 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Human-Object Interaction Detection:A Quick Survey and Examination of Methods
Sep 27, 2020
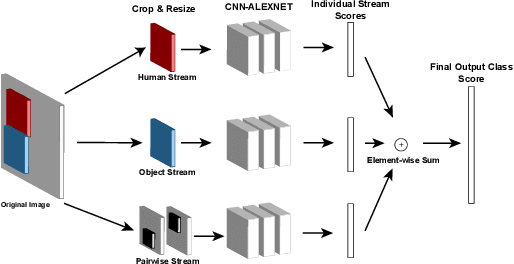
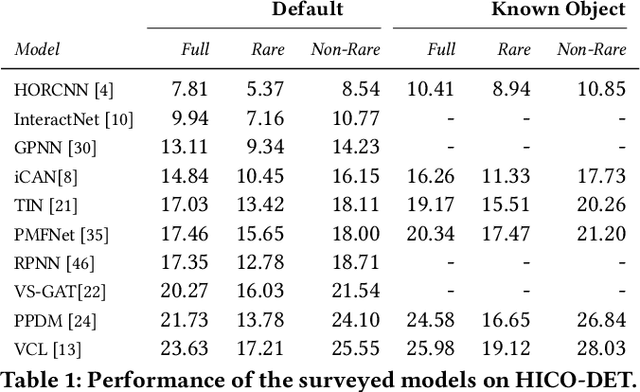
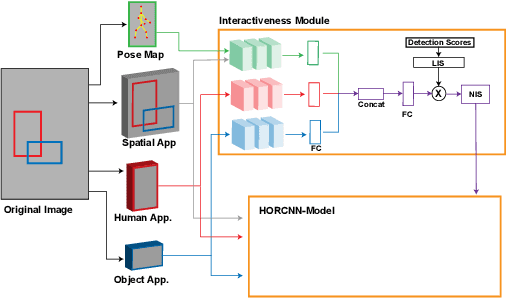

Human-object interaction detection is a relatively new task in the world of computer vision and visual semantic information extraction. With the goal of machines identifying interactions that humans perform on objects, there are many real-world use cases for the research in this field. To our knowledge, this is the first general survey of the state-of-the-art and milestone works in this field. We provide a basic survey of the developments in the field of human-object interaction detection. Many works in this field use multi-stream convolutional neural network architectures, which combine features from multiple sources in the input image. Most commonly these are the humans and objects in question, as well as the spatial quality of the two. As far as we are aware, there have not been in-depth studies performed that look into the performance of each component individually. In order to provide insight to future researchers, we perform an individualized study that examines the performance of each component of a multi-stream convolutional neural network architecture for human-object interaction detection. Specifically, we examine the HORCNN architecture as it is a foundational work in the field. In addition, we provide an in-depth look at the HICO-DET dataset, a popular benchmark in the field of human-object interaction detection. Code and papers can be found at https://github.com/SHI-Labs/Human-Object-Interaction-Detection.
Deep Neural Network for 3D Surface Segmentation based on Contour Tree Hierarchy
Aug 25, 2020
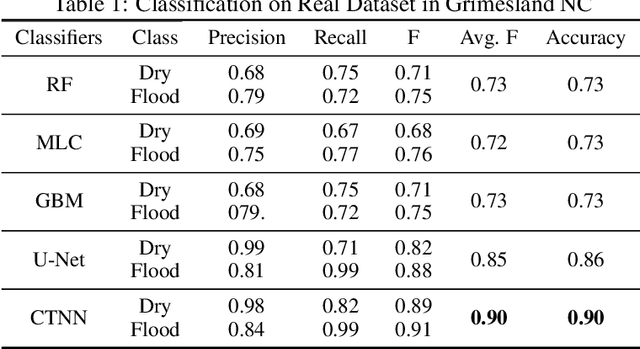
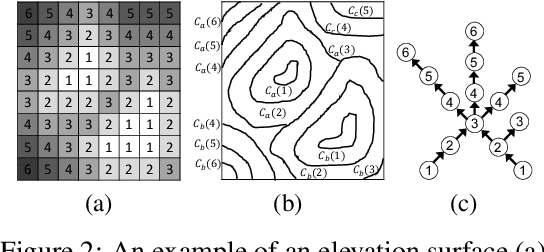
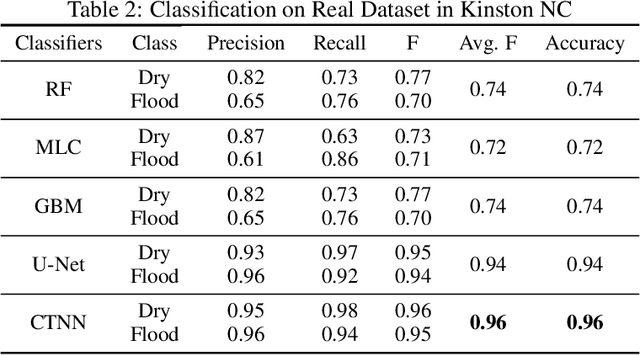
Given a 3D surface defined by an elevation function on a 2D grid as well as non-spatial features observed at each pixel, the problem of surface segmentation aims to classify pixels into contiguous classes based on both non-spatial features and surface topology. The problem has important applications in hydrology, planetary science, and biochemistry but is uniquely challenging for several reasons. First, the spatial extent of class segments follows surface contours in the topological space, regardless of their spatial shapes and directions. Second, the topological structure exists in multiple spatial scales based on different surface resolutions. Existing widely successful deep learning models for image segmentation are often not applicable due to their reliance on convolution and pooling operations to learn regular structural patterns on a grid. In contrast, we propose to represent surface topological structure by a contour tree skeleton, which is a polytree capturing the evolution of surface contours at different elevation levels. We further design a graph neural network based on the contour tree hierarchy to model surface topological structure at different spatial scales. Experimental evaluations based on real-world hydrological datasets show that our model outperforms several baseline methods in classification accuracy.
Cardiac MR Image Segmentation Techniques: an overview
Feb 14, 2015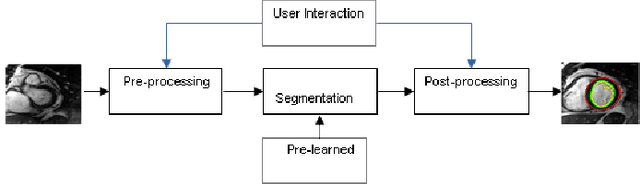
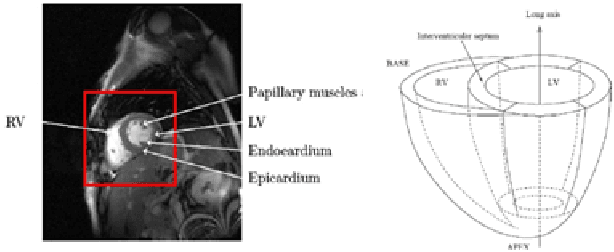
Broadly speaking, the objective in cardiac image segmentation is to delineate the outer and inner walls of the heart to segment out either the entire or parts of the organ boundaries. This paper will focus on MR images as they are the most widely used in cardiac segmentation -- as a result of the accurate morphological information and better soft tissue contrast they provide. This cardiac segmentation information is very useful as it eases physical measurements that provides useful metrics for cardiac diagnosis such as infracted volumes, ventricular volumes, ejection fraction, myocardial mass, cardiac movement, and the like. But, this task is difficult due to the intensity and texture similarities amongst the different cardiac and background structures on top of some noisy artifacts present in MR images. Thus far, various researchers have proposed different techniques to solve some of the pressing issues. This seminar paper presents an overview of representative medical image segmentation techniques. The paper also highlights preferred approaches for segmentation of the four cardiac chambers: the left ventricle (LV), right ventricle (RV), left atrium (LA) and right atrium (RA), on short axis image planes.
A Multimodal Memes Classification: A Survey and Open Research Issues
Sep 17, 2020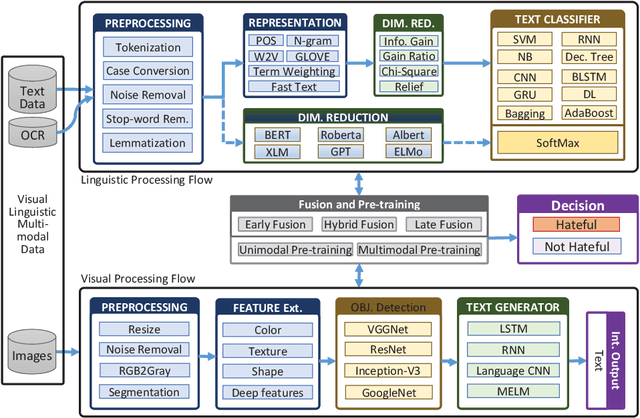
Memes are graphics and text overlapped so that together they present concepts that become dubious if one of them is absent. It is spread mostly on social media platforms, in the form of jokes, sarcasm, motivating, etc. After the success of BERT in Natural Language Processing (NLP), researchers inclined to Visual-Linguistic (VL) multimodal problems like memes classification, image captioning, Visual Question Answering (VQA), and many more. Unfortunately, many memes get uploaded each day on social media platforms that need automatic censoring to curb misinformation and hate. Recently, this issue has attracted the attention of researchers and practitioners. State-of-the-art methods that performed significantly on other VL dataset, tends to fail on memes classification. In this context, this work aims to conduct a comprehensive study on memes classification, generally on the VL multimodal problems and cutting edge solutions. We propose a generalized framework for VL problems. We cover the early and next-generation works on VL problems. Finally, we identify and articulate several open research issues and challenges. This is the first study that presents the generalized view of the advanced classification techniques concerning memes classification to the best of our knowledge. We believe this study presents a clear road-map for the Machine Learning (ML) research community to implement and enhance memes classification techniques.
Semi-Supervised Semantic Segmentation in Earth Observation: The MiniFrance Suite, Dataset Analysis and Multi-task Network Study
Oct 15, 2020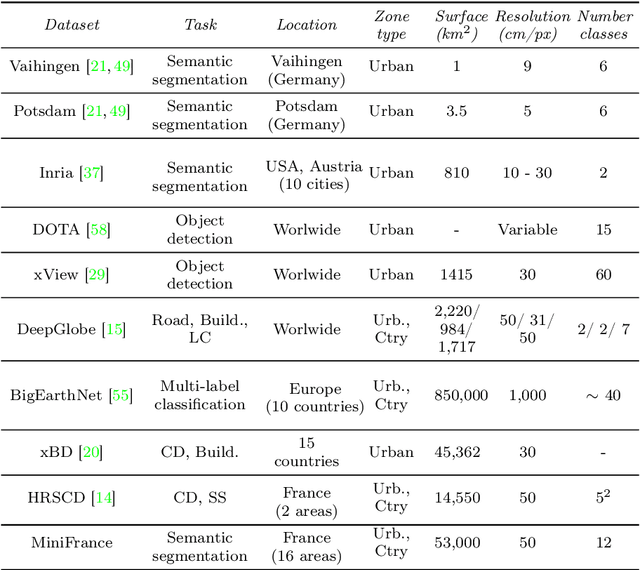
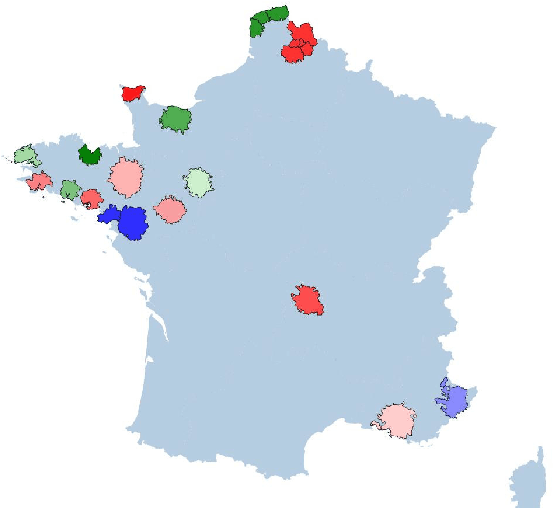
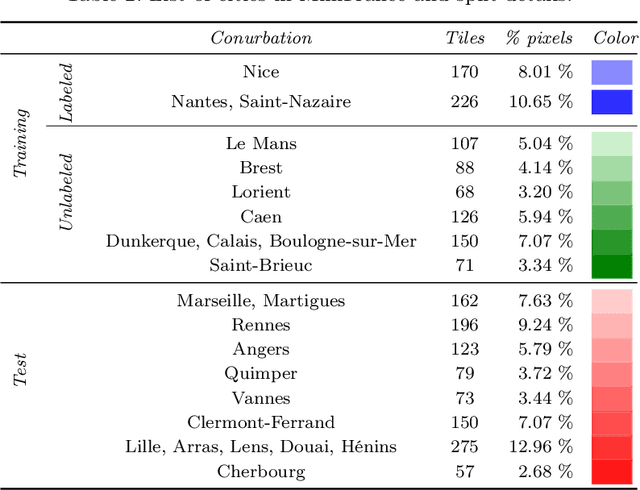
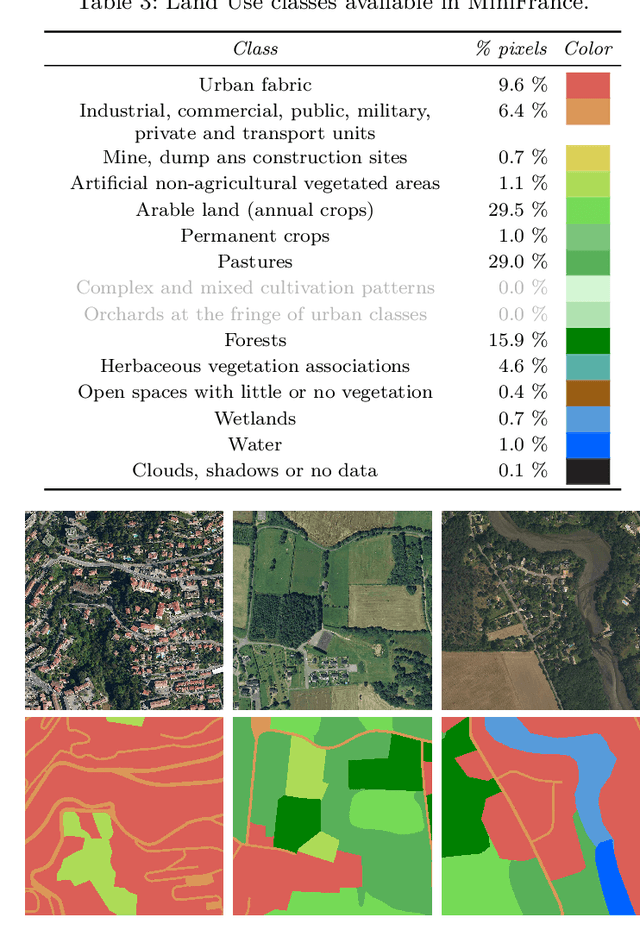
The development of semi-supervised learning techniques is essential to enhance the generalization capacities of machine learning algorithms. Indeed, raw image data are abundant while labels are scarce, therefore it is crucial to leverage unlabeled inputs to build better models. The availability of large databases have been key for the development of learning algorithms with high level performance. Despite the major role of machine learning in Earth Observation to derive products such as land cover maps, datasets in the field are still limited, either because of modest surface coverage, lack of variety of scenes or restricted classes to identify. We introduce a novel large-scale dataset for semi-supervised semantic segmentation in Earth Observation, the MiniFrance suite. MiniFrance has several unprecedented properties: it is large-scale, containing over 2000 very high resolution aerial images, accounting for more than 200 billions samples (pixels); it is varied, covering 16 conurbations in France, with various climates, different landscapes, and urban as well as countryside scenes; and it is challenging, considering land use classes with high-level semantics. Nevertheless, the most distinctive quality of MiniFrance is being the only dataset in the field especially designed for semi-supervised learning: it contains labeled and unlabeled images in its training partition, which reproduces a life-like scenario. Along with this dataset, we present tools for data representativeness analysis in terms of appearance similarity and a thorough study of MiniFrance data, demonstrating that it is suitable for learning and generalizes well in a semi-supervised setting. Finally, we present semi-supervised deep architectures based on multi-task learning and the first experiments on MiniFrance.
On the Comparison of Classic and Deep Keypoint Detector and Descriptor Methods
Jul 29, 2020
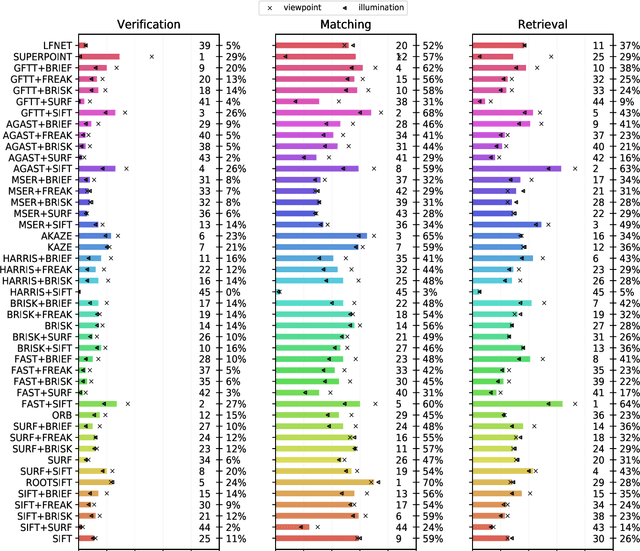
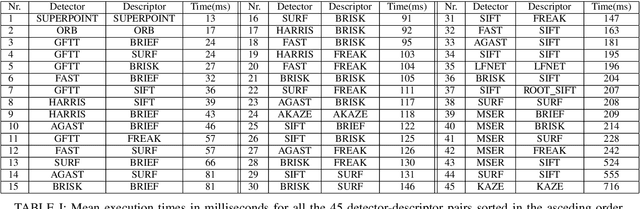
The purpose of this study is to give a performance comparison between several classic hand-crafted and deep key-point detector and descriptor methods. In particular, we consider the following classical algorithms: SIFT, SURF, ORB, FAST, BRISK, MSER, HARRIS, KAZE, AKAZE, AGAST, GFTT, FREAK, BRIEF and RootSIFT, where a subset of all combinations is paired into detector-descriptor pipelines. Additionally, we analyze the performance of two recent and perspective deep detector-descriptor models, LF-Net and SuperPoint. Our benchmark relies on the HPSequences dataset that provides real and diverse images under various geometric and illumination changes. We analyze the performance on three evaluation tasks: keypoint verification, image matching and keypoint retrieval. The results show that certain classic and deep approaches are still comparable, with some classic detector-descriptor combinations overperforming pretrained deep models. In terms of the execution times of tested implementations, SuperPoint model is the fastest, followed by ORB. The source code is published on \url{https://github.com/kristijanbartol/keypoint-algorithms-benchmark}.
Solving the Blind Perspective-n-Point Problem End-To-End With Robust Differentiable Geometric Optimization
Jul 29, 2020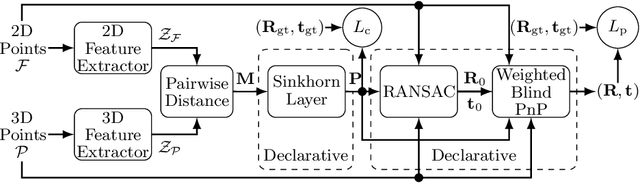
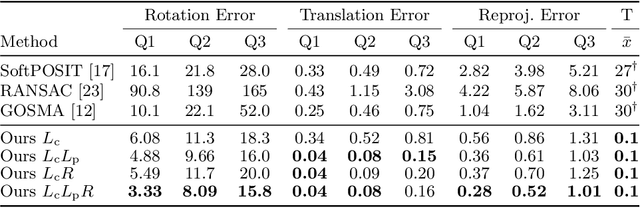
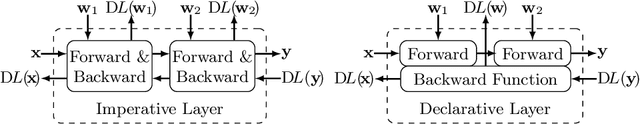
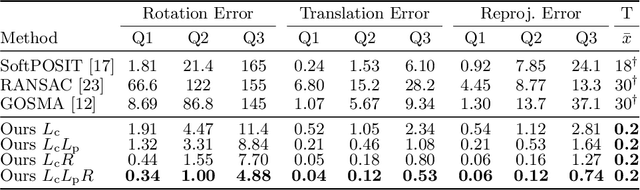
Blind Perspective-n-Point (PnP) is the problem of estimating the position and orientation of a camera relative to a scene, given 2D image points and 3D scene points, without prior knowledge of the 2D-3D correspondences. Solving for pose and correspondences simultaneously is extremely challenging since the search space is very large. Fortunately it is a coupled problem: the pose can be found easily given the correspondences and vice versa. Existing approaches assume that noisy correspondences are provided, that a good pose prior is available, or that the problem size is small. We instead propose the first fully end-to-end trainable network for solving the blind PnP problem efficiently and globally, that is, without the need for pose priors. We make use of recent results in differentiating optimization problems to incorporate geometric model fitting into an end-to-end learning framework, including Sinkhorn, RANSAC and PnP algorithms. Our proposed approach significantly outperforms other methods on synthetic and real data.
Mask-guided sample selection for Semi-Supervised Instance Segmentation
Aug 25, 2020
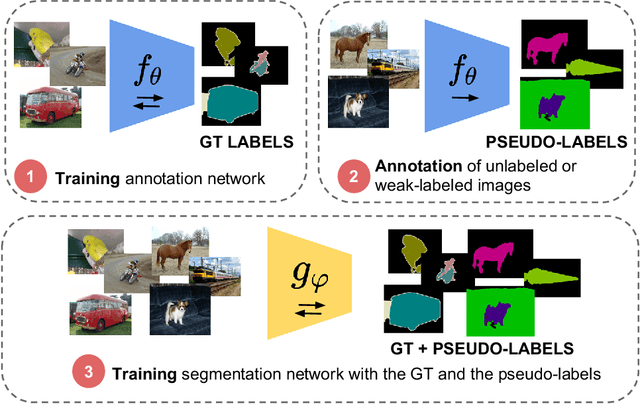
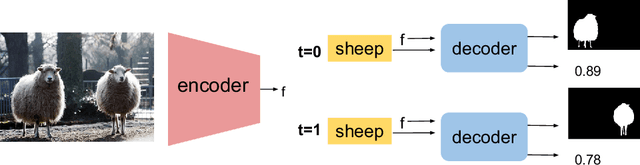
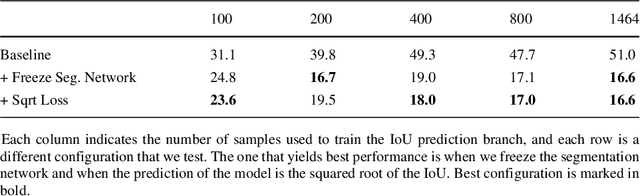
Image segmentation methods are usually trained with pixel-level annotations, which require significant human effort to collect. The most common solution to address this constraint is to implement weakly-supervised pipelines trained with lower forms of supervision, such as bounding boxes or scribbles. Another option are semi-supervised methods, which leverage a large amount of unlabeled data and a limited number of strongly-labeled samples. In this second setup, samples to be strongly-annotated can be selected randomly or with an active learning mechanism that chooses the ones that will maximize the model performance. In this work, we propose a sample selection approach to decide which samples to annotate for semi-supervised instance segmentation. Our method consists in first predicting pseudo-masks for the unlabeled pool of samples, together with a score predicting the quality of the mask. This score is an estimate of the Intersection Over Union (IoU) of the segment with the ground truth mask. We study which samples are better to annotate given the quality score, and show how our approach outperforms a random selection, leading to improved performance for semi-supervised instance segmentation with low annotation budgets.
Segmentation-by-Detection: A Cascade Network for Volumetric Medical Image Segmentation
Oct 31, 2017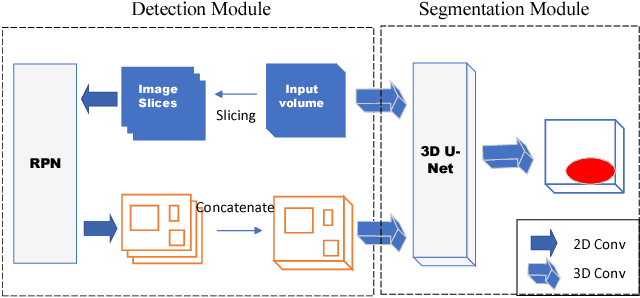
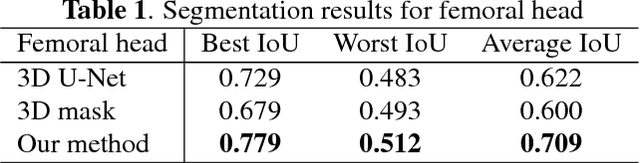
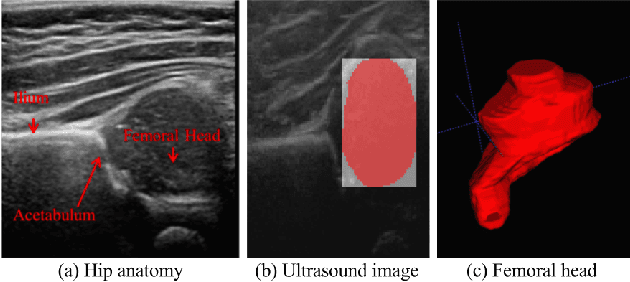
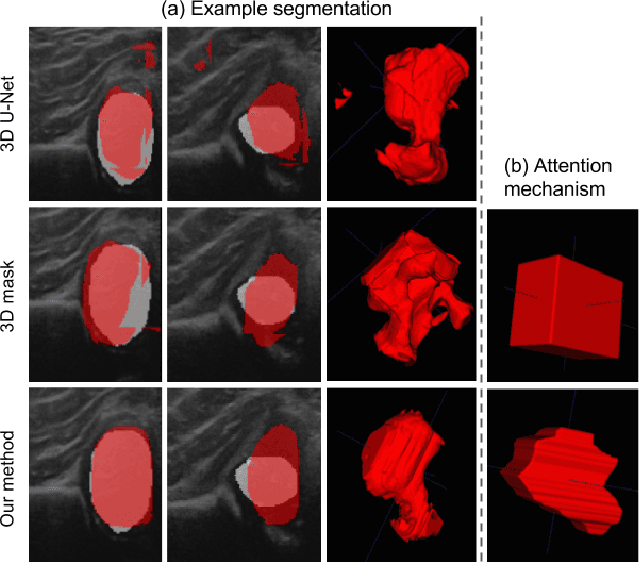
We propose an attention mechanism for 3D medical image segmentation. The method, named segmentation-by-detection, is a cascade of a detection module followed by a segmentation module. The detection module enables a region of interest to come to attention and produces a set of object region candidates which are further used as an attention model. Rather than dealing with the entire volume, the segmentation module distills the information from the potential region. This scheme is an efficient solution for volumetric data as it reduces the influence of the surrounding noise which is especially important for medical data with low signal-to-noise ratio. Experimental results on 3D ultrasound data of the femoral head shows superiority of the proposed method when compared with a standard fully convolutional network like the U-Net.
Uncertainty-Aware Weakly Supervised Action Detection from Untrimmed Videos
Jul 21, 2020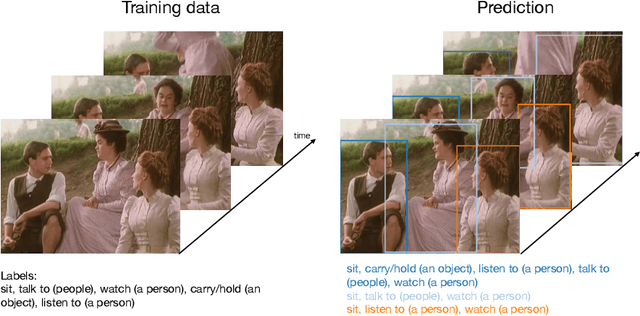
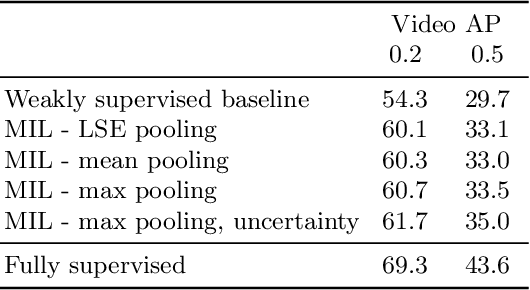
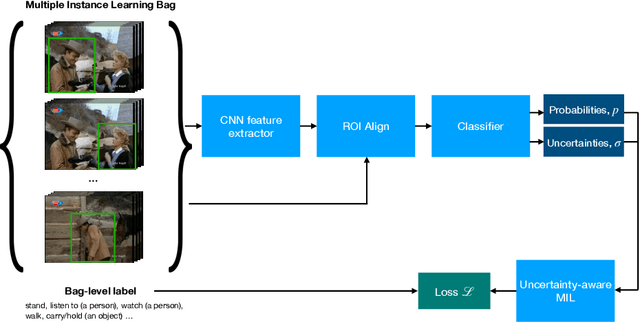

Despite the recent advances in video classification, progress in spatio-temporal action recognition has lagged behind. A major contributing factor has been the prohibitive cost of annotating videos frame-by-frame. In this paper, we present a spatio-temporal action recognition model that is trained with only video-level labels, which are significantly easier to annotate. Our method leverages per-frame person detectors which have been trained on large image datasets within a Multiple Instance Learning framework. We show how we can apply our method in cases where the standard Multiple Instance Learning assumption, that each bag contains at least one instance with the specified label, is invalid using a novel probabilistic variant of MIL where we estimate the uncertainty of each prediction. Furthermore, we report the first weakly-supervised results on the AVA dataset and state-of-the-art results among weakly-supervised methods on UCF101-24.