 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Automatic Data Augmentation via Deep Reinforcement Learning for Effective Kidney Tumor Segmentation
Feb 22, 2020
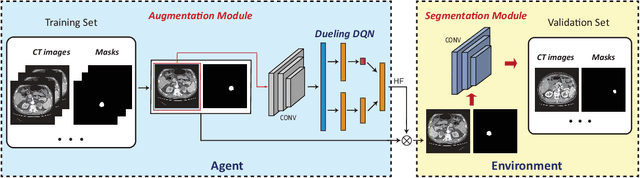
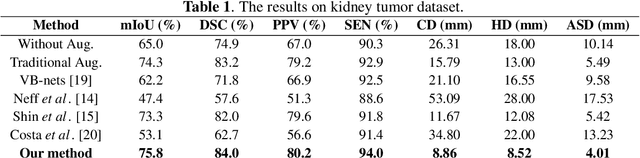
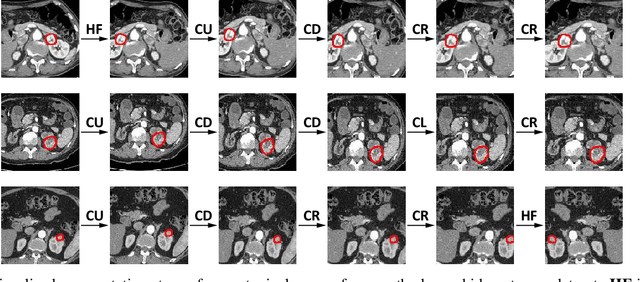
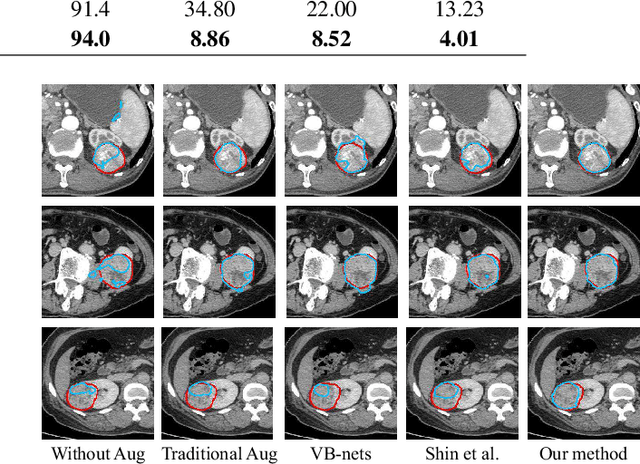
Conventional data augmentation realized by performing simple pre-processing operations (\eg, rotation, crop, \etc) has been validated for its advantage in enhancing the performance for medical image segmentation. However, the data generated by these conventional augmentation methods are random and sometimes harmful to the subsequent segmentation. In this paper, we developed a novel automatic learning-based data augmentation method for medical image segmentation which models the augmentation task as a trial-and-error procedure using deep reinforcement learning (DRL). In our method, we innovatively combine the data augmentation module and the subsequent segmentation module in an end-to-end training manner with a consistent loss. Specifically, the best sequential combination of different basic operations is automatically learned by directly maximizing the performance improvement (\ie, Dice ratio) on the available validation set. We extensively evaluated our method on CT kidney tumor segmentation which validated the promising results of our method.
Fuzzy-Based Dialectical Non-Supervised Image Classification and Clustering
Dec 03, 2017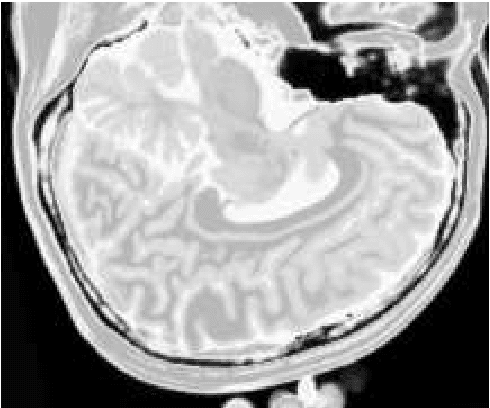
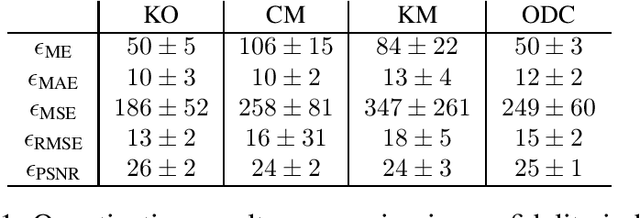
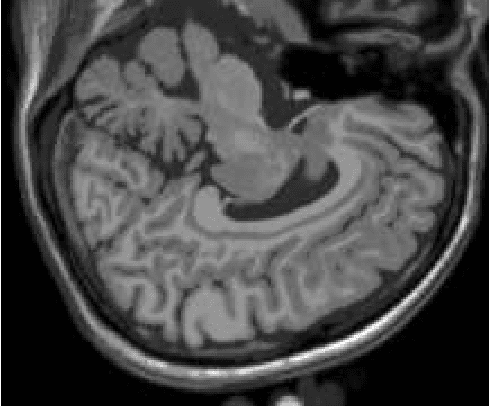
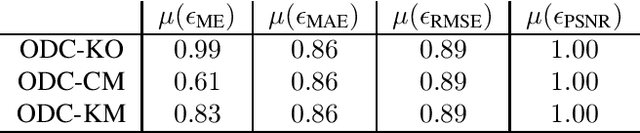
The materialist dialectical method is a philosophical investigative method to analyze aspects of reality. These aspects are viewed as complex processes composed by basic units named poles, which interact with each other. Dialectics has experienced considerable progress in the 19th century, with Hegel's dialectics and, in the 20th century, with the works of Marx, Engels, and Gramsci, in Philosophy and Economics. The movement of poles through their contradictions is viewed as a dynamic process with intertwined phases of evolution and revolutionary crisis. In order to build a computational process based on dialectics, the interaction between poles can be modeled using fuzzy membership functions. Based on this assumption, we introduce the Objective Dialectical Classifier (ODC), a non-supervised map for classification based on materialist dialectics and designed as an extension of fuzzy c-means classifier. As a case study, we used ODC to classify 181 magnetic resonance synthetic multispectral images composed by proton density, $T_1$- and $T_2$-weighted synthetic brain images. Comparing ODC to k-means, fuzzy c-means, and Kohonen's self-organized maps, concerning with image fidelity indexes as estimatives of quantization distortion, we proved that ODC can reach almost the same quantization performance as optimal non-supervised classifiers like Kohonen's self-organized maps.
Dominant Sets for "Constrained" Image Segmentation
Jul 15, 2017
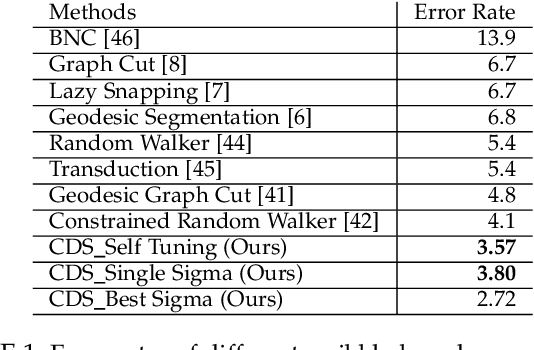

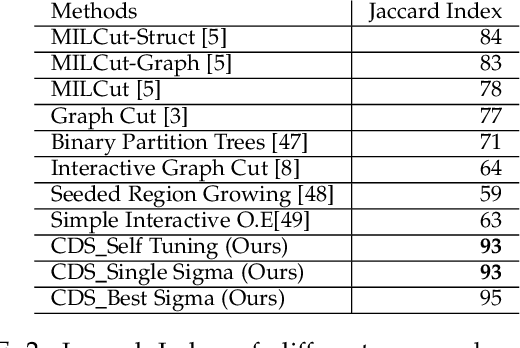
Image segmentation has come a long way since the early days of computer vision, and still remains a challenging task. Modern variations of the classical (purely bottom-up) approach, involve, e.g., some form of user assistance (interactive segmentation) or ask for the simultaneous segmentation of two or more images (co-segmentation). At an abstract level, all these variants can be thought of as "constrained" versions of the original formulation, whereby the segmentation process is guided by some external source of information. In this paper, we propose a new approach to tackle this kind of problems in a unified way. Our work is based on some properties of a family of quadratic optimization problems related to dominant sets, a well-known graph-theoretic notion of a cluster which generalizes the concept of a maximal clique to edge-weighted graphs. In particular, we show that by properly controlling a regularization parameter which determines the structure and the scale of the underlying problem, we are in a position to extract groups of dominant-set clusters that are constrained to contain predefined elements. In particular, we shall focus on interactive segmentation and co-segmentation (in both the unsupervised and the interactive versions). The proposed algorithm can deal naturally with several type of constraints and input modality, including scribbles, sloppy contours, and bounding boxes, and is able to robustly handle noisy annotations on the part of the user. Experiments on standard benchmark datasets show the effectiveness of our approach as compared to state-of-the-art algorithms on a variety of natural images under several input conditions and constraints.
Interactive Image Segmentation From A Feedback Control Perspective
Sep 26, 2016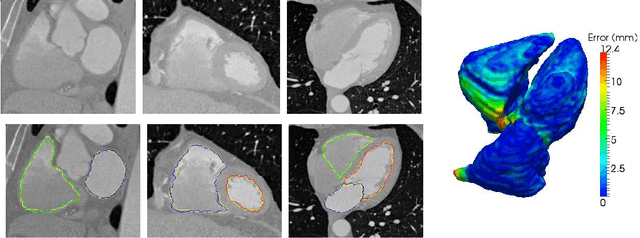
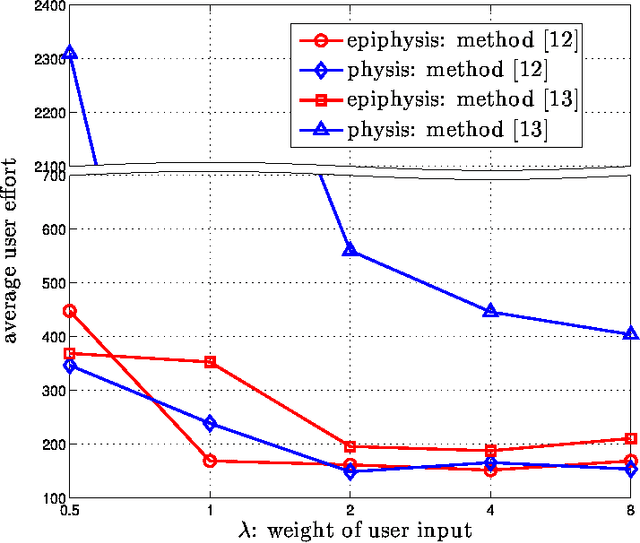
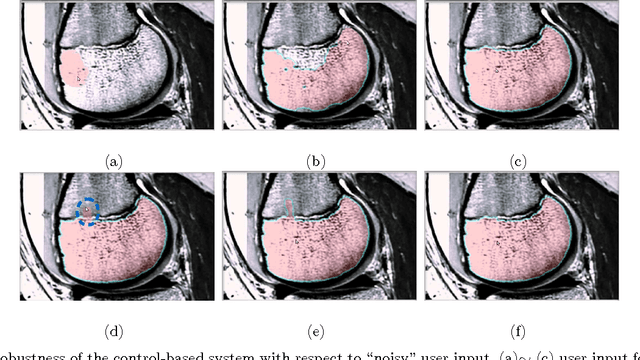

Image segmentation is a fundamental problem in computational vision and medical imaging. Designing a generic, automated method that works for various objects and imaging modalities is a formidable task. Instead of proposing a new specific segmentation algorithm, we present a general design principle on how to integrate user interactions from the perspective of feedback control theory. Impulsive control and Lyapunov stability analysis are employed to design and analyze an interactive segmentation system. Then stabilization conditions are derived to guide algorithm design. Finally, the effectiveness and robustness of proposed method are demonstrated.
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
Jun 07, 2016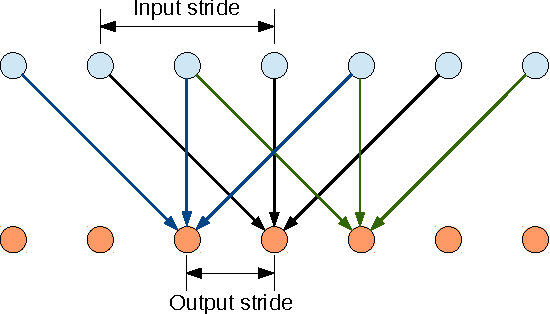

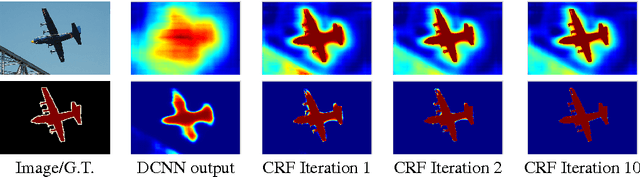

Deep Convolutional Neural Networks (DCNNs) have recently shown state of the art performance in high level vision tasks, such as image classification and object detection. This work brings together methods from DCNNs and probabilistic graphical models for addressing the task of pixel-level classification (also called "semantic image segmentation"). We show that responses at the final layer of DCNNs are not sufficiently localized for accurate object segmentation. This is due to the very invariance properties that make DCNNs good for high level tasks. We overcome this poor localization property of deep networks by combining the responses at the final DCNN layer with a fully connected Conditional Random Field (CRF). Qualitatively, our "DeepLab" system is able to localize segment boundaries at a level of accuracy which is beyond previous methods. Quantitatively, our method sets the new state-of-art at the PASCAL VOC-2012 semantic image segmentation task, reaching 71.6% IOU accuracy in the test set. We show how these results can be obtained efficiently: Careful network re-purposing and a novel application of the 'hole' algorithm from the wavelet community allow dense computation of neural net responses at 8 frames per second on a modern GPU.
PatternNet: A Benchmark Dataset for Performance Evaluation of Remote Sensing Image Retrieval
Jul 10, 2017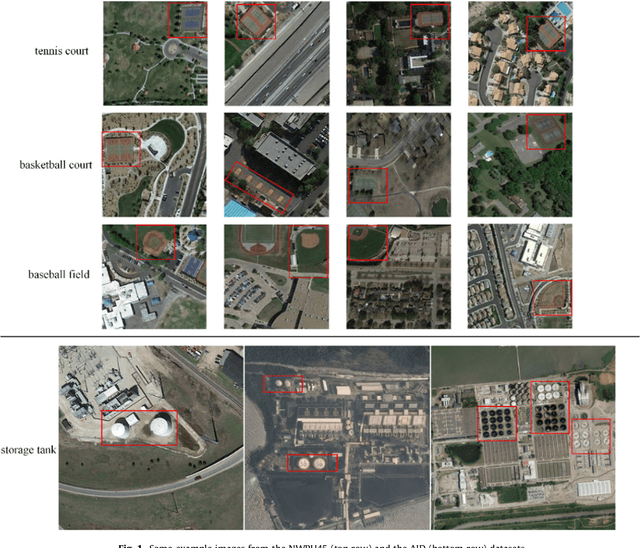

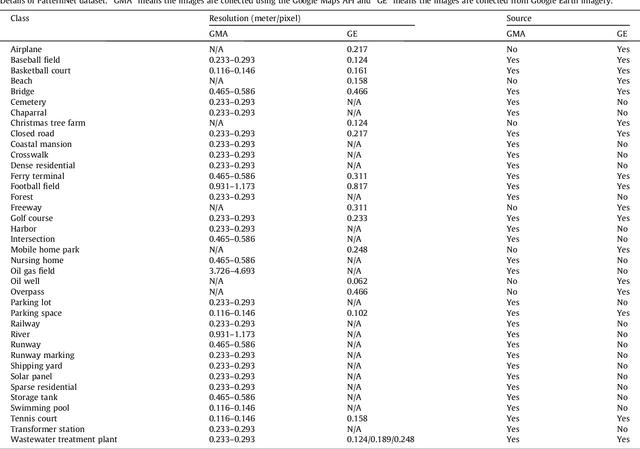

Remote sensing image retrieval(RSIR), which aims to efficiently retrieve data of interest from large collections of remote sensing data, is a fundamental task in remote sensing. Over the past several decades, there has been significant effort to extract powerful feature representations for this task since the retrieval performance depends on the representative strength of the features. Benchmark datasets are also critical for developing, evaluating, and comparing RSIR approaches. Current benchmark datasets are deficient in that 1) they were originally collected for land use/land cover classification and not image retrieval, 2) they are relatively small in terms of the number of classes as well the number of sample images per class, and 3) the retrieval performance has saturated. These limitations have severely restricted the development of novel feature representations for RSIR, particularly the recent deep-learning based features which require large amounts of training data. We therefore present in this paper, a new large-scale remote sensing dataset termed "PatternNet" that was collected specifically for RSIR. PatternNet was collected from high-resolution imagery and contains 38 classes with 800 images per class. We also provide a thorough review of RSIR approaches ranging from traditional handcrafted feature based methods to recent deep learning based ones. We evaluate over 35 methods to establish extensive baseline results for future RSIR research using the PatternNet benchmark.
Burst Denoising of Dark Images
Mar 17, 2020
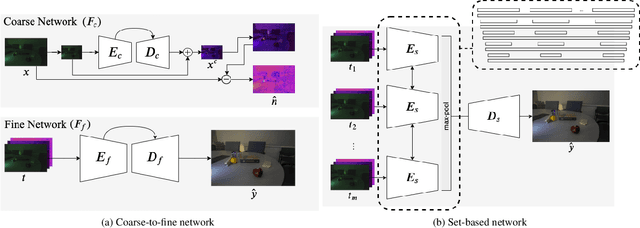
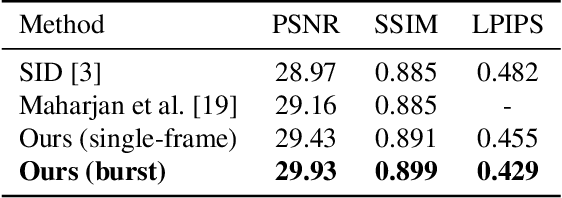

Capturing images under extremely low-light conditions poses significant challenges for the standard camera pipeline. Images become too dark and too noisy, which makes traditional image enhancement techniques almost impossible to apply. Very recently, researchers have shown promising results using learning based approaches. Motivated by these ideas, in this paper, we propose a deep learning framework for obtaining clean and colorful RGB images from extremely dark raw images. The backbone of our framework is a novel coarse-to-fine network architecture that generates high-quality outputs in a progressive manner. The coarse network predicts a low-resolution, denoised raw image, which is then fed to the fine network to recover fine-scale details and realistic textures. To further reduce noise and improve color accuracy, we extend this network to a permutation invariant structure so that it takes a burst of low-light images as input and merges information from multiple images at the feature-level. Our experiments demonstrate that the proposed approach leads to perceptually more pleasing results than state-of-the-art methods by producing much sharper and higher quality images.
Two-shot Spatially-varying BRDF and Shape Estimation
Apr 01, 2020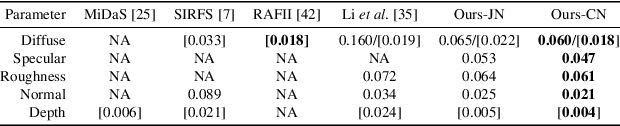
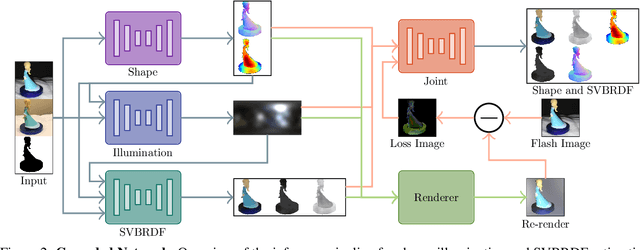
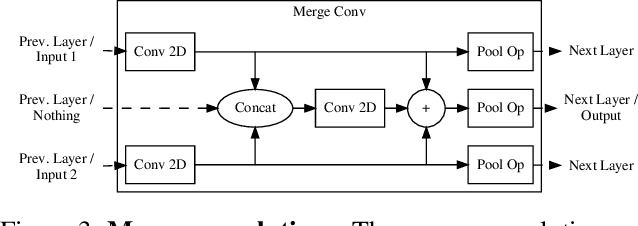

Capturing the shape and spatially-varying appearance (SVBRDF) of an object from images is a challenging task that has applications in both computer vision and graphics. Traditional optimization-based approaches often need a large number of images taken from multiple views in a controlled environment. Newer deep learning-based approaches require only a few input images, but the reconstruction quality is not on par with optimization techniques. We propose a novel deep learning architecture with a stage-wise estimation of shape and SVBRDF. The previous predictions guide each estimation, and a joint refinement network later refines both SVBRDF and shape. We follow a practical mobile image capture setting and use unaligned two-shot flash and no-flash images as input. Both our two-shot image capture and network inference can run on mobile hardware. We also create a large-scale synthetic training dataset with domain-randomized geometry and realistic materials. Extensive experiments on both synthetic and real-world datasets show that our network trained on a synthetic dataset can generalize well to real-world images. Comparisons with recent approaches demonstrate the superior performance of the proposed approach.
3D Solid Spherical Bispectrum CNNs for Biomedical Texture Analysis
Apr 28, 2020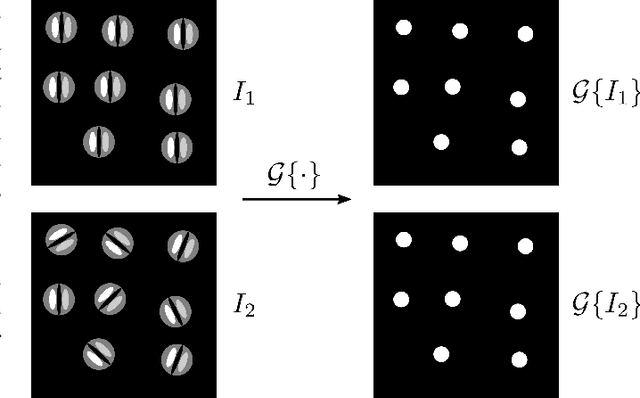
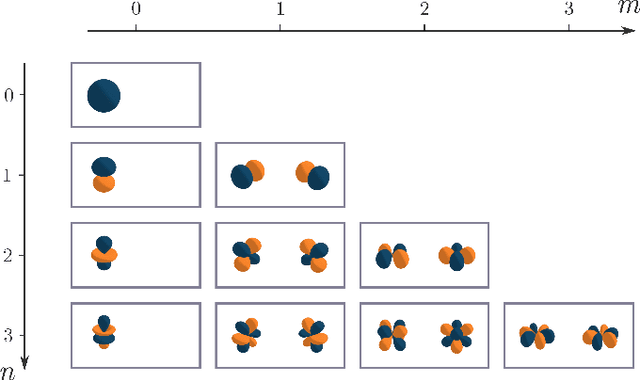
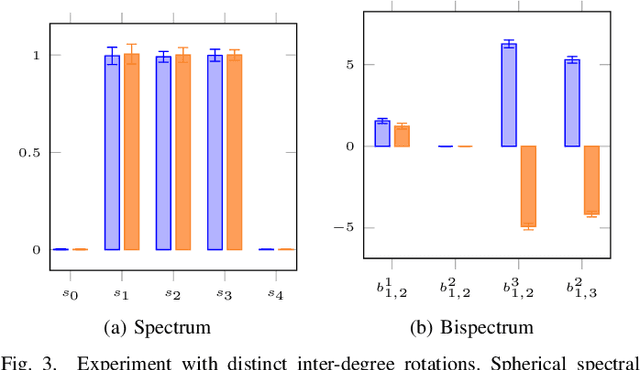
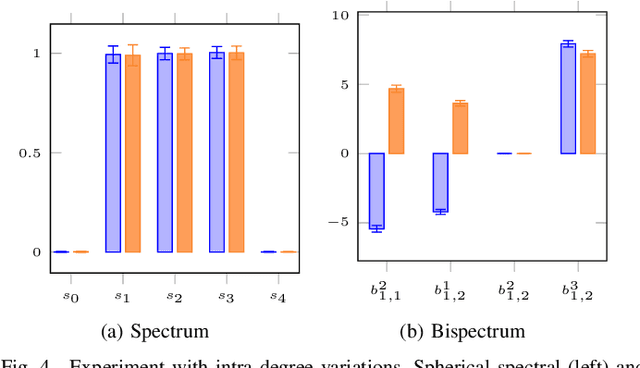
Locally Rotation Invariant (LRI) operators have shown great potential in biomedical texture analysis where patterns appear at random positions and orientations. LRI operators can be obtained by computing the responses to the discrete rotation of local descriptors, such as Local Binary Patterns (LBP) or the Scale Invariant Feature Transform (SIFT). Other strategies achieve this invariance using Laplacian of Gaussian or steerable wavelets for instance, preventing the introduction of sampling errors during the discretization of the rotations. In this work, we obtain LRI operators via the local projection of the image on the spherical harmonics basis, followed by the computation of the bispectrum, which shares and extends the invariance properties of the spectrum. We investigate the benefits of using the bispectrum over the spectrum in the design of a LRI layer embedded in a shallow Convolutional Neural Network (CNN) for 3D image analysis. The performance of each design is evaluated on two datasets and compared against a standard 3D CNN. The first dataset is made of 3D volumes composed of synthetically generated rotated patterns, while the second contains malignant and benign pulmonary nodules in Computed Tomography (CT) images. The results indicate that bispectrum CNNs allows for a significantly better characterization of 3D textures than both the spectral and standard CNN. In addition, it can efficiently learn with fewer training examples and trainable parameters when compared to a standard convolutional layer.
Simulation of an Elevator Group Control Using Generative Adversarial Networks and Related AI Tools
Sep 03, 2020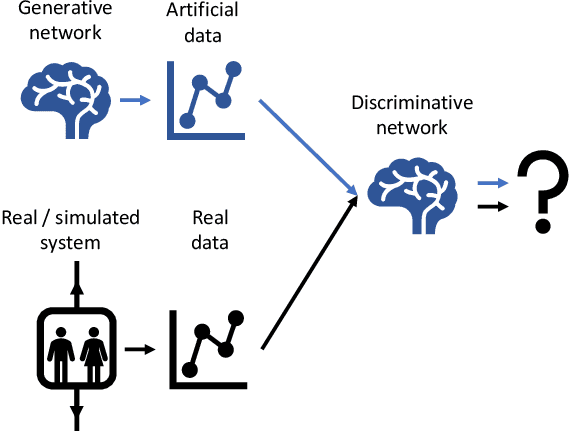

Testing new, innovative technologies is a crucial task for safety and acceptance. But how can new systems be tested if no historical real-world data exist? Simulation provides an answer to this important question. Classical simulation tools such as event-based simulation are well accepted. But most of these established simulation models require the specification of many parameters. Furthermore, simulation runs, e.g., CFD simulations, are very time consuming. Generative Adversarial Networks (GANs) are powerful tools for generating new data for a variety of tasks. Currently, their most frequent application domain is image generation. This article investigates the applicability of GANs for imitating simulations. We are comparing the simulation output of a technical system with the output of a GAN. To exemplify this approach, a well-known multi-car elevator system simulator was chosen. Our study demonstrates the feasibility of this approach. It also discusses pitfalls and technical problems that occurred during the implementation. Although we were able to show that in principle, GANs can be used as substitutes for expensive simulation runs, we also show that they cannot be used "out of the box". Fine tuning is needed. We present a proof-of-concept, which can serve as a starting point for further research.