 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Framework based on Deep Neural Networks to Extract Anatomy of Mosquitoes from Images
Jul 29, 2020
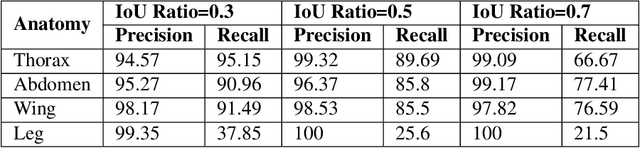
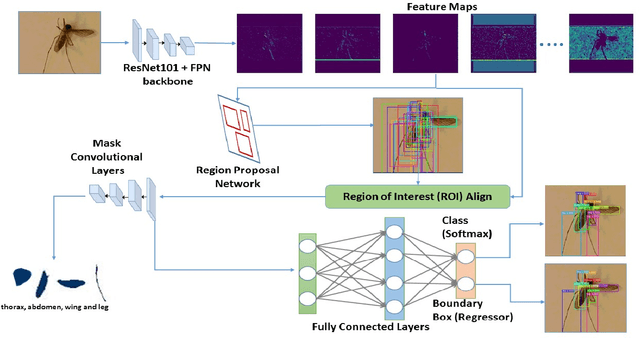
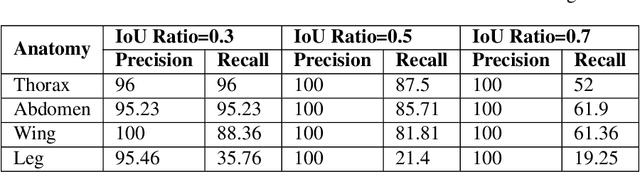

We design a framework based on Mask Region-based Convolutional Neural Network (Mask R-CNN) to automatically detect and separately extract anatomical components of mosquitoes - thorax, wings, abdomen and legs from images. Our training dataset consisted of 1500 smartphone images of nine mosquito species trapped in Florida. In the proposed technique, the first step is to detect anatomical components within a mosquito image. Then, we localize and classify the extracted anatomical components, while simultaneously adding a branch in the neural network architecture to segment pixels containing only the anatomical components. Evaluation results are favorable. To evaluate generality, we test our architecture trained only with mosquito images on bumblebee images. We again reveal favorable results, particularly in extracting wings. Our techniques in this paper have practical applications in public health, taxonomy and citizen-science efforts.
A Robust Attentional Framework for License Plate Recognition in the Wild
Jun 09, 2020

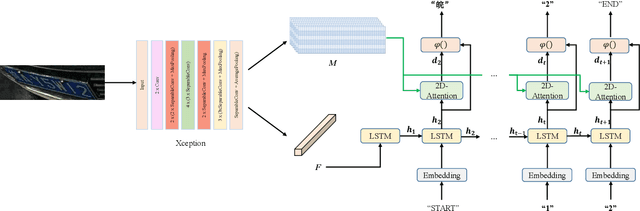
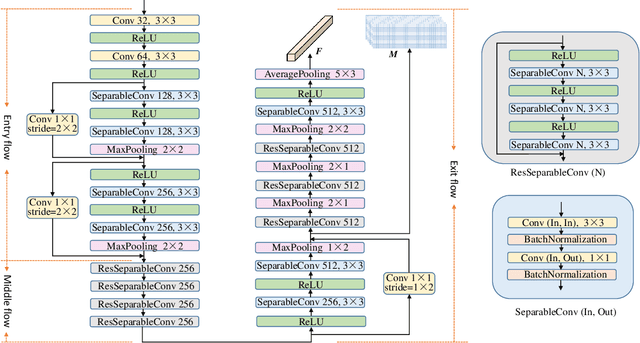
Recognizing car license plates in natural scene images is an important yet still challenging task in realistic applications. Many existing approaches perform well for license plates collected under constrained conditions, eg, shooting in frontal and horizontal view-angles and under good lighting conditions. However, their performance drops significantly in an unconstrained environment that features rotation, distortion, occlusion, blurring, shading or extreme dark or bright conditions. In this work, we propose a robust framework for license plate recognition in the wild. It is composed of a tailored CycleGAN model for license plate image generation and an elaborate designed image-to-sequence network for plate recognition. On one hand, the CycleGAN based plate generation engine alleviates the exhausting human annotation work. Massive amount of training data can be obtained with a more balanced character distribution and various shooting conditions, which helps to boost the recognition accuracy to a large extent. On the other hand, the 2D attentional based license plate recognizer with an Xception-based CNN encoder is capable of recognizing license plates with different patterns under various scenarios accurately and robustly. Without using any heuristics rule or post-processing, our method achieves the state-of-the-art performance on four public datasets, which demonstrates the generality and robustness of our framework. Moreover, we released a new license plate dataset, named "CLPD", with 1200 images from all 31 provinces in mainland China. The dataset can be available from: https://github.com/wangpengnorman/CLPD_dataset.
Circumventing Outliers of AutoAugment with Knowledge Distillation
Mar 25, 2020
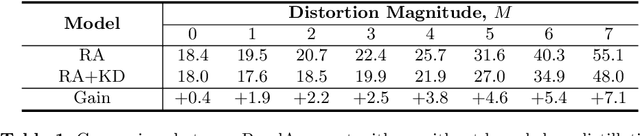
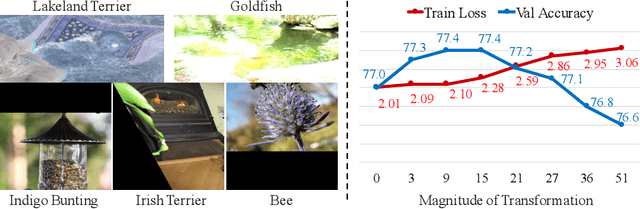

AutoAugment has been a powerful algorithm that improves the accuracy of many vision tasks, yet it is sensitive to the operator space as well as hyper-parameters, and an improper setting may degenerate network optimization. This paper delves deep into the working mechanism, and reveals that AutoAugment may remove part of discriminative information from the training image and so insisting on the ground-truth label is no longer the best option. To relieve the inaccuracy of supervision, we make use of knowledge distillation that refers to the output of a teacher model to guide network training. Experiments are performed in standard image classification benchmarks, and demonstrate the effectiveness of our approach in suppressing noise of data augmentation and stabilizing training. Upon the cooperation of knowledge distillation and AutoAugment, we claim the new state-of-the-art on ImageNet classification with a top-1 accuracy of 85.8%.
Learned Fine-Tuner for Incongruous Few-Shot Learning
Sep 29, 2020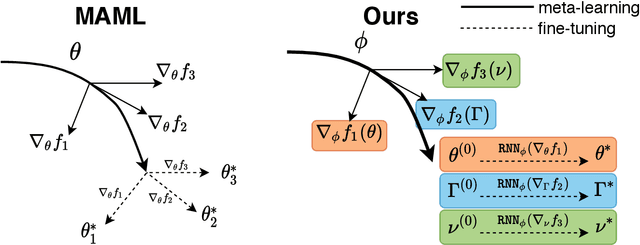
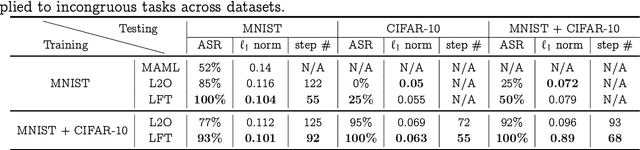
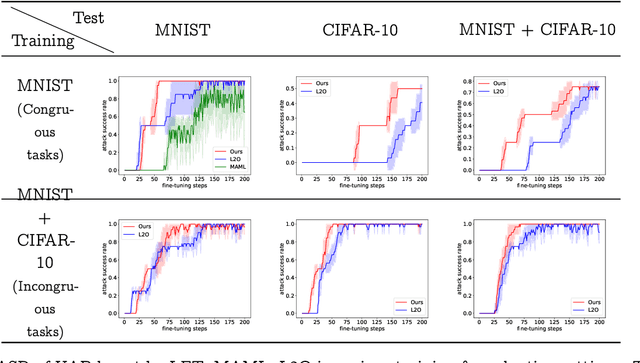
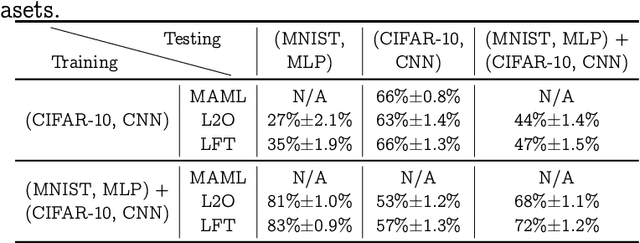
Model-agnostic meta-learning (MAML) effectively meta-learns an initialization of model parameters for few-shot learning where all learning problems share the same format of model parameters -- congruous meta-learning. We extend MAML to incongruous meta-learning where different yet related few-shot learning problems may not share any model parameters. In this setup, we propose the use of a Learned Fine Tuner (LFT) to replace hand-designed optimizers (such as SGD) for the task-specific fine-tuning. The meta-learned initialization in MAML is replaced by learned optimizers based on the learning-to-optimize (L2O) framework to meta-learn across incongruous tasks such that models fine-tuned with LFT (even from random initializations) adapt quickly to new tasks. The introduction of LFT within MAML (i) offers the capability to tackle few-shot learning tasks by meta-learning across incongruous yet related problems (e.g., classification over images of different sizes and model architectures), and (ii) can {efficiently} work with first-order and derivative-free few-shot learning problems. Theoretically, we quantify the difference between LFT (for MAML) and L2O. Empirically, we demonstrate the effectiveness of LFT through both synthetic and real problems and a novel application of generating universal adversarial attacks across different image sources in the few-shot learning regime.
Bone Suppression on Chest Radiographs With Adversarial Learning
Feb 08, 2020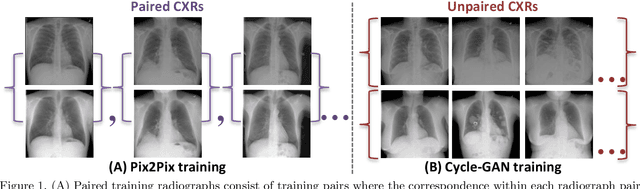

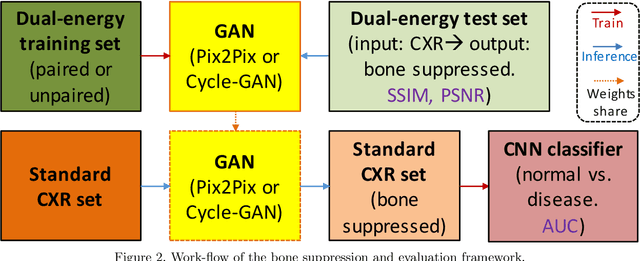
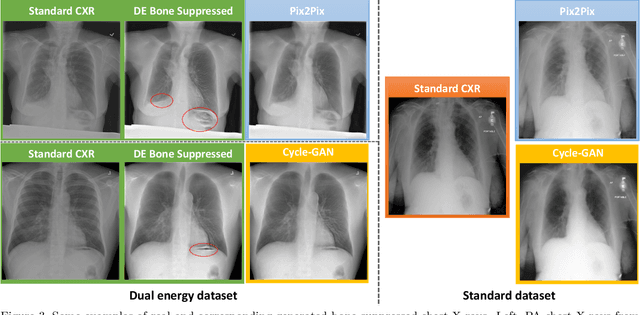
Dual-energy (DE) chest radiography provides the capability of selectively imaging two clinically relevant materials, namely soft tissues, and osseous structures, to better characterize a wide variety of thoracic pathology and potentially improve diagnosis in posteroanterior (PA) chest radiographs. However, DE imaging requires specialized hardware and a higher radiation dose than conventional radiography, and motion artifacts sometimes happen due to involuntary patient motion. In this work, we learn the mapping between conventional radiographs and bone suppressed radiographs. Specifically, we propose to utilize two variations of generative adversarial networks (GANs) for image-to-image translation between conventional and bone suppressed radiographs obtained by DE imaging technique. We compare the effectiveness of training with patient-wisely paired and unpaired radiographs. Experiments show both training strategies yield "radio-realistic'' radiographs with suppressed bony structures and few motion artifacts on a hold-out test set. While training with paired images yields slightly better performance than that of unpaired images when measuring with two objective image quality metrics, namely Structural Similarity Index (SSIM) and Peak Signal-to-Noise Ratio (PSNR), training with unpaired images demonstrates better generalization ability on unseen anteroposterior (AP) radiographs than paired training.
Detecting soccer balls with reduced neural networks: a comparison of multiple architectures under constrained hardware scenarios
Sep 28, 2020
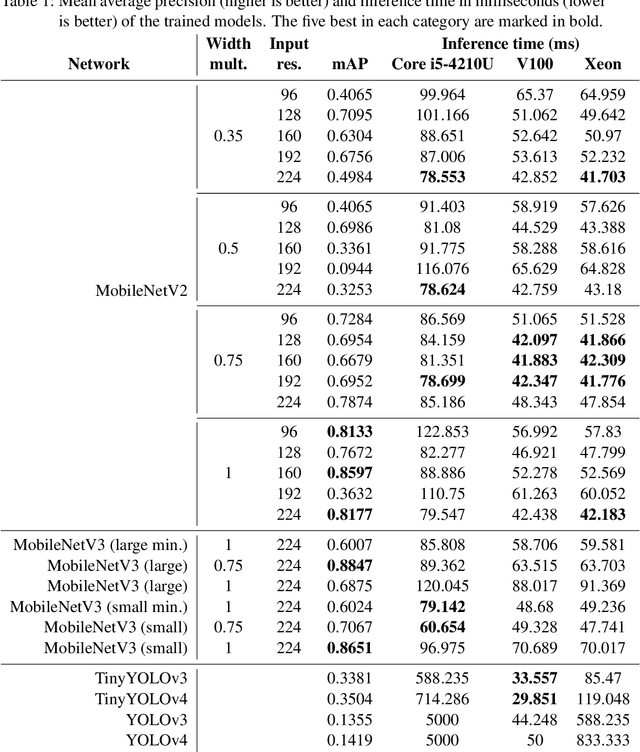
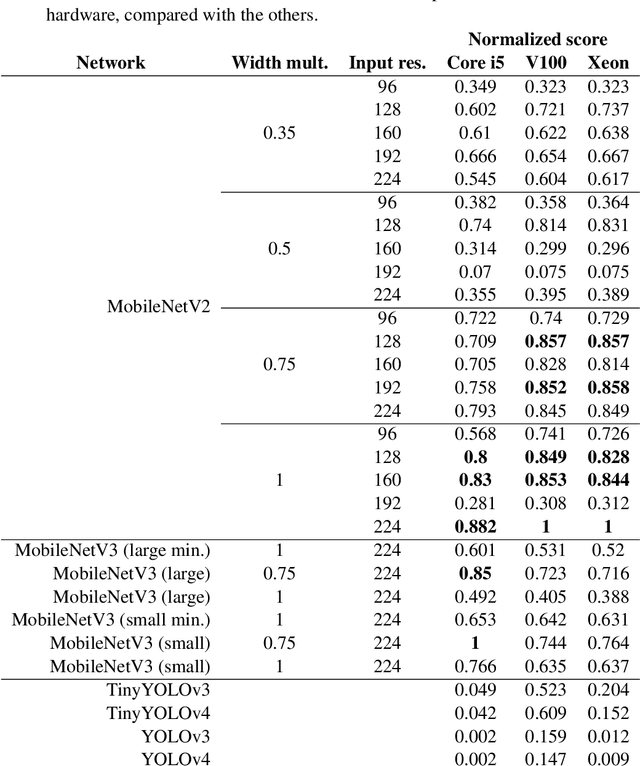
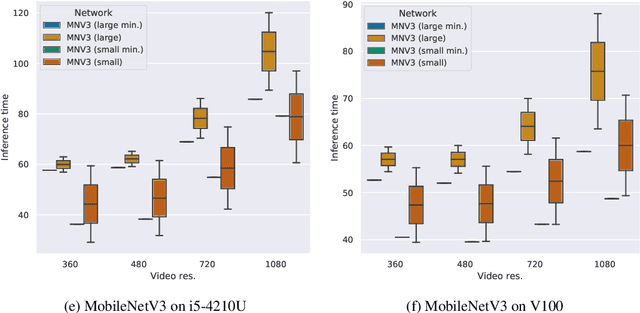
Object detection techniques that achieve state-of-the-art detection accuracy employ convolutional neural networks, implemented to have optimal performance in graphics processing units. Some hardware systems, such as mobile robots, operate under constrained hardware situations, but still benefit from object detection capabilities. Multiple network models have been proposed, achieving comparable accuracy with reduced architectures and leaner operations. Motivated by the need to create an object detection system for a soccer team of mobile robots, this work provides a comparative study of recent proposals of neural networks targeted towards constrained hardware environments, in the specific task of soccer ball detection. We train multiple open implementations of MobileNetV2 and MobileNetV3 models with different underlying architectures, as well as YOLOv3, TinyYOLOv3, YOLOv4 and TinyYOLOv4 in an annotated image data set captured using a mobile robot. We then report their mean average precision on a test data set and their inference times in videos of different resolutions, under constrained and unconstrained hardware configurations. Results show that MobileNetV3 models have a good trade-off between mAP and inference time in constrained scenarios only, while MobileNetV2 with high width multipliers are appropriate for server-side inference. YOLO models in their official implementations are not suitable for inference in CPUs.
Table Structure Recognition using Top-Down and Bottom-Up Cues
Oct 09, 2020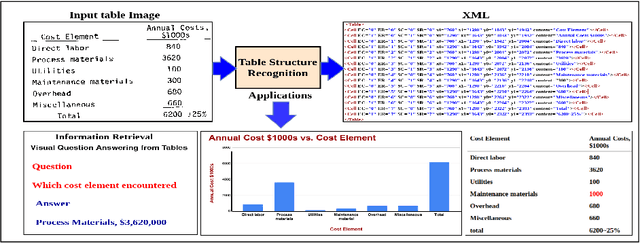

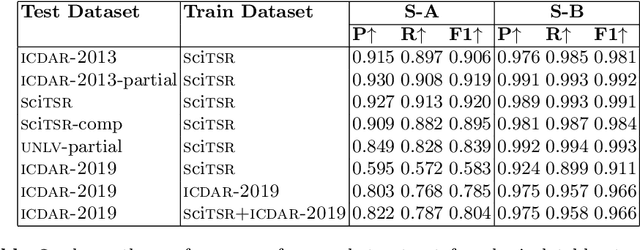
Tables are information-rich structured objects in document images. While significant work has been done in localizing tables as graphic objects in document images, only limited attempts exist on table structure recognition. Most existing literature on structure recognition depends on extraction of meta-features from the PDF document or on the optical character recognition (OCR) models to extract low-level layout features from the image. However, these methods fail to generalize well because of the absence of meta-features or errors made by the OCR when there is a significant variance in table layouts and text organization. In our work, we focus on tables that have complex structures, dense content, and varying layouts with no dependency on meta-features and/or OCR. We present an approach for table structure recognition that combines cell detection and interaction modules to localize the cells and predict their row and column associations with other detected cells. We incorporate structural constraints as additional differential components to the loss function for cell detection. We empirically validate our method on the publicly available real-world datasets - ICDAR-2013, ICDAR-2019 (cTDaR) archival, UNLV, SciTSR, SciTSR-COMP, TableBank, and PubTabNet. Our attempt opens up a new direction for table structure recognition by combining top-down (table cells detection) and bottom-up (structure recognition) cues in visually understanding the tables.
DeepLandscape: Adversarial Modeling of Landscape Video
Aug 21, 2020
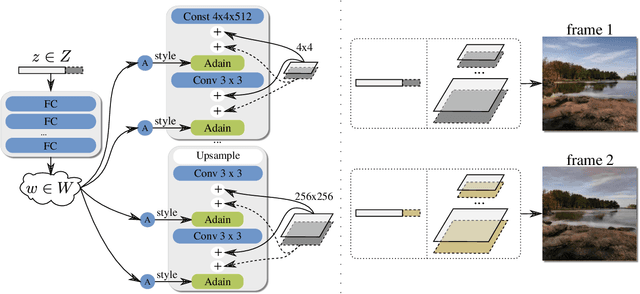
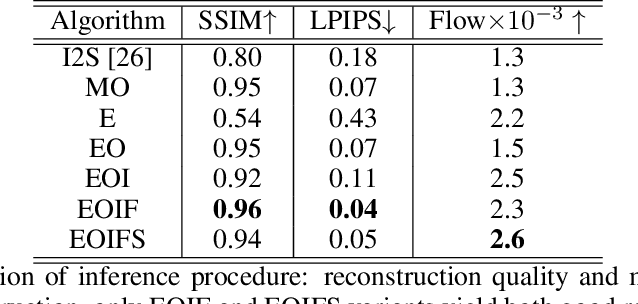
We build a new model of landscape videos that can be trained on a mixture of static landscape images as well as landscape animations. Our architecture extends StyleGAN model by augmenting it with parts that allow to model dynamic changes in a scene. Once trained, our model can be used to generate realistic time-lapse landscape videos with moving objects and time-of-the-day changes. Furthermore, by fitting the learned models to a static landscape image, the latter can be reenacted in a realistic way. We propose simple but necessary modifications to StyleGAN inversion procedure, which lead to in-domain latent codes and allow to manipulate real images. Quantitative comparisons and user studies suggest that our model produces more compelling animations of given photographs than previously proposed methods. The results of our approach including comparisons with prior art can be seen in supplementary materials and on the project page https://saic-mdal.github.io/deep-landscape
Data-driven Flood Emulation: Speeding up Urban Flood Predictions by Deep Convolutional Neural Networks
Apr 17, 2020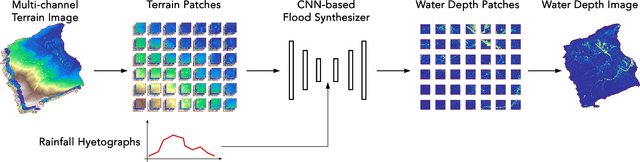
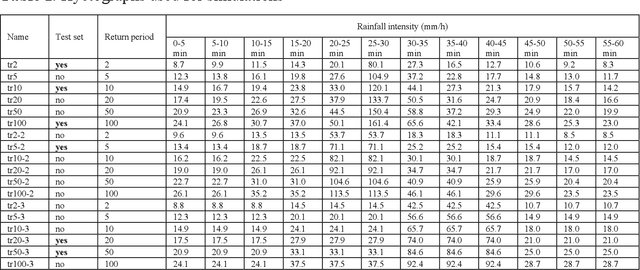
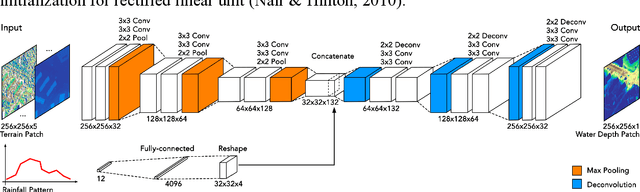
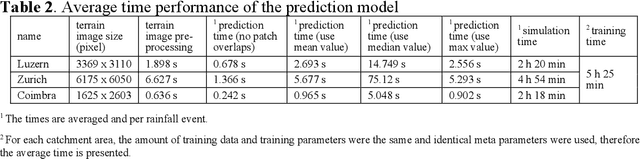
Computational complexity has been the bottleneck of applying physically-based simulations on large urban areas with high spatial resolution for efficient and systematic flooding analyses and risk assessments. To address this issue of long computational time, this paper proposes that the prediction of maximum water depth rasters can be considered as an image-to-image translation problem where the results are generated from input elevation rasters using the information learned from data rather than by conducting simulations, which can significantly accelerate the prediction process. The proposed approach was implemented by a deep convolutional neural network trained on flood simulation data of 18 designed hyetographs on three selected catchments. Multiple tests with both designed and real rainfall events were performed and the results show that the flood predictions by neural network uses only 0.5 % of time comparing with physically-based approaches, with promising accuracy and ability of generalizations. The proposed neural network can also potentially be applied to different but relevant problems including flood predictions for urban layout planning.
A Latent Source Model for Patch-Based Image Segmentation
Oct 06, 2015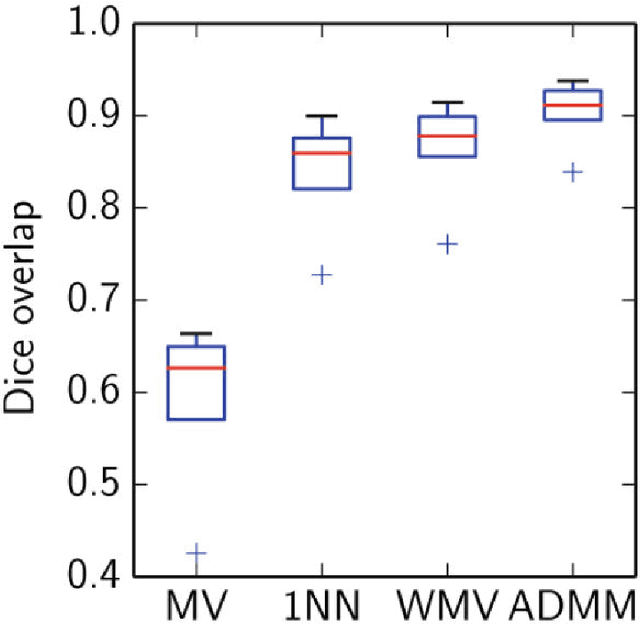
Despite the popularity and empirical success of patch-based nearest-neighbor and weighted majority voting approaches to medical image segmentation, there has been no theoretical development on when, why, and how well these nonparametric methods work. We bridge this gap by providing a theoretical performance guarantee for nearest-neighbor and weighted majority voting segmentation under a new probabilistic model for patch-based image segmentation. Our analysis relies on a new local property for how similar nearby patches are, and fuses existing lines of work on modeling natural imagery patches and theory for nonparametric classification. We use the model to derive a new patch-based segmentation algorithm that iterates between inferring local label patches and merging these local segmentations to produce a globally consistent image segmentation. Many existing patch-based algorithms arise as special cases of the new algorithm.