 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CaDIS: Cataract Dataset for Image Segmentation
Jul 19, 2019
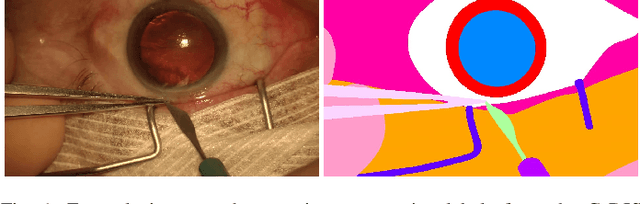
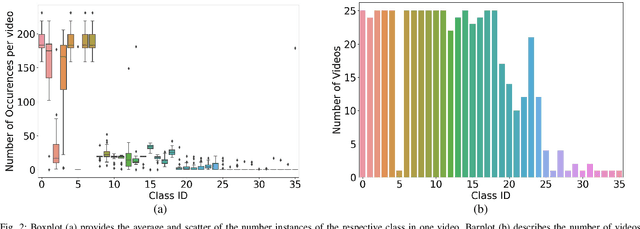
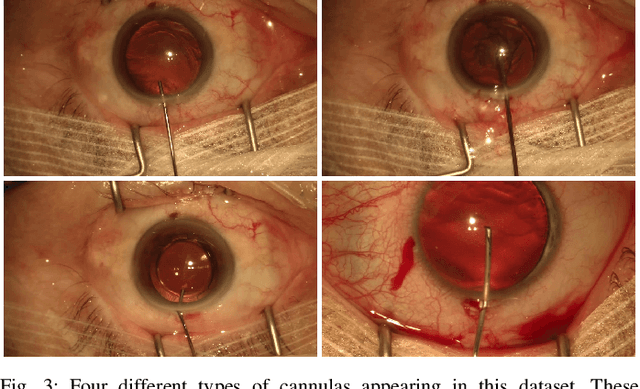

Video signals provide a wealth of information about surgical procedures and are the main sensory cue for surgeons. Video processing and understanding can be used to empower computer assisted interventions (CAI) as well as the development of detailed post-operative analysis of the surgical intervention. A fundamental building block to such capabilities is the ability to understand and segment video into semantic labels that differentiate and localize tissue types and different instruments. Deep learning has advanced semantic segmentation techniques dramatically in recent years but is fundamentally reliant on the availability of labelled datasets used to train models. In this paper, we introduce a high quality dataset for semantic segmentation in Cataract surgery. We generated this dataset from the CATARACTS challenge dataset, which is publicly available. To the best of our knowledge, this dataset has the highest quality annotation in surgical data to date. We introduce the dataset and then show the automatic segmentation performance of state-of-the-art models on that dataset as a benchmark.
MAVIDH Score: A COVID-19 Severity Scoring using Chest X-Ray Pathology Features
Dec 01, 2020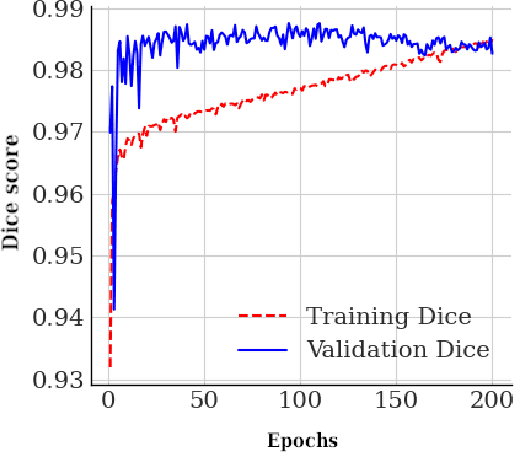
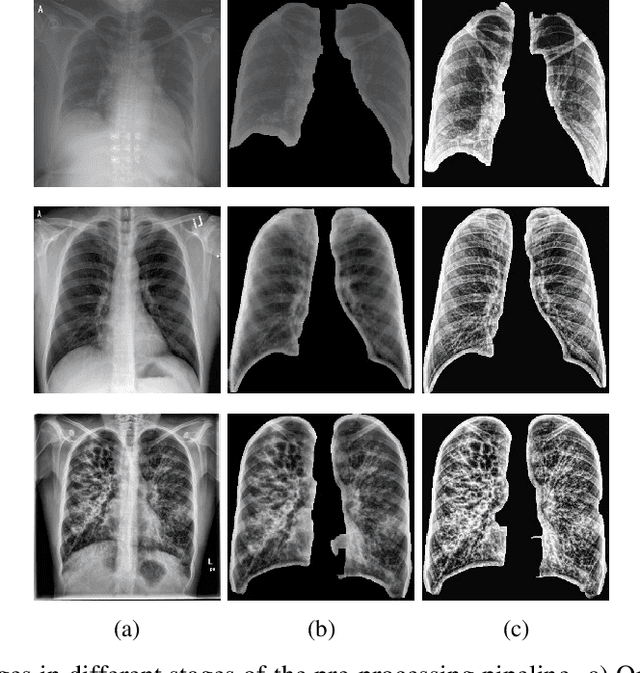
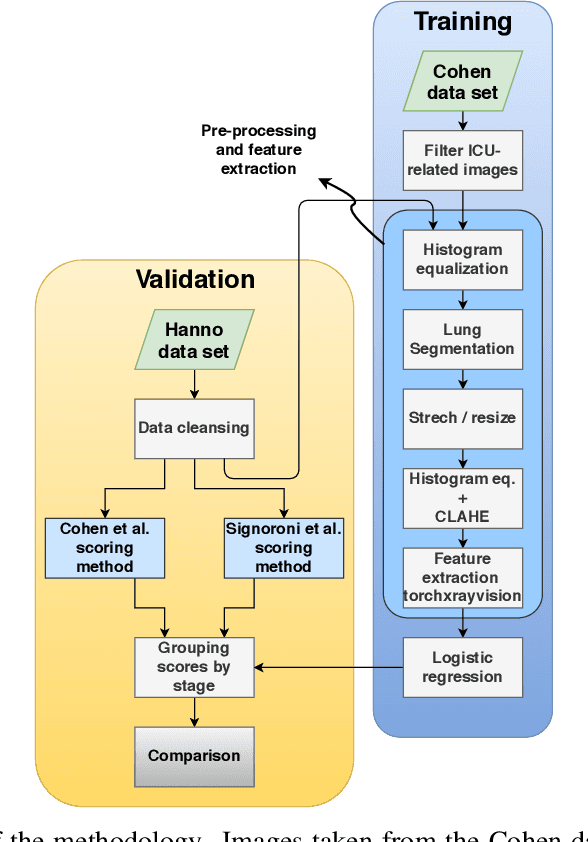
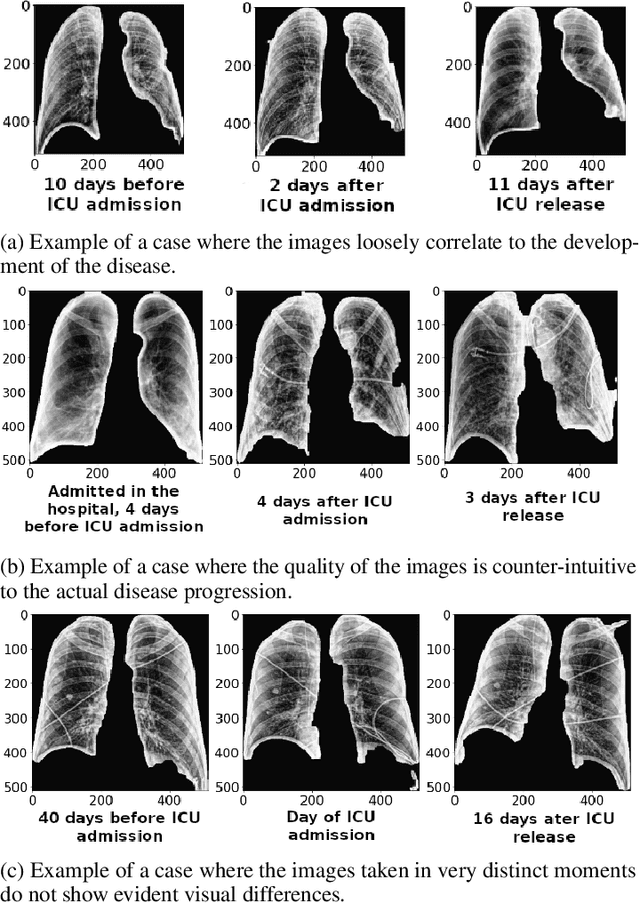
The application of computer vision for COVID-19 diagnosis is complex and challenging, given the risks associated with patient misclassifications. Arguably, the primary value of medical imaging for COVID-19 lies rather on patient prognosis. Radiological images can guide physicians assessing the severity of the disease, and a series of images from the same patient at different stages can help to gauge disease progression. Based on these premises, a simple method based on lung-pathology features for scoring disease severity from Chest X-rays is proposed here. As the primary contribution, this method shows to be correlated to patient severity in different stages of disease progression comparatively well when contrasted with other existing methods. An original approach for data selection is also proposed, allowing the simple model to learn the severity-related features. It is hypothesized that the resulting competitive performance presented here is related to the method being feature-based rather than reliant on lung involvement or compromise as others in the literature. The fact that it is simpler and interpretable than other end-to-end, more complex models, also sets aside this work. As the data set is small, bias-inducing artifacts that could lead to overfitting are minimized through an image normalization and lung segmentation step at the learning phase. A second contribution comes from the validation of the results, conceptualized as the scoring of patients groups from different stages of the disease. Besides performing such validation on an independent data set, the results were also compared with other proposed scoring methods in the literature. The expressive results show that although imaging alone is not sufficient for assessing severity as a whole, there is a strong correlation with the scoring system, termed as MAVIDH score, with patient outcome.
Deep Controllable Backlight Dimming
Aug 19, 2020
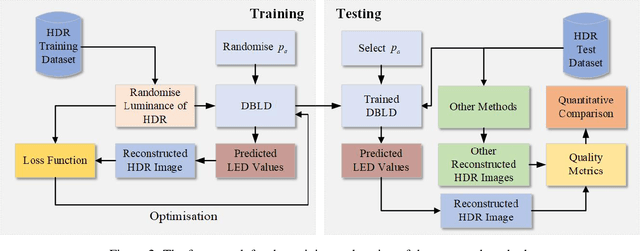
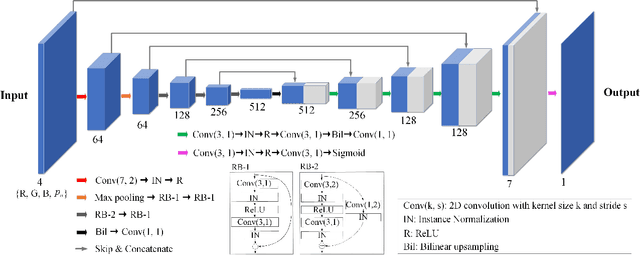
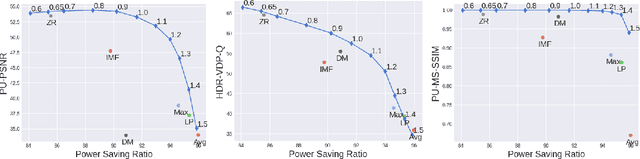
Dual-panel displays require local dimming algorithms in order to reproduce content with high fidelity and high dynamic range. In this work, a novel deep learning based local dimming method is proposed for rendering HDR images on dual-panel HDR displays. The method uses a Convolutional Neural Network to predict backlight values, using as input the HDR image that is to be displayed. The model is designed and trained via a controllable power parameter that allows a user to trade off between power and quality. The proposed method is evaluated against six other methods on a test set of 105 HDR images, using a variety of quantitative quality metrics. Results demonstrate improved display quality and better power consumption when using the proposed method compared to the best alternatives.
Towards A Controllable Disentanglement Network
Jan 22, 2020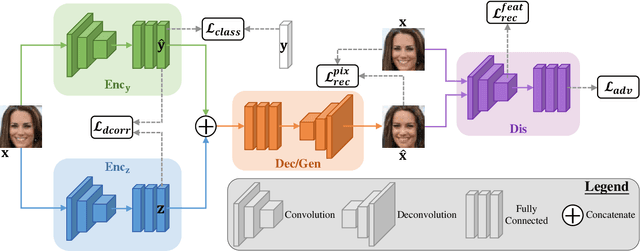
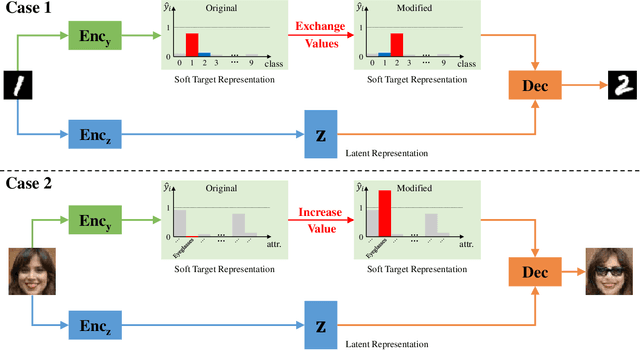


This paper addresses two crucial problems of learning disentangled image representations, namely controlling the degree of disentanglement during image editing, and balancing the disentanglement strength and the reconstruction quality. To encourage disentanglement, we devise a distance covariance based decorrelation regularization. Further, for the reconstruction step, our model leverages a soft target representation combined with the latent image code. By exploring the real-valued space of the soft target representation, we are able to synthesize novel images with the designated properties. To improve the perceptual quality of images generated by autoencoder (AE)-based models, we extend the encoder-decoder architecture with the generative adversarial network (GAN) by collapsing the AE decoder and the GAN generator into one. We also design a classification based protocol to quantitatively evaluate the disentanglement strength of our model. Experimental results showcase the benefits of the proposed model.
Indirect Local Attacks for Context-aware Semantic Segmentation Networks
Dec 02, 2019

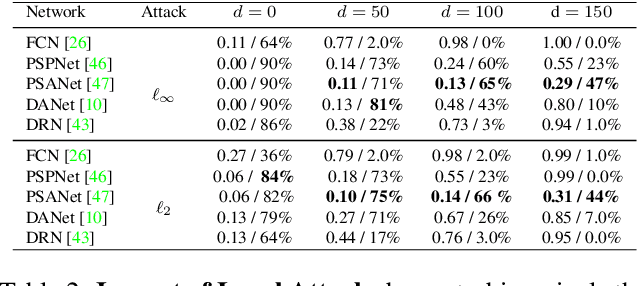

Recently, deep networks have achieved impressive semantic segmentation performance, in particular thanks to their use of larger contextual information. In this paper, we show that the resulting networks are sensitive not only to global attacks, where perturbations affect the entire input image, but also to indirect local attacks where perturbations are confined to a small image region that does not overlap with the area that we aim to fool. To this end, we introduce several indirect attack strategies, including adaptive local attacks, aiming to find the best image location to perturb, and universal local attacks. Furthermore, we propose attack detection techniques both for the global image level and to obtain a pixel-wise localization of the fooled regions. Our results are unsettling: Because they exploit a larger context, more accurate semantic segmentation networks are more sensitive to indirect local attacks.
Detecting GAN generated errors
Dec 02, 2019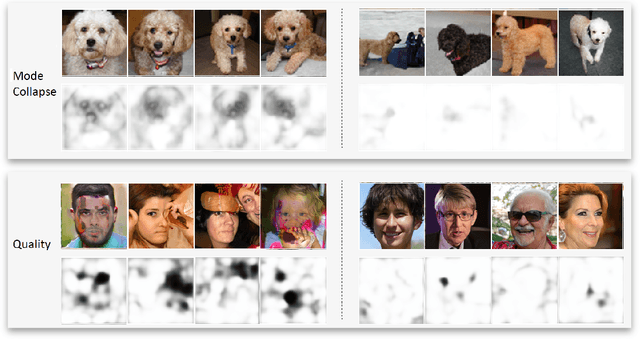



Despite an impressive performance from the latest GAN for generating hyper-realistic images, GAN discriminators have difficulty evaluating the quality of an individual generated sample. This is because the task of evaluating the quality of a generated image differs from deciding if an image is real or fake. A generated image could be perfect except in a single area but still be detected as fake. Instead, we propose a novel approach for detecting where errors occur within a generated image. By collaging real images with generated images, we compute for each pixel, whether it belongs to the real distribution or generated distribution. Furthermore, we leverage attention to model long-range dependency; this allows detection of errors which are reasonable locally but not holistically. For evaluation, we show that our error detection can act as a quality metric for an individual image, unlike FID and IS. We leverage Improved Wasserstein, BigGAN, and StyleGAN to show a ranking based on our metric correlates impressively with FID scores. Our work opens the door for better understanding of GAN and the ability to select the best samples from a GAN model.
Learning to segment images with classification labels
Dec 28, 2019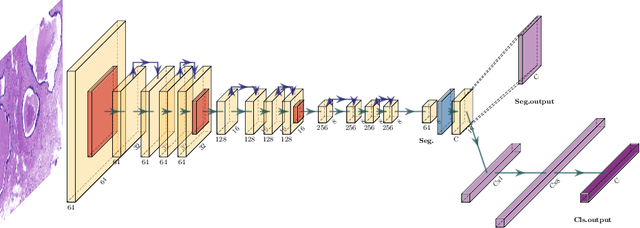
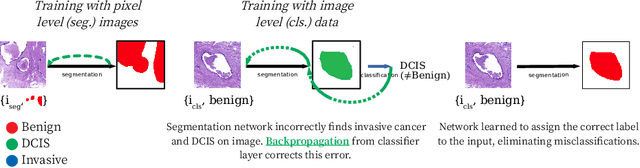
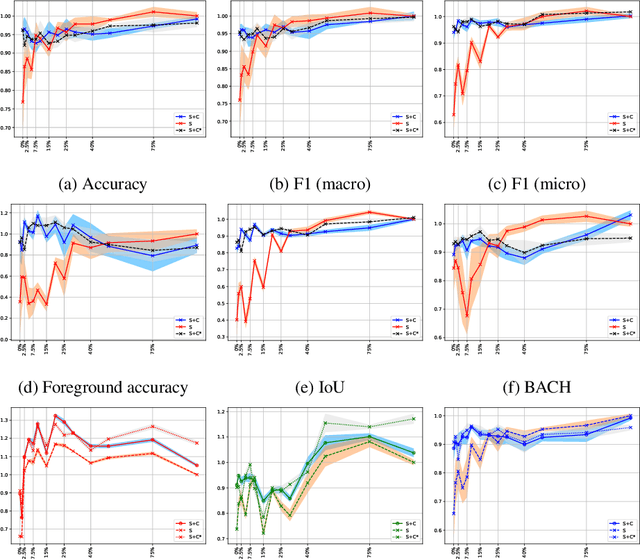

Two of the most common tasks in medical imaging are classification and segmentation. Either task requires labeled data annotated by experts, which is scarce and expensive to collect. Annotating data for segmentation is generally considered to be more laborious as the annotator has to draw around the boundaries of regions of interest, as opposed to assigning image patches a class label. Furthermore, in tasks such as breast cancer histopathology, any realistic clinical application often includes working with whole slide images, whereas most publicly available training data are in the form of image patches, which are given a class label. We propose an architecture that can alleviate the requirements for segmentation-level ground truth by making use of image-level labels to reduce the amount of time spent on data curation. In addition, this architecture can help unlock the potential of previously acquired image-level datasets on segmentation tasks by annotating a small number of regions of interest. In our experiments, we show using only one segmentation-level annotation per class, we can achieve performance comparable to a fully annotated dataset.
Defending Against Multiple and Unforeseen Adversarial Videos
Sep 11, 2020
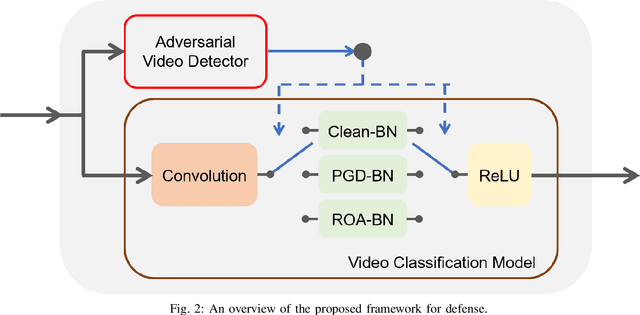

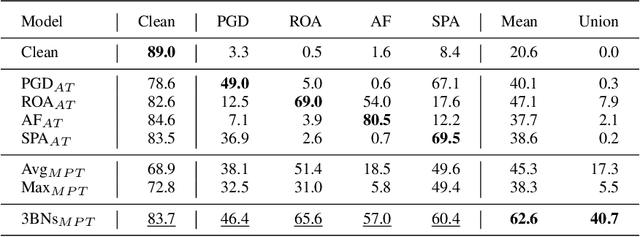
Adversarial examples of deep neural networks have been actively investigated on image-based classification, segmentation and detection tasks. However, adversarial robustness of video models still lacks exploration. While several studies have proposed how to generate adversarial videos, only a handful of approaches pertaining to the defense strategies have been published in the literature. Furthermore, these defense methods are limited to a single perturbation type and often fail to provide robustness to Lp-bounded attacks and physically realizable attacks simultaneously. In this paper, we propose one of the first defense solutions against multiple adversarial video types for video classification. The proposed approach performs adversarial training with multiple types of video adversaries using independent batch normalizations (BNs), and recognizes different adversaries by an adversarial video detector. During inference, a switch module sends an input to a proper batch normalization branch according to the detected attack type. Compared to conventional adversarial training, our method exhibits stronger robustness to multiple and even unforeseen adversarial videos and provides higher classification accuracy.
A Bayesian algorithm for detecting identity matches and fraud in image databases
Jun 20, 2017
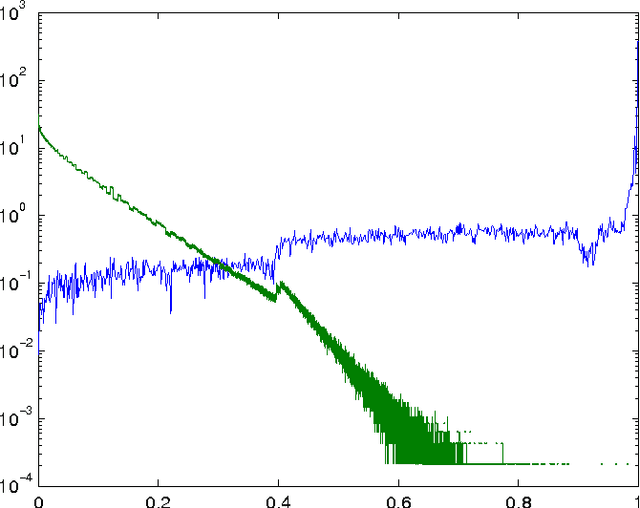
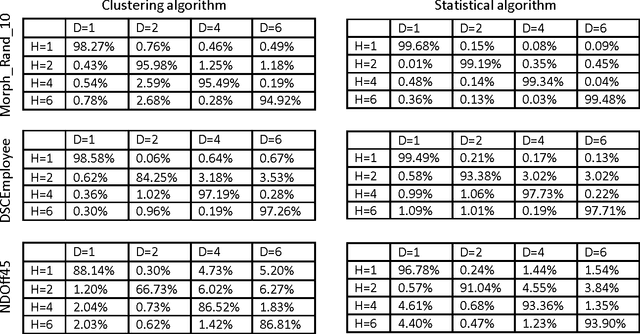
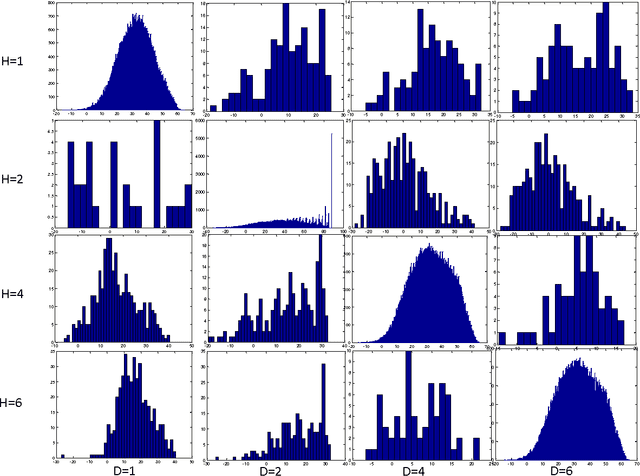
A statistical algorithm for categorizing different types of matches and fraud in image databases is presented. The approach is based on a generative model of a graph representing images and connections between pairs of identities, trained using properties of a matching algorithm between images.
Towards Lightweight Lane Detection by Optimizing Spatial Embedding
Aug 27, 2020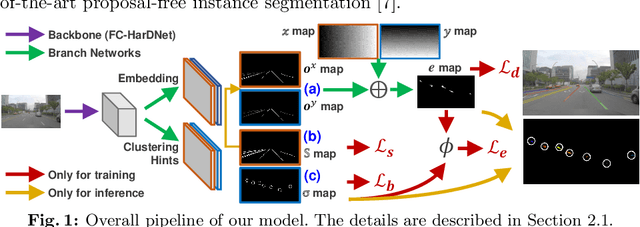
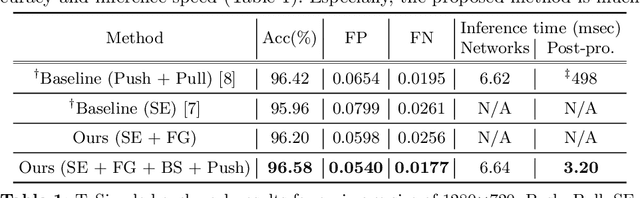
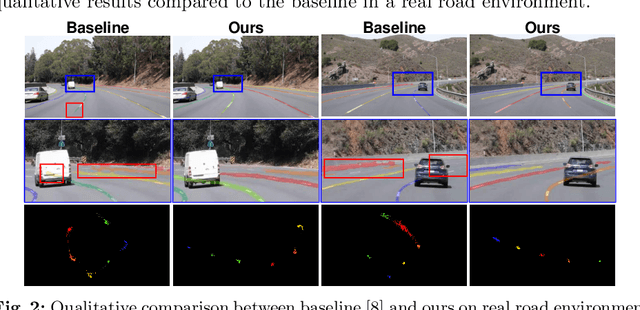
A number of lane detection methods depend on a proposal-free instance segmentation because of its adaptability to flexible object shape, occlusion, and real-time application. This paper addresses the problem that pixel embedding in proposal-free instance segmentation based lane detection is difficult to optimize. A translation invariance of convolution, which is one of the supposed strengths, causes challenges in optimizing pixel embedding. In this work, we propose a lane detection method based on proposal-free instance segmentation, directly optimizing spatial embedding of pixels using image coordinate. Our proposed method allows the post-processing step for center localization and optimizes clustering in an end-to-end manner. The proposed method enables real-time lane detection through the simplicity of post-processing and the adoption of a lightweight backbone. Our proposed method demonstrates competitive performance on public lane detection datasets.