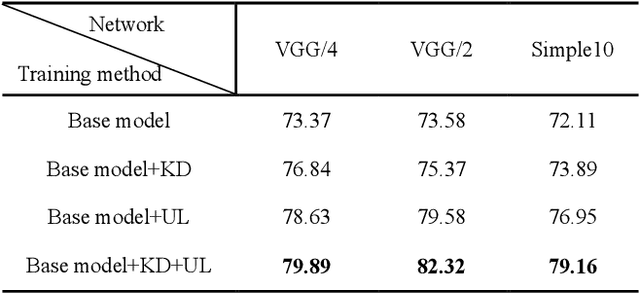
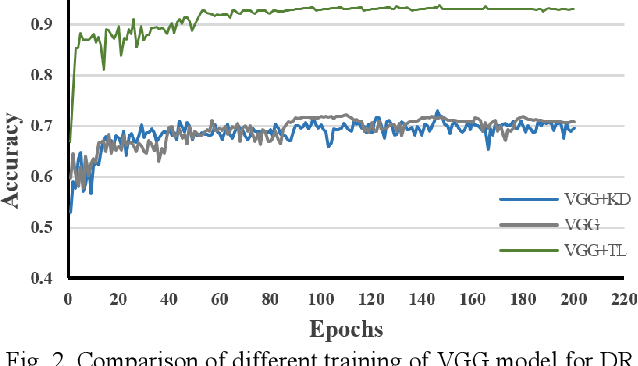
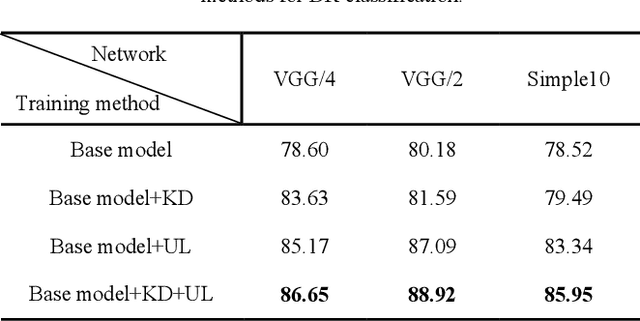
Convolutional neural networks (CNNs) are extensively beneficial for medical image processing. Medical images are plentiful, but there is a lack of annotated data. Transfer learning is used to solve the problem of lack of labeled data and grants CNNs better training capability. Transfer learning can be used in many different medical applications; however, the model under transfer should have the same size as the original network. Knowledge distillation is recently proposed to transfer the knowledge of a model to another one and can be useful to cover the shortcomings of transfer learning. But some parts of the knowledge may not be distilled by knowledge distillation. In this paper, a novel knowledge distillation using transfer learning is proposed to transfer the whole knowledge of a model to another one. The proposed method can be beneficial and practical for medical image analysis in which a small number of labeled data are available. The proposed process is tested for diabetic retinopathy classification. Simulation results demonstrate that using the proposed method, knowledge of an extensive network can be transferred to a smaller model.
Hyperparameter Ensembles for Robustness and Uncertainty Quantification
Jun 24, 2020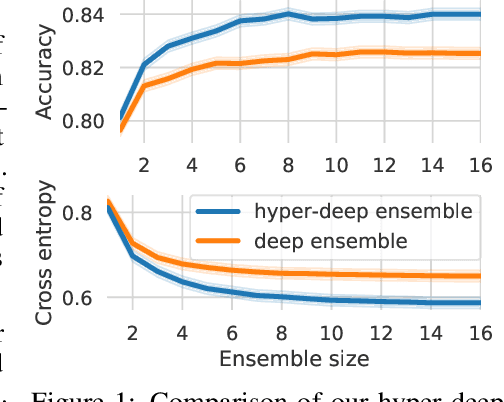
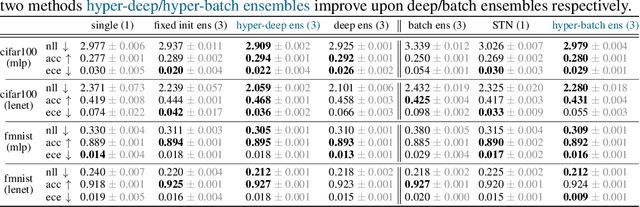

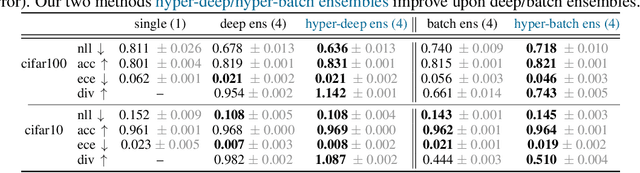
Ensembles over neural network weights trained from different random initialization, known as deep ensembles, achieve state-of-the-art accuracy and calibration. The recently introduced batch ensembles provide a drop-in replacement that is more parameter efficient. In this paper, we design ensembles not only over weights, but over hyperparameters to improve the state of the art in both settings. For best performance independent of budget, we propose hyper-deep ensembles, a simple procedure that involves a random search over different hyperparameters, themselves stratified across multiple random initializations. Its strong performance highlights the benefit of combining models with both weight and hyperparameter diversity. We further propose a parameter efficient version, hyper-batch ensembles, which builds on the layer structure of batch ensembles and self-tuning networks. The computational and memory costs of our method are notably lower than typical ensembles. On image classification tasks, with MLP, LeNet, and Wide ResNet 28-10 architectures, our methodology improves upon both deep and batch ensembles.
Orderless Recurrent Models for Multi-label Classification
Nov 25, 2019
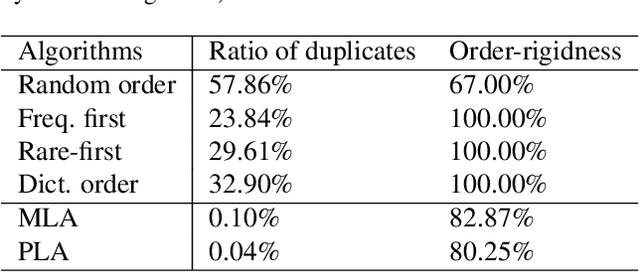
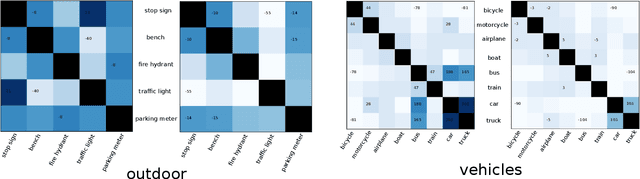
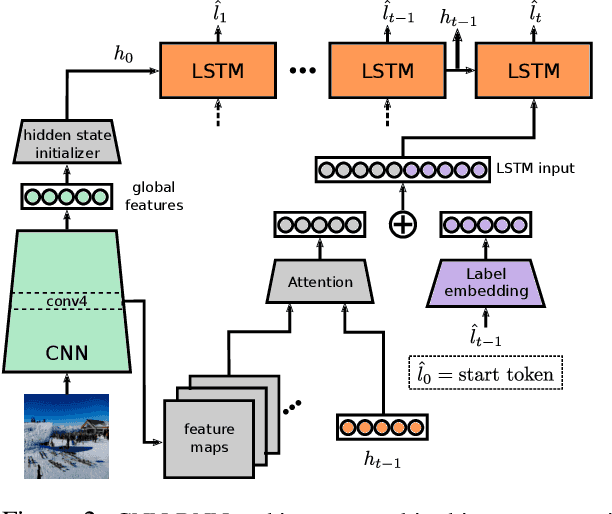
Recurrent neural networks (RNN) are popular for many computer vision tasks, including multi-label classification. Since RNNs produce sequential outputs, labels need to be ordered for the multi-label classification task. Current approaches sort labels according to their frequency, typically ordering them in either rare-first or frequent-first. These imposed orderings do not take into account that the natural order to generate the labels can change for each image, e.g.\ first the dominant object before summing up the smaller objects in the image. Therefore, in this paper, we propose ways to dynamically order the ground truth labels with the predicted label sequence. This allows for the faster training of more optimal LSTM models for multi-label classification. Analysis evidences that our method does not suffer from duplicate generation, something which is common for other models. Furthermore, it outperforms other CNN-RNN models, and we show that a standard architecture of an image encoder and language decoder trained with our proposed loss obtains the state-of-the-art results on the challenging MS-COCO, WIDER Attribute and PA-100K and competitive results on NUS-WIDE.
Gray Level Image Threshold Using Neutrosophic Shannon Entropy
Jun 26, 2019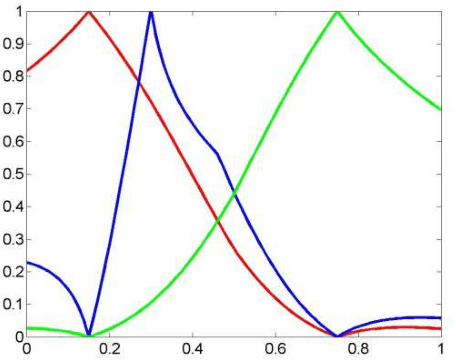

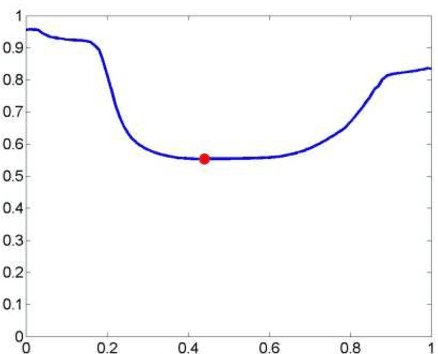

This article presents a new method of segmenting grayscale images by minimizing Shannon's neutrosophic entropy. For the proposed segmentation method, the neutrosophic information components, i.e., the degree of truth, the degree of neutrality and the degree of falsity are defined taking into account the belonging to the segmented regions and at the same time to the separation threshold area. The principle of the method is simple and easy to understand and can lead to multiple thresholds. The efficacy of the method is illustrated using some test gray level images. The experimental results show that the proposed method has good performance for segmentation with optimal gray level thresholds.
Two-Stage Deep Learning for Accelerated 3D Time-of-Flight MRA without Matched Training Data
Aug 04, 2020
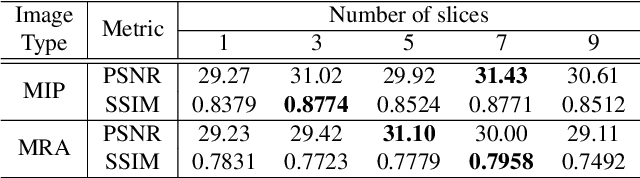
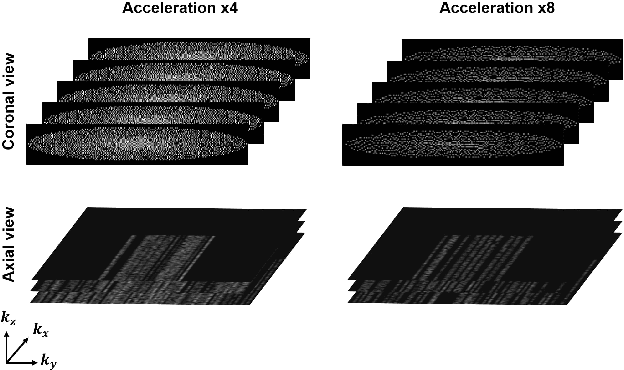
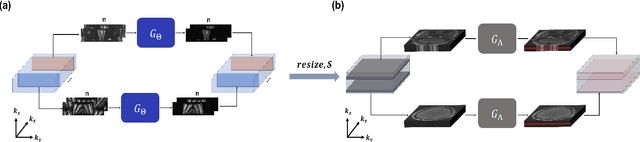
Time-of-flight magnetic resonance angiography (TOF-MRA) is one of the most widely used non-contrast MR imaging methods to visualize blood vessels, but due to the 3-D volume acquisition highly accelerated acquisition is necessary. Accordingly, high quality reconstruction from undersampled TOF-MRA is an important research topic for deep learning. However, most existing deep learning works require matched reference data for supervised training, which are often difficult to obtain. By extending the recent theoretical understanding of cycleGAN from the optimal transport theory, here we propose a novel two-stage unsupervised deep learning approach, which is composed of the multi-coil reconstruction network along the coronal plane followed by a multi-planar refinement network along the axial plane. Specifically, the first network is trained in the square-root of sum of squares (SSoS) domain to achieve high quality parallel image reconstruction, whereas the second refinement network is designed to efficiently learn the characteristics of highly-activated blood flow using double-headed max-pool discriminator. Extensive experiments demonstrate that the proposed learning process without matched reference exceeds performance of state-of-the-art compressed sensing (CS)-based method and provides comparable or even better results than supervised learning approaches.
Relation Network for Person Re-identification
Nov 25, 2019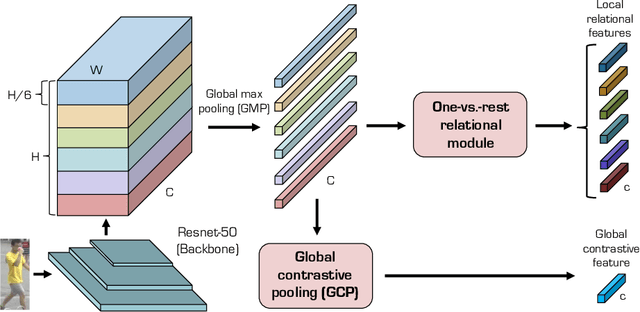
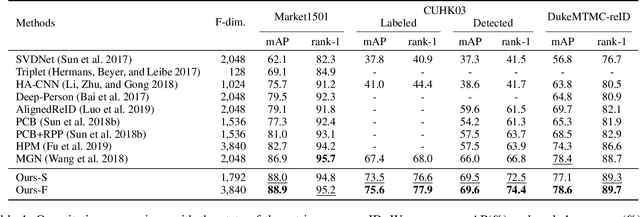
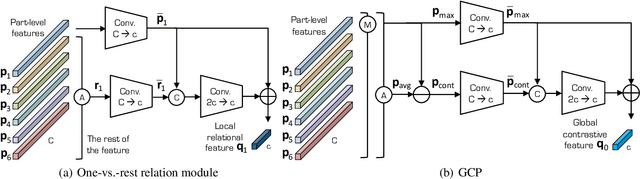
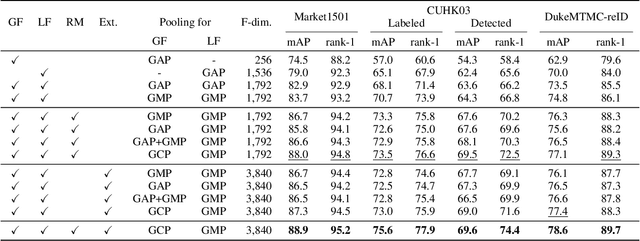
Person re-identification (reID) aims at retrieving an image of the person of interest from a set of images typically captured by multiple cameras. Recent reID methods have shown that exploiting local features describing body parts, together with a global feature of a person image itself, gives robust feature representations, even in the case of missing body parts. However, using the individual part-level features directly, without considering relations between body parts, confuses differentiating identities of different persons having similar attributes in corresponding parts. To address this issue, we propose a new relation network for person reID that considers relations between individual body parts and the rest of them. Our model makes a single part-level feature incorporate partial information of other body parts as well, supporting it to be more discriminative. We also introduce a global contrastive pooling (GCP) method to obtain a global feature of a person image. We propose to use contrastive features for GCP to complement conventional max and averaging pooling techniques. We show that our model outperforms the state of the art on the Market1501, DukeMTMC-reID and CUHK03 datasets, demonstrating the effectiveness of our approach on discriminative person representations.
Continual General Chunking Problem and SyncMap
Jun 16, 2020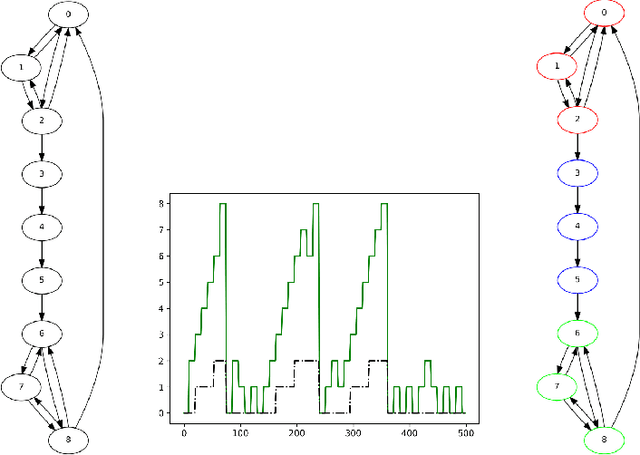
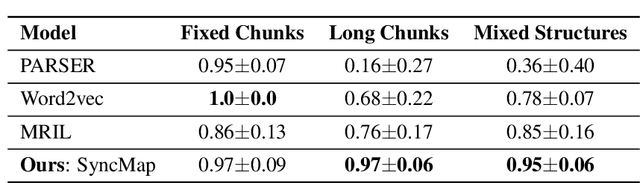
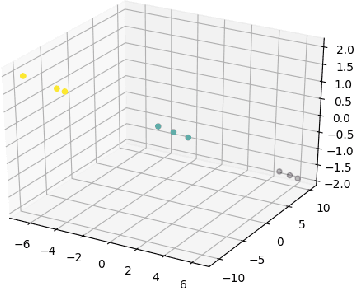
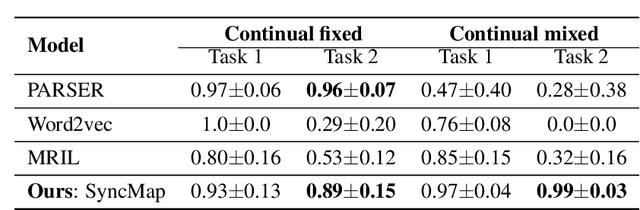
Humans possess an inherent ability to chunk sequences into their constituent parts. In fact, this ability is thought to bootstrap language skills to the learning of image patterns which might be a key to a more animal-like type of intelligence. Here, we propose a continual generalization of the chunking problem (an unsupervised problem), encompassing fixed and probabilistic chunks, discovery of temporal and causal structures and their continual variations. Additionally, we propose an algorithm called SyncMap that can learn and adapt to changes in the problem by creating a dynamic map which preserves the correlation between variables. Results of SyncMap suggest that the proposed algorithm learn near optimal solutions, despite the presence of many types of structures and their continual variation. When compared to Word2vec, PARSER and MRIL, SyncMap surpasses or ties with the best algorithm on $77\%$ of the scenarios while being the second best in the remaing $23\%$.
Enhancing Traffic Scene Predictions with Generative Adversarial Networks
Sep 24, 2019
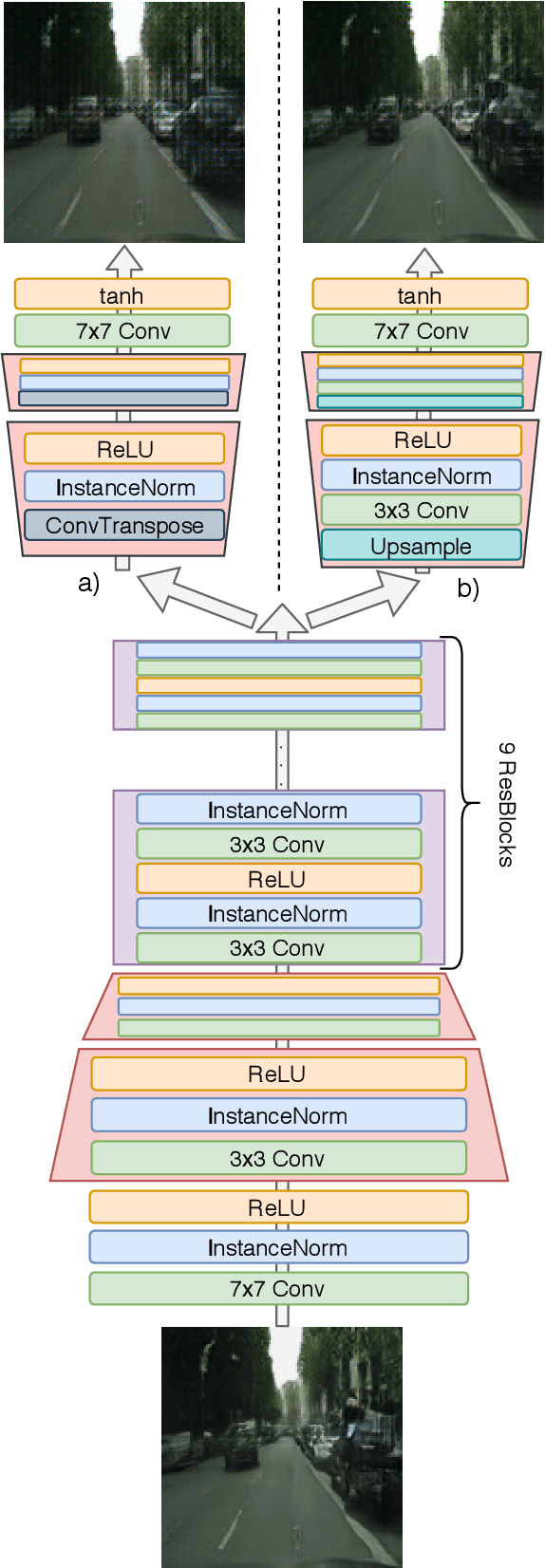

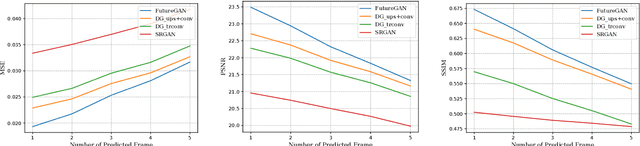
We present a new two-stage pipeline for predicting frames of traffic scenes where relevant objects can still reliably be detected. Using a recent video prediction network, we first generate a sequence of future frames based on past frames. A second network then enhances these frames in order to make them appear more realistic. This ensures the quality of the predicted frames to be sufficient to enable accurate detection of objects, which is especially important for autonomously driving cars. To verify this two-stage approach, we conducted experiments on the Cityscapes dataset. For enhancing, we trained two image-to-image translation methods based on generative adversarial networks, one for blind motion deblurring and one for image super-resolution. All resulting predictions were quantitatively evaluated using both traditional metrics and a state-of-the-art object detection network showing that the enhanced frames appear qualitatively improved. While the traditional image comparison metrics, i.e., MSE, PSNR, and SSIM, failed to confirm this visual impression, the object detection evaluation resembles it well. The best performing prediction-enhancement pipeline is able to increase the average precision values for detecting cars by about 9% for each prediction step, compared to the non-enhanced predictions.
Lesion Harvester: Iteratively Mining Unlabeled Lesions and Hard-Negative Examples at Scale
Jan 28, 2020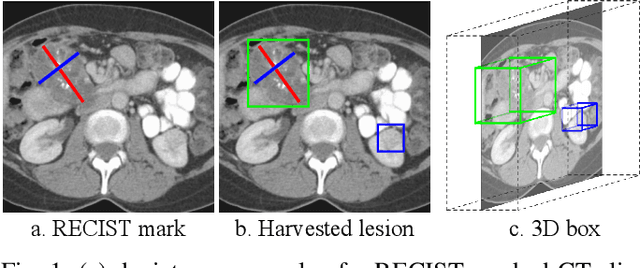
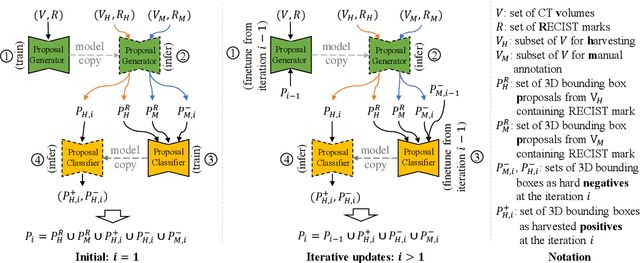
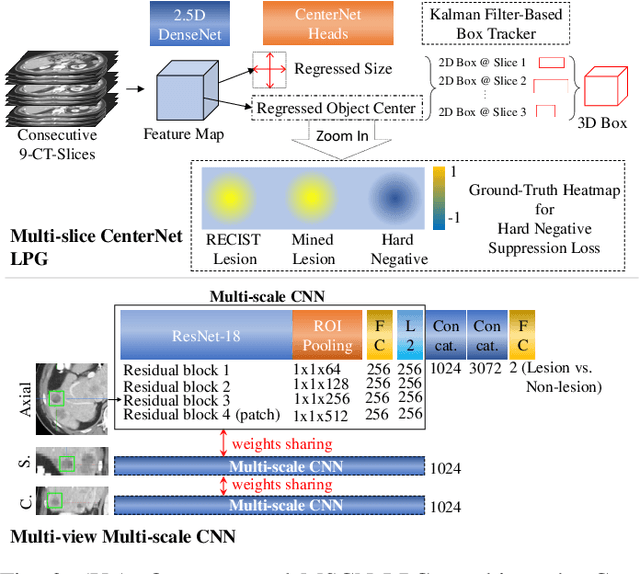
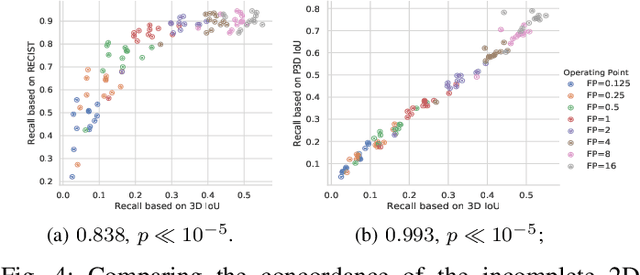
Acquiring large-scale medical image data, necessary for training machine learning algorithms, is frequently intractable, due to prohibitive expert-driven annotation costs. Recent datasets extracted from hospital archives, e.g., DeepLesion, have begun to address this problem. However, these are often incompletely or noisily labeled, e.g., DeepLesion leaves over 50% of its lesions unlabeled. Thus, effective methods to harvest missing annotations are critical for continued progress in medical image analysis. This is the goal of our work, where we develop a powerful system to harvest missing lesions from the DeepLesion dataset at high precision. Accepting the need for some degree of expert labor to achieve high fidelity, we exploit a small fully-labeled subset of medical image volumes and use it to intelligently mine annotations from the remainder. To do this, we chain together a highly sensitive lesion proposal generator and a very selective lesion proposal classifier. While our framework is generic, we optimize our performance by proposing a 3D contextual lesion proposal generator and by using a multi-view multi-scale lesion proposal classifier. These produce harvested and hard-negative proposals, which we then re-use to finetune our proposal generator by using a novel hard negative suppression loss, continuing this process until no extra lesions are found. Extensive experimental analysis demonstrates that our method can harvest an additional 9,805 lesions while keeping precision above 90%. To demonstrate the benefits of our approach, we show that lesion detectors trained on our harvested lesions can significantly outperform the same variants only trained on the original annotations, with boost of average precision of 7% to 10%. We open source our annotations at https://github.com/JimmyCai91/DeepLesionAnnotation.
End-to-end Full Projector Compensation
Aug 04, 2020

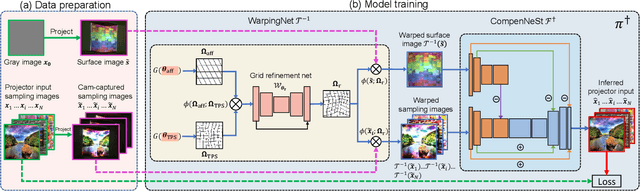

Full projector compensation aims to modify a projector input image to compensate for both geometric and photometric disturbance of the projection surface. Traditional methods usually solve the two parts separately and may suffer from suboptimal solutions. In this paper, we propose the first end-to-end differentiable solution, named CompenNeSt++, to solve the two problems jointly. First, we propose a novel geometric correction subnet, named WarpingNet, which is designed with a cascaded coarse-to-fine structure to learn the sampling grid directly from sampling images. Second, we propose a novel photometric compensation subnet, named CompenNeSt, which is designed with a siamese architecture to capture the photometric interactions between the projection surface and the projected images, and to use such information to compensate the geometrically corrected images. By concatenating WarpingNet with CompenNeSt, CompenNeSt++ accomplishes full projector compensation and is end-to-end trainable. Third, to improve practicability, we propose a novel synthetic data-based pre-training strategy to significantly reduce the number of training images and training time. Moreover, we construct the first setup-independent full compensation benchmark to facilitate future studies. In thorough experiments, our method shows clear advantages over prior art with promising compensation quality and meanwhile being practically convenient.